简介
通常,电子表格指的是表格处理程序(存储和处理数据的应用程序),例如 EXCEL。尽管文中显示的代码不是那么强大,它可以用作表格处理程序的全功能实现的一个基类。我不是要使用 MQL5 创建 MS Excel,我希望实现一个类,以便在二维数组中操作不同类型的数据。
尽管我实现的类在性能上无法比拟单一类型数据的二维数组(可直接访问数据),但该类的出现是为了方便使用。此外,该类可视作以 C++ 实施的 Variant 类,作为表格简化为一列的特殊情况。
对于迫不及待的读者和想要跳过实施的算法分析的读者,我将从可用方法开始 CTable 类的介绍。
1. 类的方法的说明
首先,我们考虑类的可用方法,让我们从更细节的层面了解它们的目的和使用原则。
1.1. FirstResize
表格布局,列类型的描述,TYPE[] - ENUM_DATATYPE 类型数组,它确定行的大小和单元格类型。
void FirstResize(const ENUM_DATATYPE &TYPE[]);
实际上,该类是具有一个参数的另一个构造函数。这很方便,原因有两个:首先,它解决了在构造函数内部传递参数的问题;其次,它提供了将对象作为参数传递,然后执行必要的数组划分的可能性。此功能允许将类作为 C++ 中的 Variant 类使用。
实施的特殊性包括:虽然函数设置了第一个维度和列的数据类型,它不需要将第一个维度的大小作为参数指定。此参数取自传递的数组 TYPE 的大小。
1.2. SecondResize
将行数更改为 "j"。
void SecondResize(int j);
函数为第二个维度的所有数组设置了一个指定的大小。因此,我们可以说它增加了表格的行数。
1.3. FirstSize
该方法返回第一个维度的大小(行的长度)。
int FirstSize();
1.4. SecondSize
该方法返回第二个维度的大小(列的长度)。
int SecondSize();1.5. PruningTable
它为第一个维度设置新的大小;此改变在初始大小的范围内是可能的。
void PruningTable(int count);
实际上,函数并未改变行的长度;它只是改写了一个变量的值,该变量用于存储行的长度的值。该类包含另一个变量,用于存储在表格初始划分时设置的分配内存的实际大小。在该变量的值的范围内,虚拟改变第一个维度的大小是可能的。当复制一个表格到另一个表格时,该函数可删去不需要的部分。
1.6. CopyTable
将一个表格的第二个维度的整个长度复制到另一个表格的方法:
void CopyTable(CTable *sor);该函数将一个表格复制到另一个表格。它启动接收表格的初始化,可用作另一个构造函数。排序变体的内部结构并未复制,只是从初始表格复制了大小、列的类型以及数据。函数将 CTable 类型的复制对象的引用作为一个参数接收,该参数由 GetPointer 函数传递。
复制一个表格到另一个表格时,一个新的表格根据 "sor" 示例创建。
void CopyTable(CTable *sor,int sec_beg,int sec_end);
使用其他参数覆盖上述函数:sec_beg - 复制初始表格的起点,sec_end - 复制的终点(请不要与复制的数据量混淆)。两个参数均针对第二个维度。数据将添加至接收表格的起始处。接收表格的大小设置为 sec_end-sec_beg+1。
1.7. TypeTable
返回第 "i" 列的 type_table 值(ENUM_DATATYPE 类型)。
ENUM_DATATYPE TypeTable(int i)
1.8. Change
Change() 方法执行列的交换。
bool Change(int &sor0,int &sor1);
正如上文所述,该类交换列(操作第一个维度)。由于信息并未实际移动,该函数的操作速度不会受第二个维度的大小的影响。
1.9. Insert
此插入方法在指定位置插入列,
bool Insert(int rec,int sor);
该函数与上面介绍的函数相同,除了它基于指定列应移至的位置执行其他列的移动。参数 "rec" 指定列应移至的位置,"sor" 指定列将移出的位置。
1.10. Variant/VariantCopy
接下来是 "varian" 系列的三个函数。表格处理的变体的识记在类中实现。
变体起到类似笔记本的提醒作用。例如,如果您按第三列执行排序,而您不希望在下次处理时重置数据,您应切换变体。要访问处理的上个变体,调用 "variant" 函数。如果下次处理应基于上次处理的结果,您应复制变体。默认情况下,设置编号为 0 的变体。
设置变体(如果没有这样的变体,将创建该变体以及所有缺失的变体直到 "ind")和获取活动变体。"variantcopy" 方法将 "sor" 变体复制到 "rec" 变体。
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
variant(int ind) 方法切换所选变体。执行自动内存分配。如果指定的参数少于上次指定的参数个数,将不会重新分配内存。
variantcopy 方法允许复制 "sor" 变体到 "rec" 变体。该函数被创建用于安排变体。如果 "rec" 变体不存在,它自动增加变体的数目,并且切换至新复制的变体。
1.11. SortTwoDimArray
SortTwoDimArray 方法按选定的行 "i" 排序表格。
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
按指定列排序表格的功能。参数:i - 列,beg - 排序起点,end - 排序终点(包含),mode - 布尔变量,确定排序方向。如果 mode=true,它表示值随索引增大而增大("false" 是默认值,因为索引从表的顶部到底部逐渐增大)。
1.12. QuickSearch
该方法按与 "element" 模式相等的值在数组中快速搜索元素的位置。
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
在排序数组中搜索与模式相等的第一个元素。返回与 "element" 模式相等的第一个值的索引。有必要指定在此范围早前执行的排序类型(如果没有这样的元素,则返回 -1)。
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
在排序数组中搜索与模式相等的最后一个元素。
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
在排序数组中搜索大于模式的最接近的元素。
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
在排序数组中搜索小于模式的最接近的元素。
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
Set 和 Get 函数具有空类型;它们被表格使用的四种数据类型所覆盖。该函数识别数据类型,如果 "value" 参数不符合列类型,将显示一则警告消息且不会进行分配。唯一的例外是字符串类型。如果输入参数为字符串类型,它将被转换为列类型。该例外在不可能设置一个接收单元格的值的变量时,为使传输信息更加方便而量身定做。
设置值的方法(i - 第一个维度的索引,j - 第二个维度的索引)。
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
获取值的方法(i - 第一个维度的索引,j - 第二个维度的索引)。
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
从第 "j" 列第 "i" 行获取字符串类型的值。
string sGet(int i,int j); // return value of the i-th row and j-th column
Get 系列的唯一函数通过 "return" 运算符而不是参数变量返回值。返回一个字符串类型的值(不考虑列类型)。
1.20. StringDigits
当类型转换为“字符串”,您可以通过函数使用精度设置:
void StringDigits(int i,int digits);
来设置“双精度”的精度,以及
int StringDigits(int i);
设置在“日期时间”中显示秒数的精度;任何不等于 -1 的值都通过。指定的值为列而记忆,因此您不必每次在显示信息时指出值。您可以多次设定精度,因为该信息存储在原始类型中,并只在输出期间转换为指定的精度。精度值不会在复制时存储,因此,当复制表格至新的表格时,新表格的列的精度将与默认精度相符。
1.21. 使用示例:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
操作结果是打印单元格 (2;0) 的内容。读者可能已注意到,复制数据的精度不会超出初始表格的精度。
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
现在,我们开始算法本身的说明。
2. 选择模型
有两种方式组织信息:连接列方案(本文所实施的结构)及其呈连接行形式的替代选择如下所示。
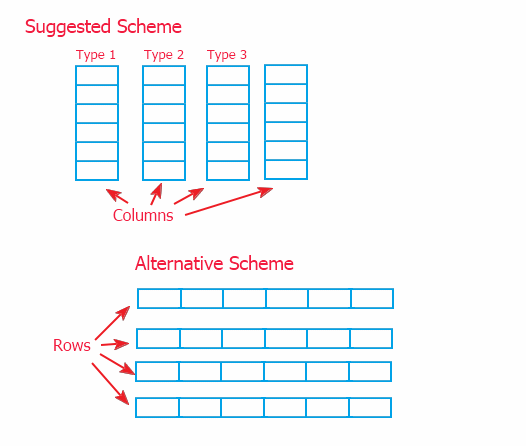
由于通过一个中间物引用信息(在 p. 2 中说明),上范围的实施没有太大的差异。但我选择列模型,因为它允许在存储数据的对象中的下范围上实施数据方法。而替代方案可能要求覆盖用于在上类 CTable 中处理信息的方法。并且这会使类的增强复杂化(如果必要的话)。
因此,两种方案都可使用。建议的方案允许快速移动数据,而替代方案可更快地添加数据(因为信息往往是逐行添加至表格)和获取行。
还有另一种安排表格的方式 - 结构数组。虽然它最容易实现,但却有一个重大缺陷。结构必须由程序表说明。因此,我们失去了通过自定义参数设置表格属性的机会(无需更改源代码)。
3. 在动态数组中统一数据
要获得在单一动态数组中统一不同类型数据的可能性,我们需要解决向数组单元格分配不同类型数据的问题。该问题已通过标准库的连接列表解决。我的第一个开发基于类的标准库。但在项目的开发期间,我发现需要对 CObject 基类进行大量更改。
这就是我决定开发自己的类的原因。对于那些不熟悉标准库的读者,我将解释刚才提到的问题是如何解决的。要解决该问题,您需要用到继承机制。
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
看上去,继承机制的示意图就像一把梳子:

如果声明了类的动态对象的创建,这意味着基类的构造函数将被调用。正是该属性使得在两个步骤内创建对象成为可能。随着基类的虚拟函数被覆盖,我们获得从派生类通过不同类型的参数调用该函数的可能性。
为什么简单的覆盖还不够?问题是执行的函数很大,因此,如果我们在基类中(而不使用继承)说明它们的主体,则未使用的函数和主体的完整代码将为二进制代码中的每个对象创建。而使用继承机制时,占用的内存相较填入代码的函数要少得多的空函数将被创建。
4. 操作数组
令我拒绝使用标准类的主要和次要原因是对数据的引用。我通过一个中间索引数组对数组单元格进行间接引用,而不是通过单元格的索引进行引用。相比通过一个变量使用直接引用,它规定了一个较慢的工作速度。事实是,指示索引的变量工作速度要快于数组单元格,后者首先需要在内存中将其找到。
我们来分析一下一维数组和多维数组排序的本质区别。排序前,一维数组的元素具有随机位置,排序后元素按顺序排列。当排序二维数组时,我们不需要对整个数组进行排序,只需要按照它的一列执行排序。所有的行必须改变它们的位置以保持其结构。
在这里,行本身是包含不同类型数据的绑定结构。要解决这个问题,我们需要在所选数组中排序数据以及保存初始索引的结构。通过这种方式,如果我们知道哪一行包含单元格,我们可以显示整行。因此,在排序二维数组时,我们需要获得排序数组的索引数组而不改变数据的结构。
例如:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
因此,我们获得了按照交易品种、建仓日期、盈利等排序信息的可能性。
已有大量的排序算法被开发出来。这些算法中的最佳变体是稳定排序算法。
标准类中使用的快速排序算法指的是不稳定的排序算法。这就是它不适合我们的经典实现的原因。但即便将快速排序以稳定的形式(需额外的数据复制和索引数组排序)引入,快速排序看起来也比冒泡排序(最快的稳定排序算法之一)要快。该算法非常快速,但它使用递归。
这就是我处理字符串数组类型(它需要更多的堆栈内存)时使用鸡尾酒排序(双向的冒泡排序)的原因。
5. 排列二维数组
我要讨论的最后一个问题是动态二维数组的排列。对于这样的排列,通过将一维数组包装成类,然后通过指针数组调用对象数组即已足够。换言之,我们需要创建和排列数组。
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. 程序结构
CTable 类的代码使用(使用伪模板替代 C++ 模板)一文中介绍的模板编写。正是因为使用了模板,我才可以如此快速地编写这么一大段代码。这也是我不打算详细说明整段代码的原因;此外,算法的大部分代码都是对标准类的修改。
我准备向大家介绍类的基本结构以及函数的一些有趣特性,以清楚说明几个重点内容。

结构图的右侧部分主要被位于派生类 CLONGArray、CDOUBLEArray、CDATETIMEArray 和 CSTRINGArray 中的覆盖方法所占据。它们中的每一个(私有区段中)都包含一个对应类型的数组。这些数组用于访问信息的所有技巧。上面列示的类方法的名称与公共方法相同。
基类 CBASEArray 通过覆盖虚拟方法填入,并只有在 CTable 类的私有区段中声明 CBASEArray 对象的动态数组时才是必要的。CBASEArray 指针数组作为动态对象的动态数组声明。最终构建对象和选择必要实例的工作在 FirstResize() 函数中完成。这些工作也可以在 CopyTable() 函数中完成,因为该函数在其主体中调用 FirstResize()。
CTable 类还执行数据处理方法(位于 CTable 类的实例中)和控制 Cint2D 类的索引的对象的协调。整个协调包装在覆盖公共方法中。
CTable 类中频繁重复的覆盖部分使用定义代替,以避免生成过于冗长的代码:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
因此,更简洁形式的部分:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
将被预处理程序的下述代码行所取代:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
在上述示例中,数据处理方法是如何调用的一目了然("return" 中的部分)。
我已经提到过,CTable 类在处理过程中并不执行数据的实际移动;它只是改变索引对象中的值。要为数据处理方法提供与索引对象交互的可能性,将其作为 array_index 参数传递至所有处理函数。
array_index 对象存储第二个维度的元素的位置关系。第一个维度的索引编排由在 CTable 类的私有区段中声明的 aic[] 动态数组完成。它提供了改变列的位置的可能性(当然,不是实际移动,而是通过索引)。
例如,在执行 Change() 操作时,仅两个包含列的索引的内存单元改变它们的位置。虽然看起来像是移动两个列。CTable 类的函数在文档中已有了详实的说明(有些甚至是逐行说明)。
现在,我们转到继承自 CBASEArray 的类的函数。实际上,这些类的算法是取自标准类的算法。我采用标准名称来标示它们。修改包括使用索引数组间接返回值,这与标准算法不同,后者是直接返回值。
首先,我们对快速排序进行修改。由于该算法来自不稳定排序类别,在开始排序前,我们需要对传递至算法的数据进行备份。我还根据数据的更改模式添加了索引对象的同步性修改。
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
该排序算法的部分代码如下:
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
在原来的算法中,没有 Cint2D 类的实例。我们对其他标准算法也做了类似的改变。我不打算说明所有代码的模板。如果有读者希望改进代码,他们可以通过用模板代替真实类型从真实代码获得一个模板。
至于编写模板,我使用的是处理长类型的类代码。在这种经济型算法中,开发人员尝试避免对整数的不必要使用,如果存在使用 int 的可能性的话。这就是长类型变量最有可能成为覆盖参数的原因。使用模板时,它们被 "templat" 代替。
总结
我希望本文能够成为编程新人学习面向对象方法的好帮手,并使得处理信息变得更加容易。CTable 类可能成为很多复杂应用的基类。本文介绍的方法可以成为开发种类繁多的解决方案类的基础,因为它们实现了处理数据的一般方法。
此外,本文证明了滥用 MQL5 是毫无根据的。您想要使用变体类型?在这里,它就是使用 MQL5 实现的。因此,完全没有必要改变标准和削弱语言的安全性。祝您好运!