为什么要获取这些数据
如果只是阅读,那么你完全可以打开一个股票软件,按F10后找到相关财务报表进行阅读,如果觉得还不够详细,那就直接百度这家公司,从网站中查看或下载对应的季报、年报等。
但是如果要深入的使用这些数据,例如进行相关公司的财务预测与分析,最好是能把相关数据放到excle里,一个是方便阅读,另外是可以动手操作,利用excle的强大功能进行计算,最后还可以导出各种好看的图。
目前好像暂时没有人(或者我不知道)提供excle的财务三张表(资产负债、利润、现金),所以想了两个办法来解决这个问题。
方法一:人肉搬运
创建一个excle文件,然后打开一个股票软件,手工把对应内容敲到excle里。虽然没什么技术含量,可是对于只关心少数几家公司的用户来说,这样很方便,但是如果你想获取很多公司的财务报表,那就需要下面的方法了。
方法二:通过python从聚宽获取数据,并写到excle里面。为什么不从万德或者恒生聚源获取呢?因为没有权限呗。。。要想获得免费的数据,个人感觉聚宽是比较好的渠道。
大致分为以下两大步骤
步骤一:准备工作
首先我是windows系统,然后python版本是3.7
安装python 并安装对应的库。python里面会用到的功能包括 dbfread(把输出的数据转化成字典格式) xlsxwriter(把获取的数据写入excle)
同时还需要去聚宽申请一个账号,并申请本地数据功能,然后安装以下聚宽本地数据。
步骤二:具体数据提取
用python从聚宽提取相关数据
步骤一:
来这里的肯定有聚宽账号,如果想在本地使用,是需要开通本地数据的,具体步骤如下:
申请开通本地数据
申请好了之后可以自己看教程,里面有详细说明。
安装 jqdata dbfread xlsxwriter
我是通过pip安装的,建议先更新一下pip版本,不然有的内容可能安装不上。
更新pip的方法
打开cmd,输入:
python -m pip install --upgrade pip
更新好了pip后,仍旧是在cmd,分三次输入以下内容按回车就好
pip install jqdatasdk
pip install dbfread
pip install XlsxWriter
安装好了之后就开始使用啦
步骤二:
我的思路是先从聚宽获取到相关数据,然后转换格式,让他成为自己可以直接操作的格式,之后按照自己的需求写入excle。
1 登录聚宽本地数据
#引入相关库
from jqdatasdk import *
from dbfread import DBF
import xlsxwriter
#登录一下本地数据
auth('聚宽账号','聚宽密码')
#查询剩余可调用条数
sykdyts = get_query_count()
print(sykdyts)
code
先引入各种库和功能
然后需要登录一下聚宽本地数据,在我标注的地方填上你的账号密码
为了验证一下链接情况,可以顺手查一下剩余的可调用条数,每天给100万条,对于目前的需求来说绝对够用。
如果连接成功,应该看到以下内容:
第一行表示登录成功
第二行提示你 总共多少条,剩余多少条可调用数据。
2 开始从数据库获取相关数据
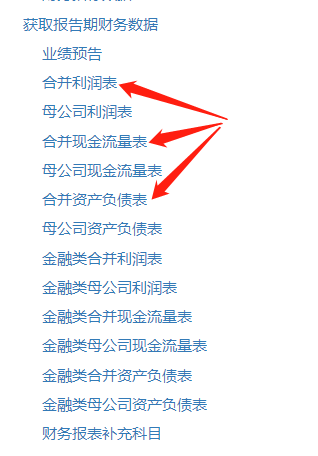
这次从贵州茅台开始获取,所以先取我标注的三张表。
之前获取的是母公司利润表,后来发现数据不太对,问了聚宽的客服人员才发现获取错了,后来调整成我标注的三张表。
至于代码部分,就不详述了,大致的流程就是:连接jqdatasdk 获取三张表数据,然后按照一定格式写入excle中。
代码可能有很多不足,大佬们多指点,直接贴代码吧,有需要的可以直接复制过去,改一下相关内容,就可以在python下直接使用了(别忘了申请聚宽账号和本地数据权限,按照我上文的介绍。)
#聚宽本地调用数据
#https://www.joinquant.com/help/api/help?name=JQData
from jqdatasdk import *
from dbfread import DBF
import xlsxwriter
#登录一下本地数据
auth('输入你的聚宽用户名','输入你的聚宽密码')
#查询剩余可调用条数
sykdyts = get_query_count()
print(sykdyts)
#设定要查询的股票,上海 .XSHG 深圳 .XSHE 设定查询的时间
stock_code = '600519.XSHG'
start_time = '2018-01-01'
end_time = '2018-12-31'
#获取合并利润表
def income_statement():
from jqdatasdk import finance
q = query(finance.STK_INCOME_STATEMENT).filter(finance.STK_INCOME_STATEMENT.code==stock_code,\
finance.STK_INCOME_STATEMENT.start_date==start_time,\
finance.STK_INCOME_STATEMENT.end_date==end_time,\
finance.STK_INCOME_STATEMENT.report_type==0).limit(200)
df=finance.run_query(q)
df=df.to_dict()
print(df)
return df
income_statement()
#获取现金流量表
def cashflow_statement():
from jqdatasdk import finance
q = query(finance.STK_CASHFLOW_STATEMENT).filter(finance.STK_CASHFLOW_STATEMENT.code==stock_code,\
finance.STK_CASHFLOW_STATEMENT.start_date==start_time,\
finance.STK_CASHFLOW_STATEMENT.end_date==end_time,\
finance.STK_CASHFLOW_STATEMENT.report_type==0).limit(200)
df=finance.run_query(q)
df=df.to_dict()
print(df)
return df
cashflow_statement()
#获取资产负债表
def blance_sheet():
from jqdatasdk import finance
q = query(finance.STK_BALANCE_SHEET).filter(finance.STK_BALANCE_SHEET.code==stock_code,\
finance.STK_BALANCE_SHEET.start_date==start_time,\
finance.STK_BALANCE_SHEET.end_date==end_time,\
finance.STK_BALANCE_SHEET.report_type==0).limit(200)
df=finance.run_query(q)
df=df.to_dict()
print(df)
return df
blance_sheet()
def write_in_excle():
# 创建excle表格,并创建具体sheet
workbook = xlsxwriter.Workbook(stock_code '.xlsx')
worksheet = workbook.add_worksheet('利润表')
worksheet1 = workbook.add_worksheet('现金流量表')
worksheet2 = workbook.add_worksheet('资产负债表')
#写入利润表数据
stock_dict = income_statement()
# 从第一行第一列开始定义
row = 0
col = 0
# 依次添加列数据,先把数据名称写进去
for name in stock_dict.keys():
worksheet.write(row, col,name)
row = 1
# 从第一行第一列开始定义
row = 0
col = 0
#然后开始写具体数据
for content in stock_dict.values():
for num,s_content in content.items():
col = int(num 1)
worksheet.write(row, col,s_content)
row = 1
#写入现金流量表数据
stock_dict = cashflow_statement()
# 从第一行第一列开始定义
row = 0
col = 0
# 依次添加列数据,先把数据名称写进去
for name in stock_dict.keys():
worksheet1.write(row, col,name)
row = 1
# 从第一行第一列开始定义
row = 0
col = 0
#然后开始写具体数据
for content in stock_dict.values():
for num,s_content in content.items():
col = int(num 1)
worksheet1.write(row, col,s_content)
row = 1
#写入资产负债表数据
stock_dict = blance_sheet()
# 从第一行第一列开始定义
row = 0
col = 0
# 依次添加列数据,先把数据名称写进去
for name in stock_dict.keys():
worksheet2.write(row, col,name)
row = 1
# 从第一行第一列开始定义
row = 0
col = 0
#然后开始写具体数据
for content in stock_dict.values():
for num,s_content in content.items():
col = int(num 1)
worksheet2.write(row, col,s_content)
row = 1
workbook.close()
write_in_excle()
code
具体的使用方法:
在15行,设置你想查询的股票代码,提示里有后缀说明,如果是深圳的股票记得把后缀改成.XSHE。
先标注一下,我这个代码仅限获取已经发布的年报,最早可以到2005年(聚宽最早给到05年的),如果要获取季报等内容,就需要改代码了,这里先不描述。
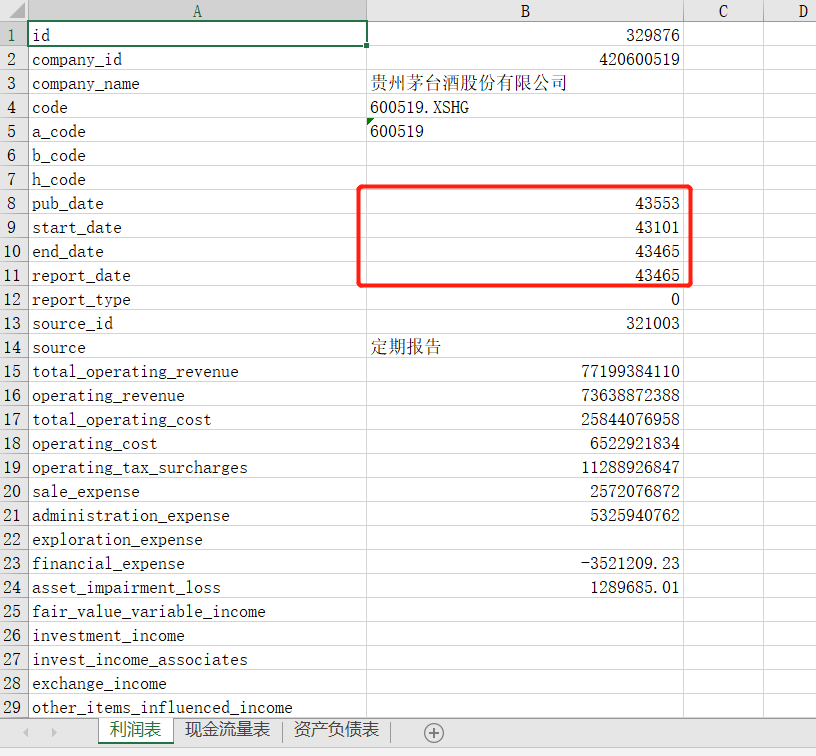
16、17行是设置获取报告的开始和结束时间,因为我需要的是2018年的年报,所以开始结束就如上图所示。如果你想获取其他年份的报告,自己改一下年,不要改日期,因为这个开始结束日期是指报告的覆盖范围。
执行完毕之后就可以在你python文件保存的文件夹下生成一个excle了。
打开后可以看到三张表
红框部分记得改一下单元格格式,改成 日期,就可以正常显示了。至于名称这栏都是英文,有空再改代码吧,这个比耗时间,顺便学学英文不也挺好的么~
以上就是全部内容啦,分享出来希望能帮到大家。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程