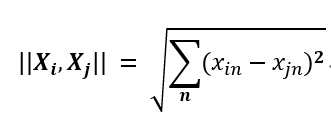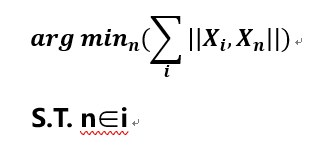一、 背景介绍
我们知道,在各种数据分析方法中,除了部分方法本身对数据值不敏感外,离群值、极端值对于分析结果都是具有影响的。这种影响尤其体现在需要对数据具体的值进行运算的方法中,比如回归类型的问题。极端值出现频率过高,极端值过于极端,都有可能造成分析结果的严重偏误,在探索数据之间关系和规律的过程中,这种极端值造成了很大困扰。
而金融数据分析中,无论是金融理论在实践分析中的应用,比如尝试使用CAPM,Fama-Franch因子模型对现实经济标的进行分析,还是在量化决策过程中应用模型进行择时或品种选择,都离不开对原始数据的处理和运算。对于数据在这些领域的应用,模型能否给出精准结果至关重要,前者决定着学术观点是否能被现实情况有力支撑,后者则直接决定了投资行为是否能最大化的产生效益。虽然保证模型结果的精确性是一个多步骤的复杂过程,但一定离不开对原始数据的维护。在这个前提下,对待极端值的态度和处理方法也就成了需要不断探索的问题。
对于极端数据,在量化领域有一些常用的方法。比如3-Mad方法,3-Sigmod方法,这些方法在剔除离群的数据方面是简单而有效的,受到了广泛的认可。用沪深300股票的市值数据为例:
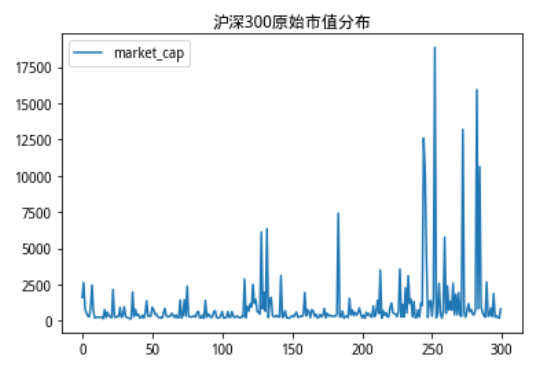
沪深300的原始市值分布如下:
我们可以看到,沪深300成分股市值分布十分极端,存在部分市值规模过于庞大的股票,如果用这样的数据进行运算,得出的结果会收到极端值非常严重的影响
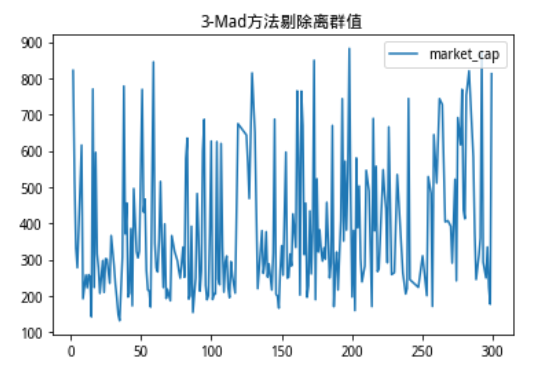
我们使用3-Mad方法进行剔除
无论是从纵坐标的值域还是分布图像上都可以看出,3-Mad方法剔除后,筛选出的股票市值波动都被压缩到了一定的范畴内,并且对比原始分布,几乎完全剔除了特别极端的离群点。
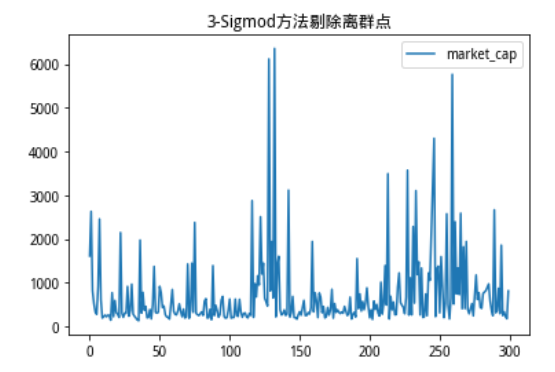
我们再看一看以标准差为参照基准的3-Sigmod方法对离群点的剔除效果。
对比原始分布的图例值域,可以看出极端离群的市值点被3-Sigmod方法过滤掉了,而对比3-Mad方法,3-Sigmod方法在剔除条件上更宽松一点,两者各有优劣,3-Mad方法严格地保证了数据在一定范围内波动,而3-Sigmod方法则保留了更多的数据值,可以根据不同的需求对方法进行选择
通过上文的介绍,我们已经看出,在剔除离群点上,已经有很多行之有效的方法可供选择。但是,事实上我们仍然面对一个问题,那就是,上文介绍的所有方法,都是对于单一序列的处理,如果我们现在面对的是有两个以上维度的高维数据,我们该如何考虑离群点的处理方法。
可能有人会说,高维数据也是由不同截面下的一维序列构成的,对于每个不同的维度应用一下上面的方法就可以了。但事实上并不能这么做,这样做的,光是显然易见的弊端就有两个:第一,会造成更大规模的信息损失,因为逐一进行剔除,不同的纬度之间剔除的部分是取并集的,最极端会出现提出所有数据的情况;第二,这样的方法在高维度上没有考虑到不同维度之间联合分布。
二、方法介绍
基于上述问题,我们思考了对高维数据剔除极端值的一种新方法,并且对极端值的处理重新做了设计。
首先我们知道高维数据是形如 \mathbit{X}i=(x{i1},x{i2},x{i3},...x_{in})的向量组,这些向量组虽然无法直接可视化描述,但是对于他们联合分布的关系我们可以使用替代的方法去描述标志。在这里我选择了距离作为这个替代变量,距离计算公式表示如下:
为了能够描述数据点之间的分布,我们需要找到一个目标数据点,使得所有其他数据点到这个目标数据点距离最小化,然后用其他数据点到目标数据点之间的距离来近似地描述所有数据在高维上的分布情况,数学表示如下:
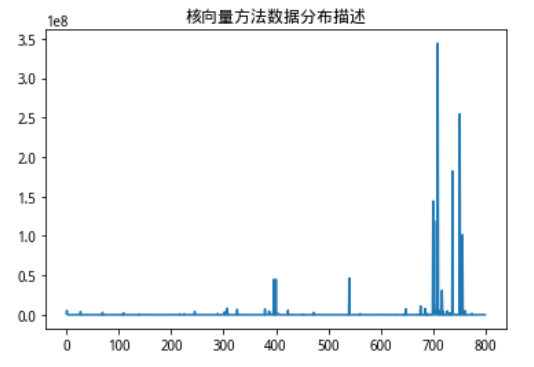
我把找到的这个目标向量称为核向量。还是以沪深300股票为例子,我们使用的数据维度为市值,ROE和市盈率(pe ratio),我们观察一下通过寻找核向量而计算得出的数据分布情况。
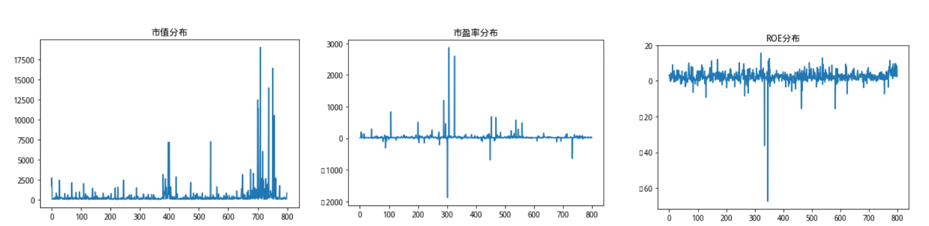
这时候我们发现了一个问题,我们看一看数据点各个维度单一序列的分布情况。
我们发现,寻找核向量并计算出来用以描述高维联合分布情况地距离数据,和市值数据的分布情况一致性程度非常高,也就是说,市值数据由于本身数值巨大,完全影响了我们对距离的计算,占到了巨大的权重,但事实上,在我们的想法以及现实经济意义中,我们认为这些财务情况对股票的影响权重虽然不一定等权,但不可能是这样不平衡的极端情况,鉴于此,我们修改了核向量的寻找方法,在加入了距离惩罚项,以此来平衡不同量纲的数据对距离计算的影响。当然这个距离惩罚项可以有多种计算方法,比如Max-Min,、Z-score等,这里我们使用最简单的均值作为距离惩罚。
我们观察一下修改方法后的数据情况:
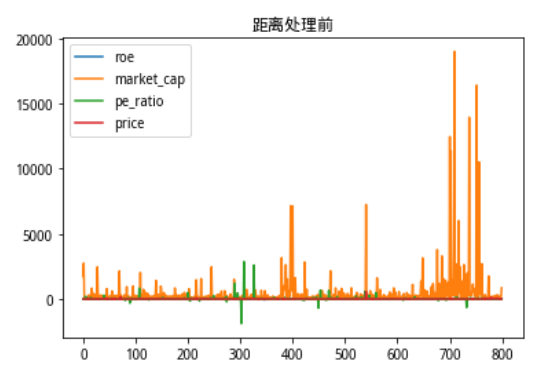
首先把修改方法前所有的原始数据分布绘制出来看一看
可以看到市值在数据上的体量完全覆盖掉了其他数据的分布情况。
这个时候我们可以看到修改方法后,不同数据的分布情况都能够较为明显得体现出来。
当前计算出来的核向量距离数据分布如下:
经过以上计算,我们就可以进行下一步,处理数据了。
处理极端数据的方法,我并没有直接使用传统的直接剔除的方法,因为鉴于目前各种统计方法对数据量的需求,我们更愿意保留一些数据信息使得模型更加平滑可靠。在统计学习领域有一种叫做KNN的计算方法,聚宽的量化课堂上有详细的描述,我之前也写过如何实现KNN的文章,有需求的读者可以去阅读,在这里不再赘叙。
简单来说,我们的模型使用的历史数据都是有标注的,一个特征向量对应一个特征值,我们经常通过KNN算法对特征值进行预测,但是这个方法中我们反向运用KNN,首先我们通过一个准则来确定一个特征向量是不是离群点,如果是,则通过寻找和它标签值最邻近的K个值特征向量,然后将这个离群点的特征向量值替换为K个点对应特征值的平均值。这样既处理了数据,又部分保留了特征信息,同时没有减少数据量。
这时候我们又遇到了一个问题,在回归问题中,特征向量的标签值是连续的数字,寻找最临近数据点,但是分类问题中,标签大多为离散取值,甚至在二分类问题中我们的标签全都是bool值,总不能随机选取几个bool值进行KNN计算吧?
所以我们给出的权衡方法是,在分类问题中,如果数据点A是离群点,那么我们就寻找和数据点A到核向量数据点距离值最接近且不为离群点的的K个数据点作为A的临近点进行计算。这样可以比较妥当的解决不同问题中由于数值特性带来的计算问题。
最后要提及的是,我们的离群点确认方法是在核向量距离中确定离群点,我们认为距离核向量过于远的数据为离群点,这里我还是使用了3-Mad的方法,和上文一致,我们可以看下这样处理后,单一维度的分布情况
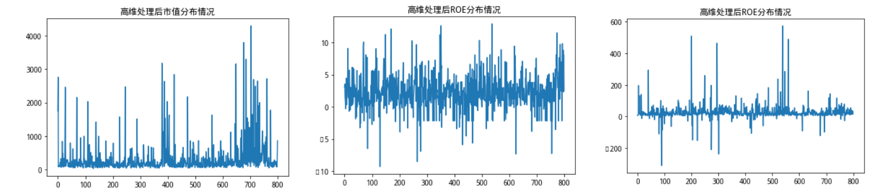
对比一下上图完全无处理时候的单一序列分布图,可以明显看出各个特征维度在极端值和值分布上都得到了较好的处理。
三、 方法实证
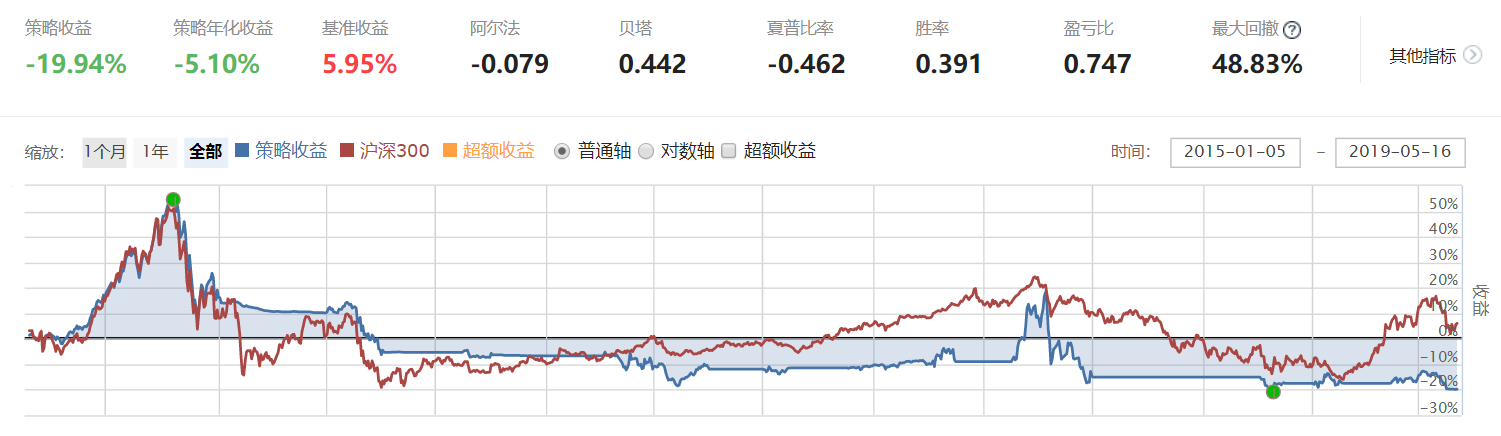
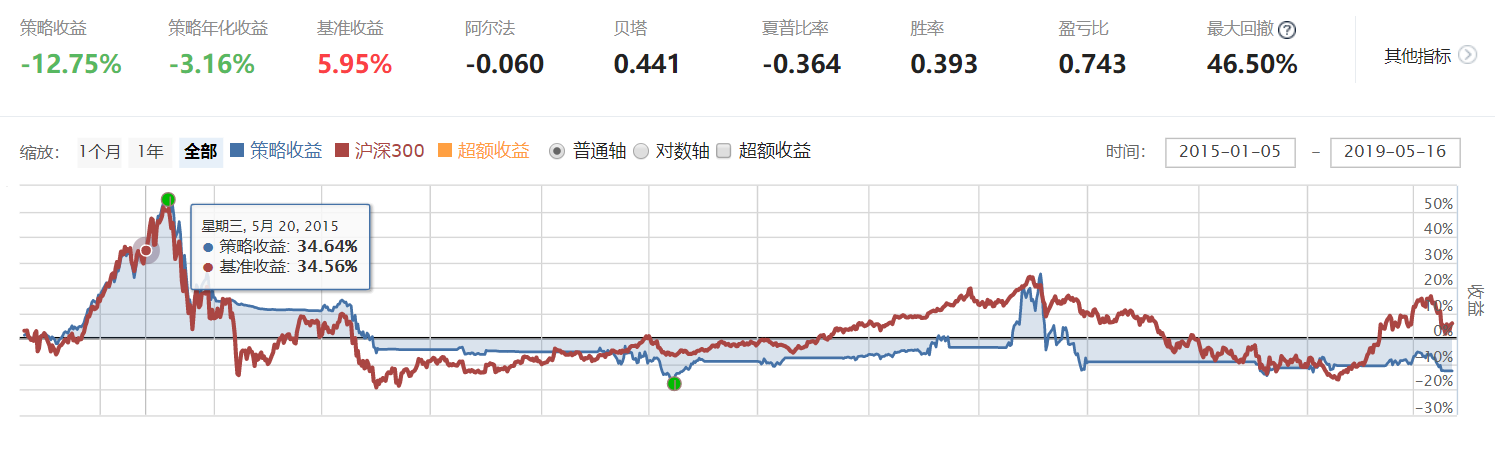
注:截面回归的实证代码和数据处理具体方法代码一起写在研究环境里,在下方已插入文章,对比测试数据处理效果的策略由于我对于聚宽社区文章相关功能应用不好,没有找到同时插入两个回测的方法,所以仅展示使用该方法调整数据后的策略回测
from jqdata import*
import statsmodels.api as sm
import datetime
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#前置条件
current_date = datetime.date(2018,12,10)
stock_list = get_index_stocks('000906.XSHG',date = current_date)
trade_days = list(get_all_trade_days())
#准备数据
market_query = query(indicator.roe,
valuation.market_cap,
valuation.pe_ratio).filter(
valuation.code.in_(stock_list))
MKT_data = get_fundamentals(market_query,date = current_date)
price_data = get_price(stock_list,current_date,current_date,'1d',['close'])['close'].T
MKT_data['price'] = array(price_data)
/opt/conda/lib/python3.6/site-packages/jqresearch/api.py:87: FutureWarning: Panel is deprecated and will be removed in a future version. The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/. Pandas provides a `.to_xarray()` method to help automate this conversion. pre_factor_ref_date=_get_today())
#无处理回归结果
x = MKT_data[['roe','market_cap','pe_ratio']]
y = MKT_data['price']
model = sm.OLS(y,x)
result = model.fit()
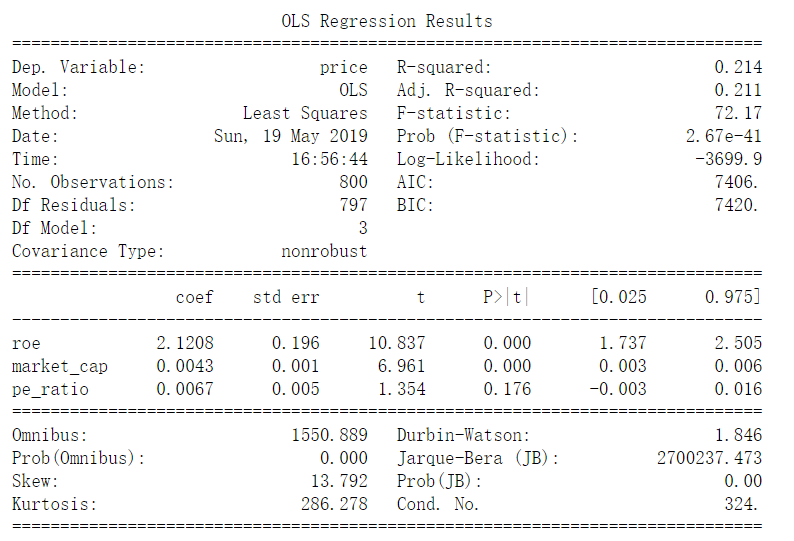
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: price R-squared: 0.214
Model: OLS Adj. R-squared: 0.211
Method: Least Squares F-statistic: 72.17
Date: Sun, 19 May 2019 Prob (F-statistic): 2.67e-41
Time: 16:56:44 Log-Likelihood: -3699.9
No. Observations: 800 AIC: 7406.
Df Residuals: 797 BIC: 7420.
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
roe 2.1208 0.196 10.837 0.000 1.737 2.505
market_cap 0.0043 0.001 6.961 0.000 0.003 0.006
pe_ratio 0.0067 0.005 1.354 0.176 -0.003 0.016
==============================================================================
Omnibus: 1550.889 Durbin-Watson: 1.846
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2700237.473
Skew: 13.792 Prob(JB): 0.00
Kurtosis: 286.278 Cond. No. 324.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
#寻找核向量,最小化距离极值处理方法
def cal_sumdis(vector,mat):
dis_mat = float(((mat - vector) ** 2).sum(axis = 1).sum())
return dis_mat
def min_dis_vector(mat):
array_mat = array(mat)
min_vector = array_mat[0]
min_dis = cal_sumdis(min_vector,mat)
for vector in array(mat)[1:]:
if cal_sumdis(vector,mat) < min_dis:
min_dis = cal_sumdis(vector,mat)
min_vector = vector
else:
pass
return min_vector
#按照上述方法寻找核向量
min_dis_vec = min_dis_vector(MKT_data)
#核向量和其他点的距离
dis_spread = ((MKT_data - min_dis_vec) ** 2).sum(axis = 1)
#观察最小距离分布
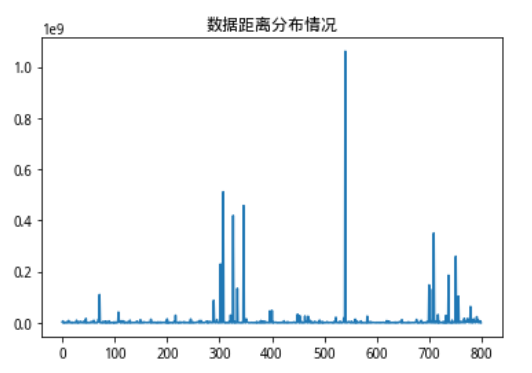
dis_spread.plot(title = '核向量方法数据分布描述')
<matplotlib.axes._subplots.AxesSubplot at 0x7fbc796e2cc0>

#观察市值的数值分布
a = MKT_data['market_cap'].plot()
b = MKT_data['pe_ratio'].plot()
c = MKT_data['roe'].plot()

发现问题,向量距离的分布和市值的数值几乎同分布 原因在于距离计算方法是L2范数,而L2范数数值敏感,放大大值,缩小小值,使得相对数值比较大地市值因素影响能力大幅放大 所以我们使用新方法:距离加权
#修改函数
def new_cal_sumdis(vector,mat):
dis_mat = (mat - vector) ** 2
return dis_mat / (dis_mat.mean(axis = 0) / dis_mat.mean(axis = 0).sum())
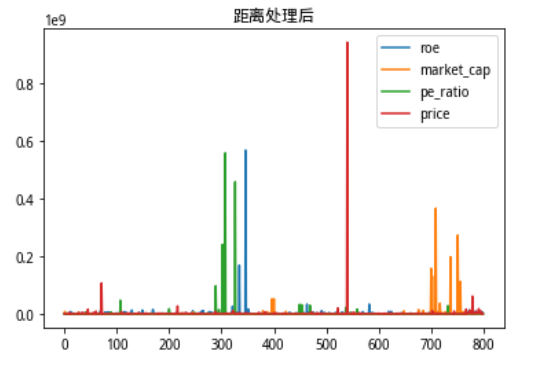
a = new_cal_sumdis(array([1,1,1,1]),MKT_data).plot(title = '距离处理后')
b = MKT_data.plot(title = '距离处理前')


可以清晰地看出经过距离加权处理之后,没有改变原有数据列地分布保留了原有信息,而且使得每一个特征值都不受到本身数值大小的影响
#新核向量寻找函数
def deal_min_dis_vector(mat):
array_mat = array(mat)
min_vec = array_mat[0]
min_distance = float(new_cal_sumdis(min_vec,mat).sum(axis = 1).sum())
for vector in array_mat:
vec_dis = float(new_cal_sumdis(vector,mat).sum(axis = 1).sum())
if vec_dis < min_distance:
min_vec = vector
min_distance = vec_dis
else:
pass
return min_vec
#新核心向量
deal_min_vec = deal_min_dis_vector(MKT_data)
#观察以新核心向量计算出地距离分布
deal_dis_mat = new_cal_sumdis(deal_min_vec,MKT_data).sum(axis = 1)
#deal_dis_mat.plot()
mid_ar = np.ones(300) *float(deal_dis_mat.median())
plt.plot(mid_ar)
mean_ar = np.ones(300) *float(deal_dis_mat.mean())
plt.plot(mean_ar)
affect_num = deal_dis_mat.mean() - deal_dis_mat.median()
affect_num
6883683.096694872

affect_mat = deal_dis_mat - deal_dis_mat.median()
affect_mat.plot()
affect_ar = np.ones(300) * (deal_dis_mat.median() + 3 *affect_num)
plt.plot(affect_ar)
[<matplotlib.lines.Line2D at 0x7f1968cabeb8>]

在一个完全对称的分布里,中位数和平均值应该是相同的,而中位数和平均值的差异,体现了极端值对于均值对中位数偏移的平均影响程度, 而某个点的值和中位数的差距,体现了他们和中位数的距离,这个距离如果大于均值和中位数之间的绝对距离,说明其对均值产生了大于平均水平的对应方向的影响
deal_indexA = deal_dis_mat[deal_dis_mat >= deal_dis_mat.median() + 3 * affect_num].index
deal_indexB = deal_dis_mat[deal_dis_mat <= deal_dis_mat.median() - 3 * affect_num].index
for item in deal_indexB:
if item not in deal_indexA:
deal_indexA.append(item)
else:
pass
deal_index = deal_indexA
#反向KNN,输入原始数据列,寻找最邻近点的数量K个,希望处理的离群点向量值
def Re_KNN(data,KNN_number,aim_series):
data = array(data)
label_list = array([vector[-1] for vector in data])
feature_list = [vector[:-1] for vector in data]
label_arg = abs((label_list - aim_series[-1])).argsort()
min_arg = label_arg[:KNN_number + 1]
min_knn_list = array([feature_list[i] for i in min_arg])
mean_feature = list(min_knn_list.mean(axis = 0))
label_value = mean([label_list[i] for i in min_arg])
mean_point = list(mean_feature)
mean_point.append(label_value)
return array(mean_point)
array_MKT_data = array(MKT_data)
deal_target = np.zeros((array_MKT_data.shape[0] - len(deal_index),4))
j = 0
for i in range(0,array_MKT_data.shape[0]):
if i not in deal_index:
deal_target[j] = array_MKT_data[i]
j += 1
else:
pass
for index in deal_index:
array_MKT_data[index] = Re_KNN(deal_target,5,array_MKT_data[index])
deal_df = pd.DataFrame(array_MKT_data,columns = ['roe','market_cap','pe_ratio','price'])
deal_df['pe_ratio'].plot(title = '高维处理后ROE分布情况')
<matplotlib.axes._subplots.AxesSubplot at 0x7fbc162206d8>

MKT_data['market_cap'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f1968be7358>

#观察回归效果
deal_x = deal_df[['roe','market_cap','pe_ratio']]
deal_y = deal_df['price']
deal_model = sm.OLS(deal_y,deal_x)
deal_result = deal_model.fit()
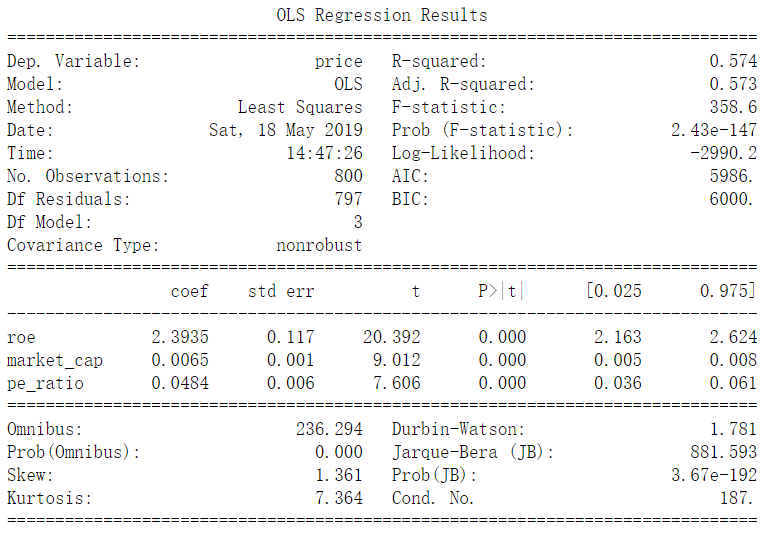
print(deal_result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: price R-squared: 0.574
Model: OLS Adj. R-squared: 0.573
Method: Least Squares F-statistic: 358.6
Date: Sat, 18 May 2019 Prob (F-statistic): 2.43e-147
Time: 14:47:26 Log-Likelihood: -2990.2
No. Observations: 800 AIC: 5986.
Df Residuals: 797 BIC: 6000.
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
roe 2.3935 0.117 20.392 0.000 2.163 2.624
market_cap 0.0065 0.001 9.012 0.000 0.005 0.008
pe_ratio 0.0484 0.006 7.606 0.000 0.036 0.061
==============================================================================
Omnibus: 236.294 Durbin-Watson: 1.781
Prob(Omnibus): 0.000 Jarque-Bera (JB): 881.593
Skew: 1.361 Prob(JB): 3.67e-192
Kurtosis: 7.364 Cond. No. 187.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程