0. 前言
本文说的内容来源于,我以前发过一篇推文《机器学习的简单套用》遇到的问题:
“模型局限:周期之间训练出来的模型保持孤立状态,而且每一次预测完会有预测分类结果和实际分类结果(实际的结果我还没用到模型上), 如何对它们做cost function,甚至利用这个cost function对以后的周期训练作指导,这个问题我想了一下,可能需要套用各种RNN。”
本文提供一种解决方案的探讨:利用LSTM通过Tensorflow库来解决周期之间,模型训练孤立的问题。(但是没有解决模型交互之后误差数据处理的问题)
PS: 小弟今年大三金融,对计算机一知半解,如果小伙伴们发现有啥错误的,咱们可以多多交流(Wechat: dhl19988882)
1. 基础知识
本文不提供LSTM相关原理/内容,但是会提供小弟自学LSTM的各种传送门:
模型直观认识: RNN, LSTM
模型推导(建议自己推导几次): RNN , LSTM
TF模型实现: 莫烦大大的教学视频
2. 结果展示
我把逻辑整理成策略(放到策略擂台),小伙伴们可以看一下:
中证500池子,预测当天涨的标的,根据预测的涨幅加权配资
策略擂台: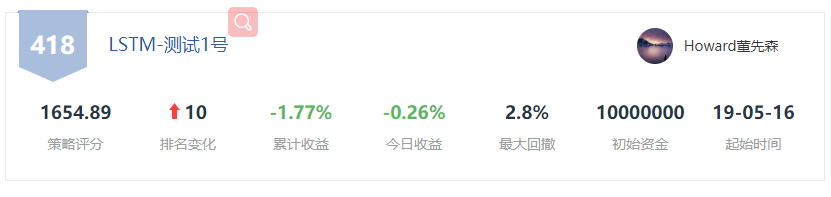
回测结果: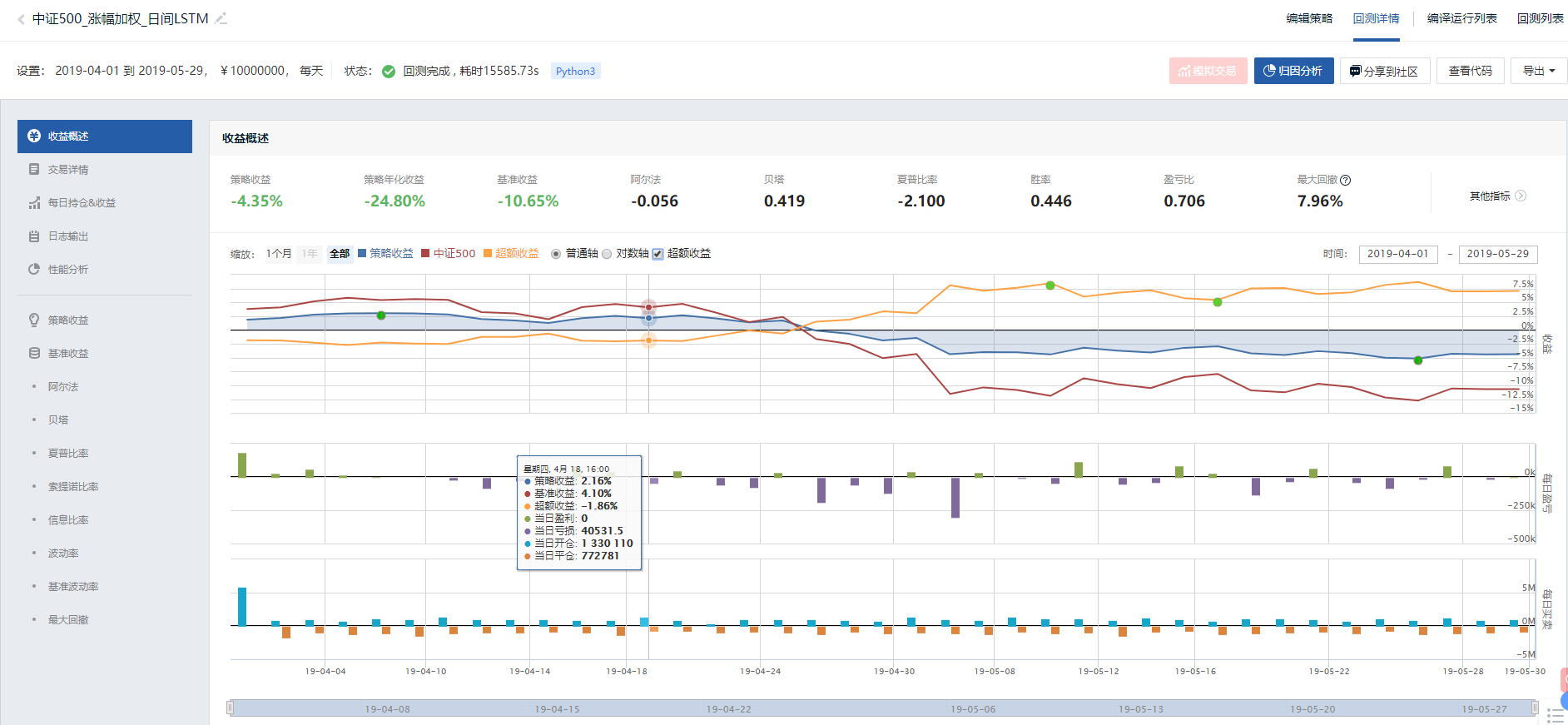
3. 后记思考
1)因子:本文的因子有点杂,仅通过简单的数据预处理,没有进行筛选;本文也没有引用非结构化数据和半结构化数据。
2)算法:本文仅仅针对周期之间训练孤立的问题进行解决尝试,并没有对预测和实际结果误差这类与环境交互的数据进行处理,后期会做一个与环境交互的强化学习模型。
3)择时:毕竟每天能买到涨的股票是小概率事件,可以引用择时逻辑。
4)交易:多因子裸多策略不一定能在任何时间跑赢大盘,且波动较大,可以引用一下对冲。
1. 数据准备¶
# 导入函数库
import pandas as pd
import numpy as np
import time
import datetime
import statsmodels.api as sm
import pickle
import warnings
from itertools import combinations
import itertools
from jqfactor import get_factor_values
from jqdata import *
from jqfactor import neutralize
from jqfactor import standardlize
from jqfactor import winsorize
from jqfactor import neutralize
import calendar
from scipy import stats
import statsmodels.api as sm
from statsmodels import regression
import csv
from six import StringIO
from jqlib.technical_analysis import *
#导入pca
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.grid_search import GridSearchCV
from sklearn import metrics
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.pyplot as plt
from jqfactor import neutralize
import warnings
warnings.filterwarnings("ignore")
# 函数打包!!!!!!!毕竟是自己写的,小伙们如果发现有啥错误,多多交流哈(wechat:dhl19988882)
# 时间戳获取
def get_time(today,shift):
# 预测时间list
tradingday = get_all_trade_days() # 获取所有的交易日,返回一个包含所有交易日的 list,元素值为 datetime.date 类型.
shift_index_pred = list(tradingday).index(today) # 获取today对应的绝对日期排序数
pred_days = tradingday[shift_index_pred - shift+1 : shift_index_pred+1] # 获取回溯需要的日期array
start_date_pred = pred_days[0]
end_date_pred = pred_days[-1]
# 训练时间list
shift_index_train = list(tradingday).index(today) -1 # 获取yesterday对应的绝对日期排序数
train_days = tradingday[shift_index_train - shift+1 : shift_index_train+1 ]
start_date_train = train_days[0]
end_date_train = train_days[-1]
return start_date_train,end_date_train, start_date_pred, end_date_pred
def get_days(today,shift):
# 预测时间list
tradingday = get_all_trade_days() # 获取所有的交易日,返回一个包含所有交易日的 list,元素值为 datetime.date 类型.
shift_index_pred = list(tradingday).index(today) # 获取today对应的绝对日期排序数
pred_days = tradingday[shift_index_pred - shift+1 : shift_index_pred+1] # 获取回溯需要的日期array
start_date_pred = pred_days[0]
end_date_pred = pred_days[-1]
# 训练时间list
shift_index_train = list(tradingday).index(today) -1 # 获取yesterday对应的绝对日期排序数
train_days = tradingday[shift_index_train - shift+1 : shift_index_train+1 ]
start_date_train = train_days[0]
end_date_train = train_days[-1]
return pred_days, train_days
#去除上市距beginDate不足1年且退市在endDate之后的股票
def delect_stop(stocks,beginDate,endDate,n=365):
stockList=[]
beginDate = datetime.datetime.strptime(beginDate, "%Y-%m-%d")
endDate = datetime.datetime.strptime(endDate, "%Y-%m-%d")
for stock in stocks:
start_date=get_security_info(stock).start_date
end_date=get_security_info(stock).end_date
if start_date<(beginDate-datetime.timedelta(days=n)).date() and end_date>endDate.date():
stockList.append(stock)
return stockList
# 数据获取函数
# 技术面
def get_factors_one_stock(stocks,date):
'''
获取一只股票一天的因子数据集
input:
stocks:一只股票
date:日期
output:
df:dataframe,各个因子一天的数值
'''
if type(date) != str:
date = datetime.datetime.strftime(date,'%Y-%m-%d')
price = get_price(stocks,end_date=date,count=1,fields=['close','volume'])
price.index = [date]
accer = ACCER(stocks,check_date=date,N=5)
accer_df = pd.DataFrame(list(accer.values()),columns=['ACCER'])
#乘离率
bias,bias_ma = BIAS_QL(stocks, date, M = 6)
bias_df = pd.DataFrame(list(bias.values()),columns=['BIAS'])
#动态买卖气
adtm,maadtm = ADTM(stocks,check_date=date,N=23,M=8)
adtm_df = pd.DataFrame(list(adtm.values()),columns=['ADTM'])
#商品路径
cci = CCI(stocks, date, N=14)
cci_df = pd.DataFrame(list(cci.values()),columns=['CCI'])
#多空线
dkx,madkx = DKX(stocks, date, M = 10)
dkx_df = pd.DataFrame(list(dkx.values()),columns=['DKX'])
#随机指标
k,d = SKDJ(stocks, date, N = 9, M = 3)
k_df = pd.DataFrame(list(k.values()),columns=['KBJ'])
#市场趋势
cye,_ = CYE(stocks, date)
cye_df = pd.DataFrame(list(cye.values()),columns=['CYE'])
#简单波动指标
emv,_ = EMV(stocks, date, N = 14, M = 9)
emv_df = pd.DataFrame(list(emv.values()),columns=['EMV'])
#相对强弱
br, ar = BRAR(stocks, date, N=26)
br_df = pd.DataFrame(list(br.values()),columns=['BR'])
ar_df = pd.DataFrame(list(ar.values()),columns=['AR'])
df = pd.concat([accer_df,bias_df,adtm_df,cci_df,dkx_df,k_df,cye_df,emv_df,br_df,ar_df],axis=1)
df.index = [date]
df = pd.concat([price,df],axis=1)
return df
def get_data_from_date(start_date,end_date,stocks):
'''
获取时间轴数据
'''
trade_date = get_trade_days(start_date=start_date,end_date=end_date)
df = get_factors_one_stock(stocks,trade_date[0])
for date in trade_date[1:]:
df1 = get_factors_one_stock(stocks,date)
df = pd.concat([df,df1])
return df
def winsorize_and_standarlize(data,qrange=[0.05,0.95],axis=0):
'''
input:
data:Dataframe or series,输入数据
qrange:list,list[0]下分位数,list[1],上分位数,极值用分位数代替
'''
if isinstance(data,pd.DataFrame):
if axis == 0:
q_down = data.quantile(qrange[0])
q_up = data.quantile(qrange[1])
index = data.index
col = data.columns
for n in col:
data[n][data[n] > q_up[n]] = q_up[n]
data[n][data[n] < q_down[n]] = q_down[n]
data = (data - data.mean())/data.std()
data = data.fillna(0)
else:
data = data.stack()
data = data.unstack(0)
q = data.quantile(qrange)
index = data.index
col = data.columns
for n in col:
data[n][data[n] > q[n]] = q[n]
data = (data - data.mean())/data.std()
data = data.stack().unstack(0)
data = data.fillna(0)
elif isinstance(data,pd.Series):
name = data.name
q = data.quantile(qrange)
data[data>q] = q
data = (data - data.mean())/data.std()
return data
# 基本面
# 行业代码获取函数
def get_industry(date,industry_old_code,industry_new_code):
'''
输入:
date: str, 时间点
industry_old_code: list, 旧的行业代码
industry_new_code: list, 新的行业代码
输出:
list, 行业代码
'''
#获取行业因子数据
if datetime.datetime.strptime(date,"%Y-%m-%d").date()<datetime.date(2014,2,21):
industry_code=industry_old_code
else:
industry_code=industry_new_code
len(industry_code)
return industry_code
# 取股票对应行业
def get_industry_name(i_Constituent_Stocks, value):
return [k for k, v in i_Constituent_Stocks.items() if value in v]
# 缺失值处理
def replace_nan_indu(factor_data, stockList, industry_code, date):
'''
输入:
factor_data: dataframe, 有缺失值的因子值
stockList: list, 指数池子所有标的
industry_code: list, 行业代码
date: str, 时间点
输出:
格式为list
所有因子的排列组合
'''
# 创建一个字典,用于储存每个行业对应的成分股(行业标的和指数标的取交集)
i_Constituent_Stocks={}
# 创建一个行业因子数据表格,待填因子数据(暂定为均值)
ind_factor_data = pd.DataFrame(index=industry_code,columns=factor_data.columns)
# 遍历所有行业
for i in industry_code:
# 获取单个行业所有的标的
stk_code = get_industry_stocks(i, date)
# 储存每个行业对应的所有成分股到刚刚创建的字典中(行业标的和指数标的取交集)
i_Constituent_Stocks[i] = list(set(stk_code).intersection(set(stockList)))
# 对于某个行业,根据提取出来的指数池子,把所有交集内的因子值取mean,赋值到行业因子值的表格上
ind_factor_data.loc[i]=mean(factor_data.loc[i_Constituent_Stocks[i],:])
# 对于行业值缺失的(行业标的和指数标的取交集),用所有行业的均值代替
for factor in ind_factor_data.columns:
# 提取行业缺失值所在的行业,并放到list去
null_industry=list(ind_factor_data.loc[pd.isnull(ind_factor_data[factor]),factor].keys())
# 遍历行业缺失值所在的行业
for i in null_industry:
# 所有行业的均值代替,行业缺失的数值
ind_factor_data.loc[i,factor]=mean(ind_factor_data[factor])
# 提取含缺失值的标的
null_stock=list(factor_data.loc[pd.isnull(factor_data[factor]),factor].keys())
# 用行业值(暂定均值)去填补,指数因子缺失值
for i in null_stock:
industry = get_industry_name(i_Constituent_Stocks, i)
if industry:
factor_data.loc[i, factor] = ind_factor_data.loc[industry[0], factor]
else:
factor_data.loc[i, factor] = mean(factor_data[factor])
return factor_data
# 获取时间为date的全部因子数据
def get_factor_data(stock_list,date):
data=pd.DataFrame(index=stock_list)
# 第一波因子提取
q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(stock_list))
df = get_fundamentals(q, date)
df['market_cap']=df['market_cap']*100000000
df.index = df['code']
del df['code'],df['id']
# 第二波因子提取
factor_data=get_factor_values(stock_list,['roe_ttm','roa_ttm','total_asset_turnover_rate',\
'net_operate_cash_flow_ttm','net_profit_ttm',\
'cash_to_current_liability','current_ratio',\
'gross_income_ratio','non_recurring_gain_loss',\
'operating_revenue_ttm','net_profit_growth_rate'],end_date=date,count=1)
# 第二波因子转dataframe格式
factor=pd.DataFrame(index=stock_list)
for i in factor_data.keys():
factor[i]=factor_data[i].iloc[0,:]
#合并得大表
df=pd.concat([df,factor],axis=1)
# 有些因子没有的,用别的近似代替
df.fillna(0, inplace = True)
# profitability 因子
# proft/net revenue
data['gross_profit_margin'] = df['gross_profit_margin']
data['net_profit_margin'] = df['net_profit_margin']
data['operating_profit_margin'] = df['operating_profit']/(df['total_operating_revenue']-df['total_operating_cost'])
data['pretax_margin'] = (df['net_profit'] + df['income_tax_expense'])/(df['total_operating_revenue']-df['total_operating_cost'])
# profit/capital
data['ROA'] = df['roa']
data['EBIT_OA'] = df['operating_profit']/df['total_assets']
data['ROTC'] = df['operating_profit']/(df['total_owner_equities'] + df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])
data['ROE'] = df['roe']
# Others
data['inc_total_revenue_annual'] = df['inc_total_revenue_annual']
# Activity 因子
# inventory
data['inventory_turnover'] = df['operating_cost']/df['inventories']
data['inventory_processing_period'] = 365/data['inventory_turnover']
# account receivables
data['receivables_turnover'] =df['total_operating_revenue']/df['account_receivable']
data['receivables_collection_period'] = 365/data['receivables_turnover']
# activity cycle
data['operating_cycle'] = data['receivables_collection_period']+data['inventory_processing_period']
# Other turnovers
data['total_asset_turnover'] = df['operating_revenue']/df['total_assets']
data['fixed_assets_turnover'] = df['operating_revenue']/df['fixed_assets']
data['working_capital_turnover'] = df['operating_revenue']/(df['total_current_assets']-df['total_current_liability'])
# Liquidity 因子
data['current_ratio'] =df['current_ratio']
data['quick_ratio'] =(df['total_current_assets']-df['inventories'])/df['total_current_liability']
data['cash_ratio'] = (df['cash_equivalents']+df['proxy_secu_proceeds'])/df['total_current_liability']
# leverage
data['debt_to_equity'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_owner_equities']
data['debt_to_capital'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/(df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable']+df['total_owner_equities'])
data['debt_to_assets'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_assets']
data['financial_leverage'] = df['total_assets'] / df['total_owner_equities']
# Valuation 因子
# Price
data['EP']=df['net_profit_ttm']/df['market_cap']
data['PB']=df['pb_ratio']
data['PS']=df['ps_ratio']
data['P/CF']=df['market_cap']/df['net_operate_cash_flow']
# 技术面 因子
# 下面技术因子来自于西交大元老师量化小组的SVM研究,report,https://www.joinquant.com/view/community/detail/15371
stock = stock_list
#个股60个月收益与上证综指回归的截距项与BETA
stock_close=get_price(stock, count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
SZ_close=get_price('000001.XSHG', count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
stock_pchg=stock_close.pct_change().iloc[1:]
SZ_pchg=SZ_close.pct_change().iloc[1:]
beta=[]
stockalpha=[]
for i in stock:
temp_beta, temp_stockalpha = stats.linregress(SZ_pchg, stock_pchg[i])[:2]
beta.append(temp_beta)
stockalpha.append(temp_stockalpha)
#此处alpha beta为list
data['alpha']=stockalpha
data['beta']=beta
#动量
data['return_1m']=stock_close.iloc[-1]/stock_close.iloc[-20]-1
data['return_3m']=stock_close.iloc[-1]/stock_close.iloc[-60]-1
data['return_6m']=stock_close.iloc[-1]/stock_close.iloc[-120]-1
data['return_12m']=stock_close.iloc[-1]/stock_close.iloc[-240]-1
#取换手率数据
data_turnover_ratio=pd.DataFrame()
data_turnover_ratio['code']=stock
trade_days=list(get_trade_days(end_date=date, count=240*2))
for i in trade_days:
q = query(valuation.code,valuation.turnover_ratio).filter(valuation.code.in_(stock))
temp = get_fundamentals(q, i)
data_turnover_ratio=pd.merge(data_turnover_ratio, temp,how='left',on='code')
data_turnover_ratio=data_turnover_ratio.rename(columns={'turnover_ratio':i})
data_turnover_ratio=data_turnover_ratio.set_index('code').T
#个股个股最近N个月内用每日换手率乘以每日收益率求算术平均值
data['wgt_return_1m']=mean(stock_pchg.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['wgt_return_3m']=mean(stock_pchg.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['wgt_return_6m']=mean(stock_pchg.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['wgt_return_12m']=mean(stock_pchg.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#个股个股最近N个月内用每日换手率乘以函数exp(-x_i/N/4)再乘以每日收益率求算术平均值
temp_data=pd.DataFrame(index=data_turnover_ratio[-240:].index,columns=stock)
temp=[]
for i in range(240):
if i/20<1:
temp.append(exp(-i/1/4))
elif i/20<3:
temp.append(exp(-i/3/4))
elif i/20<6:
temp.append(exp(-i/6/4))
elif i/20<12:
temp.append(exp(-i/12/4))
temp.reverse()
for i in stock:
temp_data[i]=temp
data['exp_wgt_return_1m']=mean(stock_pchg.iloc[-20:]*temp_data.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['exp_wgt_return_3m']=mean(stock_pchg.iloc[-60:]*temp_data.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['exp_wgt_return_6m']=mean(stock_pchg.iloc[-120:]*temp_data.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['exp_wgt_return_12m']=mean(stock_pchg.iloc[-240:]*temp_data.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#波动率
data['std_1m']=stock_pchg.iloc[-20:].std()
data['std_3m']=stock_pchg.iloc[-60:].std()
data['std_6m']=stock_pchg.iloc[-120:].std()
data['std_12m']=stock_pchg.iloc[-240:].std()
#股价
data['ln_price']=np.log(stock_close.iloc[-1])
#换手率
data['turn_1m']=mean(data_turnover_ratio.iloc[-20:])
data['turn_3m']=mean(data_turnover_ratio.iloc[-60:])
data['turn_6m']=mean(data_turnover_ratio.iloc[-120:])
data['turn_12m']=mean(data_turnover_ratio.iloc[-240:])
data['bias_turn_1m']=mean(data_turnover_ratio.iloc[-20:])/mean(data_turnover_ratio)-1
data['bias_turn_3m']=mean(data_turnover_ratio.iloc[-60:])/mean(data_turnover_ratio)-1
data['bias_turn_6m']=mean(data_turnover_ratio.iloc[-120:])/mean(data_turnover_ratio)-1
data['bias_turn_12m']=mean(data_turnover_ratio.iloc[-240:])/mean(data_turnover_ratio)-1
#技术指标
data['PSY']=pd.Series(PSY(stock, date, timeperiod=20))
data['RSI']=pd.Series(RSI(stock, date, N1=20))
data['BIAS']=pd.Series(BIAS(stock,date, N1=20)[0])
dif,dea,macd=MACD(stock, date, SHORT = 10, LONG = 30, MID = 15)
data['DIF']=pd.Series(dif)
data['DEA']=pd.Series(dea)
data['MACD']=pd.Series(macd)
# 去inf
a = np.array(data)
where_are_inf = np.isinf(a)
a[where_are_inf] = nan
factor_data =pd.DataFrame(a, index=data.index, columns = data.columns)
return factor_data
# 处理后的基本面因子
def get_fundamental(stockList, date,industry_old_code,industry_new_code):
# 行业获取
industry_code = get_industry(str(date),industry_old_code,industry_new_code)
# 获取数据
factor_data = get_factor_data(stockList, date)
# 数据预处理
# 缺失值处理
data = replace_nan_indu(factor_data, stockList, industry_code, date)
# 启动内置函数去极值
data = winsorize(data, qrange=[0.05,0.93], inclusive=True, inf2nan=True, axis=0)
# 启动内置函数标准化
data = standardlize(data, inf2nan=True, axis=0)
# 启动内置函数中性化,行业为'sw_l1'
data = neutralize(data, how=['sw_l1','market_cap'], date=date , axis=0)
return data
def get_fund(stockList, train_days,industry_old_code,industry_new_code):
x_fund_train = {}
for day in train_days:
print('正在进行第'+str(day)+'截面基本面数据获取……')
x_fund = get_fundamental(stockList,day,industry_old_code,industry_new_code)
x_fund_train[str(day)] = x_fund
return pd.Panel(x_fund_train)
# 训练数据获取
# 单周期训练数据【x】
def get_train_x(stockList, start_date_pre, end_date_pre):
# 训练数据【x】
input_data1 = {}
for i in stockList:
data = get_data_from_date(start_date_pre, end_date_pre, i)
del data[data.columns[0]]
data_pro = winsorize_and_standarlize(data)
input_data1[i] = data_pro
x_train = pd.Panel(input_data1) # 训练因子数据
return x_train
# 单周期训练数据【y】
def get_train_y(stockList, start_date_last, end_date_last):
# 训练数据【y】
input_data = {}
for i in stockList:
data = get_data_from_date(start_date_last, end_date_last, i)
data = data[data.columns[0]]
input_data[i] = pd.DataFrame(data)
y_train = pd.Panel(input_data) # 训练因子数据
return y_train
# 参数
# 行业:申万一级
industry_old_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230']
industry_new_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750',\
'801760','801770','801780','801790','801880','801890']
# index= '399905.XSHE' # 定义股票池,中证500 ; 中证100:'000903.XSHG' ;"上证50:" '000016.XSHG'
index = '399905.XSHE'
shift = 5 # 回溯时间步
print('时间戳获取中……')
today = datetime.datetime.now().date() # 获取
start_date_train,end_date_train,start_date_pred,end_date_pred = get_time(today,shift)
pred_days, train_days = get_days(today,shift)
date = str(today)
# 指数池子提取
stockList = get_index_stocks(index , date=date)
#剔除ST股
st_data=get_extras('is_st',stockList, count = 1,end_date = date)
stockList = [stock for stock in stockList if not st_data[stock][0]]
#剔除停牌、新股及退市股票
stockList=delect_stop(stockList,date,date)
# stockList = stockList[:9]
print('大盘池子个数为' + str(len(stockList)))
print('训练数据获取中……')
x_tech_train = get_train_x(stockList, start_date_train, end_date_train)
x_fund_train = get_fund(stockList, train_days,industry_old_code,industry_new_code)
x_train = pd.concat([x_tech_train, np.transpose(x_fund_train, (1,0,2))], axis =2)
y_train = get_train_y(stockList, start_date_train, end_date_train)
print('预测预备数据获取中……')
x_tech_pred = get_train_x(stockList, start_date_pred, end_date_pred)
x_fund_pred = get_fund(stockList, pred_days,industry_old_code,industry_new_code)
x_pred = pd.concat([x_tech_pred, np.transpose(x_fund_pred, (1,0,2))], axis =2)
print('单周期数据准备完成!!')
print('获取预测标的准备中……')
x_sub_train = array(x_train.astype(np.float32))
y_sub_train = array(y_train.astype(np.float32))
x_test = array(x_pred.astype(np.float32))
print('数据准备完成!')
2. 训练-预测¶
import tensorflow as tf
# 【取最后时间步的输出为拿来训练的预测值】单层 LSTM
def single_layer_lstm_for_last_step(x, lstm_size):
# PS: lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, n_hidden_units]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([n_hidden_units, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [n_hidden_units]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(x, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
# lstm_cell
# lstm_cell = tf.keras.layers.LSTMCell(lstm_size) # keras 的 final_states 是先 cell_state 后 h_state
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(lstm_cell, _x , dtype=tf.float32)
# output 放到最后hidden layer加工,最后一层的输出
# hidden layer for output as the final results
# 方法一:
# final_states[1]: 分线剧情结果
last_hidden_output = final_states[1]
results = tf.matmul(last_hidden_output, W['out']) + b['out']
# 方法二:把 tensor 解开 变成list
# unpack to list [( batch, outputs)..] * steps, (28steps,(batch, outputs))
# outputs = tf.unpack(tf.transpose(outputs, [1,0,2])) # states is the last outputs
# results = tf.matmul(outputs[-1], W['out']) + b['out']
return results
# 【取每一时间步的输出为拿来训练的预测值】单层 LSTM, 输出结果就是prediction
def single_layer_lstm_for_each_step(x, lstm_size):
# PS: lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, n_hidden_units]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([n_hidden_units, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [n_hidden_units]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(x, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
# lstm_cell
# lstm_cell = tf.keras.layers.LSTMCell(lstm_size) # keras 的 final_states 是先 cell_state 后 h_state
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(lstm_cell, _x , dtype=tf.float32)
# output 为每一个时间步隐藏层的输出值,shape:(batch_size, n_step, hidden_units)
# 放入 lstm 前的 hidden_layer
_output = tf.transpose(output, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, hidden_units)
_output = tf.reshape(_output, [-1, n_hidden_units])
# # new shape: (n_steps * batch_size, n_input )
# ReLu activation
_output = tf.nn.relu(tf.matmul(_output, W['out']) + b['out'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_output = tf.split(_output, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_output = tf.transpose(_output, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
return _output
# 【取最后时间步的输出为拿来训练的预测值】多层LSTM
def multi_layer_lstm_for_last_step(X, n_lstm_layer, lstm_size):
# n_lstm_layer: lstm的层数
# lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, lstm_size]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([lstm_size, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [lstm_size]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(x, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
layers = [tf.contrib.rnn.BasicLSTMCell(num_units=lstm_size,
activation=tf.nn.relu)
for layer in range(n_layers)]
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(layers)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(multi_layer_cell,x,dtype=tf.float32)
# hidden layer for output as the final results
results = tf.matmul(final_states[n_layers-1][1], W['out']) + b['out'] # 最后一层lstm层,对其hidden_state的输出进行矩阵乘法
return results
# 【我的策略的话取的是这个思路】
# 【取每一时间步的输出为拿来训练的预测值】多层LSTM, 输出结果就是prediction
def multi_layer_lstm_for_each_step(X, n_lstm_layer, n_hidden_units):
# n_lstm_layer: lstm的层数
# lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, n_hidden_units]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([n_hidden_units, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [n_hidden_units]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(X, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
# 定义多层lstm
layers = [tf.contrib.rnn.BasicLSTMCell(num_units=n_hidden_units,
activation=tf.nn.relu)
for layer in range(n_layers)]
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(layers)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(multi_layer_cell,_x,dtype=tf.float32)
# output 为每一个时间步隐藏层的输出值,shape:(batch_size, n_step, hidden_units)
# 放入 lstm 前的 hidden_layer
_output = tf.transpose(output, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, hidden_units)
_output = tf.reshape(_output, [-1, n_hidden_units])
# # new shape: (n_steps * batch_size, n_input )
# ReLu activation
_output = tf.nn.relu(tf.matmul(_output, W['out']) + b['out'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_output = tf.split(_output, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_output = tf.transpose(_output, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
pred = _output
return pred
# 格式参数
training_iters = 100 # 单周期训练次数
stop = 20 # 停下来查看loss的时间步
lr = 0.01 # 学习率
n_hidden_units = 20 # neurons in hidden layer
lstm_size = n_hidden_units # 单层 lstm 的 hidden_units 数量
# 参数
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
拆开来看看训练情况¶
# 单周期多层LSTM(加上回溯前面周期)训练
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
# 定义placeholder
x = tf.placeholder(tf.float32, shape = x_sub_train.shape , name = 'x') # shape = (因子数量, 样本数量)
y = tf.placeholder(tf.float32, shape = y_sub_train.shape, name = 'y')
# 单层lstm
# prediction = single_layer_lstm_for_last_step(x, lstm_size)
# prediction = single_layer_lstm_for_each_step(x, lstm_size)
# # 多层lstm
n_layers = 2
#prediction = multi_layer_lstm_for_last_step(x, n_layers, n_hidden_units)
prediction = multi_layer_lstm_for_each_step(x, n_layers, n_hidden_units)
#损失函数,均方差
y_cost = tf.transpose(y,[1,0,2]) # 转换格式 (时间步,标的数量,分类结果)
y_cost_for_train = y_cost[-1] # 提取样本内最后一个时间步(周期)的分类结果, shape=(标的数量,分类结果【一维数据,1 or 0】)
# MSE损失函数
loss = tf.reduce_mean(tf.square(y - prediction))
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction, labels=y))
#梯度下降: AdamOptimizer 收敛速度快,但是过拟合严重
train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss) #learning_rate可以调整
# # 预测
correct_pred = tf.equal(tf.argmax(prediction,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
train_loss_list = []
for epoach in range(training_iters):
sess.run(train_step, feed_dict={x:x_sub_train, y:y_sub_train})
if epoach % stop == 0:
# 训练误差
loss_train = sess.run(loss, feed_dict = {x:x_sub_train, y:y_sub_train})
train_loss_list.append(loss_train)
# 预测
pred = sess.run(prediction, feed_dict = {x:x_test})
# acc = sess.run(accuracy, feed_dict = {x:x_sub_test, y:y_sub_test})
# 测试误差
# test_loss = sess.run(loss, feed_dict = {x:x_sub_test, y:y_sub_test})
print ('Iter' + str(epoach) + ' Training Loss:' + str(loss_train) )
整合成几行行代码 ,含预测¶
# # 策略打包好的函数~
# 【取每一时间步的输出为拿来训练的预测值】多层LSTM, 输出结果就是prediction
def multi_layer_lstm_for_each_step(X, n_lstm_layer, n_hidden_units, n_inputs, n_classes,n_steps,n_layers):
# n_lstm_layer: lstm的层数
# lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, n_hidden_units]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([n_hidden_units, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [n_hidden_units]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(X, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
# 定义多层lstm
layers = [tf.contrib.rnn.BasicLSTMCell(num_units=n_hidden_units,
activation=tf.nn.relu)
for layer in range(n_layers)]
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(layers)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(multi_layer_cell,_x,dtype=tf.float32)
# output 为每一个时间步隐藏层的输出值,shape:(batch_size, n_step, hidden_units)
# 放入 lstm 前的 hidden_layer
_output = tf.transpose(output, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, hidden_units)
_output = tf.reshape(_output, [-1, n_hidden_units])
# # new shape: (n_steps * batch_size, n_input )
# ReLu activation
_output = tf.nn.relu(tf.matmul(_output, W['out']) + b['out'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_output = tf.split(_output, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_output = tf.transpose(_output, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
pred = _output
return pred
# 单周期多层lstm预测
def lstmtrain(x_sub_train, y_sub_train, x_pred, n_hidden_units,n_inputs, n_classes,n_steps,n_layers,lr, training_iters, stop):
# 单周期多层LSTM(加上回溯前面周期)训练 +预测
warnings.filterwarnings("ignore")
tf.reset_default_graph()
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
# 单层lstm
# prediction = single_layer_lstm_for_last_step(x, lstm_size)
# prediction = single_layer_lstm_for_each_step(x, lstm_size)
# # 多层lstm
n_layers = 2
#prediction = multi_layer_lstm_for_last_step(x, n_layers, n_hidden_units)
prediction = multi_layer_lstm_for_each_step(x_sub_train, n_layers, n_hidden_units, n_inputs, n_classes,n_steps,n_layers)
#损失函数,均方差
# y_cost = tf.transpose(y,[1,0,2]) # 转换格式 (时间步,标的数量,分类结果)
# y_cost_for_train = y_cost[-1] # 提取样本内最后一个时间步(周期)的分类结果, shape=(标的数量,分类结果【一维数据,1 or 0】)
# MSE损失函数
loss = tf.reduce_mean(tf.square(y_sub_train - prediction))
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction, labels=y))
#梯度下降: AdamOptimizer 收敛速度快,但是过拟合严重
train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss) #learning_rate可以调整
# # 预测
# correct_pred = tf.equal(tf.argmax(prediction,1), tf.argmax(y,1))
# accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
train_loss_list = []
for epoach in range(training_iters):
sess.run(train_step)
if epoach % stop == 0:
# 训练误差
loss_train = sess.run(loss)
train_loss_list.append(loss_train)
# 预测
pred = sess.run(prediction)
print ('Iter' + str(epoach) + ' Training Loss:' + str(loss_train) )
return pred
# 获取买入卖出池子
def get_buy_sell(pred,y_train,stockList):
# 整合结果
# 上一个交易日的收盘价
df_y_t0 = dict(np.transpose((y_train),(1,0,2)))[list(dict(np.transpose((y_train),(1,0,2))).keys())[-1]]
# 本交易日预测价格
p = np.transpose(pred, (1,0,2))
df_pred = pd.DataFrame(p[-1])
df_pred.index = df_y_t0.index
# 整合
df = pd.concat([df_y_t0, df_pred], axis =1)
df.columns = ['t0','pre_t1']
# 获取预测标的池子
diff1 = (df['pre_t1']-df['t0'])
# 表格整理
df1 = df.copy()
df1['buy_decision'] = 0
for i in range(len(df)):
if list(diff1)[i] > 0:
df1.iloc[i,2] = True
else :
df1.iloc[i,2] = False
# 买入池子
buy = []
for i in range(len(diff1)):
if list(diff1)[i] > 0 :
buy.append(diff1.index[i])
# 卖出池子
sell = set(stockList) - set(buy)
return buy,sell,df1
# 获取标的日间浮动收益率
def get_floating_return(stock,yesterday,today):
a = get_price(stock,start_date= yesterday, end_date=today,fields=['close'])
past_p = list(a['close'])[0]
current_p = list(a['close'])[-1]
floating_return = current_p/past_p -1
return floating_return
# 整合
def get_one_day_pred(today, index,shift, training_iters, stop, lr, n_hidden_units):
print('时间戳获取中……')
start_date_train,end_date_train,start_date_pred,end_date_pred = get_time(today,shift)
pred_days, train_days = get_days(today,shift)
date = str(today)
# 指数池子提取
stockList = get_index_stocks(index , date=date)
#剔除ST股
st_data=get_extras('is_st',stockList, count = 1,end_date = date)
stockList = [stock for stock in stockList if not st_data[stock][0]]
#剔除停牌、新股及退市股票
stockList=delect_stop(stockList,date,date)
stockList = stockList[:9]
print('大盘池子个数为' + str(len(stockList)))
print('训练数据获取中……')
x_tech_train = get_train_x(stockList, start_date_train, end_date_train)
x_fund_train = get_fund(stockList, train_days)
x_train = pd.concat([x_tech_train, np.transpose(x_fund_train, (1,0,2))], axis =2)
y_train = get_train_y(stockList, start_date_train, end_date_train)
print('预测预备数据获取中……')
x_tech_pred = get_train_x(stockList, start_date_pred, end_date_pred)
x_fund_pred = get_fund(stockList, pred_days)
x_pred = pd.concat([x_tech_pred, np.transpose(x_fund_pred, (1,0,2))], axis =2)
print('单周期数据准备完成!!')
# 【保存】pickle
import pickle
dic_file = open('x_pred.pickle','wb')
pickle.dump(x_pred, dic_file)
dic_file.close()
# 【保存】pickle
import pickle
dic_file = open('x_train.pickle','wb')
pickle.dump(x_train, dic_file)
dic_file.close()
# 【保存】pickle
import pickle
dic_file = open('y_train.pickle','wb')
pickle.dump(y_train, dic_file)
dic_file.close()
x_sub_train = array(x_train.astype(np.float32))
y_sub_train = array(y_train.astype(np.float32))
x_test = array(x_pred.astype(np.float32))
# y_test = y_test
print('所有数据保存完毕!')
# 格式参数
training_iters = 100 # 单周期训练次数
stop = 20 # 停下来查看loss的时间步
lr = 0.01 # 学习率
n_hidden_units = 20 # neurons in hidden layer
lstm_size = n_hidden_units # 单层 lstm 的 hidden_units 数量
n_layers = 2 # lstm层数
# 参数
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
# 预测
print('预测中……')
pred = lstmtrain(x_sub_train, y_sub_train, x_pred, n_hidden_units,n_inputs, n_classes,n_steps,n_layers)
# 获取买入卖出池子
buy,sell,df1 = get_buy_sell(pred,y_train,stockList)
print('预测池子获取完成!!!')
return buy,sell,df1
# 【资金加权】
def get_buy_position(df,buy):
# 涨跌幅获取
df['increase_pct'] = df['pre_t1']/df['t0']
# 提取预测涨的股票
df_buy = df.ix[buy]
# 降序
df_buy = df_buy.sort_values(by = ['increase_pct'], ascending = False)
# 配资比率
df_buy['buy%'] = df_buy['increase_pct']/sum(df['increase_pct'])
return df_buy
print('预测中……')
pred = lstmtrain(x_sub_train, y_sub_train, x_pred, n_hidden_units,n_inputs, n_classes,n_steps,n_layers,lr, training_iters, stop)
print('获取买入卖出池子中……')
buy,sell,df = get_buy_sell(pred, y_train, stockList)
buy_position = get_buy_position(df,buy)
print('预测结果:',df)
print('买入配资', buy_position) # 涨幅加权配资
print('买入池子:',buy) # 买入预测涨的标的
print('卖出池子:',sell) # 卖出预测跌的标的
buy_position