在之前文章中,我们一直在添加新对象,并扩展现有对象的功能。 所有这些增加扩展了我们的函数库。 我们还加入了一个 OpenCL 程序文件。 现在,代码比最初版本大了 10 多倍。 在代码中跟踪对象之间的关系变得越来越困难。 读者可能会发现,阅读代码时感觉非常混乱,且难以理解。 我尝试在每篇文章中都提供对动作逻辑的详述。 但是,演示单独动作链,并不能提供对该程序的全面理解。
这就是为什么我决定演示如何创建代码文档,从而可从另一个角度查看代码。 本文档的目的是概括函数库中的所有对象和方法,并建立对象和方法的继承层次结构。 这应该使我们对所做的事情有一个大致的了解。
技术文档在 IT 开发中的目的是什么? 首先,文档能给出程序体系结构和操作的全面概念。 正确的文档令开发团队能够正确地区分责任范围,跟踪代码中的所有变更,并评估其对整个算法和体系结构完整性的影响。 它还有助于知识共享。 理解程序体系结构的完整性,可分析和制定项目开发的方式。
正确编写的技术文档应考虑到其目标用户的资质。 信息应清晰,并应避免过多的解释。 文档应包括用户需要的所有信息。 于此同时,它应该简明易懂。 过多的内容会浪费额外的时间来阅读,并令读者反感。 如果用户即使阅读过冗长的文档,却依然找不到所需的信息,则更令人烦恼。 这会导致下一条规则:文档必须具有便捷的信息搜索工具。 用户友好的界面和交叉引用,令查找所需的信息变得更加轻松。
文档应包含解决方案的完整体系结构,以及已实现的技术解决方案的说明。 完整而详细的解决方案描述有助于开发和进一步的支持。 始终随时保持文档更新是非常重要的。 过时的信息可能导致管理决策矛盾,结果可能会令整体开发失衡。
而且,文档必须必须描述组件之间的接口。
有一些专用程序可以帮助创建文档。 我认为,最常见的是 Doxygen,Sphinx,Latex(还有其他一些工具)。 所有这些目标旨在降低人工创建文档的成本。 当然,每个程序都是由开发人员创建的,用于解决特定问题。 例如,Doxygen 是为 C++ 程序和类似编程语言创建文档的程序。 Sphinx 是为 Python 文档创建的。 但这并不意味着它们仅限于一种编程语言方面非常专业。 这两个程序都可以与各种编程语言一起很好地工作。 相关程序网站提供了有关它们如何使用的详细参考,故您可以选择最适合自己的一种。
前面已经在文章“自动创建 MQL5 程序的文档”中讨论过 MQL5 的文档。 本文建议采用 Doxygen。 我还将这个程序用于我的开发。 MQL5 语法接近 C++,因此 Doxygen 非常适合 MQL5 程序。 我喜欢的事实:为了创建文档,您只需要在程序代码中添加相应的注释,而其余的工作则由专用软件来完成。 甚而,Doxygen 允许插入超链接和数学公式,这对于文章的主题而言非常重要。 在本文中,我们将采用特定的示例,进一步研究特定功能的用法。
如上所述,为了生成文档,您需要在程序代码中添加注释。 Doxygen 则根据这些注释创建文档。 自然,并非所有代码注释都应包含在文档之中。 一些注释可能包含开发人员批注,在某些地方还为没用到的代码添加了注释。 Doxygen 开发人员提供了一些方式来标记包含在文档中的注释。 有若干种选择,您可为自己选择一种最方便的。
与 MQL5 类似,文档注释可以是单行和多行。 为了避免将来直接引用代码时不会受到干扰,我们将采用标准选项来插入注释;对于单行注释,我们将采用一个额外的斜杠;对于多行注释,我们将附加一个星号。 可选地,还可用感叹号来标识文档注释块。
/// A single-line comment for documentation /** A multi-line block for documentation */ //! An alternative single-line comment for documentation /*! An alternative multi-line block for documentation */
请注意,多行注释块并不意味着在文档里一定要出现相同的多行。 如果您需要分隔程序对象的简述和详述,则您可以添加不同的注释块或使用特殊命令,这些命令由这些字符表示 "\" 或 "@"。 命令 "\n" 可用来强制换行。
选项 1: 分离的块 /// Short description /** Detailed description */ 选项 2: 特殊命令的用法 /** \brief Brief description \details Detailed description */
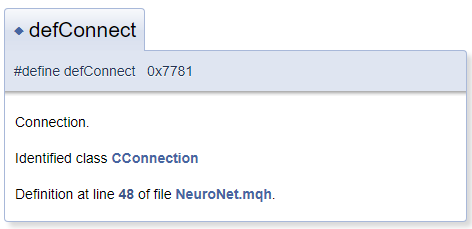
通常,假定文档对象位于文件中的注释块旁边。 但实际上,可能位于注释块之前位于的对象需要进行注释。 在这种情况下,使用字符 "<" 通知 Doxygen 注释的对象位于该块之前。 若要在注释中创建交叉引用,则在引用对象之前添加 "#"。 下面是代码示例,以及在文档中生成的代码块。 在生成的模板中,“CConnection” 是一个引用,指向相应类的文档页面。
#define defConnect 0x7781 ///<Connection \details Identified class #CConnection
Doxygen 功能很广泛。 命令的完整列表及其说明可在程序页面的文档板块下找到。 甚而,Doxygen 还能理解 HTML 和 XML 标记。 所有这些功能在创建文档时都可解决各种任务。
至此,我们已经回顾了工具的功能,我们可以开始处理文档。 首先,我们来描述一下我们的文件。
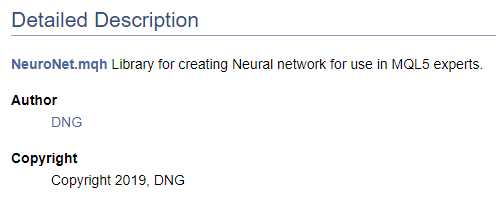
/// \file /// \brief NeuroNet.mqh /// Library for creating Neural network for use in MQL5 experts /// \author [DNG](https://www.mql5.com/en/users/dng) /// \copyright Copyright 2019, DNG
且
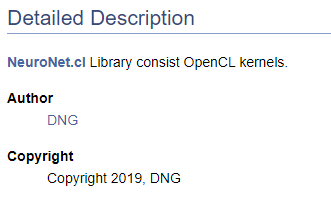
/// \file /// \brief NeuroNet.cl /// Library consist OpenCL kernels /// \author <A HREF="https://www.mql5.com/en/users/dng"> DNG </A> /// \copyright Copyright 2019, DNG
请注意,在第一种情况下,\author 指针后跟 Doxygen 提供的标记;在第二种情况下,用的是 HTML 标记。 此处用它是为演示不同选项,譬如创建超链接。 在这些情况下,结果是相同的 - 它在 MQL5.com 上创建了指向我个人资料的链接。
当然,在开始创建代码文档时,必须至少已拥有所需结果的高级结构。 对最终结构的理解可以对文档对象进行正确的分组。 我们将所创建枚举合并到一个分离的组中。 为了声明一个组,使用 “\defgroup” 命令。 组的边界可用字符 "@{" 和 "@}" 表示。
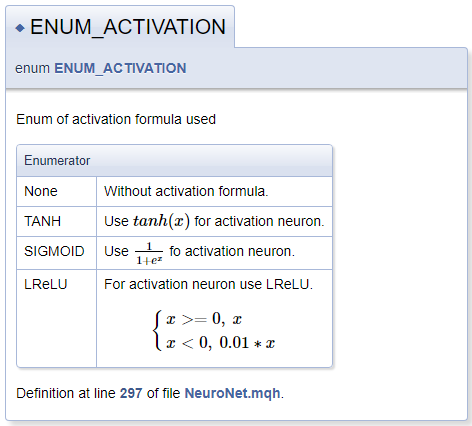
///\defgroup enums ENUM ///@{ //+------------------------------------------------------------------+ /// Enum of activation formula used //+------------------------------------------------------------------+ enum ENUM_ACTIVATION { None=-1, ///< Without activation formula TANH, ///< Use \f$tanh(x)\f$ for activation neuron SIGMOID, ///< Use \f$\frac{1}{1+e^x}\f$ fo activation neuron LReLU ///< For activation neuron use LReLU \f[\left\{ \begin{array} a x>=0, \ x \\x<0, \ 0.01*x \end{array} \right.\f] }; //+------------------------------------------------------------------+ /// Enum of optimization method used //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM ///< Adam }; ///@}
在描述激活函数时,我曾演示过通过 MathJax 声明数学公式的功能。 如果希望在文本行中显示公式,则应在一对 “\f$” 命令之间放置此类公式的说明,或者,若您希望公式显示在单独行上,则放置于命令 “\f[ 和 "\f]" 之间。 "\frac" 命令能够描述分数。 该命令之后,在大括号中是小数的分子和分母。
描述 LReLU 时,我们需要一个统一的左大括号。 为了创建它,我们使用了命令 "\left\{" 和 "\right\."。 “\right” 命令后跟 “\.”,因为公式中不需要右大括号。 否则,句号将被一个大括号代替。 使用命令 "\begin{array} a" 和 "\end{array}" 在块内声明字符串数组,数组元素则是由 "\\" 命令执行分隔的。 "\ " 字符能够添加强制空格。
生成的文档块如下所示。
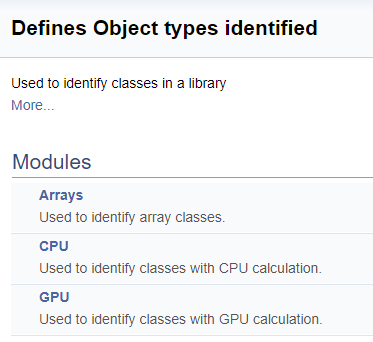
在下一步中,我们为函数库中的类标识符创建一个单独的组。 在该组内,我们将分配数组的子组,在 CPU 上计算神经元的运算,和在 GPU 上计算神经元的运算。 如早前所述,添加了指向相应类的链接。
///\defgroup ObjectTypes Defines Object types identified ///Used to identify classes in a library ///@{ //+------------------------------------------------------------------+ ///\defgroup arr Arrays ///Used to identify array classes ///\{ #define defArrayConnects 0x7782 ///<Array of connections \details Identified class #CArrayCon #define defLayer 0x7787 ///<Layer of neurons \details Identified class #CLayer #define defArrayLayer 0x7788 ///<Array of layers \details Identified class #CArrayLayer #define defNet 0x7790 ///<Neuron Net \details Identified class #CNet ///\} ///\defgroup cpu CPU ///Used to identify classes with CPU calculation ///\{ #define defConnect 0x7781 ///<Connection \details Identified class #CConnection #define defNeuronBase 0x7783 ///<Neuron base type \details Identified class #CNeuronBase #define defNeuron 0x7784 ///<Full connected neuron \details Identified class #CNeuron #define defNeuronConv 0x7785 ///<Convolution neuron \details Identified class #CNeuronConv #define defNeuronProof 0x7786 ///<Proof neuron \details Identified class #CNeuronProof #define defNeuronLSTM 0x7791 ///<LSTM Neuron \details Identified class #CNeuronLSTM ///\} ///\defgroup gpu GPU ///Used to identify classes with GPU calculation ///\{ #define defBufferDouble 0x7882 ///<Data Buffer OpenCL \details Identified class #CBufferDouble #define defNeuronBaseOCL 0x7883 ///<Neuron Base OpenCL \details Identified class #CNeuronBaseOCL #define defNeuronConvOCL 0x7885 ///<Convolution neuron OpenCL \details Identified class #CNeuronConvOCL #define defNeuronProofOCL 0x7886 ///<Proof neuron OpenCL \details Identified class #CNeuronProofOCL #define defNeuronAttentionOCL 0x7887 ///<Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL ///\} ///@}
生成的文档中的分组如下所示。
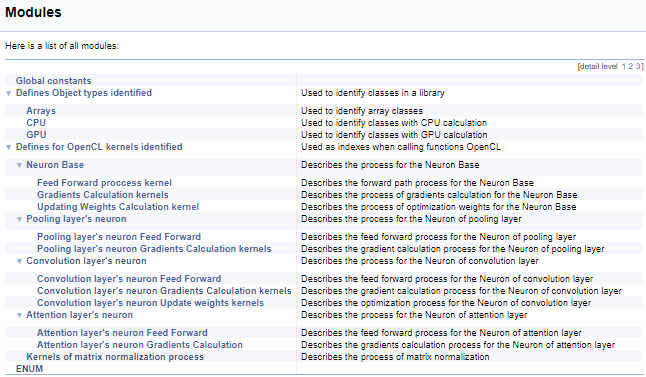
接下来,我们将研究操控 OpenCL 内核的大量定义组。 在该块中,将助记符名称分配给内核索引及其参数,从主程序调用内核时会用到这些索引。 采用上述技术,我们将依据调用内核神经元的类别、以及内核中操作的内容(前馈,梯度反向传播,更新权重系数)来分组。 我不会在此处提供完整的代码 - 可从下面的附件中找到它们。 构造子组的逻辑与上面的示例相似。 下面的截屏展示了完整的组结构。
继续介绍内核,我们转至正评述的 OpenCL 程序。 为了创建连贯的文档结构,并获得全面印象,我们将利用另一个 Doxygen 命令 “\ingroup”,该命令能够将新的文档对象添加到之前创建的组中。 我们用它将内核添加到早前创建的索引分组当中,以便操控内核。 在内核描述中,添加指向调用类的链接,以及指向该站点上带有过程描述的文章链接。 接下来,我们来描述内核参数。 指针 “[in]” 和 “[out]” 的用法将显示信息流的方向。 交叉引用将显示数据格式。
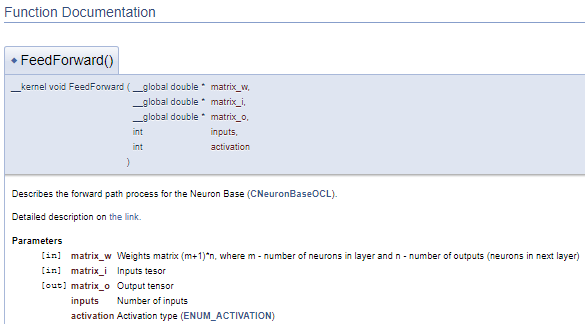
///\ingroup neuron_base_ff Feed forward process kernel /// Describes the forward path process for the Neuron Base (#CNeuronBaseOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/en/articles/8435#para41">the link.</A> //+------------------------------------------------------------------+ __kernel void FeedForward(__global double *matrix_w,///<[in] Weights matrix (m+1)*n, where m - number of neurons in layer and n - number of outputs (neurons in next layer) __global double *matrix_i,///<[in] Inputs tesor __global double *matrix_o,///<[out] Output tensor int inputs,///< Number of inputs int activation///< Activation type (#ENUM_ACTIVATION) )
上面的代码将生成以下文档块。
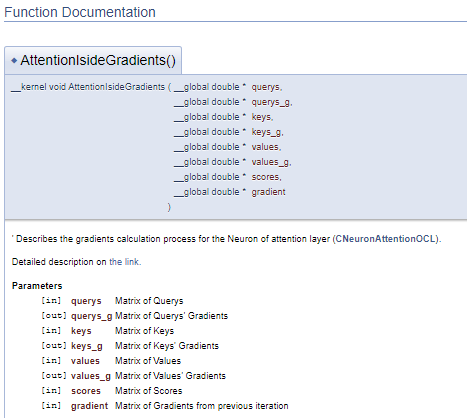
在上面的示例中,参数声明之后立即给出其·说明。 但是这种方式会令代码变得笨拙。 在这种情况下,建议使用 “\param” 命令来描述参数。 通过使用此命令,我们可在文件的任何部分中描述参数,但是我们需要直接指定参数名称。
///\ingroup neuron_atten_gr Attention layer's neuron Gradients Calculation kernel /// Describes the gradients calculation process for the Neuron of attention layer (#CNeuronAttentionOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8765#para44">the link.</A> /// @param[in] querys Matrix of Querys /// @param[out] querys_g Matrix of Querys' Gradients /// @param[in] keys Matrix of Keys /// @param[out] keys_g Matrix of Keys' Gradients /// @param[in] values Matrix of Values /// @param[out] values_g Matrix of Values' Gradients /// @param[in] scores Matrix of Scores /// @param[in] gradient Matrix of Gradients from previous iteration //+------------------------------------------------------------------+ __kernel void AttentionIsideGradients(__global double *querys,__global double *querys_g, __global double *keys,__global double *keys_g, __global double *values,__global double *values_g, __global double *scores, __global double *gradient)
这种方式生成一个类似的文档块,但它能够将注释块与程序代码分离。 因此,代码变得更易于阅读。
主要工作涉及我们的函数库类及其方法的文档。 我们需要描述所有用到的类及其方法。 为此,我们将利用上述所有不同形式的命令,并添加一些新命令。 首先,我们将类添加到相应的组中,就像我们早前针对内核那样(\ingroup 命令)。 "\class" 命令通知 Doxygen 下述需应用于该类。 在命令参数中,指定类名称,从而将描述链接到正确的对象
利用 "\brief" 和 "\details" 命令,提供类的简述和扩展描述。 在详述之中,加入相应文章的链接。 此处,我们将在文章的特定章节添加一个锚链接,如此可令用户能够更快地找到所需的信息。
将它们的描述直接添加到变量声明行。 如有必要,则添加指向对象说明的链接。 无需在注释中设置指向已声明对象类的指针,而 Doxygen 会自动添加它们。
类的描述方法与此类似。 不过,与变量不同,应在注释中添加参数描述。 为此,利用前面介绍的 “\param” 命令,以及 “[in]”,“[out]”,“[in,out]” 指针。 利用 “\return” 命令描述方法的执行结果。
它也可以通过某些功能将独立方法附加到组中。 例如,它们可按功能组合。
下面的代码展示了上述所有步骤。
///\ingroup neuron_base ///\class CNeuronBaseOCL ///\brief The base class of neuron for GPU calculation. ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8435#para45">the link.</A> //+------------------------------------------------------------------+ class CNeuronBaseOCL : public CObject { protected: COpenCLMy *OpenCL; ///< Object for working with OpenCL CBufferDouble *Output; ///< Buffer of Output tenzor CBufferDouble *PrevOutput; ///< Buffer of previous iteration Output tenzor CBufferDouble *Weights; ///< Buffer of weights matrix CBufferDouble *DeltaWeights; ///< Buffer of last delta weights matrix (#SGD) CBufferDouble *Gradient; ///< Buffer of gradient tenzor CBufferDouble *FirstMomentum; ///< Buffer of first momentum matrix (#ADAM) CBufferDouble *SecondMomentum; ///< Buffer of second momentum matrix (#ADAM) //--- const double alpha; ///< Multiplier to momentum in #SGD optimization int t; ///< Count of iterations //--- int m_myIndex; ///< Index of neuron in layer ENUM_ACTIVATION activation; ///< Activation type (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Optimization method (#ENUM_OPTIMIZATION) //--- ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. public: /** Constructor */CNeuronBaseOCL(void); /** Destructor */~CNeuronBaseOCL(void); virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual void SetActivationFunction(ENUM_ACTIVATION value) { activation=value; } ///< Set the type of activation function (#ENUM_ACTIVATION) //--- virtual int getOutputIndex(void) { return Output.GetIndex(); } ///< Get index of output buffer @return Index virtual int getPrevOutIndex(void) { return PrevOutput.GetIndex(); } ///< Get index of previous iteration output buffer @return Index virtual int getGradientIndex(void) { return Gradient.GetIndex(); } ///< Get index of gradient buffer @return Index virtual int getWeightsIndex(void) { return Weights.GetIndex(); } ///< Get index of weights matrix buffer @return Index virtual int getDeltaWeightsIndex(void) { return DeltaWeights.GetIndex(); } ///< Get index of delta weights matrix buffer (SGD)@return Index virtual int getFirstMomentumIndex(void) { return FirstMomentum.GetIndex(); } ///< Get index of first momentum matrix buffer (Adam)@return Index virtual int getSecondMomentumIndex(void) { return SecondMomentum.GetIndex();} ///< Get index of Second momentum matrix buffer (Adam)@return Index //--- virtual int getOutputVal(double &values[]) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getPrevVal(double &values[]) { return PrevOutput.GetData(values); } ///< Get values of previous iteration output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return Gradient.GetData(values); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual int getWeights(double &values[]) { return Weights.GetData(values); } ///< Get values of weights matrix buffer @param[out] values Array of data @return number of items virtual int Neurons(void) { return Output.Total(); } ///< Get number of neurons in layer @return Number of neurons virtual int Activation(void) { return (int)activation; } ///< Get type of activation function @return Type (#ENUM_ACTIVATION) virtual int getConnections(void) { return (CheckPointer(Weights)!=POINTER_INVALID ? Weights.Total()/(Gradient.Total()) : 0); } ///< Get number of connections 1 neuron to next layer @return Number of connections //--- virtual bool FeedForward(CObject *SourceObject); ///< Dispatch method for defining the subroutine for feed forward process. @param SourceObject Pointer to the previous layer. virtual bool calcHiddenGradients(CObject *TargetObject); ///< Dispatch method for defining the subroutine for transferring the gradient to the previous layer. @param TargetObject Pointer to the next layer. virtual bool UpdateInputWeights(CObject *SourceObject); ///< Dispatch method for defining the subroutine for updating weights.@param SourceObject Pointer to previos layer. ///\ingroup neuron_base_gr ///@{ virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. virtual bool calcOutputGradients(CArrayDouble *Target); ///< Method of output gradients calculation by calling kernel ::CalcOutputGradient().@param Target target value ///@} //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronBaseOCL; }///< Identifier of class.@return Type of class };
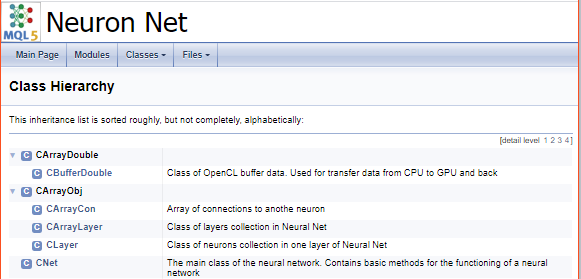
为了完成代码的处理,我们创建一个封面。 "\mainpage" 命令用于标识封面块。 该命令后应加随封面标题。 在下面,我们添加项目描述,并创建参考列表。 列表项将用字符 "-" 标记。 为了创建指向早前创建的分组链接,则利用 “\ref” 命令。 当 Doxygen 生成文档时,将生成类层次结构(hierarchy.html)和所用文件(files.html)的页面。 将指向特定页面的链接添加到列表当中。 封面的最终代码如下所示。
///\mainpage NeuronNet /// Library for creating Neural network for use in MQL5 experts. /// - \ref const /// - \ref enums /// - \ref ObjectTypes /// - \ref group1 /// - [<b>Class Hierarchy</b>](hierarchy.html) /// - [<b>Files</b>](files.html)
以下页面是根据以上代码生成。
附件中提供了所有注释的完整代码。
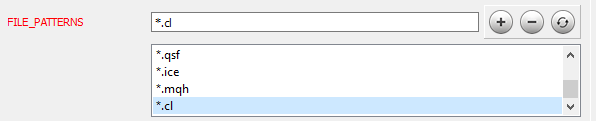
代码处理完毕后,就进入下一个阶段。 在[第九篇]文章里详细介绍了 Doxygen 的安装和设置。 我们研究一些程序参数的设置。 首先,通知 Doxygen 它应该使用哪些文件:在“智能系统”选卡上的“输入”主题中,将必要的文件掩码添加到 FILE_PATTERNS 参数。 在这种情况下,我已添加了 "*.mqh" 和 "*.cl"。
现在,我们需要通知 Doxygen 如何解析添加的文件。 转到同一“智能系统”选卡上的“项目”主题,然后编辑 EXTENSION_MAPPING 参数,如下图所示。

为了让 Doxygen 能够生成数学公式,需激活 MathJax。 为此,激活“智能系统”选卡的 HTML 主题中的 USE_MATHJAX 参数,如下图所示。

程序配置完毕后,转到“向导”选卡并指定项目名称,源文件的路径,以及显示生成文档的路径(所有这些步骤均在[第九篇]文章中展示过)。 转到“运行”选项卡,然后运行文档生成程序。
一旦程序完成,您将收到一个现成的文档。 Some screenshots are shown below. 附件中提供了完整的文档。
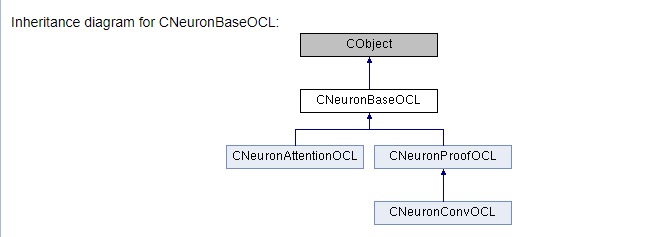
为所开发程序编制文档不是程序员的主要任务。 然而,在开发复杂项目时,此类文档至关重要。 它有助于跟踪任务的执行情况,协调开发团队的工作,并提供开发的整体视图。 共享知识时必须有文档。
本文介绍了一种 MQL5 语言开发建档的机制。 它提供了该机制所有步骤的详细说明。 附件中提供了所做工作的结果,故每个人都可以对其进行评估。
希望我的经验对您有所帮助。
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 2 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
| 3 | html.zip | ZIP 存档 | Doxygen 生成的文档存档 |
| 4 | NN.chm | HTML 帮助 | 转换后的 HTML 帮助文件。 |
| 5 | Doxyfile | Doxygen 参数文件 |

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







