前兩篇文章給大家聊了聊單因子的一些測試工具,那麼有了工具我們就可以運用一下,實際的來測試一些因子,分析一下我們通過工具得出的結果是怎麼樣的。 本文思路主要參考《華泰金工多因子模型》以及《光大多因子系列報告》 多因子模型本質上是將對N只股票的收益-風險預測轉變成對K個因子的收益-風險預測,將估算個股收益率的協方差矩陣轉化為估算因子收益率協方差矩陣,極大地降低了預測工作量,提高了準確度。 多因子模型主要的有三種:
宏觀因子模型:使用宏觀經濟數據序列,如通脹率,利率等作為指標,反應股票市場和外部經濟之間的關聯性,並據此做出預測。
基本面因子模型:使用可觀察到的股票自身的基本屬性,如估值水平、成長性、換手率等等,作為股票市場收益率變動的主要解釋變量,其中一般歸納為基本面類、估值類、市場類。
統計因子模型:從股票收益率的協方差矩陣中提取統計因子,作為股票市場收益率變動的主要解釋變量,常見的統計分析方法有主成分分析法、最大似然分析和預期最大化分析等。
這其中效果較好的是基本面模型,在實際應用中,應注意基本面指標與收益率之間的經濟邏輯是否與模型結果一致,以做出正確的判斷。
本文通過幾個基本面的因子,來闡述該方法的流程和其中的一些細節處理。
方法論:
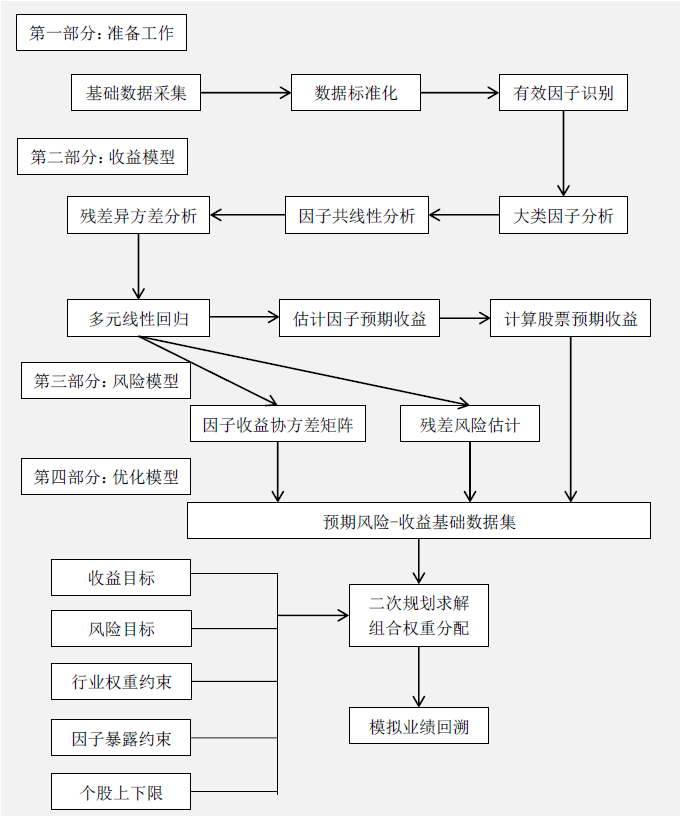
首先是因子:
價值因子:
EP:淨利潤(TTM,過去12個月)/總市值
BP:淨資產/總市值
SP:營業收入/總市值
NCFP:淨現金流/總市值
OCFP:經營性現金流/總市值
財務質量因子:
roe_ttm :淨資產收益率
roa_ttm :資產收益率
grossprofitmargin_ttm :毛利率
profit_margin :扣非後利潤率
operationcashflowratio:經營性現金流/淨利潤
assetturnover : 資產周轉率
成長因子:
sales_growth:營收增長率
net_profit_growth:淨利潤增長率同比
動量因子:
return_1m :近n月收益率
return_3m
return_6m
return_12m
wgt_return_1m :近n月以日換手率作為權重求得每日收益率的算數平均值
wgt_return_3m
wgt_return_6m
取其中的一個因子數據來看一看標準化的效果:
處理前:
去極值後:
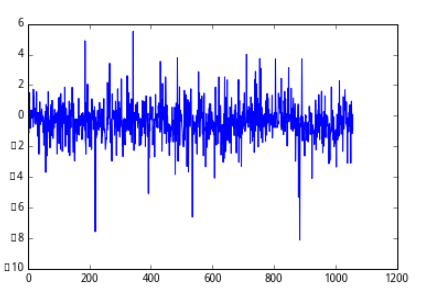
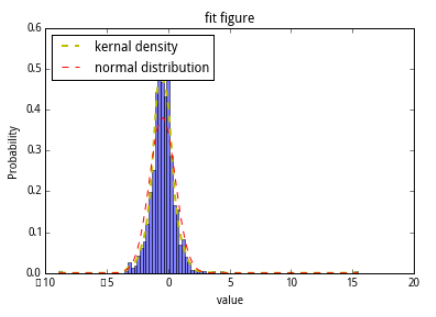
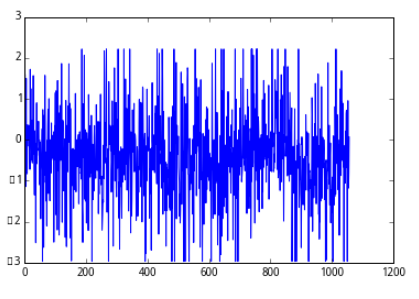

標準化處理(z-score)後:
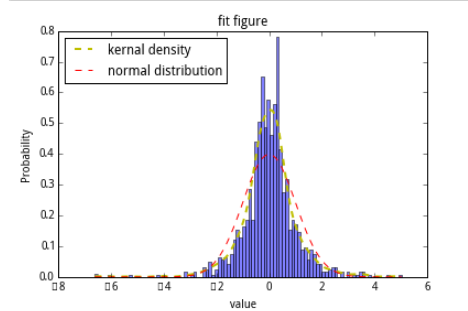
取其中一個因子做一下t值和IC值的分析: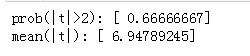

多重共線性的檢驗和消除:
計算各因子暴露之間的相關系數,對於相關系數較高的因子,可做以下處理:
1.根據有效性排序(IC,t),選取最有效因子保留
2.等權重*新因子,即將相關的因子都賦予等權重,假設有n個相關因子,則每個權重1/n,加和之後再做標準化處理。
3.曆史收益率權重*新因子,方法類似2,權重變為曆史收益率。
通常具有很高相關性的因子都是經濟意義上較為相近和有聯系的因子,我們可以做一些去除處理。
異方差檢驗和消除:
在回歸中為了保證回歸參數估計量有良好的統計性質,經典線性回歸中有一個重要的假設是:隨機誤差項滿足同方差性。 若不滿足同方差性,會使得回歸標準差的估計不再是無偏估計,從而使得OLS估計量不再有效,t統計量和F統計量不服從相應分布,故無法進行假設檢驗和區間估計。 通常經濟數據一般都很難滿足同方差的條件。
我們可以使用White檢驗法進行檢驗: 1.回歸得到OLS的殘差 2.用殘差項和自變量再次進行回歸,即檢查殘差項是否與自變量有關系。 3.構造LM統計量或F統計量,看第二次回歸的整體系數是否顯著不為0,如果顯著,則拒絕原假設(殘差項同方差),即原序列有異方差性。
消除異方差的方法我們在上一篇(《全面了解多因子系列入門(二)》)中已經做了詳細介紹(GLS)。
完成了這些工作之後我們就可以進行因子收益的回歸分析了,同樣是使用到多元線性回歸,估計每一期的因子收益(這里的因子收益即以因子暴露作為自變量,股票收益作為因變量,回歸得到的系數,描述了該因子對股票收益的貢獻)。
我們使用增加行業啞變量的回歸,能夠剔除不同行業之間差異的影響(或者在之前處理數據時進行行業中性化)
做了這麼多工作,其實我們想要做的事情和所有的投資者想做的事情一樣,那就是預測下一期的因子收益率(這樣我們才能“未卜先知”選擇那些因子表現好的股票嘛)
那麼估計因子預期收益也有一系列的方法:
1.曆史均值法:簡單地使用前N期的因子曆史收益率均值作為下一期的因子預期收益率(這不是假設未來永遠都是曆史的中庸水平嗎?感覺好像沒有卵用)
2.指數加權移動平均法(EWMA):該方法是將曆史對未來的影響賦予不同的權重,按照我們直觀的理解,越近的事件對下一期影響應該越大,越遠的影響應該會逐漸消失。
$r_{t+1}=\lambda *r_{t}+(1-\lambda )*r_{t-1}$
通過不斷迭代該式子以得到t+1時刻的因子收益率。
3.時間序列類模型:
AR(p) 、ARMA(p,q)等等做預測。
而對股票的收益預測時,則同樣使用到了多因子的回歸模型預測,帶入t+1時刻的因子收益和t時刻的因子暴露(研報的理解是在短時期內因子暴露不會產生較大的風格性變化,故可以使用本期因子暴露作為下一期因子暴露的預測),這樣就能得到股票的收益預測了。
進一步的,如果要構建策略的話,通過滾動的計算,在每一個調倉日獲得下一期股票收益的預測,買入預期高收益率的組合,賣空負收益率的組合。讀者可以自行嘗試後面的工作。
import pandas as pdimport numpy as npimport datetimeimport timefrom math import log,expimport matplotlib.pyplot as pltimport matplotlib.mlab as mlabimport statsmodels.api as smimport numpy as np np.set_pri*ptions(threshold=np.inf)
index = '000002.XSHG'#A股benchmark = '000300.XSHG'#滬深300#benchmark = '000016.XSHG'#上證50#benchmark = '000010.XSHG' #上證180
#過濾停牌 and ST股票def filterOfPauseAndST(stockList,startDate,endDate):import numpy as npunsuspendStock = []crew = get_price(stocklist, start_date=startDate, end_date=endDate, fields=['paused'])crew = crew.paused.Tcrew.rename(columns={crew.columns[0]:'paused'}, inplace=True)crew.dropna()pack = get_extras('is_st', stocklist, start_date=startDate, end_date=endDate, df=True)pack = pack.Tpack.rename(columns={pack.columns[0]:'is_st'}, inplace=True)unsuspended = crew[crew['paused']==0].indexunst = pack[pack['is_st']==False].indexfor stock in stockList:if (stock in unsuspended) and (stock in unst) :unsuspendStock.append(stock)return unsuspendStockdef DumVarM(stocklist,industry_index,date=None): a = map(get_industry_stocks,industry_index,[date]*len(industry_index))mix=[]for i in range(len(stocklist)):mix.append(map(lambda x: u[i] in x,a ))arr = mat(mix).astype('float64')return arrdef get_cap_factor(stocklist,date):q = query(valuation.market_cap).filter(valuation.code.in_(stocklist))#總市值版本#q = query(valuation.circulating_market_cap).filter(valuation.code.in_(stocklist)) #流通市值版本df = get_fundamentals(q,date)caplist = list(df['market_cap'].values)return caplist
#行業市值中性化#因子值對行業啞變量和市值對數進行回歸取殘差作為中性化後因子值def neutralization(stocks,factor,date):dumX = DumVarM(stocks,industry_index,date)capX = np.matrix(np.log(get_cap_factor(u,endDate))).TX_reg = np.column_stack((dumX,capX))model = sm.OLS(factor,X_reg).fit()res = model.residreturn res#返回的是一個(n,)的array,需要自行轉化為列向量
#MAD去極值,Z-Score標準化def standarize(factorlist):#中位數去極值copy1 = factorlist[:]sort1 = sorted(copy1)if len(sort1)%2 == 0:midd = (sort1[len(sort1)/2]+sort1[len(sort1)/2-1])/2else:midd = sort1[len(sort1)/2]a = [abs(x-midd) for x in copy1]sort2 = sorted(a) if len(sort2)%2 == 0:midd1 = (sort2[len(sort2)/2]+sort2[len(sort2)/2-1])/2else:midd1 = sort2[len(sort2)/2-1]for i,x in enumerate(copy1):if x>(midd+5*midd1):copy1[i] = midd+5*midd1elif x<midd-5*midd1:copy1[i] = midd-5*midd1return copy1
def z_score(factorlist):return map(lambda x:(x-np.mean(factorlist))/np.std(factorlist),factorlist)
# 輸入的stocks可以是單只股票或者股票列表# pointDate為計算收益率的當天# n為前n天收益率# 動量因子:return_1m,return_3m,return_6m,return_12m# n 取 30 90 180 360def calRN(stocks,pointDate,n):pastDate = pointDate - datetime.timedelta(days=n)price = get_price(stocks,start_date=pastDate,end_date=pointDate,fields='close')p = price.close.T.valuesret = p[:,-1]/p[:,0]-1ret = (ret+1)**(12/(n/30))-1ret = list(ret)return ret
def calWgt(stocks,pointDate,n):#這里多取前一天,因為求每日收益率第一行是nanpastDate = pointDate - datetime.timedelta(days=n+2)price = get_price(stocks,start_date=pastDate,end_date=pointDate,fields='close')a = price.closeb = price.close.shift(1)ret = a/b-1retlist = ret.dropna().T.valuesretlist = retlist*365#由於聚寬數據結構的原因fundamentals一次只能取一天的數據,這里只能用循環,速度較慢date = pointDateq = query( valuation.turnover_ratio ).filter(valuation.code.in_(stocks))temp = []for i in range(n+1):flag = get_price(stocks,start_date=datetime.datetime.strftime(date,"%Y-%m-%d"),end_date=datetime.datetime.strftime(date,"%Y-%m-%d"),fields='close')if len(flag.close)!=0:temp.append(get_fundamentals(q,date).values)else:passdate = date - datetime.timedelta(days=1)#temp是所有換手率的原始數據,其中每個元素是30天中一天的1057只股票換手率的array#total分別計算了1057只股票的過去一個月總換手率total=[]sums=0for j in range(len(stocks)):for i in range(len(temp)):sums = sums+temp[i][j][0]+0.000000000000000000000000000000000001#防止有的總換手率為0,做分母時會出現nan值total.append(sums)sums=0#權重矩陣:#行為股票,1057只,列為天數,0為當前天,29為30天前#其中是換手率權重#如 weight[35,10]代表u中第36只股票在11天前換手率占上月換手率的比重weight=mat(zeros((len(stocks),len(temp))))for j in range(len(stocks)):for i in range(len(temp)):weight[j,i]=temp[i][j][0]/total[j] wgt = []rev = 0for i in range(len(stocks)):for j in range(len(temp)):rev = rev + weight[i,j]*retlist[i][j]wgt.append(rev)rev=0 return wgt
def calExpWgt(stocks,pointDate,n):#這里多取前一天,因為求每日收益率第一行是nanpastDate = pointDate - datetime.timedelta(days=n+2)price = get_price(stocks,start_date=pastDate,end_date=pointDate,fields='close')a = price.closeb = price.close.shift(1)ret = a/b-1retlist = ret.dropna().T.valuesretlist = retlist*365date = pointDateq = query( valuation.turnover_ratio ).filter(valuation.code.in_(stocks))temp = []xi=[]zjbl=[]for i in range(n+1):flag = get_price(stocks,start_date=datetime.datetime.strftime(date,"%Y-%m-%d"),end_date=datetime.datetime.strftime(date,"%Y-%m-%d"),fields='close')if len(flag.close)!=0:temp.append(get_fundamentals(q,date).values)mid = (pointDate-date).daysxi.append(mid)zjbl.append(exp(-mid*4/(n/30)))else:passdate = date - datetime.timedelta(days=1)#temp是所有換手率的原始數據,其中每個元素是30天中一天的1057只股票換手率的array#total分別計算了1057只股票的過去一個月總換手率total=[]sums=0for j in range(len(stocks)):for i in range(len(temp)):sums = sums+temp[i][j][0]+0.000000000000000000000000000000000001#防止有的總換手率為0,做分母時會出現nan值total.append(sums)sums=0 #權重矩陣:#行為股票,1057只,列為天數,0為當前天,29為30天前#其中是換手率權重#如 weight[35,10]代表u中第36只股票在11天前換手率占上月換手率的比重weight=mat(zeros((len(stocks),len(temp))))for j in range(len(stocks)):for i in range(len(temp)):weight[j,i]=(temp[i][j][0]/total[j])*zjbl[i] expWgt = []rev = 0for i in range(len(stocks)):for j in range(len(temp)):rev = rev + weight[i,j]*retlist[i][j]expWgt.append(rev)rev=0 return expWgt
def figureAnalysis(data):# figure analysis#kernal densitykde = mlab.GaussianKDE(data)x2 = np.linspace(min(data),max(data), 1000)line2 = plt.plot(x2,kde(x2), 'y', linewidth = 2,label="kernal density")n, bins, patches = plt.hist(data,100,normed=1, facecolor='blue', alpha=0.5)#直方圖函數,x為x軸的值,normed=1表示為概率密度,即和為一,藍色方塊,色深參數0.5.返回n個概率,直方塊左邊線的x值,及各個方塊對象y = mlab.normpdf(bins, mean(data),std(data))plt.plot(bins, y, 'r',label="normal distribution") #繪制y的曲線plt.xlabel('value') #繪制x軸plt.ylabel('Probability') #繪制y軸plt.title(r'fit figure')#中文標題 u'xxx'plt.legend(loc='upper left')industry_index = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150','801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750','801760','801770','801780','801790','801880','801890']
#startDate = datetime.datetime(2006,1,1,9,30)startDate = datetime.datetime(2016,12,1,9,30)endDate = datetime.datetime(2018,3,1,9,30)#pointDate = datetime.datetime(2017,12,1,9,30)stocklist = get_index_stocks(index)u = filterOfPauseAndST(stocklist,startDate,endDate)
價值因子:
EP:淨利潤(TTM,過去12個月)/總市值
BP:淨資產/總市值
SP:營業收入/總市值
NCFP:淨現金流/總市值
OCFP:經營性現金流/總市值
財務質量因子:
roe_ttm :淨資產收益率
roa_ttm :資產收益率
grossprofitmargin_ttm :毛利率
profit_margin :扣非後利潤率
operationcashflowratio:經營性現金流/淨利潤
assetturnover : 資產周轉率
成長因子:
sales_growth:營收增長率
net_profit_growth:淨利潤增長率同比
動量因子:
return_1m :近n月收益率
return_3m
return_6m
return_12m
wgt_return_1m :近n月以日換手率作為權重求得每日收益率的算數平均值
wgt_return_3m
wgt_return_6m
#價值因子計算q_VF = query(valuation.code, valuation.pe_ratio, valuation.pb_ratio, valuation.ps_ratio, valuation.pcf_ratio).filter(valuation.code.in_(u))df = get_fundamentals(q_VF,endDate).set_index('code')EPfactor = 1/df['pe_ratio']BPfactor = 1/df['pb_ratio']SPfactor = 1/df['ps_ratio']NCFPfactor = 1/df['pcf_ratio']#財務因子計算q_FQ = query(valuation.code,indicator.roe,indicator.roa,indicator.gross_profit_margin,indicator.net_profit_margin,indicator.adjusted_profit_to_profit,indicator.ocf_to_operating_profit,income.total_operating_revenue,balance.total_assets).filter(valuation.code.in_(u))df1 = get_fundamentals(q_FQ,endDate).set_index('code')roefactor = df1['roe']roafactor = df1['roa']gpmfactor = df1['gross_profit_margin']pmfactor = df1['adjusted_profit_to_profit']*df1['net_profit_margin']atfactor = df1['total_operating_revenue']/df1['total_assets']oopfactor = df1['ocf_to_operating_profit']#成長因子計算q_GF = query(valuation.code,indicator.inc_revenue_year_on_year,indicator.inc_net_profit_year_on_year).filter(valuation.code.in_(u))df2 = get_fundamentals(q_GF,endDate).set_index('code')incGfactor = df2['inc_revenue_year_on_year']netGfactor = df2['inc_net_profit_year_on_year']#動量因子計算return_1m = calRN(u,endDate,30)return_3m = calRN(u,endDate,90)return_6m = calRN(u,endDate,180)return_12m = calRN(u,endDate,360)wgt_return_1m = calWgt(u,endDate,30)wgt_return_3m = calWgt(u,endDate,90)wgt_return_6m = calWgt(u,endDate,180)
plot(wgt_return_6m)
[<matplotlib.lines.Line2D at 0x7f37c8e3c290>]
plot(standarize(wgt_return_6m))
[<matplotlib.lines.Line2D at 0x7f37d4b0bed0>]
figureAnalysis(wgt_return_3m)
figureAnalysis(standarize(wgt_return_3m))
figureAnalysis(z_score(wgt_return_3m))
#tt_stat={}timestamp = pd.date_range(startDate,endDate,freq='M')for date in timestamp:logret = np.log(get_price(u,end_date=date,fields='close',count=2).close.T.iloc[:,1]/get_price(u,end_date=date,fields='close',count=2).close.T.iloc[:,0])df = get_fundamentals(q_VF,date).set_index('code')BPfactor = 1/df['pb_ratio']model = sm.OLS(logret,BPfactor).fit()t_value = model.params/model.bset_stat[date] = t_valuepd.Series(t_stat)2016-12-31 09:30:00 pb_ratio -2.714229 dtype: float64 2017-01-31 09:30:00 pb_ratio -7.700975 dtype: float64 2017-02-28 09:30:00 pb_ratio -9.109835 dtype: float64 2017-03-31 09:30:00 pb_ratio -1.614685 dtype: float64 2017-04-30 09:30:00 pb_ratio -7.199039 dtype: float64 2017-05-31 09:30:00 pb_ratio -0.381703 dtype: float64 2017-06-30 09:30:00 pb_ratio -1.677513 dtype: float64 2017-07-31 09:30:00 pb_ratio -12.645502 dtype: float64 2017-08-31 09:30:00 pb_ratio -1.993199 dtype: float64 2017-09-30 09:30:00 pb_ratio -9.85773 dtype: float64 2017-10-31 09:30:00 pb_ratio -8.791854 dtype: float64 2017-11-30 09:30:00 pb_ratio 8.902485 dtype: float64 2017-12-31 09:30:00 pb_ratio -11.334248 dtype: float64 2018-01-31 09:30:00 pb_ratio 18.88212 dtype: float64 2018-02-28 09:30:00 pb_ratio 1.462943 dtype: float64 dtype: object
#ICdatebegan = timestamp[0]df = get_fundamentals(q_VF,datebegan).set_index('code')BPfactor = 1/df['pb_ratio']for date in timestamp:logret = np.log(get_price(u,end_date=date,fields='close',count=2).close.T.iloc[:,0]/get_price(u,end_date=date,fields='close',count=2).close.T.iloc[:,1])corr = logret.corr(BPfactor)print "IC:",corrdf = get_fundamentals(q_VF,date).set_index('code')BPfactor = 1/df['pb_ratio']IC: -0.0906616445869 IC: -0.00245872750451 IC: -0.0607410932649 IC: 0.0182631803712 IC: 0.0118782587615 IC: -0.112650657267 IC: 0.0651148549123 IC: -0.148153908276 IC: 0.125992657127 IC: 0.106328679642 IC: 0.0778156865195 IC: 0.0406853084862 IC: 0.0590477289408 IC: -0.0753420352392 IC: 0.0334512167471


















