技术指标说明
说到技术指标,想必不论新韭老韭都能随口念出几个来,是判断行情走势的衍生工具,也是行情软件中必备的板块内容,技术分析一直在大多数股民中备受好评,各个频道的股评专家也是乐此不疲。
股市参与者千万人,在同一市场中博弈,作为个人投资者获取行业或公司信息并无优势,然而关于市场所有的信息最终都会落到交易上,会体现在成交量和价格上,量价信息这个层面来讲,市场是公平的,这也是技术分析能够为大多数人使用的原因之一。使用技术分析之前,我们需要了解到,所有技术分析能够成立,是建立在以下的三大基石之上
- 市场行为包容消化一切信息
- 价格以趋势方式演变
- 历史会重演
- 基于以上假设,演化出了各类市场分析的手段方法,下面进行了简单的汇总,技术指标作为技术分析的一个分支,其方便、直观、快捷的使用方式很受投资者的欢迎,其中蕴涵了投资者对股价变化进行长期观察并积累经验,逐步归纳总结出来的有关股市波动的规律,本篇旨在针对技术指标进行一些探索。

进行大盘择时效果检查
- 技术指标关注的点在于标的在市场中的成交量与价格变化情况,并没有去考虑所参与的标的是造酒的还是卖软件的,我们有理由认为股价变动会与自身的实际业务及行业而具有自己独特的规律,所以,这里为了避免在个股操作中受到行业及个股自身特性的干扰,我们直接拿指标进行指数交易。这里我们选了常见的13个技术指标,指标列表下
[(0, 'None'),(1, 'MA'),(2, 'MA1'),(3, 'EMA'),(4, 'EMA1'),(5, 'MACD'),(6, 'KDJ'),(7, 'CCI'),(8, 'RSI'),(9, 'BOLL'),(10, 'BIAS'),(11, 'TRIX'),(12, 'BBI'),(13, 'PSY')]注:后面的分指标回测图,数字与这里的指标是对应的关系
- 用以上指标分别统计了各个指标在沪深300、上证50、中证500
、中证1000指数上的应用效果,为了能对结果有较为直观的对比,这里加入了指标‘None’,用于记录全仓买入指数没有择时的情况 下面是指标在沪深300指数上的择时表现,以按收益进行排序
可以看到13个指标,有9个是可以跑赢大盘本身,排名第一的是反转类指标(一般均线突破类的为趋势类,设置临界阈值类的指标为反转类),且大部分回撤都集中在大盘股灾期间注:这里旨在进行指标效果探索,已将手续费和滑点设置为0
- 下面是指标在上证50指数上的择时表现
其中只有3个指标能够跑赢大盘,排名第一的是趋势类指标布林带,大部分回撤集中在08年股灾后到15年股灾前的长熊期间 - 下面是指标在中证500指数上的择时表现
其中有4个指标能跑赢大盘,排名第一的是趋势类指标指数移动平均线,大部分回撤都集中在15年股灾后 - 下图是指数在中证1000指数上的择时表现
中证1000由于指数编制较晚,出现了较长时间的空仓期,10个指标是可以跑赢指数本身的,排名第一的是趋势类布林带指标,BOLL指标第二次出现,回撤集中在15年股灾后。
参数调试
- 以上指标进行测试直接调用的聚宽技术指标库的方法,涉及到指标参数均使用已设置的默认参数,部分涉及到设置信号阈值类的指标,如RSI指标,目前是主观给的范围(未做调优),为了进一步测试指标的效果是否稳定(Robust),下面将进行策略收益对参数变化的敏感性测试,我们取了两个指标进行测试,分别是在中证500上效果显著的EMA指数移动平均线指标,和在中证1000上效果显著的BOLL带指标,设置不同统计长度(timeperiod),分别设置为
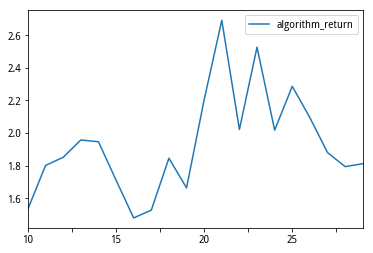
['10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','30'] - 可以看到,EMA表现最好的参数为21,BOLL带表现最好的指标是23,并且在两边是逐步下降的过程,而实际上,指标表现最好的参数基本就是一个月的交易日个数,我们猜测市场存在明显的月度效应(这里可以试着拿该指标在更多的标的中进行测试,分别统计不同参数下,跑赢不择时的比率变化规律)。
结果说明
通过上述的测试结果,我们初步发现如下的情况
- 在4个指数上都能跑赢指数本身的指标有两个,MA、RSI(这里不禁感慨难怪信仰均线的人不在少数,确实是广泛有效的指标)
- 均线类指标统计长度(timeperiod)变现最好的参数基本就是一个月交易日个数
- 择时指标开平仓普遍胜率不高,由此推测盈利主要来自于盈亏比
- 趋势类指标效果整体优于反转类指标
本篇为了避免个别标的自身特性的影响,都是拿指数进行的测试,然而不同指数本身也有各自的特点,可以借助已有的代码进行更多标的枚举暴力测试,通过多回测方法进一步挖掘更为有效的指标参数。
20181225:感谢@宋一堆 的改进思路,已将可用做空版代码附在评论区
20181225:感谢评论区sailer 和 iamrobot 的留言,文章统计结果已替换为修正后的结果,代码已更改附在评论区
#1 先导入所需要的程序包
import datetime
import numpy as np
import pandas as pd
import time
from jqdata import *
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import itertools
import copy
import pickle
# 定义类'参数分析'
class parameter_analysis(object):
# 定义函数中不同的变量
def __init__(self, algorithm_id=None):
self.algorithm_id = algorithm_id # 回测id
self.params_df = pd.DataFrame() # 回测中所有调参备选值的内容,列名字为对应修改面两名称,对应回测中的 g.XXXX
self.results = {} # 回测结果的回报率,key 为 params_df 的行序号,value 为
self.evaluations = {} # 回测结果的各项指标,key 为 params_df 的行序号,value 为一个 dataframe
self.backtest_ids = {} # 回测结果的 id
# 新加入的基准的回测结果 id,可以默认为空 '',则使用回测中设定的基准
self.benchmark_id = None
self.benchmark_returns = [] # 新加入的基准的回测回报率
self.returns = {} # 记录所有回报率
self.excess_returns = {} # 记录超额收益率
self.log_returns = {} # 记录收益率的 log 值
self.log_excess_returns = {} # 记录超额收益的 log 值
self.dates = [] # 回测对应的所有日期
self.excess_max_drawdown = {} # 计算超额收益的最大回撤
self.excess_annual_return = {} # 计算超额收益率的年化指标
self.evaluations_df = pd.DataFrame() # 记录各项回测指标,除日回报率外
# 定义排队运行多参数回测函数
def run_backtest(self, #
algorithm_id=None, # 回测策略id
running_max=10, # 回测中同时巡行最大回测数量
start_date='2006-01-01', # 回测的起始日期
end_date='2016-11-30', # 回测的结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测的初始持仓金额
param_names=[], # 回测中调整参数涉及的变量
param_values=[] # 回测中每个变量的备选参数值
):
# 当此处回测策略的 id 没有给出时,调用类输入的策略 id
if algorithm_id == None: algorithm_id=self.algorithm_id
# 生成所有参数组合并加载到 df 中
# 包含了不同参数具体备选值的排列组合中一组参数的 tuple 的 list
param_combinations = list(itertools.product(*param_values))
# 生成一个 dataframe, 对应的列为每个调参的变量,每个值为调参对应的备选值
to_run_df = pd.DataFrame(param_combinations)
# 修改列名称为调参变量的名字
to_run_df.columns = param_names
# 设定运行起始时间和保存格式
start = time.time()
# 记录结束的运行回测
finished_backtests = {}
# 记录运行中的回测
running_backtests = {}
# 计数器
pointer = 0
# 总运行回测数目,等于排列组合中的元素个数
total_backtest_num = len(param_combinations)
# 记录回测结果的回报率
all_results = {}
# 记录回测结果的各项指标
all_evaluations = {}
# 在运行开始时显示
print ('【已完成|运行中|待运行】:'),
# 当运行回测开始后,如果没有全部运行完全的话:
while len(finished_backtests)<total_backtest_num:
# 显示运行、完成和待运行的回测个数
print('[%s|%s|%s].' % (len(finished_backtests),
len(running_backtests),
(total_backtest_num-len(finished_backtests)-len(running_backtests)) )),
# 记录当前运行中的空位数量
to_run = min(running_max-len(running_backtests), total_backtest_num-len(running_backtests)-len(finished_backtests))
# 把可用的空位进行跑回测
for i in range(pointer, pointer+to_run):
# 备选的参数排列组合的 df 中第 i 行变成 dict,每个 key 为列名字,value 为 df 中对应的值
params = to_run_df.iloc[i].to_dict()
# 记录策略回测结果的 id,调整参数 extras 使用 params 的内容
backtest = create_backtest(algorithm_id = algorithm_id,
start_date = start_date,
end_date = end_date,
frequency = frequency,
initial_cash = initial_cash,
extras = params,
# 再回测中把改参数的结果起一个名字,包含了所有涉及的变量参数值
name = str(params)
)
# 记录运行中 i 回测的回测 id
running_backtests[i] = backtest
# 计数器计数运行完的数量
pointer = pointer+to_run
# 获取回测结果
failed = []
finished = []
# 对于运行中的回测,key 为 to_run_df 中所有排列组合中的序数
for key in running_backtests.keys():
# 研究调用回测的结果,running_backtests[key] 为运行中保存的结果 id
bt = get_backtest(running_backtests[key])
# 获得运行回测结果的状态,成功和失败都需要运行结束后返回,如果没有返回则运行没有结束
status = bt.get_status()
# 当运行回测失败
if status == 'failed':
# 失败 list 中记录对应的回测结果 id
failed.append(key)
# 当运行回测成功时
elif status == 'done':
# 成功 list 记录对应的回测结果 id,finish 仅记录运行成功的
finished.append(key)
# 回测回报率记录对应回测的回报率 dict, key to_run_df 中所有排列组合中的序数, value 为回报率的 dict
# 每个 value 一个 list 每个对象为一个包含时间、日回报率和基准回报率的 dict
all_results[key] = bt.get_results()
# 回测回报率记录对应回测结果指标 dict, key to_run_df 中所有排列组合中的序数, value 为回测结果指标的 dataframe
all_evaluations[key] = bt.get_risk()
# 记录运行中回测结果 id 的 list 中删除失败的运行
for key in failed:
running_backtests.pop(key)
# 在结束回测结果 dict 中记录运行成功的回测结果 id,同时在运行中的记录中删除该回测
for key in finished:
finished_backtests[key] = running_backtests.pop(key)
# 当一组同时运行的回测结束时报告时间
if len(finished_backtests) != 0 and len(finished_backtests) % running_max == 0 and to_run !=0:
# 记录当时时间
middle = time.time()
# 计算剩余时间,假设没工作量时间相等的话
remain_time = (middle - start) * (total_backtest_num - len(finished_backtests)) / len(finished_backtests)
# print 当前运行时间
print('[已用%s时,尚余%s时,请不要关闭浏览器].' % (str(round((middle - start) / 60.0 / 60.0,3)),
str(round(remain_time / 60.0 / 60.0,3)))),
# 5秒钟后再跑一下
time.sleep(30)
# 记录结束时间
end = time.time()
print ('')
print('【回测完成】总用时:%s秒(即%s小时)。' % (str(int(end-start)),
str(round((end-start)/60.0/60.0,2)))),
# 对应修改类内部对应
self.params_df = to_run_df
self.results = all_results
self.evaluations = all_evaluations
self.backtest_ids = finished_backtests
#7 最大回撤计算方法
def find_max_drawdown(self, returns):
# 定义最大回撤的变量
result = 0
# 记录最高的回报率点
historical_return = 0
# 遍历所有日期
for i in range(len(returns)):
# 最高回报率记录
historical_return = max(historical_return, returns[i])
# 最大回撤记录
drawdown = 1-(returns[i] + 1) / (historical_return + 1)
# 记录最大回撤
result = max(drawdown, result)
# 返回最大回撤值
return result
# log 收益、新基准下超额收益和相对与新基准的最大回撤
def organize_backtest_results(self, benchmark_id=None):
# 若新基准的回测结果 id 没给出
if benchmark_id==None:
# 使用默认的基准回报率,默认的基准在回测策略中设定
self.benchmark_returns = [x['benchmark_returns'] for x in self.results[0]]
# 当新基准指标给出后
else:
# 基准使用新加入的基准回测结果
self.benchmark_returns = [x['returns'] for x in get_backtest(benchmark_id).get_results()]
# 回测日期为结果中记录的第一项对应的日期
self.dates = [x['time'] for x in self.results[0]]
# 对应每个回测在所有备选回测中的顺序 (key),生成新数据
# 由 {key:{u'benchmark_returns': 0.022480100091729405,
# u'returns': 0.03184566700000002,
# u'time': u'2006-02-14'}} 格式转化为:
# {key: []} 格式,其中 list 为对应 date 的一个回报率 list
for key in self.results.keys():
self.returns[key] = [x['returns'] for x in self.results[key]]
# 生成对于基准(或新基准)的超额收益率
for key in self.results.keys():
self.excess_returns[key] = [(x+1)/(y+1)-1 for (x,y) in zip(self.returns[key], self.benchmark_returns)]
# 生成 log 形式的收益率
for key in self.results.keys():
self.log_returns[key] = [log(x+1) for x in self.returns[key]]
# 生成超额收益率的 log 形式
for key in self.results.keys():
self.log_excess_returns[key] = [log(x+1) for x in self.excess_returns[key]]
# 生成超额收益率的最大回撤
for key in self.results.keys():
self.excess_max_drawdown[key] = self.find_max_drawdown(self.excess_returns[key])
# 生成年化超额收益率
for key in self.results.keys():
self.excess_annual_return[key] = (self.excess_returns[key][-1]+1)**(252./float(len(self.dates)))-1
# 把调参数据中的参数组合 df 与对应结果的 df 进行合并
self.evaluations_df = pd.concat([self.params_df, pd.DataFrame(self.evaluations).T], axis=1)
# self.evaluations_df =
# 获取最总分析数据,调用排队回测函数和数据整理的函数
def get_backtest_data(self,
algorithm_id=None, # 回测策略id
benchmark_id=None, # 新基准回测结果id
file_name='results.pkl', # 保存结果的 pickle 文件名字
running_max=10, # 最大同时运行回测数量
start_date='2006-01-01', # 回测开始时间
end_date='2016-11-30', # 回测结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测初始持仓资金
param_names=[], # 回测需要测试的变量
param_values=[] # 对应每个变量的备选参数
):
# 调运排队回测函数,传递对应参数
self.run_backtest(algorithm_id=algorithm_id,
running_max=running_max,
start_date=start_date,
end_date=end_date,
frequency=frequency,
initial_cash=initial_cash,
param_names=param_names,
param_values=param_values
)
# 回测结果指标中加入 log 收益率和超额收益率等指标
self.organize_backtest_results(benchmark_id)
# 生成 dict 保存所有结果。
results = {'returns':self.returns,
'excess_returns':self.excess_returns,
'log_returns':self.log_returns,
'log_excess_returns':self.log_excess_returns,
'dates':self.dates,
'benchmark_returns':self.benchmark_returns,
'evaluations':self.evaluations,
'params_df':self.params_df,
'backtest_ids':self.backtest_ids,
'excess_max_drawdown':self.excess_max_drawdown,
'excess_annual_return':self.excess_annual_return,
'evaluations_df':self.evaluations_df}
# 保存 pickle 文件
pickle_file = open(file_name, 'wb')
pickle.dump(results, pickle_file)
pickle_file.close()
# 读取保存的 pickle 文件,赋予类中的对象名对应的保存内容
def read_backtest_data(self, file_name='results.pkl'):
pickle_file = open(file_name, 'rb')
results = pickle.load(pickle_file)
self.returns = results['returns']
self.excess_returns = results['excess_returns']
self.log_returns = results['log_returns']
self.log_excess_returns = results['log_excess_returns']
self.dates = results['dates']
self.benchmark_returns = results['benchmark_returns']
self.evaluations = results['evaluations']
self.params_df = results['params_df']
self.backtest_ids = results['backtest_ids']
self.excess_max_drawdown = results['excess_max_drawdown']
self.excess_annual_return = results['excess_annual_return']
self.evaluations_df = results['evaluations_df']
# 回报率折线图
def plot_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.returns[key])), self.returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), self.benchmark_returns, label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.returns[0]))
# 超额收益率图
def plot_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.excess_returns[key])), self.excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('excess returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.excess_returns[0]))
# log回报率图
def plot_log_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_returns[key])), self.log_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [log(x+1) for x in self.benchmark_returns], label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_returns[0]))
# 超额收益率的 log 图
def plot_log_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_excess_returns[key])), self.log_excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log excess returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_excess_returns[0]))
# 回测的4个主要指标,包括总回报率、最大回撤夏普率和波动
def get_eval4_bar(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
fig = plt.figure(figsize=(20,7))
# 定义位置
ax1 = fig.add_subplot(221)
# 设定横轴为对应分位,纵轴为对应指标
ax1.bar(range(len(indices)),
[self.evaluations[x]['algorithm_return'] for x in indices], 0.6, label = 'Algorithm_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax1.legend(loc='best',fontsize=15)
# 设置y标签样式
ax1.set_ylabel('Algorithm_return', fontsize=15)
# 设置y标签样式
ax1.set_yticklabels([str(x*100)+'% 'for x in ax1.get_yticks()])
# 设置图片标题样式
ax1.set_title("Strategy's of Algorithm_return performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax2 = fig.add_subplot(224)
# 设定横轴为对应分位,纵轴为对应指标
ax2.bar(range(len(indices)),
[self.evaluations[x]['max_drawdown'] for x in indices], 0.6, label = 'Max_drawdown')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax2.legend(loc='best',fontsize=15)
# 设置y标签样式
ax2.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax2.set_yticklabels([str(x*100)+'% 'for x in ax2.get_yticks()])
# 设置图片标题样式
ax2.set_title("Strategy's of Max_drawdown performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax3 = fig.add_subplot(223)
# 设定横轴为对应分位,纵轴为对应指标
ax3.bar(range(len(indices)),
[self.evaluations[x]['sharpe'] for x in indices], 0.6, label = 'Sharpe')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax3.legend(loc='best',fontsize=15)
# 设置y标签样式
ax3.set_ylabel('Sharpe', fontsize=15)
# 设置x标签样式
ax3.set_yticklabels([str(x*100)+'% 'for x in ax3.get_yticks()])
# 设置图片标题样式
ax3.set_title("Strategy's of Sharpe performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax4 = fig.add_subplot(222)
# 设定横轴为对应分位,纵轴为对应指标
ax4.bar(range(len(indices)),
[self.evaluations[x]['algorithm_volatility'] for x in indices], 0.6, label = 'Algorithm_volatility')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax4.legend(loc='best',fontsize=15)
# 设置y标签样式
ax4.set_ylabel('Algorithm_volatility', fontsize=15)
# 设置x标签样式
ax4.set_yticklabels([str(x*100)+'% 'for x in ax4.get_yticks()])
# 设置图片标题样式
ax4.set_title("Strategy's of Algorithm_volatility performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
#14 年化回报和最大回撤,正负双色表示
def get_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.evaluations[x]['max_drawdown'] for x in indices], color = '#32CD32',
width = 0.6, label = 'Max_drawdown', zorder=10)
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.evaluations[x]['annual_algo_return'] for x in indices], color = 'r',
width = 0.6, label = 'Annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
#14 超额收益的年化回报和最大回撤
# 加入新的benchmark后超额收益和
def get_excess_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.excess_max_drawdown[x] for x in indices], color = '#32CD32',
width = 0.6, label = 'Excess_max_drawdown')
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.excess_annual_return[x] for x in indices], color = 'r',
width = 0.6, label = 'Excess_annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
应用多策略回测框架,统计回测结果¶
- 根据回测algorithmId在研究中创建策略
- 设置不同指标的回测组别
- 读取回测结果进行展示
#2 设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('5473a8b9e878d36100307a7d1c0405ee')
#3 运行回测
pa.get_backtest_data(file_name = 'results1.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['tech'],
param_values = [['None','MA','MA1','EMA','EMA1','MACD','KDJ','CCI','RSI','BOLL','BIAS','TRIX','BBI','PSY']]
)
#4 数据读取
pa.read_backtest_data('results1.pkl')
#5 查看回测参数的df
pa.params_df
#6 查看回测结果指标
df = pa.evaluations_df
df
#7 回报率折线图
pa.plot_returns()

#8 超额收益率图
pa.plot_excess_returns()

#指标回测收益列表
df.index = df['tech'].values
del df['tech']
df = df[['algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df.sort_values('algorithm_return',ascending=0)
#11 回测的4个主要指标,包括总回报率、最大回撤夏普率和波动
# get_eval4_bar(self, sort_by=[])
pa.get_eval4_bar()

在上证50上的择时表现¶
#2 设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('5473a8b9e878d36100307a7d1c0405ee')
#3 运行回测
pa.get_backtest_data(file_name = 'results1.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['stock','tech'],
param_values = [['000016.XSHG'],['None','MA','MA1','EMA','EMA1','MACD','KDJ','CCI','RSI','BOLL','BIAS','TRIX','BBI','PSY']]
)
#数据读取
pa.read_backtest_data('results1.pkl')
#查看回测结果指标
df1 = pa.evaluations_df
df1
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df1.index = df1['tech'].values
del df1['tech']
df1 = df1[['algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df1.sort_values('algorithm_return',ascending=0)
#2 设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('5473a8b9e878d36100307a7d1c0405ee')
#3 运行回测
pa.get_backtest_data(file_name = 'results1.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['stock','tech'],
param_values = [['000905.XSHG'],['None','MA','MA1','EMA','EMA1','MACD','KDJ','CCI','RSI','BOLL','BIAS','TRIX','BBI','PSY']]
)
#数据读取
pa.read_backtest_data('results1.pkl')
#查看回测结果指标
df2 = pa.evaluations_df
df2
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df2.index = df2['tech'].values
del df2['tech']
df2 = df2[['algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df2.sort_values('algorithm_return',ascending=0)
#设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('5473a8b9e878d36100307a7d1c0405ee')
#3 运行回测
pa.get_backtest_data(file_name = 'results3.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['stock','tech'],
param_values = [['000852.XSHG'],['None','MA','MA1','EMA','EMA1','MACD','KDJ','CCI','RSI','BOLL','BIAS','TRIX','BBI','PSY']]
)
#数据读取
pa.read_backtest_data('results3.pkl')
#查看回测结果指标
df3 = pa.evaluations_df
df3
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df3.index = df3['tech'].values
del df3['tech']
df3 = df3[['algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df3.sort_values('algorithm_return',ascending=0)
参数加强¶
KDJ沪深300加强¶
#设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('5473a8b9e878d36100307a7d1c0405ee')
#运行回测
pa.get_backtest_data(file_name = 'results4.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['para1','para2'],
param_values = [[5,7,9,11,13,15,17,19,36],[3,4]]
)
#数据读取
pa.read_backtest_data('results4.pkl')
#查看回测结果指标
df4 = pa.evaluations_df
df4
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df4 = df4[['para1','para2','algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df4.sort_values('algorithm_return',ascending=0)
BOLL中证1000参数测试¶
#设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('f0c6eb90370078648d793bf93bb876b0')
#运行回测
pa.get_backtest_data(file_name = 'results6.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['para1'],
param_values = [['10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','30']]
)
#数据读取
pa.read_backtest_data('results6.pkl')
#查看回测结果指标
df6 = pa.evaluations_df
df6
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df6 = df6[['para1','algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df6.sort_values('algorithm_return',ascending=0)
df6.index = df6['para1'].values
df6[['para1','algorithm_return']].plot()

EMA中证500加强¶
#设定回测策略 id
# 注意!注意!注意!这里的id是在 我的策略里面的编译运行的algorithmId,在浏览器地址里面复制一下
pa = parameter_analysis('f50a271853f177b4d3d30b14eff6c7fe')
#运行回测
pa.get_backtest_data(file_name = 'results5.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2008-12-05',
end_date = '2018-12-05',
frequency = 'day',
initial_cash = '100000000',
param_names = ['para1','para2'],
param_values = [['10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','30'],[3]]
)
#数据读取
pa.read_backtest_data('results5.pkl')
#查看回测结果指标
df5 = pa.evaluations_df
df5
#7 回报率折线图
pa.plot_returns()

#指标回测收益列表
df5 = df5[['para1','para2','algorithm_return','alpha','sharpe','win_ratio','max_drawdown_period']]
df5.sort_values('algorithm_return',ascending=0)
df5.index = df5['para1'].values
df5[['para1','algorithm_return']].plot()