内容
- 概述
- 1. 循环神经网络的显著特征
- 2. 循环网络训练原则
- 3. 构建一个循环神经网络
- 3.1. 类的初始化方法
- 3.2. 前馈
- 3.3. 误差梯度计算
- 3.4. 更新权重
- 4. 测试
- 结束语
- 链接
- 本文中用到的程序
概述
我们继续研究神经网络。 我们之前已经讨论过多层感知器和卷积神经网络。 它们都在 Markov 流程的框架内处理静态数据,根据静态数据,后续系统状态仅取决于其当前状态,而非取决于过去的系统状态。 现在,我建议研究循环神经网络。 这是一种特殊的神经网络,设计用于操控时间顺序,曾被认为是该领域的领导者。
1. 循环神经网络的显著特征
之前讨论的所有类型神经网络都采用预判数量的数据。 然而,在我们的案例中,很难判定理想的价格图表分析数据量。 不同的形态可在不同的时间间隔出现。 即使间隔本身也不总是恒定的,且能根据当前情况而变化。 某些事件在市场上可能很罕见,但它们发生的概率很高。 当事件在分析的数据窗口内发生时,这是好事。 如果它超出了所分析的序列,那么即使市场当时正在对此事件做出反应,神经网络也将忽略它。 分析窗口内增加将导致计算资源的消耗增加,且需要更多时间来做出决定。
已经提议在神经网络中采用循环神经元来解决时间序列问题。 当系统的当前状态与同一神经元的先前状态一起司馈入神经元时,这是尝试在神经网络中实现短期记忆。 此过程基于这样的假设,即神经元输出的值考虑了所有因素(包括其先前状态)的影响,并且在下一步将“所有认知”转移给其未来状态。 这类似于当我们采取行动时,会基于以前的经验和早前执行的动作。 记忆持续时间及其对当前神经元状态的影响将取决于权重。

不幸的是,这种简单的解决方案有其缺陷。 这种方法能够在较短的时间间隔内保存“记忆”。 信号循环数乘以小于 1 的因子,以及神经元激活函数的应用会导致信号逐渐衰减。 为了解决这个问题,Sepp Hochreiter 和 JürgenSchmidhuber 在 1997 年提出采用长、短期记忆(LSTM)体系结构。 LTSM 算法被认为是针对时间序列分类和预测问题的最佳解决方案之一,对于重大事件,其在时间上是分开的,并在整个时间间隔上扩展。

LSTM 很难被称为神经元。 它已经是含有3 个输入通道和 3 个输出通道的神经网络。 仅使用两个通道(一个用于输入,另一个用于输出)与外界交换数据。 其余四个通道成对封闭,以便循环进行信息交换(记忆 和 隐藏状态)。
LSTM 模块包含两个主要数据流,这些数据流由 4 个完全连接神经层互连。 所有神经层都包含相同数量的神经元,等于输出流和记忆流的大小。我们来更详尽地研究该算法。
记忆数据流随时间流逝存储和传输重要信息。 它首先用零值初始化,然后在神经网络操作期间填充。 这就好比人类一样,出生时没有知识,但贯穿一生都在学习。
隐藏状态流涉及随时间传输输出系统状态。 数据通道大小等于“记忆”数据通道。
输入数据和输出状态通道旨在与外界交换信息。
三个数据流被司馈到算法之中:
- 输入数据描述系统的当前状态。
- 记忆和隐藏状态接收上一个状态。
在算法伊始,来自输入数据和隐藏状态的信息被组合到单一的数据数组当中,然后被司馈到 LSTM 的所有 4 个隐藏神经层。
第一个神经层,“遗忘门户”,判定哪些接收到的记忆数据可以遗忘,以及哪些应当记住。 它在实现的时候,作为一个含有希格玛型激活函数的完全连接神经层。 神经层中的神经元数量与“记忆”流中的记忆单元数量相对应。 神经层的每个神经元在输入处接收输入数据和隐藏状态流的整个数组,并输出从 0(彻底遗忘)到 1 (保存记忆)范围内的数字。 神经层输出数据的元素与记忆流相乘,并返回校正后的记忆。
在下一步,算法判定在此步当中获得的哪些数据应保留记忆。 以下两个神经层用于此目的:
- 新内容 — 含有双曲正切作为激活函数的完全连接神经层。 它将接收到的信息规范化为 -1 到 1。
- 输入门户 — 含有希格玛形作为激活函数的完全连接神经层。 它类似于“遗忘门户”,并判定要记忆的新数据。
新内容的元素和输入门户相乘,并添加到记忆单元值之中。 这些操作的结果是,我们得到了更新后的记忆状态,然后将其输入到下一个迭代周期。
更新记忆后,应生成输出流的值。 在此,与“遗忘门户”和“输入门户”相似,计算“输出门户”,利用双曲正切对当前记忆值进行常规化。 两个收到的数据集合元素与输出信号数组相乘,该数组来自 LSTM,并输出到外界。 相同的数据数组作为隐藏状态流被传递到下一个迭代循环。
2. 循环网络训练原则
循环神经网络遵循已经众所周知的反向传播方法进行训练。 与卷积神经网络的训练类似,该过程的周期性质在时间上被分解为多层感知器。 这种感知器中的每个时间间隔都充当一个隐藏层。 然而,这种感知器的所有层都使用一个权重矩阵。 因此,为了调整权重,取所有层的梯度总和,然后为所有层的总梯度一次性计算权重增量。

3. 构建一个循环神经网络
我们将采用 LSTM 模块来构建我们的循环神经网络。 我们从创建 CNeuronLSTM 类开始。 为了保留上一篇文章中创建的类继承结构,我们将创建新类作为 CNeuronProof 类的继承者。
class CNeuronLSTM : public CNeuronProof { protected: CLayer *ForgetGate; CLayer *InputGate; CLayer *OutputGate; CLayer *NewContent; CArrayDouble *Memory; CArrayDouble *Input; CArrayDouble *InputGradient; //--- virtual bool feedForward(CLayer *prevLayer); virtual bool calcHiddenGradients(CLayer *&nextLayer); virtual bool updateInputWeights(CLayer *&prevLayer); virtual bool updateInputWeights(CLayer *gate, CArrayDouble *input_data); virtual bool InitLayer(CLayer *layer, int numOutputs, int numOutputs); virtual CArrayDouble *CalculateGate(CLayer *gate, CArrayDouble *sequence); public: CNeuronLSTM(void); ~CNeuronLSTM(void); virtual bool Init(uint numOutputs,uint myIndex,int window, int step, int units_count); //--- virtual CLayer *getOutputLayer(void) { return OutputLayer; } virtual bool calcInputGradients(CLayer *prevLayer) ; virtual bool calcInputGradients(CNeuronBase *prevNeuron, uint index) ; //--- methods for working with files virtual bool Save( int const file_handle); virtual bool Load( int const file_handle); virtual int Type(void) const { return defNeuronLSTM; } };
父类包含一层输出神经元 OutputLayer 。 我们添加算法操作所需的 4 个神经层: ForgetGate , InputGate , OutputGate 和 NewContent 。 还有,添加 3 个数组来存储“记忆”数据,以便合并输入数据和隐藏状态,以及输入数据的误差梯度。 类方法的名称和功能与早前曾研究过的名称和功能相对应。 然而,它们的代码在算法操作需求方面有一些差异。 我们来更详尽地研究主要方法。
3.1. 类的初始化方法。
类的初始化方法从参数里接收有关正要被创建的模块基本信息。 方法参数名称都是从基类继承而来的,但其中一些现已拥有不同的含义:
- numOutputs — 传出连接数。 当完全连接层位于 LSTM 模块层之后时,将使用它们。
- myIndex — 神经元在神经层中的索引。 用于模块识别。
- window — 输入数据通道大小。
- step — 未用。
- units_count — 输出通道的宽度,和模块隐藏层中神经元的数量。 一个模块的所有神经层都包含相同数量的神经元。
bool CNeuronLSTM::Init(uint numOutputs,uint myIndex,int window,int step,int units_count) { if(units_count<=0) return false; //--- Init Layers if(!CNeuronProof::Init(numOutputs,myIndex,window,step,units_count)) return false; if(!InitLayer(ForgetGate,units_count,window+units_count)) return false; if(!InitLayer(InputGate,units_count,window+units_count)) return false; if(!InitLayer(OutputGate,units_count,window+units_count)) return false; if(!InitLayer(NewContent,units_count,window+units_count)) return false; if(!Memory.Reserve(units_count)) return false; for(int i=0; i<units_count; i++) if(!Memory.Add(0)) return false; //--- return true; }
在方法内部,我们首先检查模块每个神经层是否至少创建了一个神经元。 然后我们调用基类的相应方法。 成功完成该方法后,针对模块的隐藏层进行初始化,同时在单独的方法 InitLayer 中针对每一层进行重复的操作。 一旦神经层的初始化完成,则以零值初始化记忆数组。
InitLayer 神经层初始化方法从参数里接收指向已初始化神经层对象的指针,该层中神经元的数量和输出连接的数量。 在方法开始时,检查所接收指针的有效性。 如果指针无效,则新创建一个神经层类的实例。 如果指针有效,则清除神经元的层。
bool CNeuronLSTM::InitLayer(CLayer *layer,int numUnits, int numOutputs) { if(CheckPointer(layer)==POINTER_INVALID) { layer=new CLayer(numOutputs); if(CheckPointer(layer)==POINTER_INVALID) return false; } else layer.Clear();
用所需数量的神经元填充该层。 如果在方法的任何阶段发生了错误,则以 false 结果退出函数。
if(!layer.Reserve(numUnits)) return false; //--- CNeuron *temp; for(int i=0; i<numUnits; i++) { temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Init(numOutputs+1,i)) return false; if(!layer.Add(temp)) return false; } //--- return true; }
成功完成所有迭代后,以 true 结果退出该方法。
3.2. 前馈。
前馈传递是通过 feedForward 方法实现的。 该方法在参数中接收指向之前神经层的指针。 在方法开始时,检查接收到的指针的有效性,以及前一层中神经元的可用性。 还要检查输入数据中数组的有效性。 如果尚未创建该对象,则创建该类的新实例。 如果对象已存在,则清除数组。
bool CNeuronLSTM::feedForward(CLayer *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID || prevLayer.Total()<=0) return false; CNeuronBase *temp; CConnection *temp_con; if(CheckPointer(Input)==POINTER_INVALID) { Input=new CArrayDouble(); if(CheckPointer(Input)==POINTER_INVALID) return false; } else Input.Clear();
接下来,将有关当前系统状态的数据和有关之前时间间隔状态的数据合并到单一输入数据数组 Input 之中。
int total=prevLayer.Total(); if(!Input.Reserve(total+OutputLayer.Total())) return false; for(int i=0; i<total; i++) { temp=prevLayer.At(i); if(CheckPointer(temp)==POINTER_INVALID || !Input.Add(temp.getOutputVal())) return false; } total=OutputLayer.Total(); for(int i=0; i<total; i++) { temp=OutputLayer.At(i); if(CheckPointer(temp)==POINTER_INVALID || !Input.Add(temp.getOutputVal())) return false; } int total_data=Input.Total();
计算门户的值。 与初始化类似,将对每个门户的重复操作移到单独的 CalculateGate 方法当中。 此处调用该方法,在其中输入指向已处理门户的指针,并初始化数据数组。
//--- Calculated forget gate CArrayDouble *forget_gate=CalculateGate(ForgetGate,Input); if(CheckPointer(forget_gate)==POINTER_INVALID) return false; //--- Calculated input gate CArrayDouble *input_gate=CalculateGate(InputGate,Input); if(CheckPointer(input_gate)==POINTER_INVALID) return false; //--- Calculated output gate CArrayDouble *output_gate=CalculateGate(OutputGate,Input); if(CheckPointer(output_gate)==POINTER_INVALID) return false;
计算并常规化传入的数据,并保存到 new_content 数组当中。
//--- Calculated new content CArrayDouble *new_content=new CArrayDouble(); if(CheckPointer(new_content)==POINTER_INVALID) return false; total=NewContent.Total(); for(int i=0; i<total; i++) { temp=NewContent.At(i); if(CheckPointer(temp)==POINTER_INVALID) return false; double val=0; for(int c=0; c<total_data; c++) { temp_con=temp.Connections.At(c); if(CheckPointer(temp_con)==POINTER_INVALID) return false; val+=temp_con.weight*Input.At(c); } val=TanhFunction(val); temp.setOutputVal(val); if(!new_content.Add(val)) return false; }
最后,在所有中间计算完毕之后,计算“记忆”数组,并确定输出数据。
//--- Calculated output sequences for(int i=0; i<total; i++) { double value=Memory.At(i)*forget_gate.At(i)+new_content.At(i)*input_gate.At(i); if(!Memory.Update(i,value)) return false; temp=OutputLayer.At(i); value=TanhFunction(value)*output_gate.At(i); temp.setOutputVal(value); }
然后,删除中间数据数组,并以 true 退出该方法。
delete forget_gate; delete input_gate; delete new_content; delete output_gate; //--- return true; }
在上述 CalculateGate 方法之中,权重矩阵乘以初始数据向量,然后通过希格玛型激活函数对数据进行常规化。 该方法在参数中接收 2 个指向神经层对象和原始数据序列的指针。 首先,检查所接收指针的有效性。
CArrayDouble *CNeuronLSTM::CalculateGate(CLayer *gate,CArrayDouble *sequence)
{
CNeuronBase *temp;
CConnection *temp_con;
CArrayDouble *result=new CArrayDouble();
if(CheckPointer(gate)==POINTER_INVALID)
return NULL;
接下来,实现循环遍历所有神经元。
int total=gate.Total(); int total_data=sequence.Total(); for(int i=0; i<total; i++) { temp=gate.At(i); if(CheckPointer(temp)==POINTER_INVALID) { delete result; return NULL; }
检查神经元对象指针的有效性之后,实现嵌套循环遍历神经元的所有权重,同时计算初始数据数组中相应元素的权重乘积之和。
double val=0; for(int c=0; c<total_data; c++) { temp_con=temp.Connections.At(c); if(CheckPointer(temp_con)==POINTER_INVALID) { delete result; return NULL; } val+=temp_con.weight*(sequence.At(c)==DBL_MAX ? 1 : sequence.At(c)); }
生成的乘积之和通过激活函数来传递。 结果被写入神经元输出,并添加到数组当中。 成功遍历神经层中所有神经元后,退出该方法并返回结果数组。 如果在任何计算阶段发生错误,则该方法将返回一个空值。
val=SigmoidFunction(val); temp.setOutputVal(val); if(!result.Add(val)) { delete result; return NULL; } } //--- return result; }
3.3. 误差梯度计算。
误差梯度是由 calcHiddenGradients 方法计算的,该方法接收一个指向参数中下一层神经元的指针。 在方法伊始,检查先前所创建对象的相关性,该对象用于将误差梯度序列存储到原始数据。 如果对象尚未创建,则创建一个新实例。 如果对象已存在,则清除数组。 此外,声明内部变量和类实例。
bool CNeuronLSTM::calcHiddenGradients(CLayer *&nextLayer) { if(CheckPointer(InputGradient)==POINTER_INVALID) { InputGradient=new CArrayDouble(); if(CheckPointer(InputGradient)==POINTER_INVALID) return false; } else InputGradient.Clear(); //--- int total=OutputLayer.Total(); CNeuron *temp; CArrayDouble *MemoryGradient=new CArrayDouble(); CNeuron *gate; CConnection *con;
接下来,计算来自下一个神经层之神经元输出层的误差梯度。
for(int i=0; i<total; i++) { temp=OutputLayer.At(i); if(CheckPointer(temp)==POINTER_INVALID) return false; temp.setGradient(temp.sumDOW(nextLayer)); }
将得到的梯度扩散到 LSTM 的所有内部神经层。
if(CheckPointer(MemoryGradient)==POINTER_INVALID) return false; if(!MemoryGradient.Reserve(total)) return false; for(int i=0; i<total; i++) { temp=OutputLayer.At(i); gate=OutputGate.At(i); if(CheckPointer(gate)==POINTER_INVALID) return false; double value=temp.getGradient()*gate.getOutputVal(); value=TanhFunctionDerivative(Memory.At(i))*value; if(i>=MemoryGradient.Total()) { if(!MemoryGradient.Add(value)) return false; } else { value=MemoryGradient.At(i)+value; if(!MemoryGradient.Update(i,value)) return false; } gate.setGradient(gate.getOutputVal()!=0 && temp.getGradient()!=0 ? temp.getGradient()*temp.getOutputVal()*SigmoidFunctionDerivative(gate.getOutputVal())/gate.getOutputVal() : 0); //--- Calcculated gates and new content gradients gate=ForgetGate.At(i); if(CheckPointer(gate)==POINTER_INVALID) return false; gate.setGradient(gate.getOutputVal()!=0 && value!=0? value*SigmoidFunctionDerivative(gate.getOutputVal()) : 0); gate=InputGate.At(i); temp=NewContent.At(i); if(CheckPointer(gate)==POINTER_INVALID) return false; gate.setGradient(gate.getOutputVal()!=0 && value!=0 ? value*temp.getOutputVal()*SigmoidFunctionDerivative(gate.getOutputVal()) : 0); temp.setGradient(temp.getOutputVal()!=0 && value!=0 ? value*gate.getOutputVal()*TanhFunctionDerivative(temp.getOutputVal()) : 0); }
内部神经层的梯度计算完毕之后,计算初始数据序列的误差梯度。
//--- Calculated input gradients int total_inp=temp.getConnections().Total(); for(int n=0; n<total_inp; n++) { double value=0; for(int i=0; i<total; i++) { temp=ForgetGate.At(i); con=temp.getConnections().At(n); value+=temp.getGradient()*con.weight; //--- temp=InputGate.At(i); con=temp.getConnections().At(n); value+=temp.getGradient()*con.weight; //--- temp=OutputGate.At(i); con=temp.getConnections().At(n); value+=temp.getGradient()*con.weight; //--- temp=NewContent.At(i); con=temp.getConnections().At(n); value+=temp.getGradient()*con.weight; } if(InputGradient.Total()>=n) { if(!InputGradient.Add(value)) return false; } else if(!InputGradient.Update(n,value)) return false; }
所有梯度计算完毕之后,删除不必要的对象,并以 true 退出方法。
delete MemoryGradient; //--- return true; }
请注意以下几点:在理论部分,我提到需要及时展开序列,并计算每个时间阶段的误差梯度。 此处尚未完成此操作,因为所用训练系数远小于 1,且之前时间间隔的误差梯度影响会非常小,以至于可以忽略,从而提高算法的整体性能。
3.4. 更新权重。
自然,得到误差梯度后,我们需要调整所有 LSTM 神经层的权重。 此任务是在 updateInputWeights 方法里实现的,该方法在参数中接收指向之前神经层的指针。 请注意,输入指向上一层的指针仅用于保留继承结构。
在方法伊始,检查所接收指针的有效性,并初始数据数组。 指针成功验证后,继续调整内部神经层的权重。 同样,重复操作被移到单独的 updateInputWeights 方法中,我们将在参数里传递特定神经层和初始数据数组的指针。 在此,针对每个神经层依次调用辅助方法。
bool CNeuronLSTM::updateInputWeights(CLayer *&prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID || CheckPointer(Input)==POINTER_INVALID) return false; //--- if(!updateInputWeights(ForgetGate,Input) || !updateInputWeights(InputGate,Input) || !updateInputWeights(OutputGate,Input) || !updateInputWeights(NewContent,Input)) { return false; } //--- return true; }
我们来研究在 updateInputWeights(CLayer *gate,CArrayDouble *input_data) 方法里执行的操作。 在方法伊始,检查从参数中接收到的指针有效性,并声明内部变量。
bool CNeuronLSTM::updateInputWeights(CLayer *gate,CArrayDouble *input_data) { if(CheckPointer(gate)==POINTER_INVALID || CheckPointer(input_data)==POINTER_INVALID) return false; CNeuronBase *neuron; CConnection *con; int total_n=gate.Total(); int total_data=input_data.Total();
安排嵌套循环遍历神经层中的所有神经元和神经元的权重,并调整权重矩阵。 权重调整公式与之前在 CNeuron::updateInputWeights(CArrayObj *&prevLayer) 中曾研究过的公式相同。然而,我们不能在此采用先前创建的方法,因为那时候我们曾用神经元连接来与下一层连接,而现在它们则与上一层连接。
for(int n=0; n<total_n; n++) { neuron=gate.At(n); if(CheckPointer(neuron)==POINTER_INVALID) return false; for(int i=0; i<total_data; i++) { con=neuron.getConnections().At(i); if(CheckPointer(con)==POINTER_INVALID) return false; double data=input_data.At(i); con.weight+=con.deltaWeight=(neuron.getGradient()!=0 && data!=0 ? eta*neuron.getGradient()*(data!=DBL_MAX ? data : 1) : 0)+alpha*con.deltaWeight; } } //--- return true; }
更新权重矩阵后,以 true 退出方法。
类创建完毕之后,我们针对 NeuronBase 基类的调度进行一些小的调整,从而令其可以正确处理新类的实例。 附件中提供了所有方法和函数的完整代码。
4. 测试
最新创建的 LSTM 模块已进行了测试,条件与上一篇文章测试卷积网络的相同。 创建了 Fractal_LSTM 智能交易系统用来测试。 本质上,其与上一篇文章中的 Fractal_conv 相同。 但在 OnInit 函数中,在网络结构指定模块中,卷积层和子抽样层已替换为 4 个 LSTM 模块层(类似于卷积网络的 4 个过滤器)。
//--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=4; desc.type=defNeuronLSTM; desc.window=(int)HistoryBars*12; desc.step=(int)HistoryBars/2; if(!Topology.Add(desc)) return INIT_FAILED;
EA 代码未经其他修改。 在附件中可找到整个的 EA 代码和类。
当然,在每个 LSTM 模块中使用 4 个内部神经层,以及算法本身的复杂性都会影响性能,因此,这种神经网络的速度比之前所研究的卷积网络要低一些。 然而,循环网络的均方根误差要小得多。

在循环神经网络训练过程中,目标命中准确性图形具有明显的、几乎笔直的上升趋势。

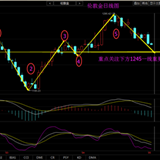
在价格图表上只能见到罕有的预测分形指针。 在之前测试里,价格图表全是预测标签。

结束语
在本文中,我们研究了循环神经网络的算法,构建了一个 LSTM 模块,并利用实际数据测试了所创建神经网络的操作。 与以前研究的神经网络类型相比,在前馈传递和学习过程中,循环网络的资源和工作量更多。 无论如何,它们展现出更好的结果,并由所进行的测试证实。
链接
- 神经网络变得轻松
- 神经网络变得轻松(第二部分):网络训练和测试
- 神经网络变得轻松(第三部分):卷积网络
- 理解 LSTM 网络
本文中用到的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Fractal.mq5 | 智能交易系统 | 一款含有回归神经网络(输出层中有 1 个神经元)的智能交易系统 |
| 2 | Fractal_2.mq5 | 智能交易系统 | 一款含有分类神经网络的智能交易系统(输出层中有 3 个神经元) |
| 3 | NeuroNet.mqh | 类库 | 创建神经网络(感知器)的类库 |
| 4 | ractal_conv.mq5 | 智能交易系统 | 含有卷积神经网络(输出层中 3 个神经元)的神经智能交易系统 |
| 5 | Fractal_LSTM.mq5 | 智能交易系统 | 含有循环神经网络的智能交易系统(输出层中有 3 个神经元) |