最好的学习方法是教会他人
导言
前文中,经过requests请求,已经把网页的内容获取下来,接下来要做的就是解析这个页面,找到自己需要的信息。而Beautiful Soup库就是这样一个解析、遍历、维护“标签树”的功能库。
本文目录
1、Beautiful Soup安装与使用
2、bs4库的基本元素
3、bs4库的遍历功能
4、信息标记的三种形式及比较
5、信息提取的一般方法
1、Beautiful Soup安装与使用
安装:
pip install beautifulsoup4
Beautiful Soup库,也叫beautifulsoup4或bs4
约定引用方式如下,即主要是用BeautifulSoup类
from bs4 import BeautifulSoup
import bs4
运行以下代码,可以清晰的看出其差异:
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.baidu.com/")
demo = r.text
print(demo)
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
此处就不再贴图了。
2、bs4库的基本元素
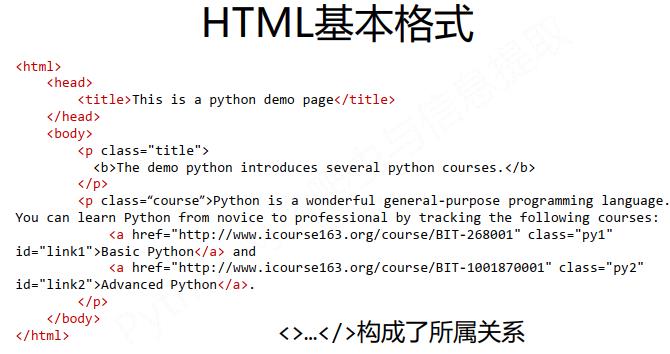
网页信息的组织形式是HTML,也即标签树,而BeautifulSoup对应一个HTML/XML文档的全部内容。如下图所示。



BeautifulSoup可以对网页进行解析,其包含的解析器如下:

下面详细看看BeautifulSoup类的基本元素
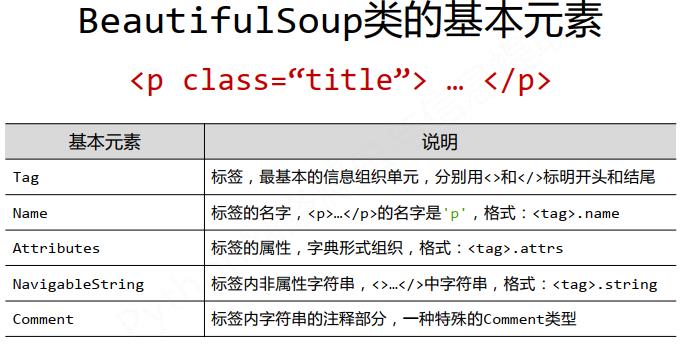
Tag标签
任何存在于HTML语法中的标签都可以用soup.访问获得
当HTML文档中存在多个相同```对应内容时, soup.```返回第一个
Tag的name
每个```都有自己的名字,通过.name```获取,字符串类型
Tag的attrs
一个``````可以有0或多个属性,字典类型
Tag的NavigableString
标签内非属性字符串, <>…>中字符串,格式: .string
NavigableString可以跨越多个层次
标签内字符串的注释部分,一种特殊的Comment类型
更详细的代码示例文档,可以参考以下两个地方:
BS4 解析库的使用
标签的各种处理
总体思路就是对html进行解析,得到soup对象,进行各种属性、方法调用,干自己想干的事
3、bs4库的遍历功能
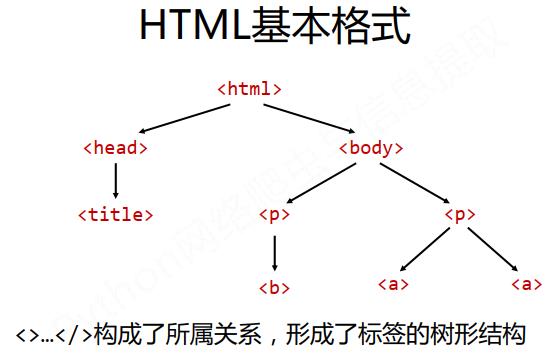
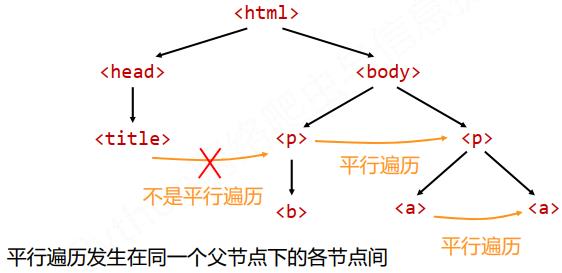
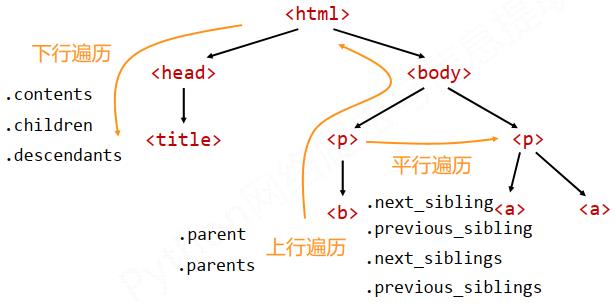
遍历是针对HTML而言。共有三种遍历方式,如下所示。
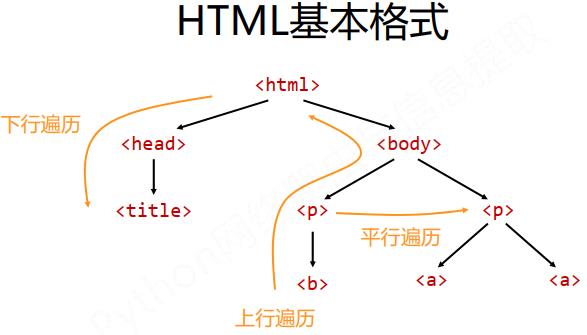
下行遍历方法:
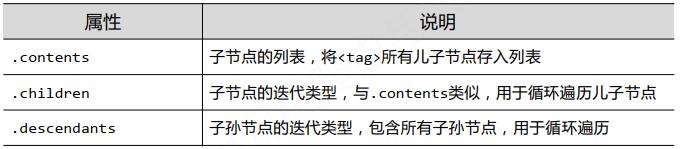
遍历儿子节点
for child in soup.body.children:
print(child)
遍历孙子节点
for child in soup.body.descendants:
print(child)
上行遍历方法:

平行遍历方法:
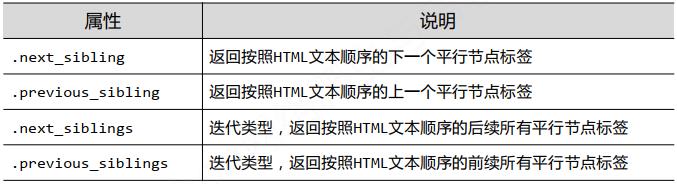
需要注意的是,平行遍历发生在同一个父节点下的各个点间:
遍历方法总结:
4、信息标记的三种形式及比较
第一种形式:XML(eXtensible Markup Language),即前面的以标签对形式出现的方式。
百度百科:XML
第二种形式:JSON(JavaScript Object Notation),以一种键值对的形式出现。
百度百科:JSON
第三种形式:YAML(YAML Ain't Markup Language),一种无类型键值对,缩进表达所属关系等
百度百科:YAML
比较
XML:
最早的通用信息标记语言,可扩展性好,但繁琐。Internet上的信息交互与传递。
JSON:
信息有类型,适合程序处理(js),较XML简洁。移动应用云端和节点的信息通信,无注释。
YAML:
信息无类型,文本信息比例最高,可读性好。各类系统的配置文件,有注释易读。
5、信息提取的一般方法
方法一:
完整解析,再提取关键信息。
需要标记解析器,如bs4库的标签对遍历。优点是信息解析准确,缺点是提取过程繁琐,速度慢。
方法二:
无视标记形式,直接搜索。提取快,但准确性打折扣。
方法三:
融合形式解析与搜索方法,需要标记解析器及文本查找函数。
本文总结
1、学会bs4解析html
2、理解BeautifulSoup对象相关方法,及查找相关内容
3、了解信息的标记与提取









