在近几年与行业内优秀的量化交易者接触后,发现他们来自各个领域,带有不同且有趣的学习和从业经历,其中部分人之前从事的IT开发工作让他们更适合量化投资这条道路,他们多拥有深厚的工科背景,在业绩方面比传统金融人更胜一筹。
在国外量化投资领域也存在这一问题,较早出名的量化基金经理——爱德华?索普(Edward Thorp)是加州大学洛杉矶分校的一名物理系研究生,他最感兴趣的是数学。再到后来的传奇高频交易人物德邵(D*id.E.Shaw),这位计算机领域的顶级专家在科学研究上硕果累累,利用超级计算机实现了可观的盈利。后来就是我们熟悉的活跃至今的世界级数学家詹姆斯?西蒙斯(James Simons),也是在数学和工科领域有卓越贡献,后来活跃于量化投资领域并成为伟大的对冲基金经理。

在职业投资这条长期道路上,有人赢在开头,有人输在途中,有人赢在最后。从我们对量化模型的认知,再到对于近几年市场的变化,再到建模环节必要的技能分析,我们发现目前庞大的程序员群体做数量化投资有优势,是有迹可循的。本文简单整理以下几个观点供大家参考讨论。
一、无语言门槛,入门速度快
从最直观的角度讲,建立量化模型离不开代码编写,目前我们熟知的代码主要有python和matlab等直观的解释性语言,但是早年需要用Pascal、Fortran、C等语言开发模型,首先必须掌握开发语言,才能谈得上进入这个门槛。
目前国内有大量的程序员群体,无论是web开发还是数据分析,亦或是其他计算机软硬件系统开发,他们在语言方面不成问题,在模型开发的第一个环节就没有障碍。

因为获得一段战胜市场的资金曲线,并非易事,同时国内金融市场的数据缺乏和不成熟等原因,导致市场风格变化较快,所以量化学习者往往进入这个门槛后,也有较高的流失率。而掌握自己熟练的编程语言,比如python这种方便的语言,会帮助投资者快速应对不同挑战,反复迭代修改策略,在入门快的基础上,更容易随市场变化而变化开发新策略。相信程序员这个群体的抗压能力和入门速度,都比其他群体要快很多。
二、数学知识体系完整
程序员的理工科背景,基本无需担心。大部分专业拥有完整的数学知识体系。如果你只是想“开发”能够运行的程序, 可能并不需要太多数学,但是要是想成为计算机科学者或工程师, 恐怕还是要学数学的,尤其是构建先对完整的知识体系。
计算机本身的工具属性决定了计算机的发展必须和具体行业或者学科结合起来,最后利用计算机完成人工手工无法完成的工作,比如超大运算量,尤其在理工科用的最多,大部分理工科都是以数学为基础的,那么计算机上处理最多的就是各种数学模型与运算,而这些都离不开各种数学知识。
在果壳网上,有一段评论我觉得适合与各位读者分享:Google的page rank算法是线性代数特征值理论的一个重要应用,很多问题最终都能化为求解线性方程组问题例如,用有限差分法或有限元法解偏微分方程,用最小二乘法求最佳逼近等等)。线性代数知识还常在机器学习或数据挖掘中被用来降低数据的维度,还有很多其他的应用。
概率论、数理统计、随机过程在最近的人工智能的各个领域则是非常重要的基础,很多机器学习算法都是基于统计模型的,像Bayes统计应用极为广泛,例如垃圾邮件过滤。
离散数学和数值分析和计算机的关系就比较容易看出来了,离散数学不同的书选取的内容不大一样,不过一般都有逻辑、图论、自动机等等,一看就和计算机关系紧密。数学理论大多是抽象的,想在计算机上用就离不开数值分析;用数值方法解一些无法求出解析解的方程也很有实用价值。
三、思维不受传统金融规则束缚
我们不得不承认,传统的金融市场规则,和金融学经济学知识,完成了基本的市场定价支撑,也让交易制度和二级市场定价得以出现在大众面前。但是经典定价理论,也影响了我们的思维定式,让我们难以跳出传统框架思考问题。所以我觉得不受传统经典金融模型的束缚反倒是程序员的一个优势。
投资标的方面,做传统基本面分析的交易者很少有人能跨几个市场、多个品种,基本上是对有限几个品种进行深入研究。而量化它是某种程度上用机器代替人,可以全市场、多品种、分散化。因为量化的优势是信息的广度和计算的速度,而人的优势是小样本的泛化理解能力。
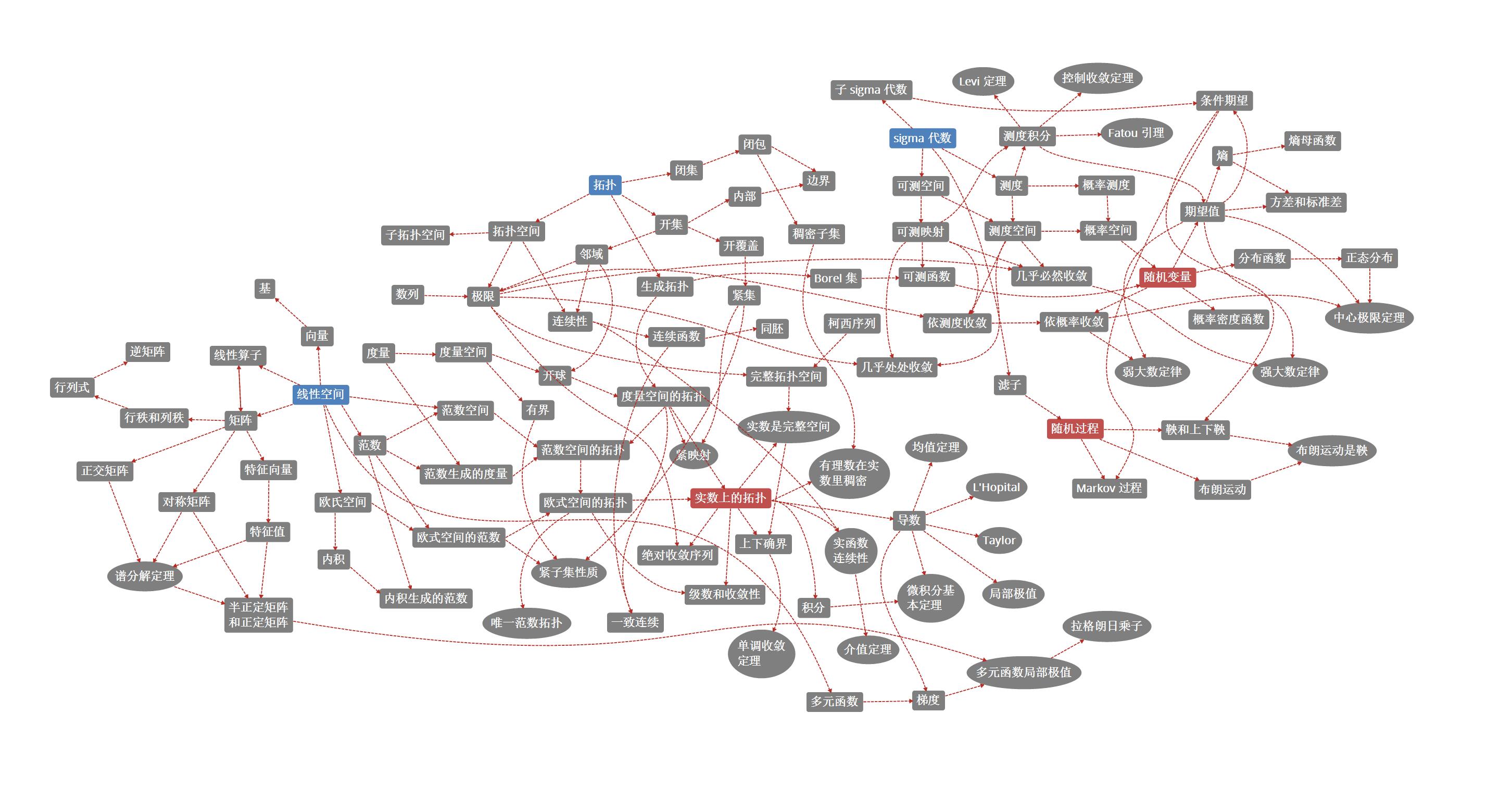
从数据频度上看,传统金融规则更多分析供求,分析货币,分析企业基本面估值模型,而量化投资更多从数学统计学入手,分析较为高频的因子,比如市场交易特征、交易者行为和心理偏差、多种宏观微观因素的高纬度叠加决策。在此基础上,我们看到很多模型,以股票模型为例,已经远远超出了传统估值定价模型,而是沿着资本资产定价模型(CAPM)和套利定价理论(APT),试图用数据解释收益率。
这种适合数量化金融处理的模型理论,可以使我们在处理大量证券定价的便捷性以及考虑风险收益特征的优越性上,提供了以往我们从传统投资所不能够达到的东西。再加上计算机处理效率高,计算效率随着CPU快速迭代和GPU并行计算的加入而提升。
四、能够执行完整交易流程,特别是底层数据获取和交易接口开发
我们见到很多交易者能够基于已有IT平台开发交易策略,甚至分析评价自己的交易策略稳健性,做参数检验等数值分析。但是在对接期货CTP接口,在接收数据、清洗数据、存储数据、回测引擎的构建方面,显得实力不足。
这种实力不足在短期内是可以通过第三方软件弥补的,比如使用文华财经或者交易开拓者等软件做期货,使用聚宽等平台做股票。但是仔细想来,平台帮助你完成了除构建策略外的所有工作,也让你对于回测框架,回测性能,策略执行原理,函数效率等细节不再关注。
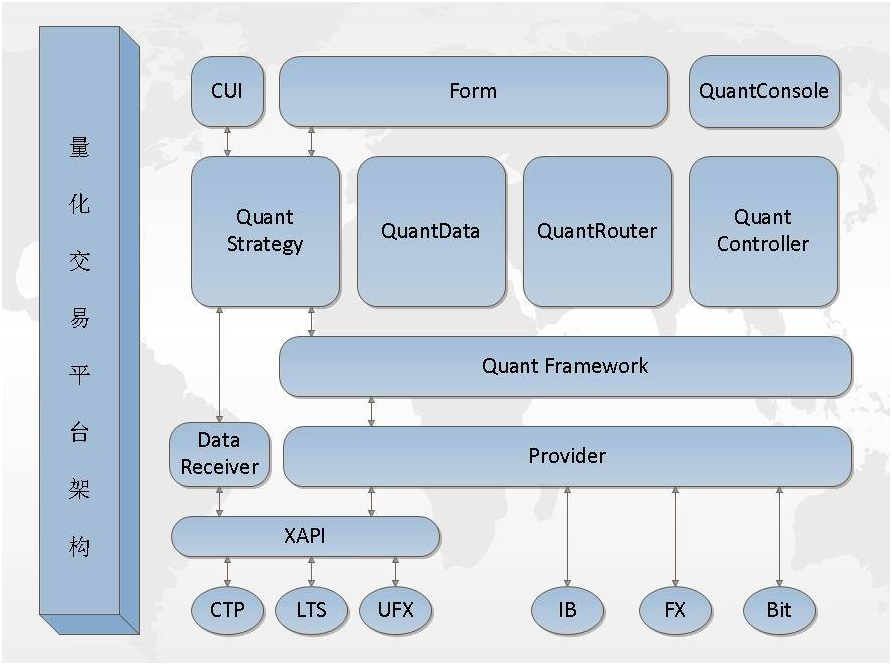
所以我们看到,很多优秀的交易者在成长到中后期时,基本上都拥有独立构建IT系统的能力,这里所说的IT系统包括了多维度多因子数据的抓取、非结构化数据的获取和整理、部分使用NLP自然语言识别方法进行因子*等前端工作。在后端,则是对接交易所接口完成下单、仓位检查、市场监控、风险控制等逻辑。
总结:补充知识,扬长避短,方可持续进步
虽然存在很多优点,但是对于新手理工科程序员直接进行量化投资模型的构建,我们也有几点小提示,这些知识点往往会成为限制你前进的阻力。
比如说对于金融经典理论体系需要再次构建,因为对于很多量化因子数据的经济学含义不清晰,导致了程序员群体对于中低频中长期财务因子对市场的影响力敏感性低,实际上中低频财务因子在国内股票市场越来越有效的情况下,能够发挥更大的收益解释能力。
近几年反而是随着流动性的衰退,交易行为类因子的效用下降,市场估值因子因为上市发审制度的变化,从alpha风格因子变化为风险因子,不能再随意使用。分析师类因子随着卖方投研体系的完善也变得更有效,研报注水和低质量等问题得到改善。反应企业内在价值的ROE、现金流等因子开始呈现出越来越显著的好坏股票区分能力,所以补充自己所缺乏的知识,找到因子内在经济金融逻辑,而不是上手后直接采用机器学习对海量因子做分析,更有利于长期发展。
再比如说,有数学功底和IT编程知识,并不意味着掌握算法级别的知识。应对高维度数据(股票模型通常有几十个上百个因子,需要调整其中关系,剔除异常数据和相关性影响),你不仅需要基础的线性回归,还需要掌握机器学习,而在校和工作阶段,学习机器学习类模型只能通过自学,大部分教程也仅是讲解案例和模型调用方式,鲜有讲解模型内部数学结构,这要求我们在持续补充知识,自学能力就显得格外重要。
最后希望交易者了解市场微观结构的同时,将目光放在更多金融产品上,了解金融机构的运作流程,了解货币对于金融市场升跌和关键经济指标的传导,了解我们目前处于什么样的经济周期,在合适的时间做合适的事。
注:本文作者在公募基金从业5年,中山大学数学学士,中央财经大学金融学硕士,长期从事数量化模型开发(以股票多因子为主),管理资产规模超10亿元。作者也是聚宽平台忠实用户,在社区内分享了众多高质量模型。