一、前言
本文主要介绍支持向量机(Support Vector Machine, SVM)在多因子选股方面的应用。
支持向量机可用于分类问题和回归问题,用于回归问题时被称为支持向量回归(Support Vector Regression, SVR)。回归是构建若干个因子值与收益率或超额收益率之间的映射关系,股票的收益率有时会受到政策、新闻、事件等方面的影响,包含了太多的噪声,分类相对来说更像是一种“模糊的正确”,因此本文根据每期截面个股收益率进行降序排列,头尾部分别作为“ 1类”和“-1类”,SVM建模对其分类。
支持向量机可分为线性支持向量机和核支持向量机,前者针对线性分类问题,后者属于非线性分类器。为了更好的挖掘因子值与股票相对强弱之间的非线性关系,本文使用了高斯核(RBF核)的核SVM。
SVM的算法原理可以参考李航的《统计学习方法》和周志华的西瓜书《机器学习》等书籍关于SVM的篇章,还有更快的入门方法,那就是《【量化课堂】SVM原理入门》。
二、策略构建
本文策略所使用的因子和构建流程主要参考了华泰金工林晓明先生的人工智能系列之三《人工智能选股之支持向量机模型》,建模流程如下:
1.回测时间范围:2010-01-01 ~ 2019-08-31
2.股票池:沪深300成分股。剔除ST股票,剔除停牌股票,剔除上市未满3个月的股票,每期截面的每只股票视作一个样本,即同一只股票在不同期视为不同样本。
3.因子库:本策略使用了60余个因子,因子列表如下。

4.因子值处理:首先采用中位数去极值,若因子值缺失,则采用申万一级行业个股均值填充,若当前行业个股皆缺失,则填充为全部行业的均值;然后,对因子值做行业中性化和市值中性化;最后,对每个因子做标准化处理。
5.模型构建:根据每期截面个股收益率进行降序排列,头尾各30%部分别作为“ 1类”和“-1类”,SVM建模分类,采用带格点搜索的交叉验证法确定模型参数。SVM模型使用sklearn.svm中的SVC,带格点搜索的交叉验证使用sklearn.model_selection中的GridSearchCV。
三、回测结果
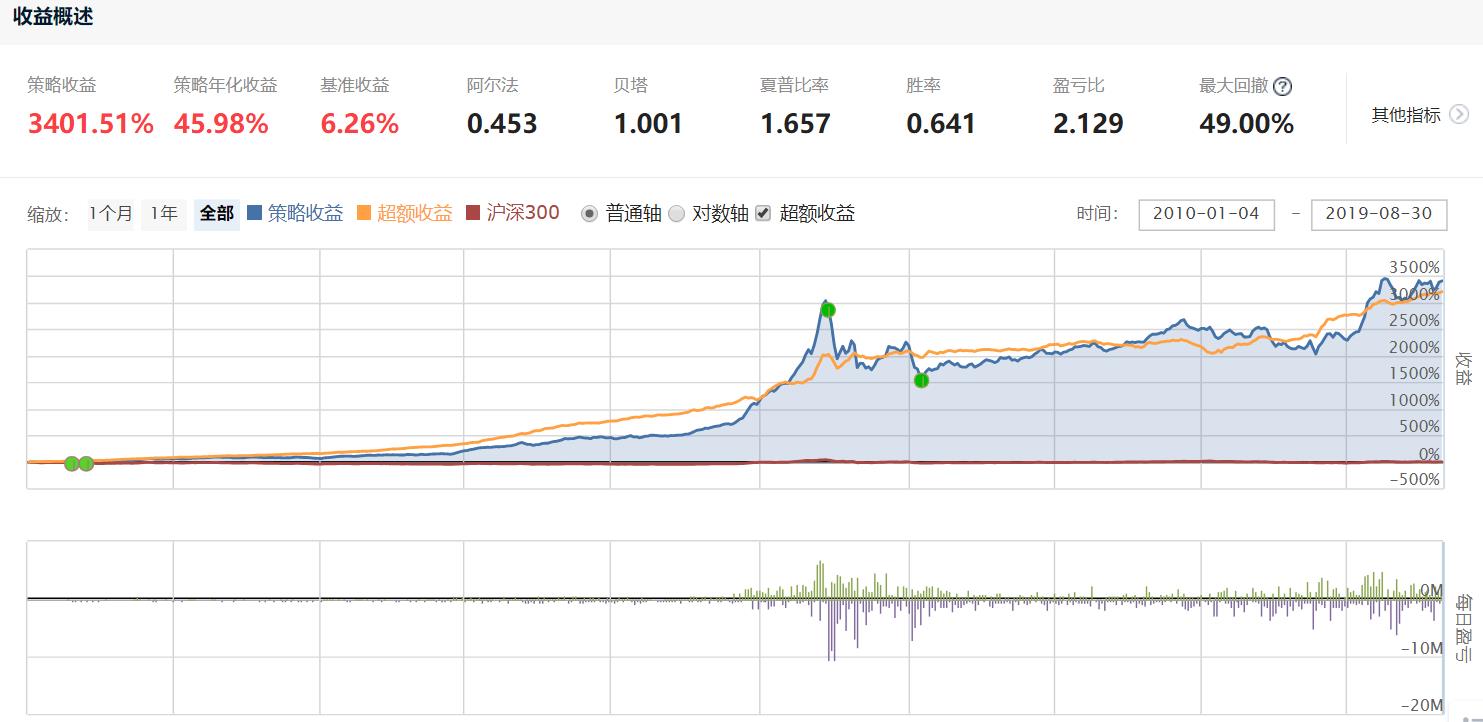
回测曲线见下图,样本内可见SVM的强大归纳能力,曲线向上不回头,但也存在两三年的曲线走平失效时间。这就要说到一般机器学习算法的使用前提i.i.d条件(independent and identically distributed, 独立同分布),由于机器学习算法强大的归纳能力,能非常好的拟合样本内(训练集)数据,但如果样本外(测试集)数据与样本内(训练集)数据不属于同一个分布,或者两者的分布差距非常大,则该算法只能“归纳”,无法“演绎”,出现非常严重的过拟合现象。
策略回测净值曲线:
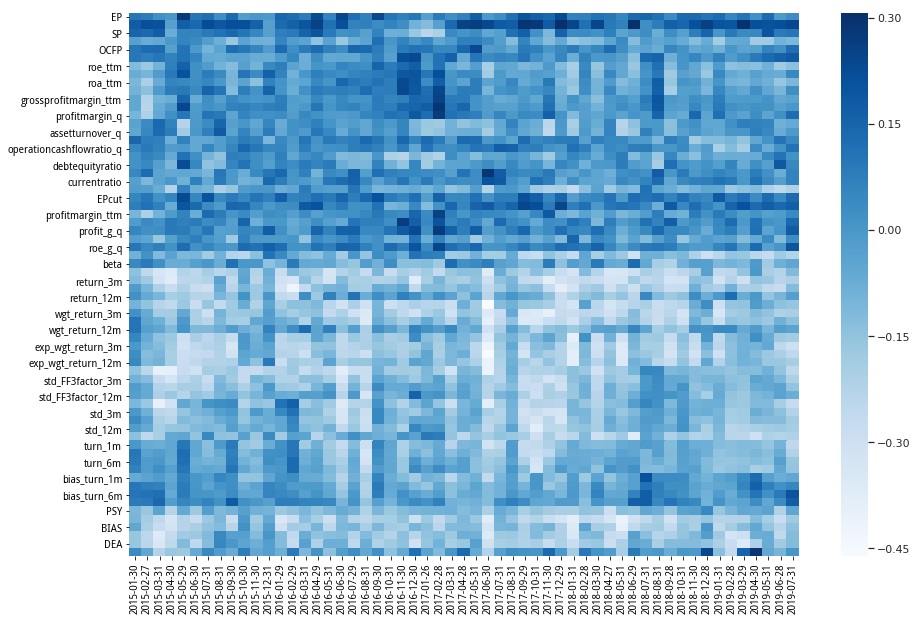
SVM预测与因子相关性热力图: