在第一篇中介绍了数据处理的各种方法,接下来到了一个很关键的地方,其实它也属于数据处理的一部分,但是由于我觉得他比较重要,所以单独拎出来说一下。
行业中性化分为以下几个步骤
1、为什么要做行业中性化
2、如何做行业市值中性化
1、为什么要做行业中性化
众所周知,行业和市值是两个十分显著对因子有影响力的因素。在进行截面回归判断每个单因子的收益情况和显著性时,需要特别关注这两个十分显著的因素。
我们做因子分析是为了挑选出有效因子,并对其值进行排序,按顺序或者倒叙来选择股票,但如果不剔除行业或者市值的影响,可能会导致选出的股票集中在某个行业或者是某种市值范围内,从而导致并不能很有效的分散风险,所以我们需要看的是在剔除了这两个因素之外,因子值的有效性。在这里我用聚宽上的因子做一个例子。
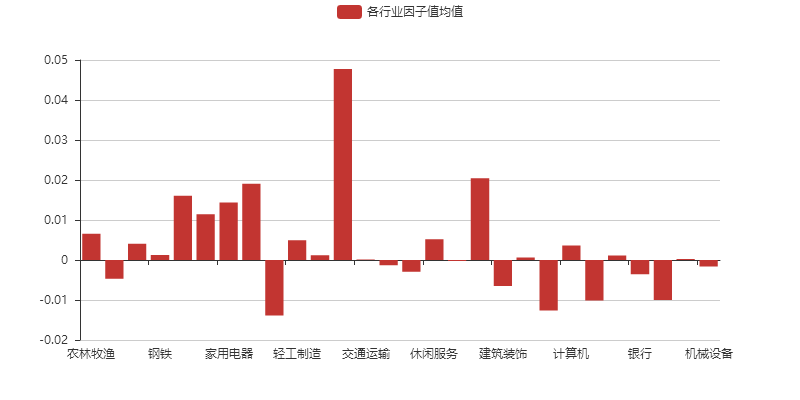
选取‘hs300_alpha’因子为例,股票范围选取沪深300指数成分股,行业分类标准选取申万一级行业分类。
从图中我们可以看出“综合”这个行业的因子值显著高于其他行业,这对我们进行因子分析是不利的。加下来就会介绍剔除行业和市值影响的行业市值中性化处理。
2、如何做行业市值中性化
我们通过建立回归方程来剔除行业和市值的影响,我们把想要剔除的因子暴露(如市值)作为X值,而Y值就是因子值本身,通过回归我们想要得到不能被X也就是该因素所解释的部分----残差值。
我们想要得到市值是十分容易的,但是行业要如何剔除呢。我们建立一个矩阵,就是如果股票属于某个行业,则该股票在该行业的因子暴露(因子值)等于1,在其他行业的因子暴露为0.这样就可以得到行业的哑变量矩阵,再通过回归得到残差值,就是我们想要得到的剔除行业中性化的值。
代码:见研究
from jqfactor import Factor, calc_factors
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
stock = get_index_stocks('000300.XSHG')
class Hs300Alpha(Factor):
# 设置因子名称
name = 'hs300_alpha'
# 设置获取数据的时间窗口长度
max_window = 10
# 设置依赖的数据
dependencies = ['close']
# 计算因子的函数, 需要返回一个 pandas.Series, index 是股票代码,value 是因子值
def calc(self, data):
# 获取个股的收盘价数据
close = data['close']
# 计算个股近10日收益
stock_return = close.iloc[-1,:]/close.iloc[0,:] -1
# 获取指数(沪深300)的收盘价数据
index_close = self._get_extra_data(securities=['000300.XSHG'], fields=['close'])['close']
# 计算指数的近10日收益
index_return = index_close.iat[-1,0]/index_close.iat[0,0] - 1
# 计算 alpha
alpha = stock_return - index_return
return alpha
factors = calc_factors(stock, [Hs300Alpha()], start_date='2017-01-01', end_date='2017-12-31')
data=factors['hs300_alpha']
from jqdata import *
sw=get_industries(name='sw_l1').index
a=[0]*len(sw)
for i in range(len(sw)):
a[i]=data[list(set(data.columns).intersection(set(get_industry_stocks(sw[i]))))].mean().mean()
from pyecharts import Bar
from pyecharts import online
online()
bar = Bar()
names=["农林牧渔","采掘","化工","钢铁",'有色金属','电子','家用电器','食品饮料','纺织服装','轻工制造',
'医药生物','公用事业','交通运输','房地产','商业贸易','休闲服务','综合','建筑材料','建筑装饰','电气设备',
'国防军工','计算机','传媒I','通信','银行','非银金融','汽车','机械设备']
bar.add("各行业因子值均值", names, a,
is_more_utils=True)
bar
#获得行业哑变量矩阵
from jqdata import *
sw=get_industries(name='sw_l1').index
industry=pd.DataFrame(0,columns=data.columns,index=range(0,28))
for i in range(len(sw)):
temp=list(set(data.columns).intersection(set(get_industry_stocks(sw[i]))))
industry.loc[i,temp]=1
#去除市值、行业因素,得到新的因子值
newx=pd.DataFrame()
for i in range(len(data.index)):
m= get_fundamentals(query(valuation.circulating_cap,valuation.code).filter(valuation.code.in_(data.columns)), date=data.index[i])
m.index=np.array(m['code'])
m=m.iloc[:,0]
m=(m-mean(m))/std(m)
x=data.iloc[i,:]
conc=pd.concat([x,m,industry.T],axis=1).fillna(mean(m))
est=sm.OLS(conc.iloc[:,0],conc.iloc[:,1:]).fit()
y_fitted = est.fittedvalues
newx[i]=est.resid
newx=newx.T
newx.index=data.index
newx=newx.iloc[1:,:]