目前机器学习已经广泛地应用在对于金融市场的分析、预测中,在资产配置上更是大显神威。但是,在浩如烟海的机器学习算法中,到底哪种算法能取得更优的预测效果呢?在目前主流的机器学习算法中,大致可以划分为两大类,一类是回归类算法,主要用于对于连续型数据的预测,第二类就是分类算法,主要是用于对离散型数据的预测,那么在股价预测上我们究竟运用那种类型的算法比较好呢?发表在《Applied Mathematical Finance》的这篇文章利用随机森林算法对股价d天之后的涨跌方向进行了预测。发现相比于SVM、线性判别分析等模型,随机森林可以取得更优秀的预测结果:能够达到85%-95%的准确率。本文笔者试图通过个股对应的大盘,行业和个股的三个维度成交量,价格(指数),运用随机森林算法进行分析研究。
摘要:
之前大部分人对于股价预测分析中,都把股价变化,看出是一个连续性的问题,采用回归模型进行预测,其结果总是不尽人意,因为影响股价的因素实在太多,而且每个因素的影响强度,在不同的时间点,也存在较大的差异性,因此我们可以化繁为简,把它转化成一个分类问题,从而最小化预测误差,本文章将预测股价的走势看做一个二分类问题(涨or跌),为了使预测更具有操作性,我们把股价涨幅划分为(f(x)>=2% or f(x)<2%),使用集成机器学习建模解决。文章里利用个股对应的大盘指数的涨跌和成交量的变化率,个股对应的行业指数的涨跌和成交量的变化,已经个股的涨跌和成交量的变化,作为分类的特征,对随机森林模型进行训练。最后发现,模型中决策树个数增加,模型准确率增加并有收敛趋势;并且,预测的时间窗口越长,模型越准确。
随机森林简介
在正式进入文章前,先对随机森林算法给出简单的介绍。
随机森林算法是一种非线性模型,顾名思义,是将多个决策树集成为森林的一种模型。理解随机森林的关键有两点:随机抽样和多数投票。
首先,对于每一个决策树,从全样本集中有放回地随机抽取训练集。本文决策树分类的标准是特征矩阵X里面的成交量变化率和价格变化率,一直利用特征分类直到基尼不纯度很小达到要求。
这些决策树独立预测,然后对每个决策树预测的结果进行投票,票数最多的成为随机森林的预测结果。这样避免了单个决策树的过拟合。
由于随机抽样,每个决策树使用的都不是全样本(大约只有2323的样本被抽到),没有被抽到的样本是这个决策树的非样本集(袋外样本 Out of Bag Sample)。对于所有决策树产生的袋外样本,对每个样本,计算它作为oob样本的树对它的分类情况(约1313的树),然后以简单多数投票作为该样本的分类结果,最后用误分个数占样本总数的比率作为随机森林的OOB误分率。所以,OOB偏差越小,说明误分类的比例越低,随机森林分类越准。
研究思路
我们先运用600519贵州茅台自2005/1/1到2019/8/1/以来的数据最为模型的训练种子数据,选择贵州茅台的作为训练集的主要原因是,股价连续性好,没有停牌、连续一字涨停或者跌停,这样训练出来的模型,更具有普适性。然后运用上证50的50只股票作为测试集,进行测试模型的效果。
数据的收集和预处理
在数据的收集上,我们收集了上证50的50只股票的2005/1/1到2019/8/1以来的价格和成交量数据,用来预测股价第二的涨幅是否大于2%,对于成交量和价格,我们并没有做太多的处理,仅仅是把它转变成变化率,因为我们主要是做短线的预测,要尽可能的保持数据信息的完整性。
线性可分性测试
在建立模型之前,笔者首先对(f(x)>=2% or f(x)<2%)这两类数据进行了线性可分测试,结果发现股票走势预测问题不是线性可分的(投影到二维空间发现凸包有大量重合),所以所有和线性判别分析有关的算法比如SVM都是不适用的。随机森林作为一种非线性算法,可以避免这种情况,在接下来的股票走势预测研究中有重要应用意义。
随机森林的建立
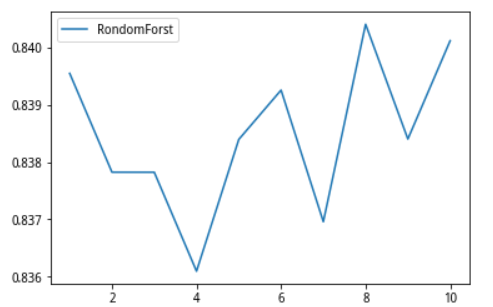
我们先建25棵树,进行十次十组交叉验证,测试的结果是平均成功率在83%左右。确定分类算法对于股价的预测具备显著的效果,随后我们对于最佳种树数量进行参数估计,
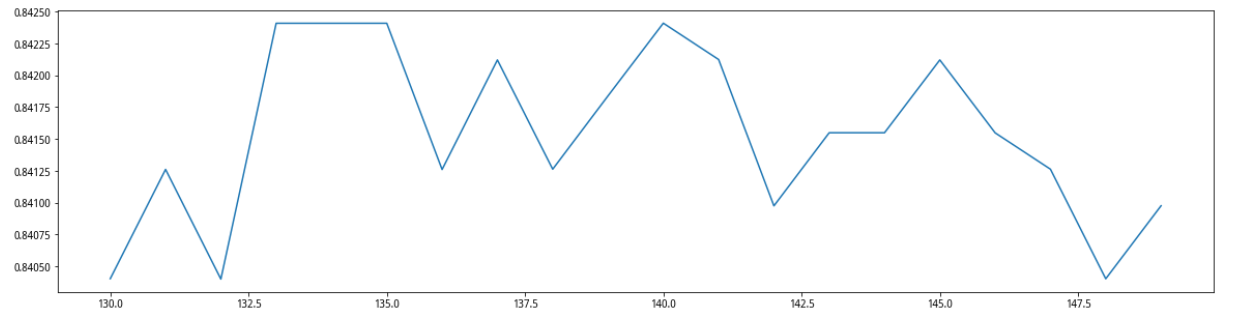
先在range(0,200,10)的范围上,确定一个大致的范围,发现最高值在140附近,随后我们在130——150的范围内进行测试,最终确定最佳种树数量是140棵,交叉验证成功在0.8424。
检查模型的普适性
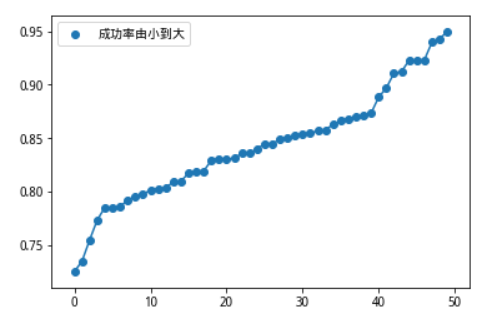
我们保持上一步调优后的模型,随后我们用600519训练的模型,对上证50成分股,自2005/1/1到2019/8/1/以来的数据进行测试,验证学习到的模型具备普遍适用性。50只个股的最终成功率分布图如下,最大值为0.9492,最小值为0.7254,平均值为0.8425。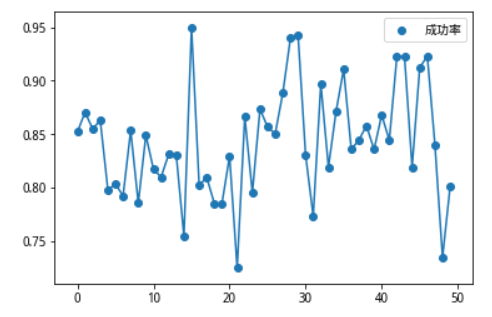
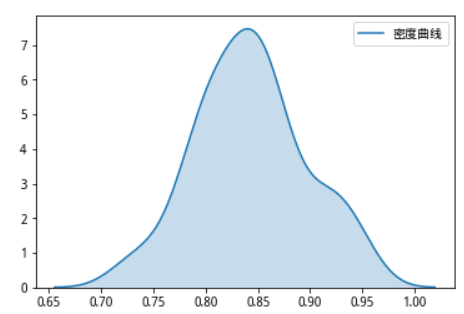
对成功率进行排序,低于80%的成功率的只有十个,高于90%的有8个,大部分数据集中在中位数附近,显示模型的预测具有较强的稳定性。
模拟交易
本来想也做一个十年的模拟交易回测看看最后的效果,即使使用历史训练好的模型,在上证50中进行选股,无奈选股时间太久,就此作罢。理想状态应该是每天都要把新数据加进来训练新的模型,最好在14:50跑完选股结果,然后收盘前进行买进,第二天出局。以后有好的想法再进行改进!
运用随机森林进行股价预测¶
from jqdata import *
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import warnings
import time
warnings.filterwarnings('ignore')
数据预处理¶
#获取个股所属申万行业代码,因为目前只有申万行业行情
def secu_industry_code(code):
a=[]
aa=get_industry(code, date=None)
for i in aa[code].keys():
if 'sw' in i:
a.append(aa[code][i]['industry_code'])
return a
code="600008.XSHG"
#测试
bb=secu_industry_code(code)
bb
#获取个股对应大盘的指数代码
def Correspondence_index(code):
a=code[:2]
if a=='60':
b='000001.XSHG'
elif a=='30':
b='399006.XSHE'
elif a=='00':
if code[:3]=='000':
b='399001.XSHE'
else:
b='399005.XSHE'
return b
def handle_table(code,num,a='g'):
#num为获取数据的长度
#a为修改列名称的标签,无特别意义
secu=attribute_history(code, num, unit='1d',
fields=[ 'close', 'volume',],
skip_paused=True, df=True, fq='pre')
#计算价格的涨跌幅,并删除空行
secu_change = secu.close.pct_change()
#新增涨跌幅列,乘以100转换成百分比
secu['chg'+a]=secu_change*100
returns=secu
#returns['close']=secu.close
returns.rename(columns={'close': 'close'+a},inplace=True)
returns.rename(columns={'volume': 'volume'+a},inplace=True)
#增加‘date’列,值为原来的索引
returns['date']=returns.index
#按日期降序排列
returns=returns.sort_values('date', ascending=False)
#重置索引,丢掉原来的索引
returns=returns.reset_index(drop = True)
return returns
#获取个股和行业以及对应大盘行情数据
def secu_industry_quotation(code,limit=None,date=None):
#limit获取数据的行数,默认全部
#date获取某日期之前的数据,默认当天
#获取行业板块行情
bb=secu_industry_code(code)
a=1
#如果时间没有指定,那么取当前时间
if date:
pass
else:
date=time.strftime('%Y-%m-%d',time.localtime())
for i in bb:
df1=finance.run_query(query(
finance.SW1_DAILY_PRICE.date,
finance.SW1_DAILY_PRICE.close,
finance.SW1_DAILY_PRICE.volume,
finance.SW1_DAILY_PRICE.change_pct
).filter(
finance.SW1_DAILY_PRICE.code==i,
finance.SW1_DAILY_PRICE.date<=date).order_by(
finance.SW1_DAILY_PRICE.date.desc()
).limit(limit))
#批量修改列名称
df1=df1.rename(columns=lambda x: x + str(a))
#把date列改回来,作为合并轴
df1=df1.rename(columns={'date'+str(a):'date'})
if a==1:
df=df1
else:
df=df.merge(df1,on='date')
a+=1
#把‘date’列的数据的object类型,转换成datetime64[ns]类型
df['date']=df['date'].astype('datetime64[ns]')
num=len(df)
#获取个股行情数据
df1=handle_table(code,num,a='g')
#个股行情和行业行情表合并
df=df.merge(df1,on='date')
#获取对应大盘行情
c=Correspondence_index(code)
df2=handle_table(c,num,a='d')
df=df.merge(df2,on='date')
#个股行情和行业行情表合并
return df
df=secu_industry_quotation(code,date='2018-08-22')
df.head()
#把成交量都变成变化率
def change_vol(df):
#获取columns列表
listdf=list(df)
for i in listdf:
if 'volume' in i:
#计算变化率
dfs1 = df[i].pct_change(-1)
a='vol'+i[-1]
df[a]=dfs1
#删掉nan行
df.dropna(inplace=True)
return df
df1=change_vol(df)
df1
#删除指定的列
def del_columns(df,col):
dfx=df
for i in df.columns:
if col in i:
dfx.drop(i,axis=1,inplace=True)
return dfx
df2=del_columns(df1,'close')
df2=del_columns(df2,'volume')
df2
#生成标签列,Y=secu_change的下一列值列。
def generate_label(df):
#生成新列“y”等于‘secu_change’的下一个值
df['y']=df['chgg'].shift(1)
#生成第二天涨幅大于2的(0,1)标签
df['y2']=np.where(df.y>2,1,0)
#删除包含‘nan’的行
df=df.dropna()
df=df.reset_index(drop=True).dropna()
return df
df3=generate_label(df2)
df3
#获取数据X,Y数据集
def current_data(code):
#获取个股、行业、大盘行情数据列表
df=secu_industry_quotation(code)
#把成交量转化成变化率
df1=change_vol(df)
#删除多余的列
df2=del_columns(df1,'close')
df2=del_columns(df2,'volume')
#添加y标签
df3=generate_label(df2)
df3=df3.dropna()
X,Y=df3.iloc[:,1:11],df3.y2
return X,Y
模型调参¶
#运用随机森林进行预测
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
code="600519.XSHG"
X,Y=current_data(code)
cfc_1=[]
#进行十次十组交叉验证
for i in range(10):
cfc=RandomForestClassifier(n_estimators=25)
cfc_s=cross_val_score(cfc,X,Y,cv=10).mean()
cfc_1.append(cfc_s)
plt.plot(range(1,11),cfc_1,label='RondomForst')
plt.legend(loc='best')
plt.show()

#学习曲线,确定n_estimators参数,先range(0,200,10),确定范围,然后,再在最大值上下十个点,进行精确定位n_estimators
superpa=[]
for i in range(130,150):
cfc=RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
cfc_s=cross_val_score(cfc,X,Y,cv=10).mean()
superpa.append(cfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(130,150),superpa)
plt.show()

训练和保存调参后的模型¶
#训练调试好的参数的模型
#初始模型我们以600519的数据进行模型训练。
code="600519.XSHG"
cfc=RandomForestClassifier(n_estimators=140,n_jobs=-1)
X,Y=current_data(code)
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,Y,test_size=0.3,random_state=10)
cfc.fit(Xtrain,Ytrain)
cfc.score(Xtest,Ytest)
#保存训练好的模型
from sklearn.externals import joblib
save='tch'+'cfc'+'.pkl'
joblib.dump(cfc,save)
检查模型的普遍有效性¶
from sklearn.externals import joblib
code="600835.XSHG"
X,Y=current_data(code)
model=joblib.load('tchcfc.pkl')
model.score(X,Y)
#使用上证50中个股,对模型进行有效性测试
b=get_index_stocks('000016.XSHG', date=None)
score=[]
for code in b:
X,Y=current_data(code)
model=joblib.load('tchcfc.pkl')
try:
b=model.score(X,Y)
except ValueError:
pass
score.append(b)
plt.plot(range(len(score)),score)
plt.scatter(range(len(score)),score,marker='o',label='成功率')
plt.legend(loc='best')
plt.show()

np.array(score).mean()
np.array(score).max()
np.array(score).min()
b=np.array(score)
c=np.sort(b)
plt.plot(range(len(c)),c)
plt.scatter(range(len(c)),c,marker='o',label='成功率由小到大')
plt.legend(loc='best')
plt.show()

c
#密度曲线
import seaborn as sns
sns.kdeplot(c, shade=True,label='密度曲线')
plt.legend()
plt.show()

调用保存模型进行预测¶
from sklearn.externals import joblib
#预测模型
def predict_data(code,date):
df=secu_industry_quotation(code,limit=2,date=date)
df1=change_vol(df)
df1=del_columns(df,'close')
df1=del_columns(df,'volume')
x=df.iloc[:,1:11]
model=joblib.load('tchcfc.pkl')
a=model.predict(x)
return a
#进行选股
def check_stock(date=None):
#进行选股
a=[]
security=get_index_stocks('000016.XSHG', date=date)
for code in security:
try:
if predict_data(code,date)==1:
g.a.append(code)
except :
pass
return a
a=get_trade_days(start_date='2010-8-1', end_date=None, count=None)
for i in a:
a=check_stock(date=i)
if len(a)>0:
print(a)