近段时间A股可以说是内忧外患,内有经济转型面临的短期困难,外有贸易战以及全球股市表现拖累等影响,一再突破前期低点,让人不禁感慨“敢问底在何方?”。刚好最近在学习数据可视化,于是就整理了一些目前A股市场的信息帮助大家参考、判断。
(注:若无特别说明,以下数据均选取自2007年1月1日至2018年11月30日,单日数据来自2018年11月30日。若需要其他日期数据,请克隆代码自行调整日期参数。)
一、A股上市公司市值分布情况
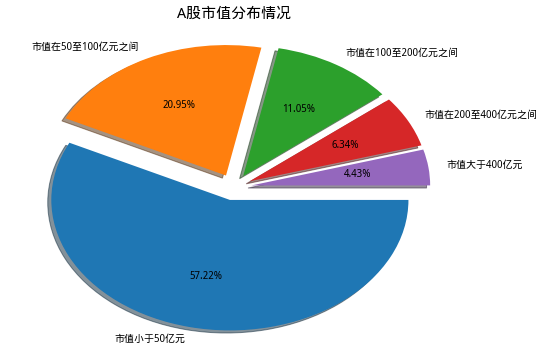
- A股一半以上的股票市值小于50亿元,将近80%的股票市值在200亿以下,这一方面说明A股大部分上市公司市值偏低,实力相对不强;另一方面也是近期市场人气低迷,投资者对上市公司的估值下调,导致股价持续下跌拖累市值。实际上,根据著名的Fama-Franch三因子理论,投资小市值公司比大市值公司更有机会取得超额收益,因此目前投资A股的机会其实是越来越大的。大市值公司方面,只有4.43%的股票市值在400亿元以上,其中有6支股票市值更是超过了10000亿元,而在5000至10000亿元市值的股票仅有4支。但同时,这10支市值在5000亿元以上的股票,大约占去了A股总市值的20%。(具体前几名可运行代码得到,在这里就不贴出来了。)
二、行业总市值、流通市值占比
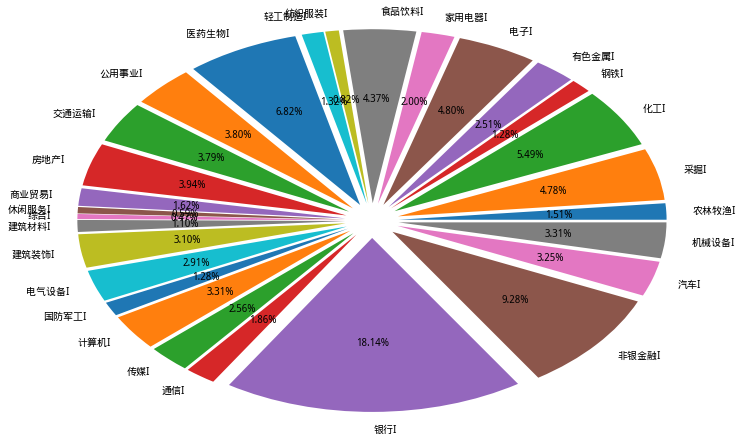
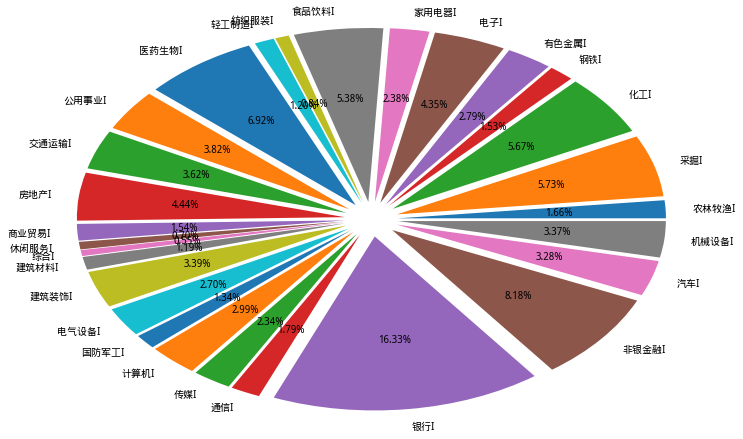
- 上面第一幅图是行业总市值占比,第二幅图是行业流通市值占比。根据申万一级行业分类统计,市值占比前三的行业依次是银行、非银金融和医药生物,其中银行占有A股将近20%的市值。而流通市值占比排名没有显著变化,但在百分比上银行和非银金融下降了约1%—2%。
三、市场整体基础财务指标走势
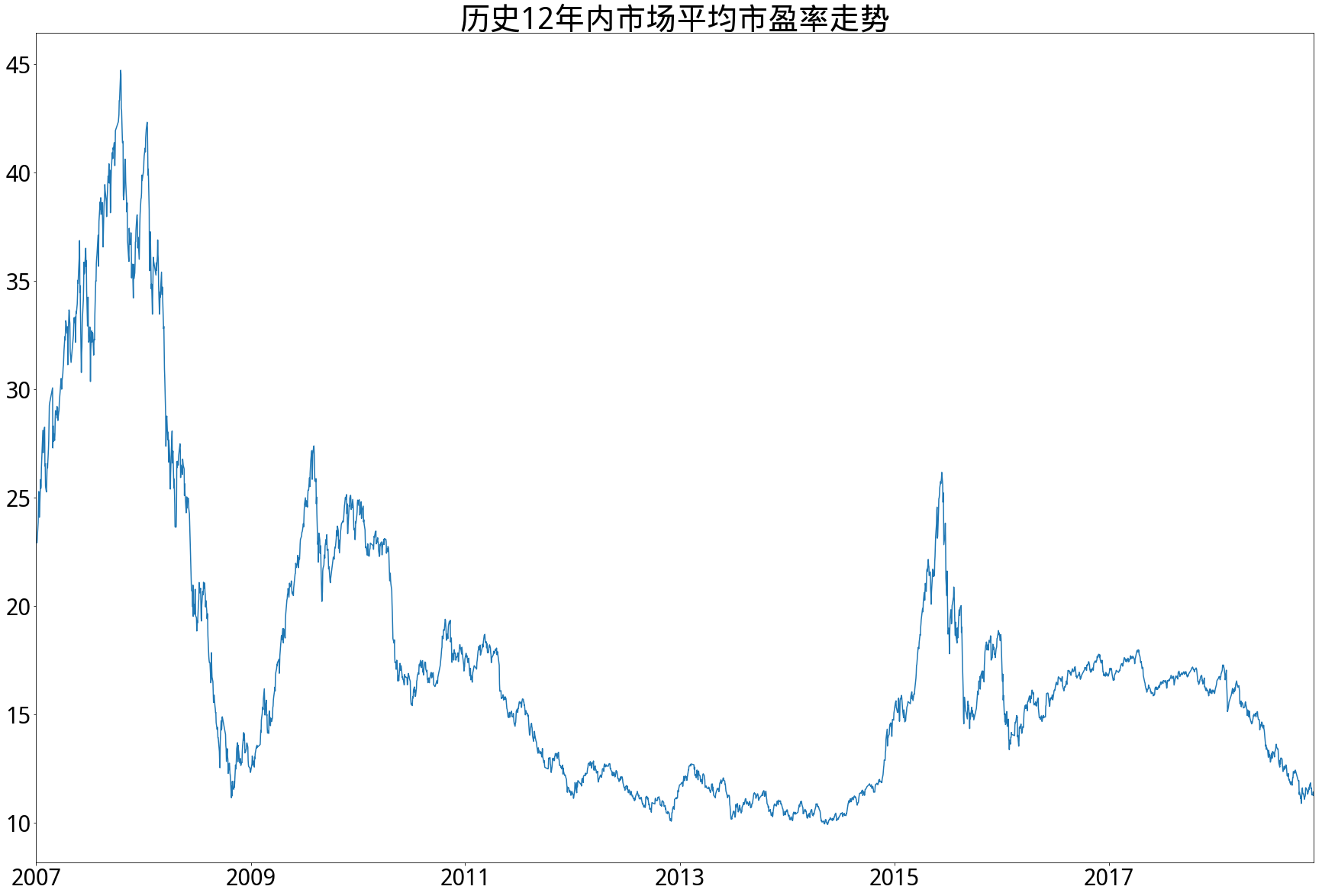
- 从A股市场历史平均市盈率数据来看,75%的时间内,平均市盈率在19倍以下。平均市盈率在12.32倍以下的时间只占25%,而目前11-12倍的市场平均市盈率,单从这一个数据来看,已经可以被称为市场底部。
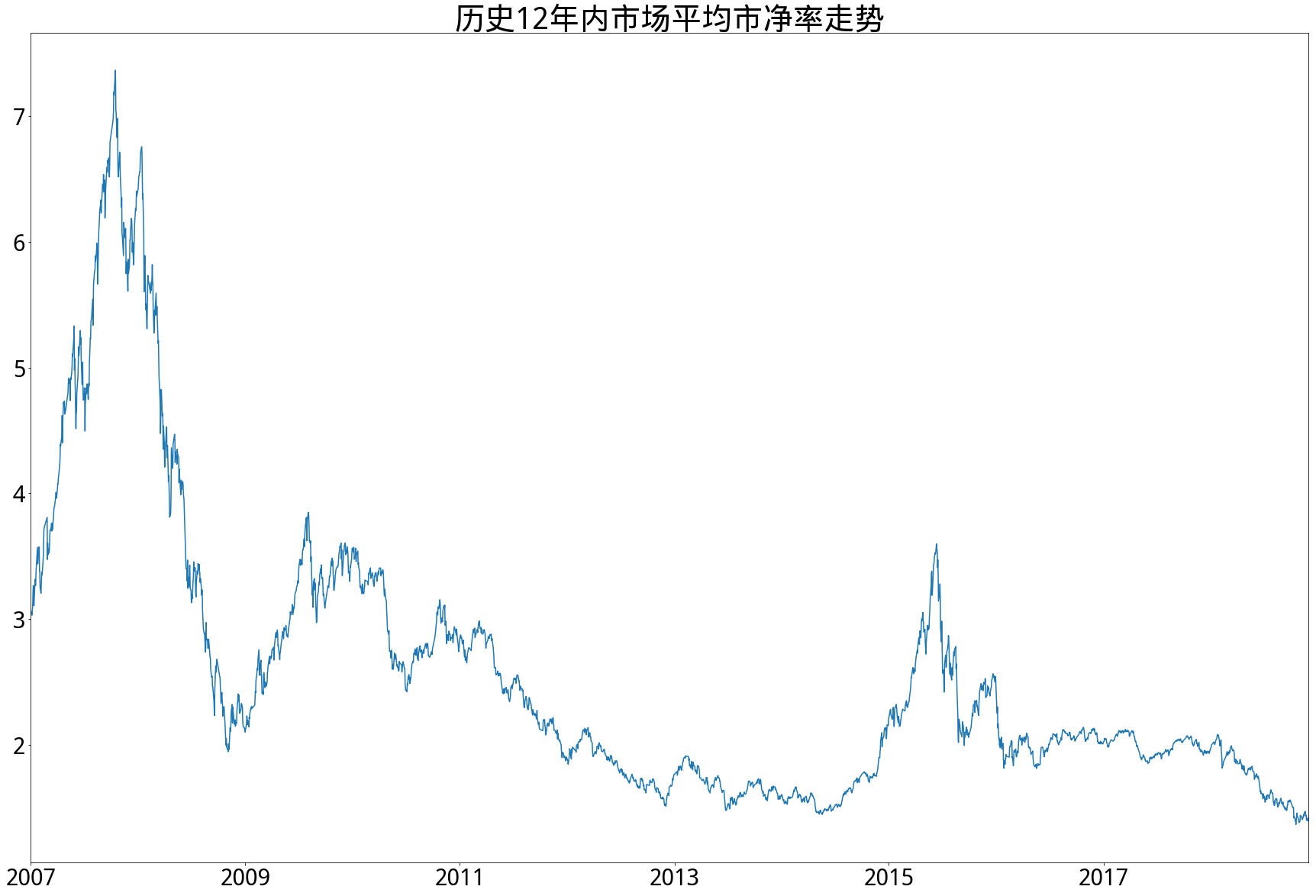
- 市净率方面,A股市场历史市净率走势与市盈率几乎相同,最大的不同点是目前1.4倍左右的市净率低于全部数据的1%分位数,处于历史最低区间。市场都快破净了,底部大概也快到了吧。
(这里我们只选取了市盈率和市净率两个指标,需要其他指标改改代码就可以了。)
四、分行业财务指标值
先上图
1.历史分行业平均市盈率变动情况
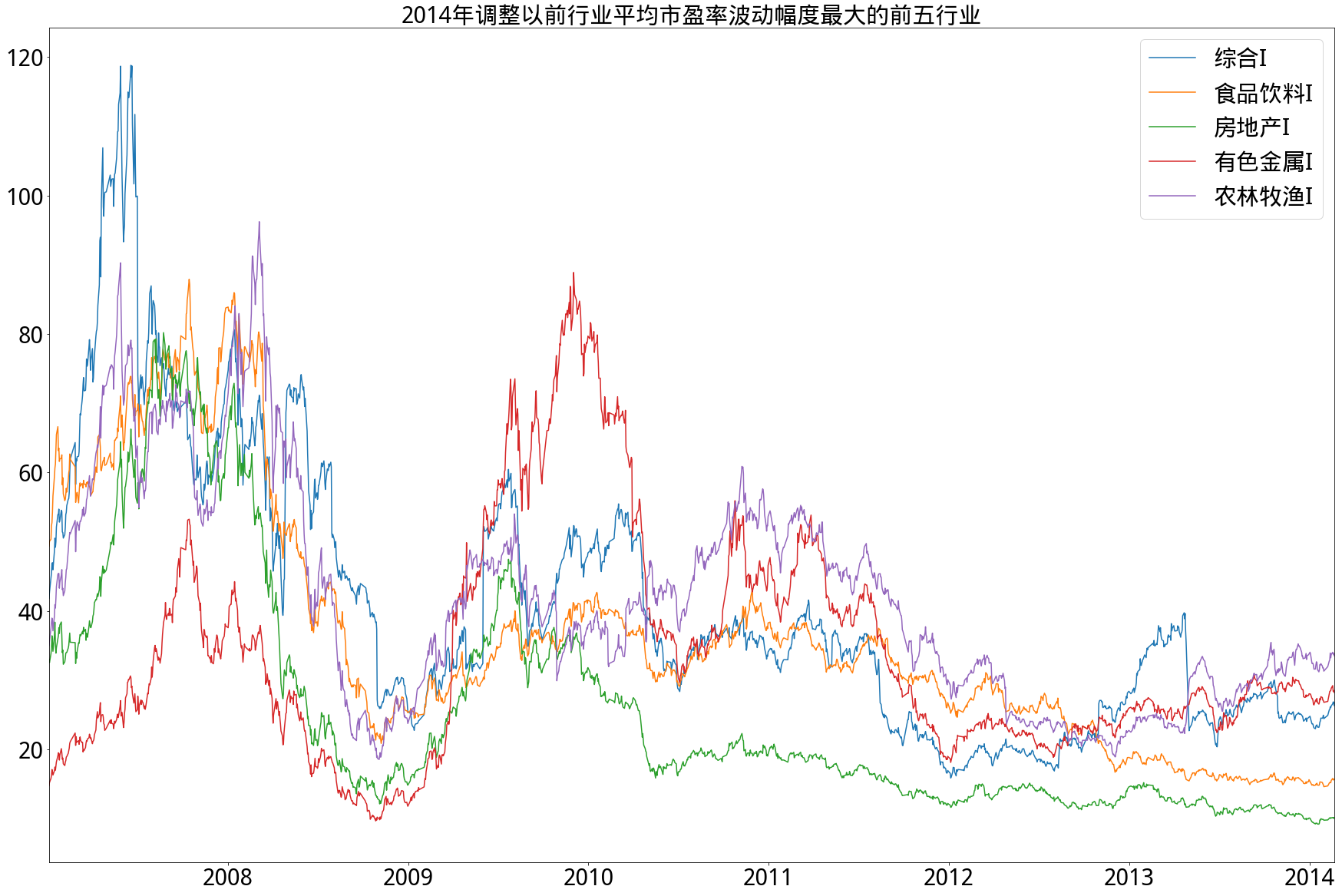
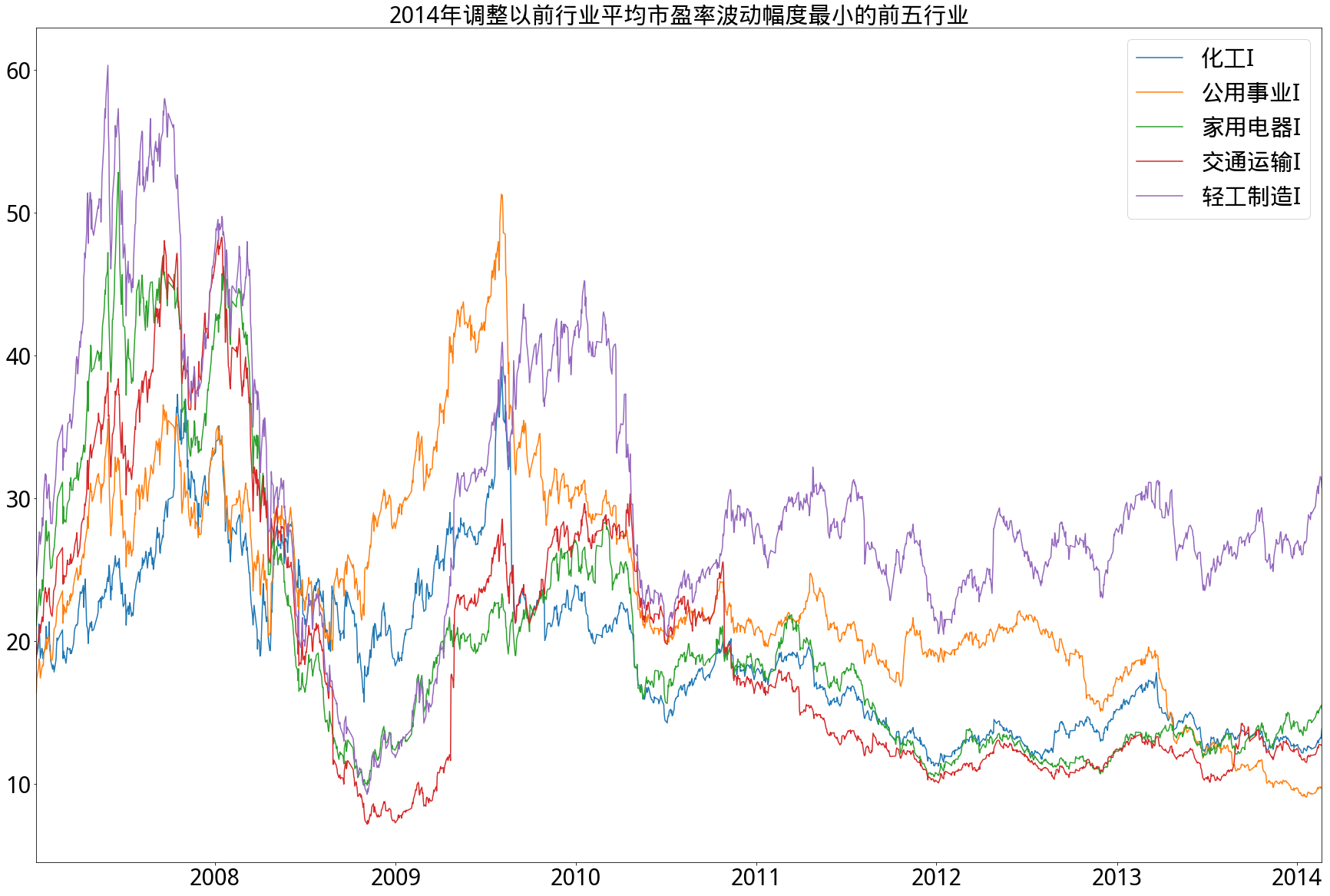
- A)2014年以前
- B)2014年以后
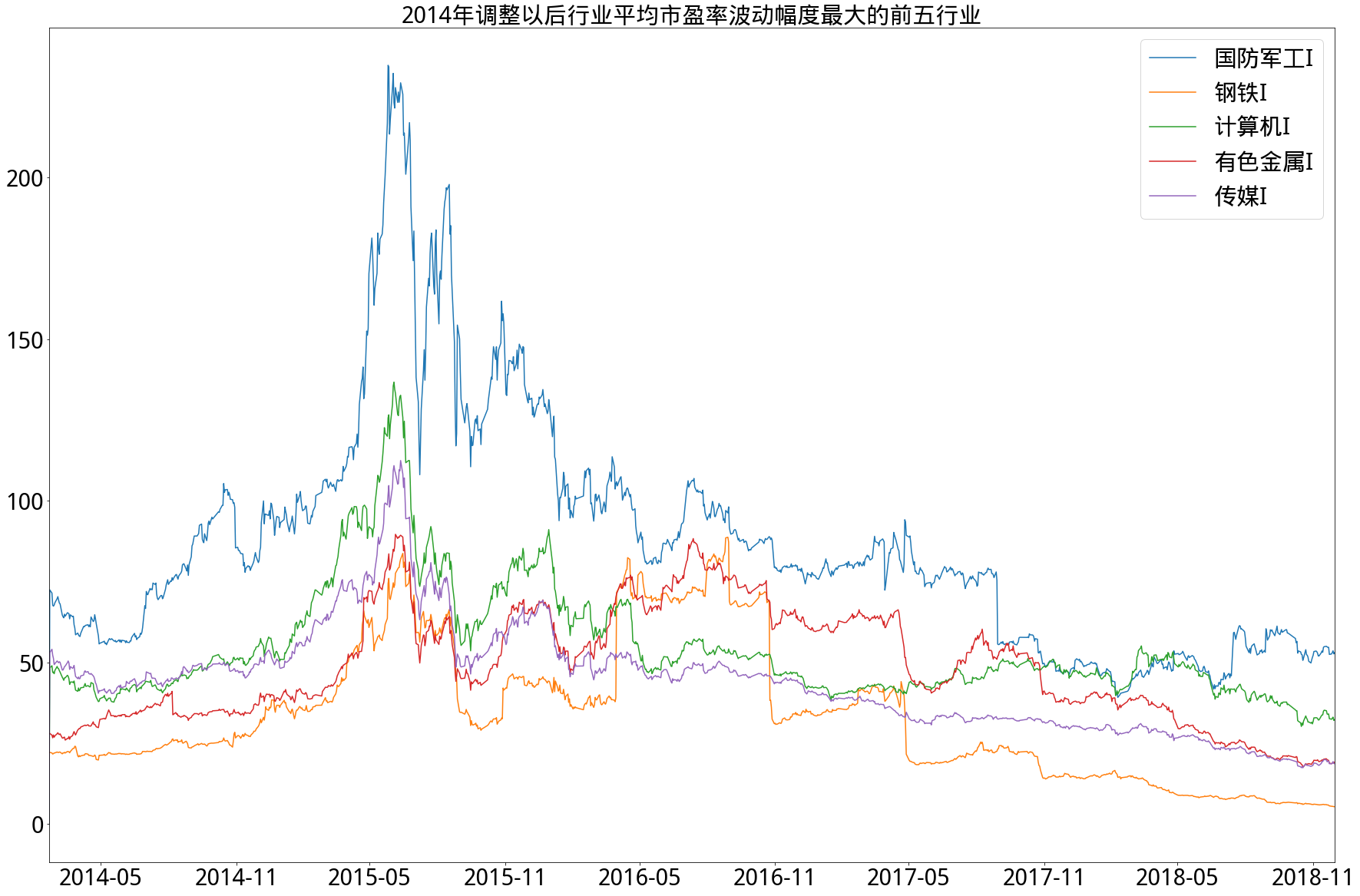
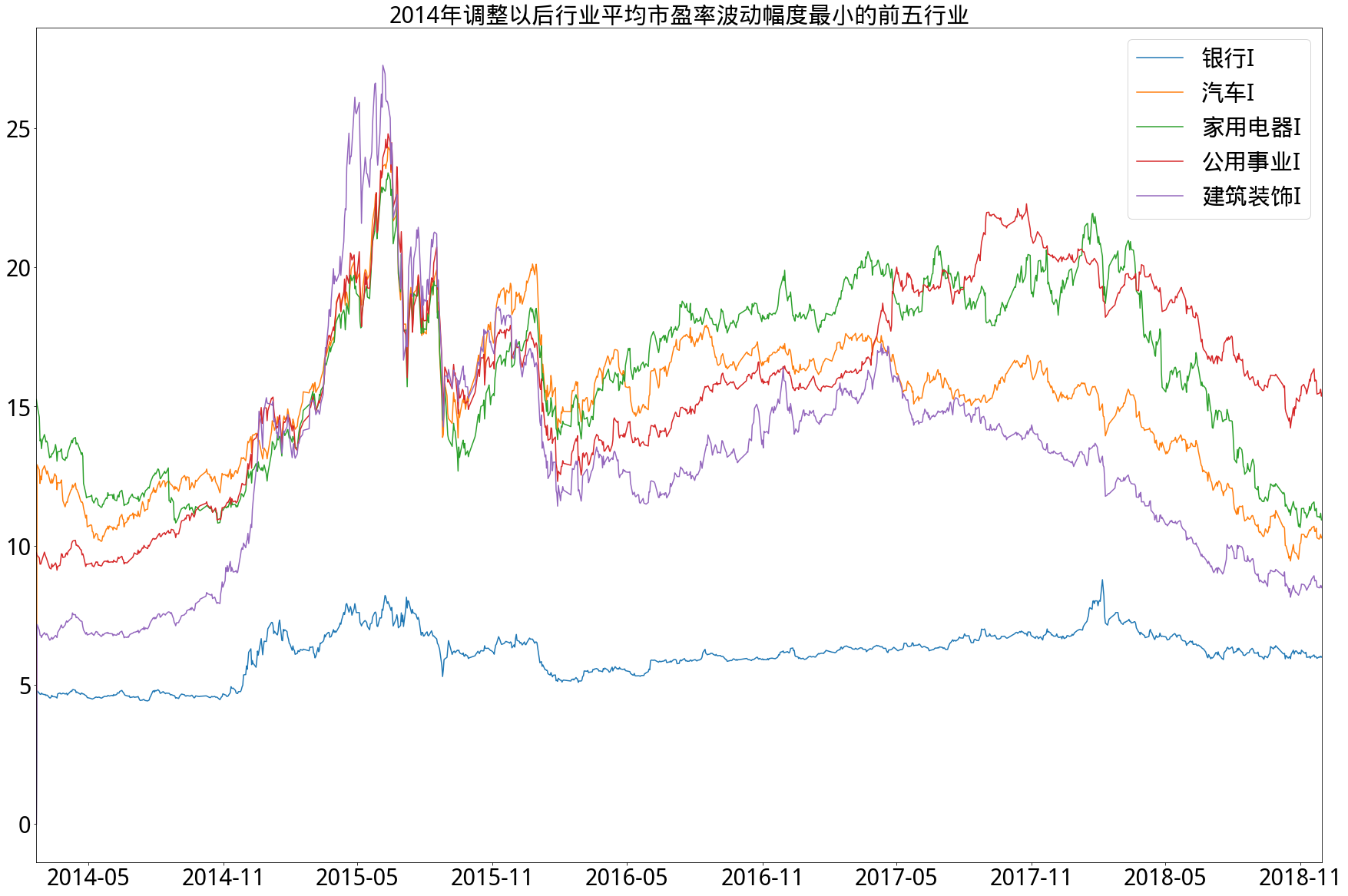
2.历史分行业平均市净率变动情况
- A)2014年以前
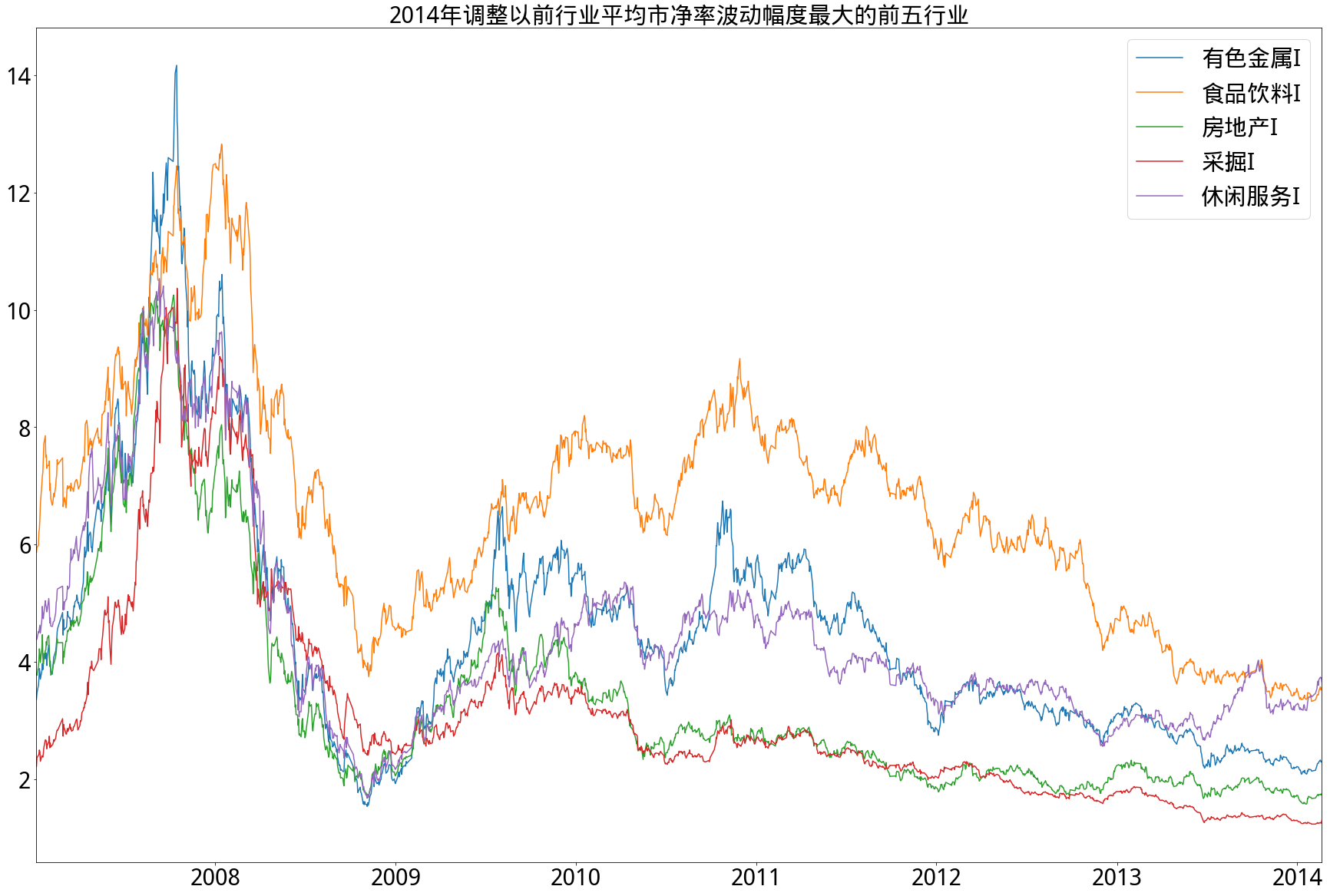
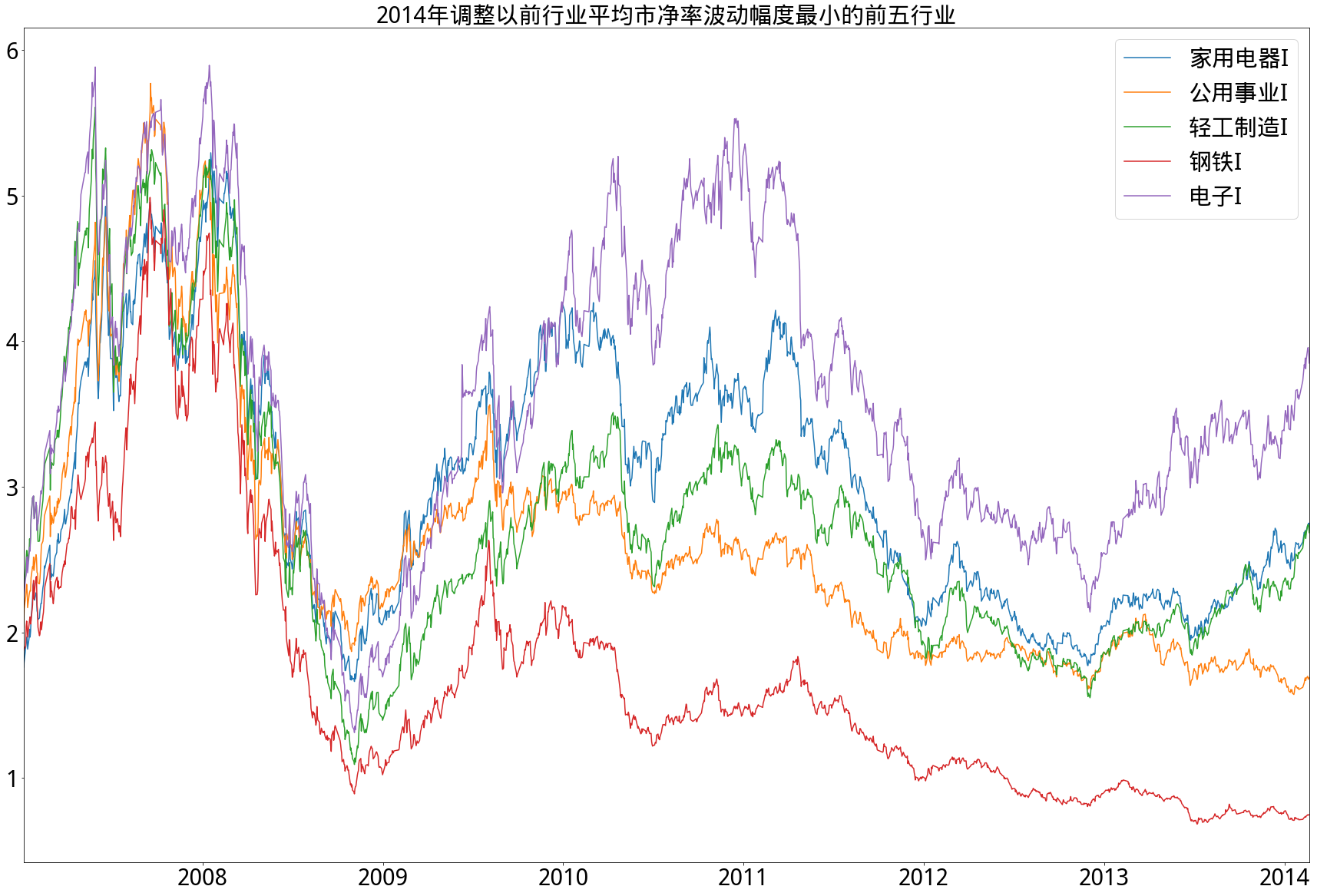
- B)2014年以后
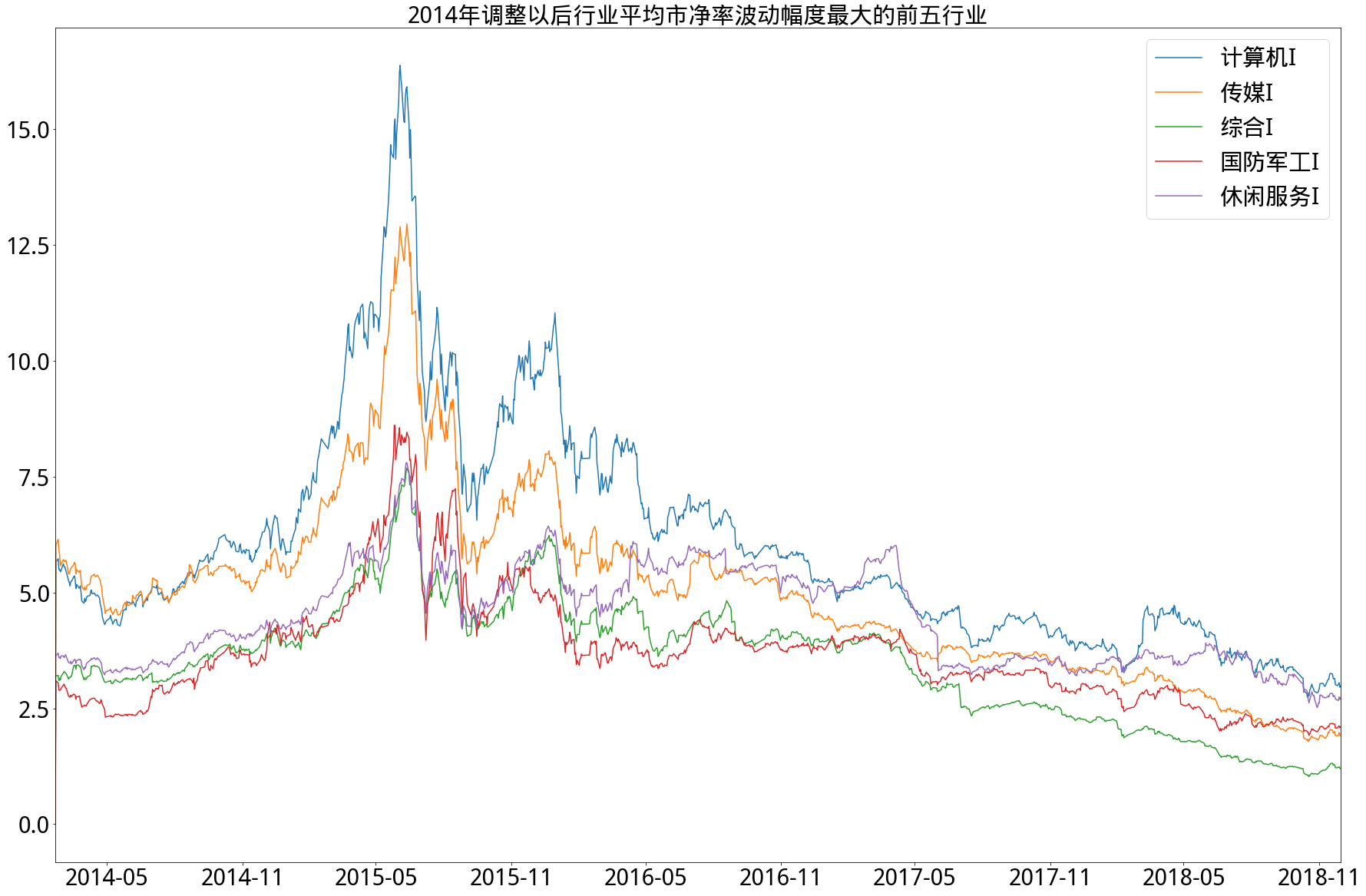
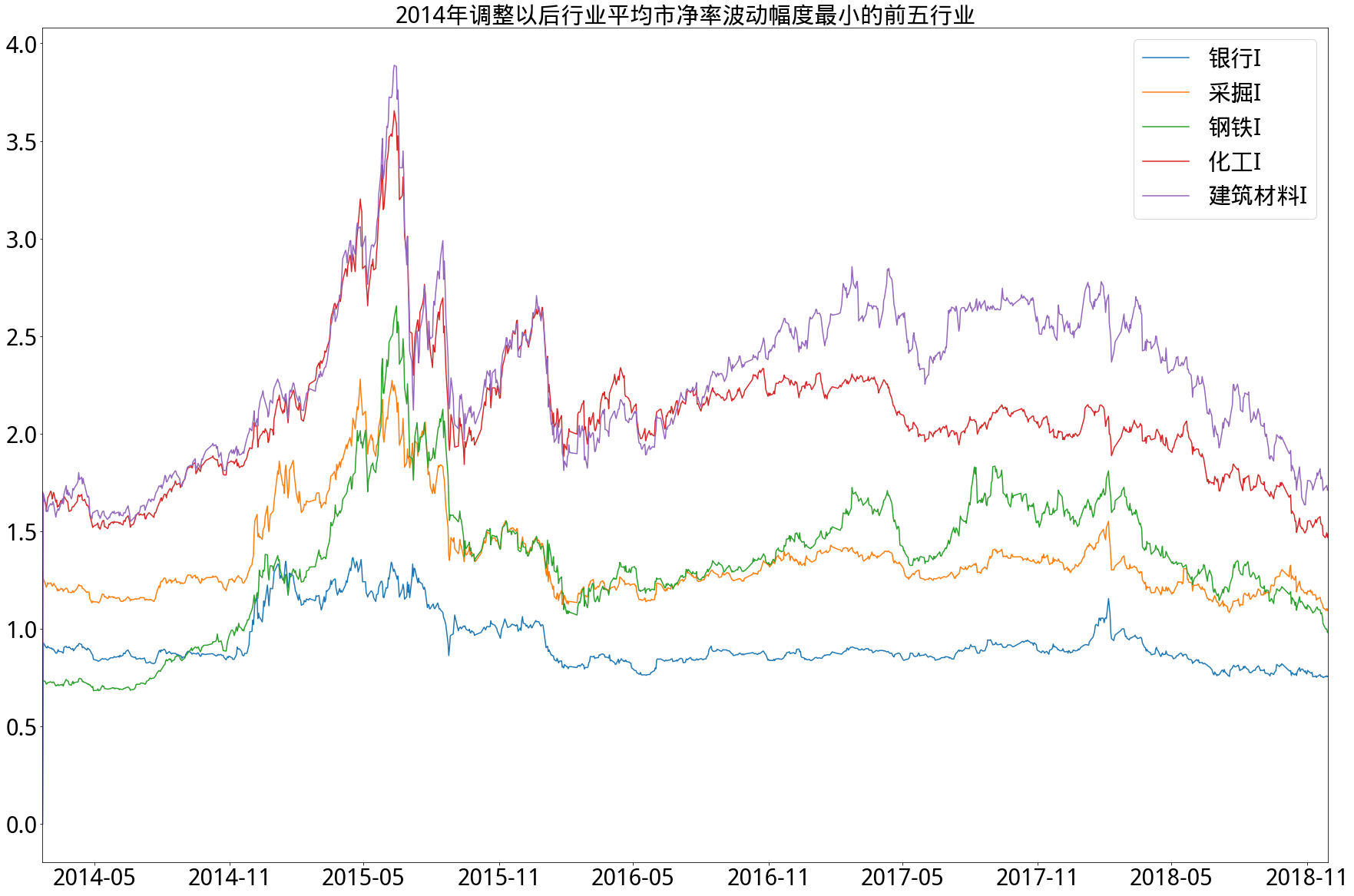
3.综合分析
- 从市盈率角度来看,在2014年调整以前的17个申万一级行业中,尽管波动率不尽相同,但相对集中,即波动率相差不大,波动率相对最低的五个行业其绝对数值也不是很小。而在2014年调整以后的28个申万行业中,分化相对明显,新加入的国防军工行业平均市盈率绝对值甚至一度超过200倍,而新加入的银行行业平均市盈率基本上始终保持在5-10倍之间,在图中明显远低于其他行业。另外,无论在调整前后,始终保持高波动率的是有色金属行业,始终保持低波动率的是家用电器和公用事业行业。
- 从市净率角度来看,情况和市盈率类似,即2014年以前相对集中,2014年以后分化明显,特别在2014年以后,行业平均市净率波动最低的前五行业市净率从未超过4倍,其中银行更是从未超过1.5倍。始终保持行业平均市净率高波动的是休闲服务行业,低波动的是钢铁行业,而采掘行业在调整前后从波动最大第4名转为波动最小第2名。
注释:
- 行业分类标准采用的是申万一级行业分类,且由于申万行业分类标准在2014年2月21日作出改动,因此以此改动日为界限分别求出行业波动率,图例按其排名顺序依次排列。
- 在计算过程中,由于新股只有市值数据而缺省净利润数据,在市值极大的新股加入行业后,用行业净利润均值填充缺省值并不合适,会造成行业平均市盈率虚高(市净率同理)。为防止此情况,计算时剔除行业内新股,而在其上市一年后再加入计算。
五、成交量、成交总额的逐年变化
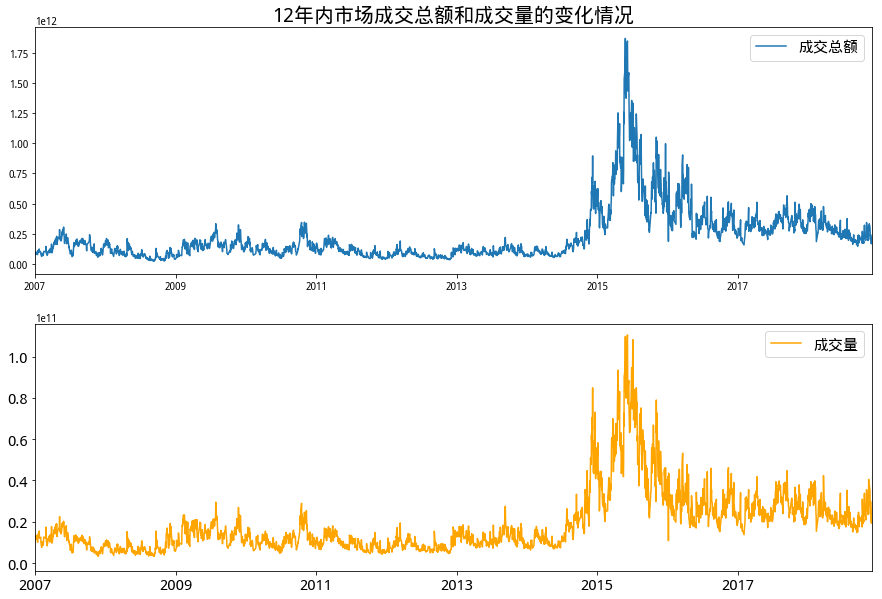
- 选取近12年A股成交总额和成交量数据绘图研究。从图中容易发现大部分时间内,成交金额数量级约为千亿,最高接近2万亿;成交量数量级约为百亿,最高在1千亿左右,且两个数据历史走势几乎完全一致。除了2015年出现高峰之外,两个数据波动几乎不大。另外成交量和成交金额在2015年高峰期之后均比2015年之前有小幅上涨,但是若考虑到通货膨胀的影响,实际增幅其实并不大。
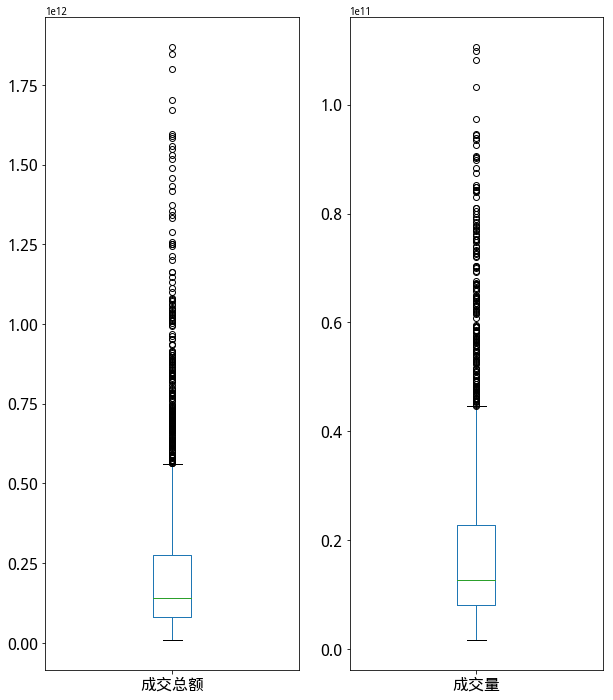
- 从第二幅箱线图中可以看出,成交金额中位数在1000亿左右,成交量中位数在100亿左右,且上方有来自15年牛市的大量异常值。
六、市场换手率占比、平均换手率
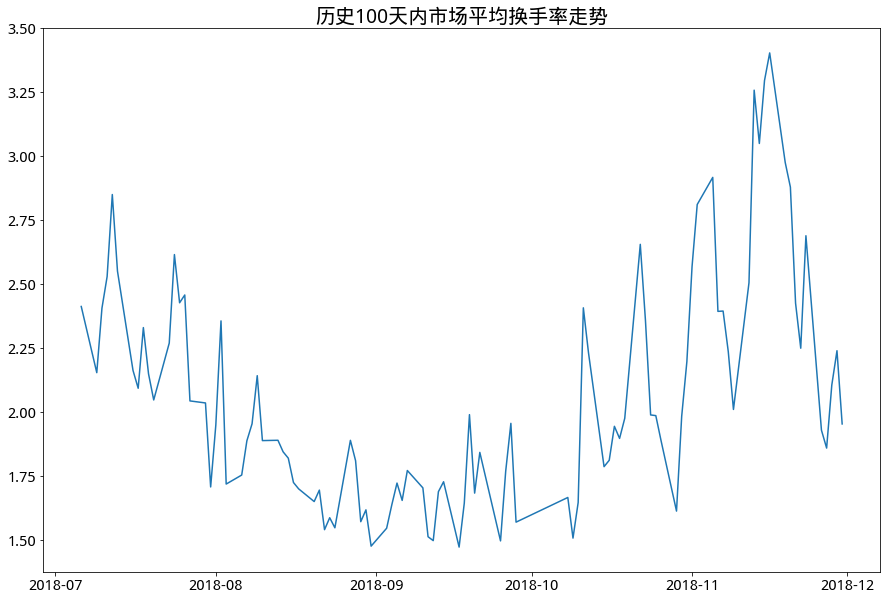
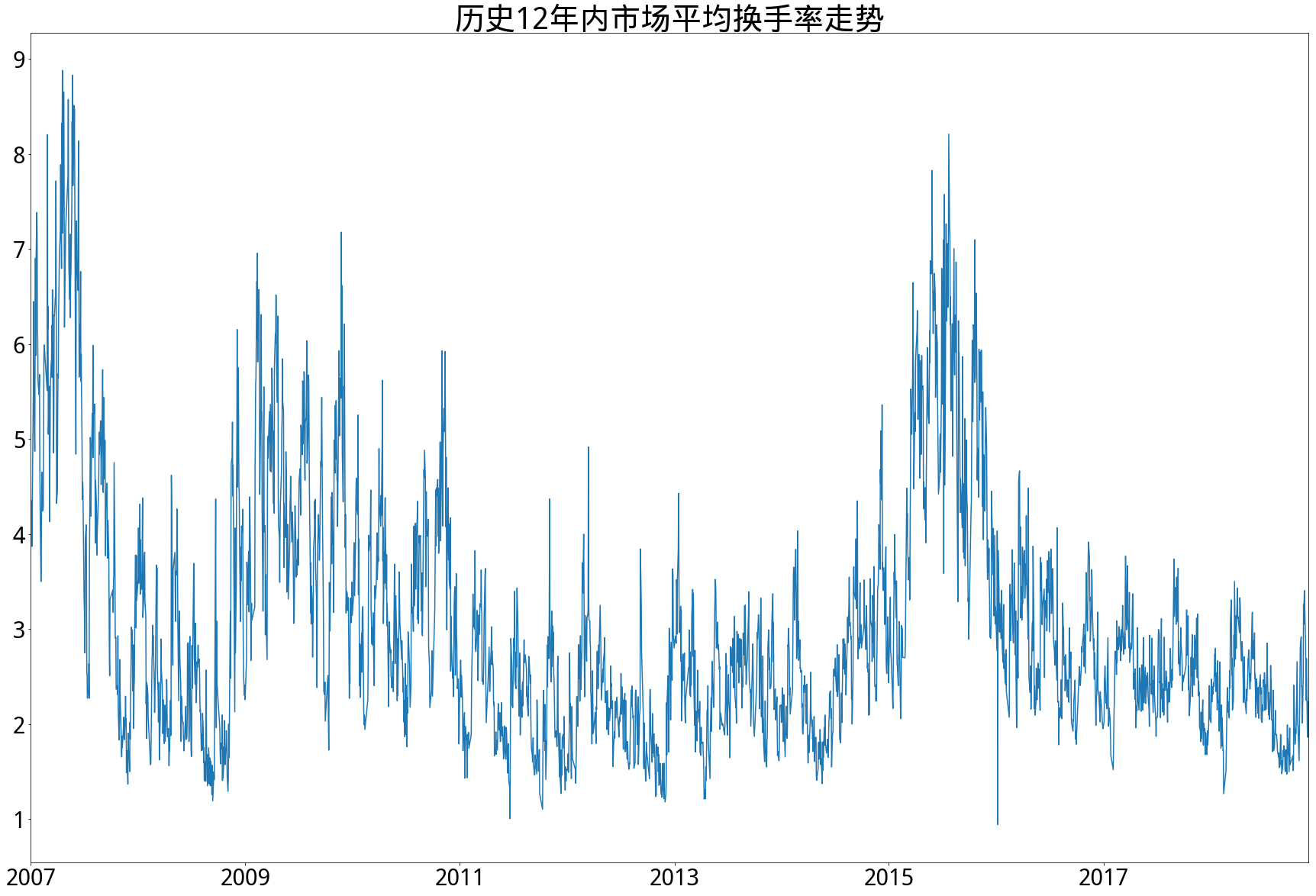
- 市场平均换手率在短期来看波动较大,经常在短时间内出现高低频繁变换,而从长期来看,平均换手率波动也很剧烈,除两次牛市曾上探到接近9%以外,大部分时间保持在4%以下。
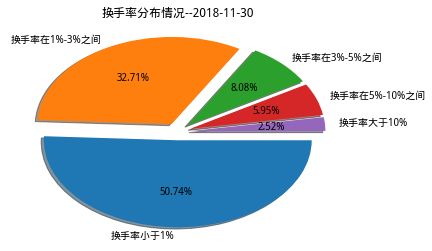
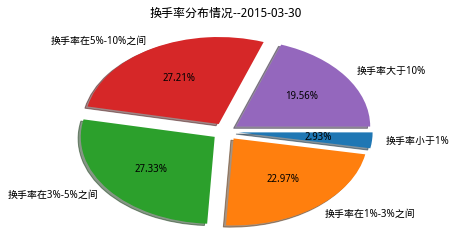
- 分析一天内各股票换手率分布情况,以近期2018-11-30这一天换手率情况为例,将近85%的个股换手率在3%以下,只有15%左右的股票表现较为活跃,说明市场比较沉闷,投资者交易意愿不高。但是在2015年出现牛市,大盘大幅上涨期间,换手率在1%以下的股票仅有2.93%,3%以下仅占四分之一,换手率在10%以上的股票占了将近20%,说明市场非常活跃。
七、总结
根据以上统计汇总得到的结果可以看出,市场底部的特征还是比较明显的,但是具体底部会持续多久,又是否会继续下探,对于同样的信息每个人也都有自己不同的解读,不好一概而论。本文旨在达到科普、抛砖引玉的效果,欢迎大家以此为框架深入研究,有兴趣可以留言多多交流建议和思路。
#导入各种包,建议使用聚宽研究平台运行。
#若使用其他方式,请自行导入numpy和matplotlib
import pandas as pd
from jqdata import *
from jqfactor import get_factor_values
def main():
#定义全局变量
global date, all_stocks, industries, indu_name
#取交易日信息
date = get_trade_days(start_date = '2007-01-01', end_date = '2018-11-30')
#取全部股票代码
all_stocks = list(get_all_securities(['stock']).index)
#获取申万一级行业
industries = get_industries(name='sw_l1').index
industries = industries.tolist()
#获取行业名
indu_name = get_industries(name='sw_l1')['name'].tolist()
#1
Stock_MCD()
#2
Industry_MCD('market_cap')
Industry_MCD('circulating_market_cap')
#3
Market_Fundamentals('pe_ratio')
Market_Fundamentals('pb_ratio')
#4
Industry_Fundamentals('pe_ratio')
Industry_Fundamentals('pb_ratio')
#5
Volume_Money()
#6
Turnover_Ratio()
TR_Distribution('2018-11-30')
TR_Distribution('2015-03-30')
#1
#股票市值分布
def Stock_MCD():
#获取全部股票市值
q = query(valuation.market_cap, valuation.code).filter(valuation.code.in_(all_stocks))
dfmc = get_fundamentals(q,'2018-11-30')
#分层处理数据
counta = 0
countb = 0
countc = 0
countd = 0
counte = 0
for i in range(len(dfmc)):
try:
if dfmc['market_cap'][i] <= 50:
counta += 1
elif dfmc['market_cap'][i] <= 100:
countb += 1
elif dfmc['market_cap'][i] <= 200:
countc += 1
elif dfmc['market_cap'][i] <= 400:
countd += 1
else:
counte += 1
except:
continue
#设置绘图参数
a = '市值小于50亿元'
b = '市值在50至100亿元之间'
c = '市值在100至200亿元之间'
d = '市值在200至400亿元之间'
e = '市值大于400亿元'
res = [counta, countb,countc,countd,counte]
l = [a,b,c,d,e]
explode = [0.1] * 5
#画饼状图
fig, ax = subplots()
ax.pie(x = res, labels = l, autopct='%.2f%%', shadow=True, explode = explode, counterclock = False)
ax.set_title('A股市值分布情况')
#ax.text(x = 1, y = -1, s = '单位:亿元')
#找出市值最大的几支股票
dfmc2 = dfmc.sort_values(by = 'market_cap', ascending = False)
#对大市值股票计数
count_m1 = 0
count_m2 = 0
for i in range(len(dfmc2)):
if dfmc['market_cap'][i] > 10000:
count_m1 += 1
count_m2 += 1
elif dfmc['market_cap'][i] > 5000:
count_m2 += 1
#求市值占比
s = sum(dfmc2['market_cap'])
p1 = sum(dfmc2['market_cap'][0:count_m1])/s
p2 = sum(dfmc2['market_cap'][0:count_m2])/s
print('市值在10000亿元以上的股票有{0}支,占A股总市值的{1:.2%}'.format(count_m1, p1))
print('市值在5000亿元以上的股票有{0}支,占A股总市值的{1:.2%}'.format(count_m2, p2))
#输出市值前五只股票信息
print('其中市值最大的前五支股票分别为:')
stock_name = []
market_cap = []
for i in range(5):
stock_name.append(get_security_info(dfmc2['code'].tolist()[i]).display_name)
market_cap.append(dfmc2['market_cap'].tolist()[i])
print('{0:8}{1:10}'.format('股票名称','市值(亿元)'))
for i in range(5):
print('{0:6}{1:10.2f}'.format(stock_name[i],market_cap[i]))
#2
#行业市值分布
def Industry_MCD(m):
#新建一个空列表
df = list([0] * len(industries))
#获取全部行业内的股票
for i in range(len(industries)):
df[i] = get_industry_stocks(industries[i])
#转换为DataFrame
df = pd.DataFrame(df)
df.index = industries
#数据清洗
df.dropna(how = 'all', inplace = True)
#保留原数据备用
df2 = df.copy()
if m == 'market_cap':
#获取个股市值
for i in range(len(df2)):
for j in range(len(df2.columns)):
try:
q = query(valuation.market_cap).filter(valuation.code.in_([df2.iloc[i,j]]))
df2.iloc[i,j] = get_fundamentals(q, "2018-11-30").iloc[0,0]
except:
df2.iloc[i,j] = 0
elif m == 'circulating_market_cap':
#获取个股市值
for i in range(len(df2)):
for j in range(len(df2.columns)):
try:
q = query(valuation.circulating_market_cap).filter(valuation.code.in_([df2.iloc[i,j]]))
df2.iloc[i,j] = get_fundamentals(q, "2018-11-30").iloc[0,0]
except:
df2.iloc[i,j] = 0
else:
print('所需指标暂不存在,请输入其他指标')
return None
df2.fillna(0, inplace = True)
#加总得到各行业市值
res = df2.apply(sum, axis = 'columns')
#做饼状图
df3 = pd.DataFrame(res)
df3.index = indu_name
df3.columns = ['market_cap']
explode = [0.2] * len(df3)
fig, ax = subplots()
ax.pie(df3, labels = df3.index, autopct='%.2f%%', shadow=False, radius = 3, explode = explode)
#3
#市场财务指标值,f为指标名称,目前只可选'pe_ratio', 'pb_ratio'
def Market_Fundamentals(f):
div = ''
#市场平均市盈率
if f == 'pe_ratio':
div = 'net_profit_ttm'
q = query(valuation.market_cap, valuation.code).filter(valuation.code.in_(all_stocks))
#数据获取、清洗、整合、计算处理
res = []
for i in range(len(date)):
df = get_fundamentals(q, date[i])
df2 = get_factor_values(all_stocks, [div], end_date = date[i], count = 1)[div].T
df2.columns = [div]
df_temp = pd.DataFrame({"code" : df2.index}, index = df2.index)
df2 = df2.join(df_temp, how = "outer")
df2.index = range(len(df2))
df = pd.merge(df,df2, on = "code", how = "left")
df.index = range(len(df))
for j in range(len(df)):
if df[div][j] <= 0 :
df.drop([j], inplace = True)
df.dropna(axis = 'index', inplace = True)
res.append(sum(df['market_cap'])*1e8/sum(df[div]))
res = pd.DataFrame(res, index = date, columns = ['市场平均市盈率'])
#作图
figsize(15,10)
fig, ax = subplots()
tick_params(labelsize=15)
plot(res)
ax.set_title('历史12年内市场平均市盈率走势', fontsize = 20)
ax.set_xlim('2007', '2018-11-30')
#市场平均市净率
elif f == 'pb_ratio':
div = 'equities_parent_company_owners'
#求历史平均市净率
q = query(valuation.market_cap, valuation.code, balance.equities_parent_company_owners).filter(valuation.code.in_(all_stocks))
res = []
for i in range(len(date)):
df = get_fundamentals(q, date[i])
df.index = range(len(df))
for j in range(len(df)):
if df[div][j] <= 0 :
df.drop([j], inplace = True)
df.dropna(axis = 'index', inplace = True)
res.append(sum(df['market_cap'])*1e8/sum(df[div]))
res = pd.DataFrame(res, index = date, columns = ['市场平均市净率'])
#作图
figsize(15,10)
fig, ax = subplots()
tick_params(labelsize=15)
plot(res)
ax.set_title('历史12年内市场平均市净率走势', fontsize = 20)
ax.set_xlim('2007', '2018-11-30')
else:
print('所需指标暂不存在,请输入其他指标')
return None
#4
#行业财务指标值,f为指标名称,目前只可选'pe_ratio', 'pb_ratio'
def Industry_Fundamentals(f):
div = ''
#行业平均市盈率
if f == 'pe_ratio':
div = 'net_profit_ttm'
#建立空DataFrame存储数据
res = pd.DataFrame([[0]*len(industries)]*len(date), index = date, columns = industries)
#数据获取、清洗、处理(会跑两个小时)
for i in range(len(date)):
#分别获取市值和净利润数据,并按个股代码合并为一个DataFrame
for industry in industries:
indu_stocks = get_industry_stocks(industry, date[i])
if indu_stocks == []:
continue
q = query(valuation.market_cap, valuation.code).filter(valuation.code.in_(indu_stocks))
df = get_fundamentals(q, date[i])
df2 = get_factor_values(indu_stocks, [div], end_date = date[i], count = 1)[div].T
df2.columns = [div]
df_temp = pd.DataFrame({"code" : df2.index}, index = df2.index)
df2 = df2.join(df_temp, how = "outer")
df2.index = range(len(df2))
df = pd.merge(df,df2, on = "code", how = "left")
df.index = range(len(df))
#清洗亏损个股
for j in range(len(df)):
if df[div][j] <= 0 :
df.drop([j], inplace = True)
#去掉缺省值(缺省主要因为新股,若加入市值远大于原行业的新股,而净利润缺省,对PE计算影响极大,因此去掉缺省值)
df.dropna(axis = 'index', inplace = True)
#结果填充
res.loc[date[i], industry] = sum(df['market_cap'])*1e8/sum(df[div])
#行业平均市净率
elif f == 'pb_ratio':
div = 'equities_parent_company_owners'
#建立空DataFrame存储数据
res = pd.DataFrame([[0]*len(industries)]*len(date), index = date, columns = industries)
#数据获取、清洗、处理(会跑两个小时)
for i in range(len(date)):
#分别获取市值和净利润数据,并按个股代码合并为一个DataFrame
for industry in industries:
indu_stocks = get_industry_stocks(industry, date[i])
if indu_stocks == []:
continue
q = query(valuation.market_cap, valuation.code, balance.equities_parent_company_owners).filter(valuation.code.in_(indu_stocks))
df = get_fundamentals(q, date[i])
df.index = range(len(df))
#清洗亏损个股
for j in range(len(df)):
if df[div][j] <= 0 :
df.drop([j], inplace = True)
#去掉缺省值(缺省主要因为新股,若加入市值远大于原行业的新股,而净利润缺省,对PE计算影响极大,因此去掉缺省值)
df.dropna(axis = 'index', inplace = True)
#结果填充
res.loc[date[i], industry] = sum(df['market_cap'])*1e8/sum(df[div])
else:
print('所需指标暂不存在,请输入其他指标')
return None
IFplot(res, f)
def IFplot(res, f):
#按申万调整期划分
res1 = res.loc[:datetime.date(2014, 2, 20)]
res2 = res.loc[datetime.date(2014, 2, 20):]
#2014年调整以前
res1.columns = indu_name
#求行业标准差代表波动率
a = res1.apply(std, axis = 0)
#排序
a.sort_values(ascending = False, inplace = True)
#去除0值行业
i = 0
while i in range(len(a)):
if a[i] == 0:
a = a.iloc[:i]
break
else:
i += 1
#取得波动率最大的五名
b = []
for i in range(5):
b.append(a.index.tolist()[i])
#作图
fig1, ax1 = subplots()
for ind in b:
res1[ind].plot.line(figsize = (20,15), fontsize = 20)
ax1.legend(b, fontsize = 20)
if f == 'pe_ratio':
ax1.set_title('2014年调整以前行业平均市盈率波动幅度最大的前五行业', fontsize = 20)
elif f == 'pb_ratio':
ax1.set_title('2014年调整以前行业平均市净率波动幅度最大的前五行业', fontsize = 20)
else:
return None
#取得波动率最小的五名
c = []
for i in range(1, 6):
c.append(a.index.tolist()[-i])
#作图
fig2, ax2 = subplots()
for ind in c:
res1[ind].plot.line(figsize = (20,15), fontsize = 20)
ax2.legend(c, fontsize = 20)
if f == 'pe_ratio':
ax2.set_title('2014年调整以前行业平均市盈率波动幅度最小的前五行业', fontsize = 20)
elif f == 'pb_ratio':
ax2.set_title('2014年调整以前行业平均市净率波动幅度最小的前五行业', fontsize = 20)
else:
return None
#2014年调整以后
res2.columns = indu_name
#求行业标准差代表波动率
d = res2.apply(std, axis = 0)
#排序
d.sort_values(ascending = False, inplace = True)
#取得波动率最大的五名
e = []
for i in range(5):
e.append(d.index.tolist()[i])
#作图
fig3, ax3 = subplots()
for ind in e:
res2[ind].plot.line(figsize = (20,15), fontsize = 20)
ax3.legend(e, fontsize = 20)
if f == 'pe_ratio':
ax3.set_title('2014年调整以后行业平均市盈率波动幅度最大的前五行业', fontsize = 20)
elif f == 'pb_ratio':
ax3.set_title('2014年调整以后行业平均市净率波动幅度最大的前五行业', fontsize = 20)
else:
return None
#取得波动率最小的五名
f = []
for i in range(1, 6):
f.append(d.index.tolist()[-i])
#作图
fig4, ax4 = subplots()
for ind in f:
res2[ind].plot.line(figsize = (20,15), fontsize = 20)
ax4.legend(f, fontsize = 20)
if f == 'pe_ratio':
ax4.set_title('2014年调整以后行业平均市盈率波动幅度最小的前五行业', fontsize = 20)
elif f == 'pb_ratio':
ax4.set_title('2014年调整以后行业平均市净率波动幅度最小的前五行业', fontsize = 20)
else:
return None
#5
#市场成交量和成交总额变化情况
def Volume_Money():
#获取近12年沪市和深市的成交量和成交总额数据
df = get_price(['000001.XSHG','399001.XSHE'], start_date = '2007-01-01', end_date = '2018-11-30',
fields = ['volume','money'])
sh = df.minor_xs('000001.XSHG')
sz = df.minor_xs('399001.XSHE')
combine = sh.copy()
#求和
combine['money'] = sh['money'] + sz['money']
combine['volume'] = sh['volume'] + sz['volume']
#作图
figsize(15,10)
fig, ax = subplots(2,1)
tick_params(labelsize=15)
ax[0].set_title('12年内市场成交总额和成交量的变化情况', fontsize = 20)
ax[0].plot(combine['money'])
ax[0].legend(['成交总额'], fontsize = 15)
ax[0].set_xlim('2007', '2018-11-30')
ax[1].plot(combine['volume'], color = 'orange')
ax[1].legend(['成交量'], fontsize = 15)
ax[1].set_xlim('2007', '2018-11-30')
#作箱线图
combine.columns = ['成交总额', '成交量']
combine.plot.box(subplots = True, figsize = (10,12), fontsize = 16)
#6
#市场平均换手率走势和占比
def Turnover_Ratio():
#查询字段换手率和股票代码
q = query(valuation.turnover_ratio,valuation.code).filter(valuation.code.in_(all_stocks))
#按日期求得平均换手率
res = []
for i in range(len(date)):
c = get_fundamentals(q, date[i])
res.append(mean(c['turnover_ratio']))
#转换数据格式并作图
res = pd.DataFrame(res)
res.index = date
res.columns = ['市场平均换手率']
#作图
figsize(30,20)
fig, ax = subplots()
tick_params(labelsize=30)
plot(res)
ax.set_title('历史12年内市场平均换手率走势', fontsize = 40)
ax.set_xlim('2007', '2018-11-30')
#按日期求得平均换手率
date_temp = get_trade_days(end_date = '2018-11-30', count = 100)
res2 = []
for i in range(len(date_temp)):
c = get_fundamentals(q, date_temp[i])
tm.append(mean(c['turnover_ratio']))
#转换数据格式并作图
res2 = pd.DataFrame(res2)
res2.index = date_temp
res2.columns = ['市场平均换手率']
figsize(15,10)
fig, ax = subplots()
tick_params(labelsize=15)
plot(res2)
ax.set_title('历史100天内市场平均换手率走势', fontsize = 20)
#换手率数据分布统计并作图
def TR_Distribution(date):
q = query(valuation.turnover_ratio,valuation.code).filter(valuation.code.in_(all_stocks))
trs = get_fundamentals(q, date)['turnover_ratio']
trs = trs.tolist()
counta = 0
countb = 0
countc = 0
countd = 0
counte = 0
for tr in trs:
if tr < 1:
counta += 1
elif tr < 3:
countb += 1
elif tr < 5:
countc += 1
elif tr < 10:
countd += 1
else :
counte += 1
result = [counta, countb, countc, countd, counte]
a = '换手率小于1%'
b = '换手率在1%-3%之间'
c = '换手率在3%-5%之间'
d = '换手率在5%-10%之间'
e = '换手率大于10%'
l = [a,b,c,d,e]
explode = [0.1] * 5
fig, ax = subplots(figsize = (8,7))
ax.set_title('换手率分布情况--' + date, fontsize = 15)
ax.pie(result, labels = l, shadow = True, counterclock = False, explode = explode, autopct = '%.2f%%')
#调用主函数,得到结果
main()