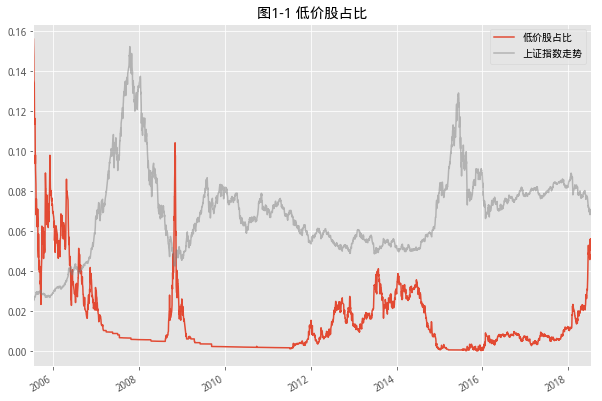
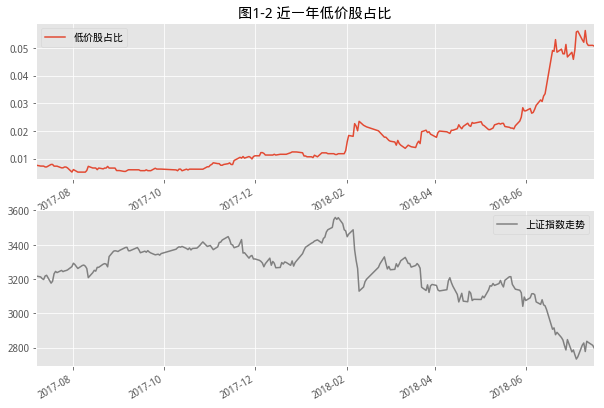
前几天看到一篇市场底部特征研究的文章【华创金工】,觉得有点意思,下面就是将这些衡量底部特征的内容在研究里进行实现。
文章的核心逻辑如下所述:
#返回股价低于2元的股票个数占比
def f1(self,date_list):
bei = len(date_list)//13
se_price_2 = []
for i in range(1,13):
e = date_list[i*bei]
s = date_list[(i-1)*bei]
if i == 0:
s = date_list[0]
elif i == 12:
e = date_list[-1]
all_stock = list(get_all_securities(types='stock',date=e).index)
def f1_1(x):
x=x.dropna(axis=0)
return sum(x)
df = get_price(all_stock,start_date=s,end_date=e,fields=['close'],fq=None)['close']
df_1 = df<=2*(1.04)**i
#print(2*(1.04)**i)
se1 = df_1.apply(f1_1,axis=1)
l2 = [len(get_all_securities(types='stock',date=i)) for i in se1.index ]
se2 = pd.Series(l2,index=se1.index)
#se2 = df_1.apply(f1_1[1],axis=1)
se_price_2.append(se1/se2)
return pd.concat(se_price_2)
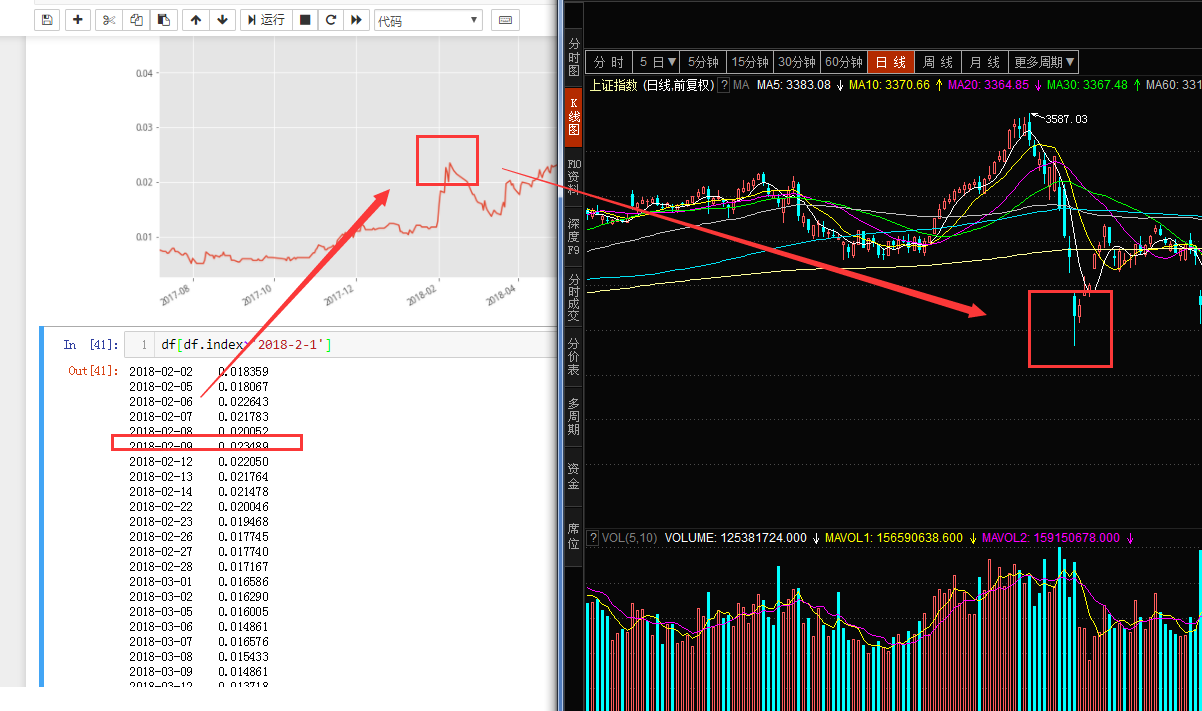
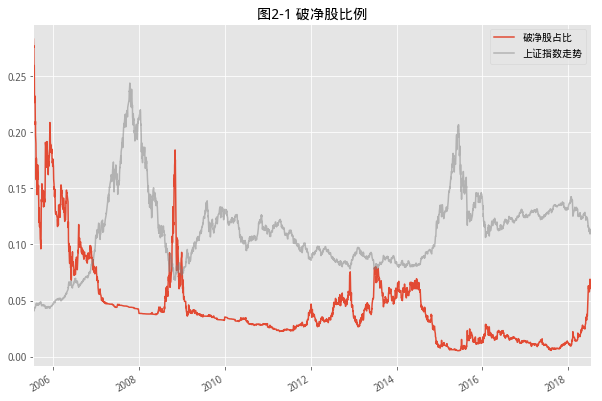
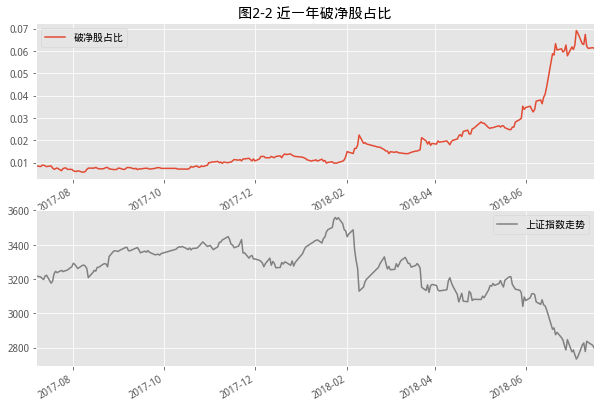
#返回破净股比例
def f2(self,date_list):
pb = []
for d in date_list:
df_temp = get_fundamentals(query(valuation.code,valuation.pb_ratio,valuation.circulating_market_cap,valuation.pe_ratio),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['pb_ratio']<=1])
#b = len(df_temp[(df_temp['pb_ratio']<=1)&(df_temp['pb_ratio']>=0)])
pb.append(b/a)
df_2 = pd.DataFrame(pb,index=date_list,columns=['pb_ratio'])
return df_2['pb_ratio']
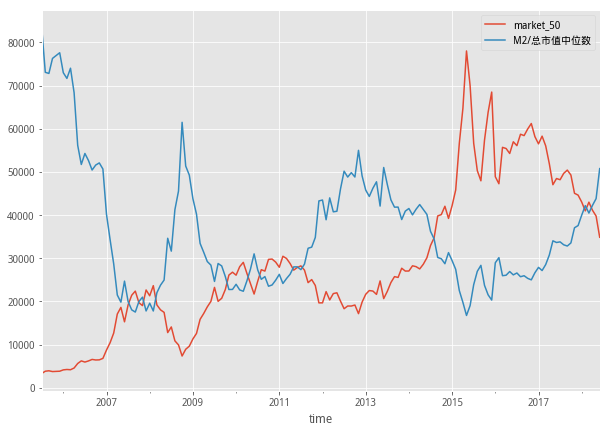
def f3_1(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
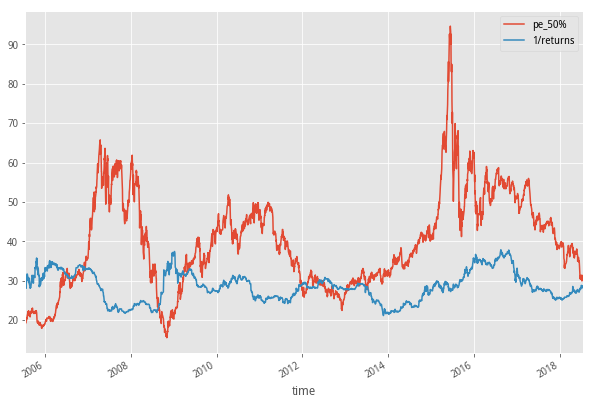
#PE中位数和十年国债收益率倒数的比较
def f4_1(self,date_list):
deb_date = pd.read_excel('10年国债数据.xls')
deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])]
deb_date.index = deb_date['time'].values
date_list_new = deb_date.time
pe = []
cir_market_ratio = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['circulating_market_cap']<45])
#print(df_temp['circulating_market_cap'].quantile(0.5))
c = df_temp['pe_ratio'].quantile(0.5)
cir_market_ratio.append(b/a)
pe.append(c)
df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%'])
df_4['returns'] = deb_date['returns']
df_4['1/returns'] = 100/deb_date['returns']
df_4['cir_market_ratio'] = cir_market_ratio
#df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns']
return df_4[['pe_50%','1/returns','cir_market_ratio']]
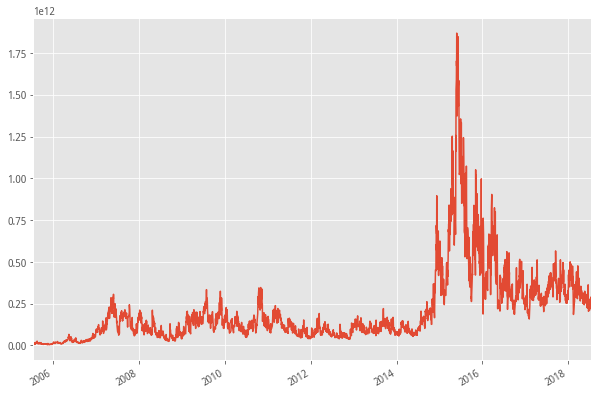
#全市场成交额
#输出两个市场成交额数据变化
def f5(self,date_list):
s,e = date_list[0],date_list[-1]
pl = get_price(['399001.XSHE','000001.XSHG'],start_date=s,end_date=e,fields=['money'])['money']
pl['money'] = pl['399001.XSHE'] pl['000001.XSHG']
return pl['money']
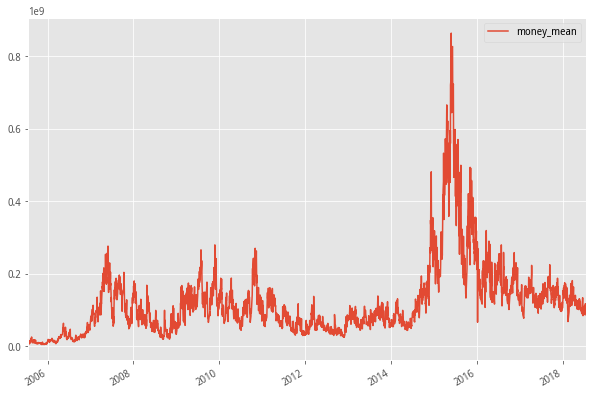
#个股成交的冷淡
#返回个股成交金额
def f6(self,date_list):
l_money_mean = []
for i in date_list:
all_stock = list(get_all_securities(types='stock',date=i).index)
df_money = get_price(all_stock,end_date=i,count=1)['money']
df_money = df_money.dropna(axis=1)
money_mean = sum(df_money.T)/df_money.shape[1]
l_money_mean.append(money_mean.values)
df_money_mean = pd.DataFrame(l_money_mean,index=date_list,columns=['money_mean'])
return df_money_mean
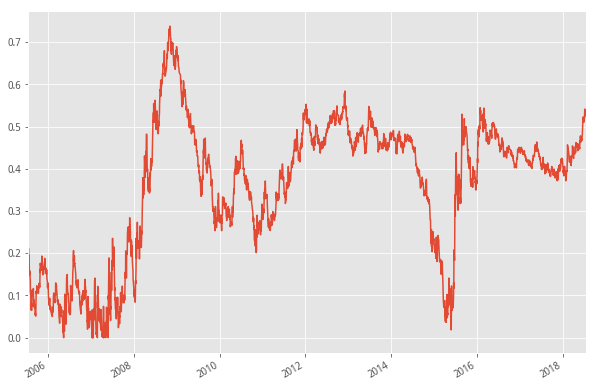
#个股区间最大跌幅中位数
def f7(self,date_list):
date = date_list[-1]
#all_stock = list(get_all_securities(types='stock',date=date).index)
all_stock = get_index_stocks('000300.XSHG')
df_temp = get_price(all_stock,start_date='2005-4-1',end_date=date,fields=['close'])['close']
se_l = []
for i in date_list:
df_temp_1 = df_temp[df_temp.index<i]
#回撤
se = 1-df_temp_1[-1:]/df_temp_1.max()
#格式为series
se_l.append(se.T.quantile(0.5))
return pd.concat(se_l)
次新股,一般是指上市一年以内的股票,可以通过以下代码获取近一年上市的所有股票,共计241只,占全市场股票6.8%,取出全市场换手率最高的前100只股票,其中次新股却有57只,对广大股民来讲,次新确实有着绝对的人气。
import datetime
#获取所有的股票信息
df = get_all_securities()
#筛选出近一年的股票
df[df['start_date']>datetime.date(2017,7,20)]
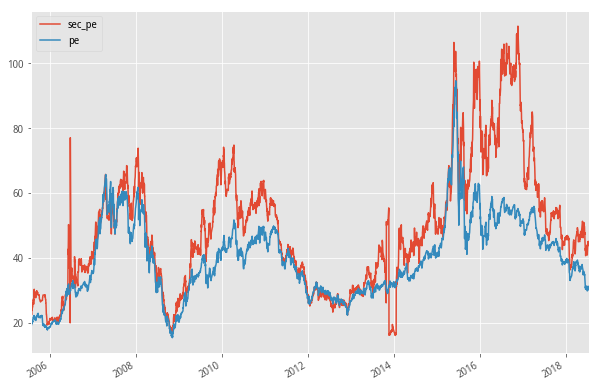
下面是次新股和全市场股票的PE中位数的数据,就最近一次的牛市行情来看,次新是不一样的,在2015股灾之后,依然走出了一波行情,直到2016年年底才开始跳水,这与IPO加速都有着直接的关系。数据往前推几年,牛熊交替的过程中我们看到,市场好的时候,大家各有各的花样,市场不好的时候,看起来都是一个样。最低点时次新股与全市场估值接近,就是所谓通杀。就目前来看,次新还是有着自己的想法。
#获取次新股和全市场股票的PE中位数
def f8(self,date_list):
sec_new_pe = []
pe = []
p_ratio_l = []
all_stock = get_all_securities(types='stock',date=date_list[-1])
all_stock['fir_open'] = [get_price(stock,end_date=all_stock.loc[stock]['start_date'],count=1,fields=['open'])['open'].values[0] for stock in all_stock.index]
for d in date_list:
df_temp = get_price('000001.XSHG',end_date=d,count=252)
year_1,month_1,day_1 = int(str(df_temp.index[0])[:4]), int(str(df_temp.index[0])[5:7]), int(str(df_temp.index[0])[8:10])
year,month,day = int(str(df_temp.index[-1])[:4]), int(str(df_temp.index[-1])[5:7]), int(str(df_temp.index[-1])[8:10])
sec_new_stock_df = all_stock[(all_stock['start_date']>datetime.date(year_1,month_1,day_1)) & (all_stock['start_date']<datetime.date(year,month,day))]
sec_new_stock = sec_new_stock_df.index
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(sec_new_stock)),date=d)
df_temp_1 = get_fundamentals(query(valuation.code,valuation.pe_ratio),date=d)
pe_sec = df_temp['pe_ratio'].quantile(0.5)
pe_all = df_temp_1['pe_ratio'].quantile(0.5)
sec_new_pe.append(pe_sec)
pe.append(pe_all)
#获取次新股当前价格
sec_new_price = get_price(list(sec_new_stock),end_date=d,fields=['close'],count=1)['close'].T
sec_new_price.columns=['fir_open']
p_ratio = sec_new_price['fir_open']/all_stock.loc[sec_new_price.index,:]['fir_open']
po_ratio = len(p_ratio[p_ratio<1])/len(p_ratio)
p_ratio_l.append(po_ratio)
df_pe = pd.DataFrame(sec_new_pe,index=date_list,columns=['sec_pe'])
df_pe['pe'] = pe
df_pe['p_ratio'] = p_ratio_l
return df_pe
a = f()
#由于部分指数上市较晚,这里开始时间从2015年开始
date_list = a.get_tradeday_list('2015-7-17','2018-7-17')
df9 = a.f9(date_list)
df9 = df9.sort_index(ascending=1)
df9.plot(figsize=(10,7))
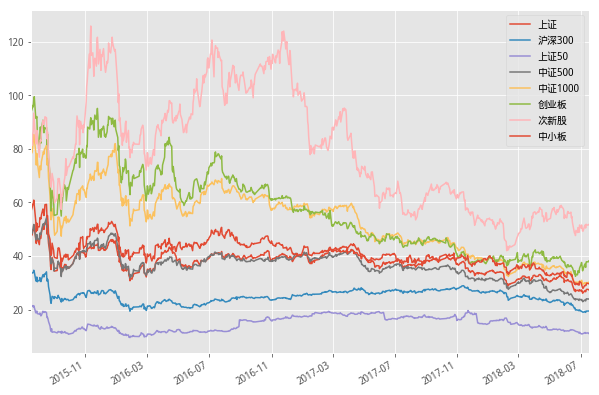
#市场大底,行业一片惨淡,无一例外
#行业PE估值
def f9(self,date_list):
#指数用成分股,pe值做市值加权处理
index_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE']
index_name = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板']
pe_fin = []
for i in date_list:
pe_index = []
for j in index_list:
stock_list = get_index_stocks(j,i)
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(stock_list)),date=i)
pe = df_temp['pe_ratio'].quantile(0.5)
pe_index.append(pe)
pe_fin.append(pe_index)
pe_df = pd.DataFrame(pe_fin,index=date_list,columns=index_name)
return pe_df
#导入各种包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
#方法
#获取交易日期列表
#时间序列函数
class f():
date_now = '2018-7-17'
all_stock_info = get_all_securities(types='stock',date=date_now)
all_stock = list(all_stock_info.index)
#df = get_price(list(all_stock.index),start_date='2008-01-01',end_date=date,fields=['close','money','volume'])['close']
#交易日期列表
def get_tradeday_list(self,s='2017-1-1',e=date_now,count=None):
if count != None:
df = get_price('000001.XSHG',end_date=e,count=count)
return df.index
else:
df = get_price('000001.XSHG',start_date=s,end_date=e)
return df.index
#股票个数序列
def all_stock_num(s,e):
get_all_securities(t)
#返回股价低于2元的股票个数占比
def f1(self,date_list):
bei = len(date_list)//13
se_price_2 = []
for i in range(1,13):
e = date_list[i*bei]
s = date_list[(i-1)*bei]
if i == 0:
s = date_list[0]
elif i == 12:
e = date_list[-1]
all_stock = list(get_all_securities(types='stock',date=e).index)
def f1_1(x):
x=x.dropna(axis=0)
return sum(x)
df = get_price(all_stock,start_date=s,end_date=e,fields=['close'],fq=None)['close']
df_1 = df<=2*(1.04)**i
#print(2*(1.04)**i)
se1 = df_1.apply(f1_1,axis=1)
l2 = [len(get_all_securities(types='stock',date=i)) for i in se1.index ]
se2 = pd.Series(l2,index=se1.index)
#se2 = df_1.apply(f1_1[1],axis=1)
se_price_2.append(se1/se2)
return pd.concat(se_price_2)
#返回破净股比例
def f2(self,date_list):
pb = []
for d in date_list:
df_temp = get_fundamentals(query(valuation.code,valuation.pb_ratio,valuation.circulating_market_cap,valuation.pe_ratio),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['pb_ratio']<=1])
#b = len(df_temp[(df_temp['pb_ratio']<=1)&(df_temp['pb_ratio']>=0)])
pb.append(b/a)
df_2 = pd.DataFrame(pb,index=date_list,columns=['pb_ratio'])
return df_2['pb_ratio']
#M2/总市值中位数
def f3(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
#M2/总市值中位数
def f3(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
def f3_1(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
#PE中位数和十年国债收益率倒数的比较
def f4(self,date_list):
deb_date = pd.read_excel('10年国债.xls')
deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])]
deb_date.index = deb_date['time'].values
date_list_new = deb_date.time
pe = []
cir_market_ratio = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['circulating_market_cap']<45])
#print(df_temp['circulating_market_cap'].quantile(0.5))
c = df_temp['pe_ratio'].quantile(0.5)
cir_market_ratio.append(b/a)
pe.append(c)
df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%'])
df_4['returns'] = deb_date['returns']
df_4['1/returns'] = 100/deb_date['returns']
df_4['cir_market_ratio'] = cir_market_ratio
#df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns']
return df_4[['pe_50%','1/returns','cir_market_ratio']]
#PE中位数和十年国债收益率倒数的比较
def f4_1(self,date_list):
deb_date = pd.read_excel('10年国债数据.xls')
deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])]
deb_date.index = deb_date['time'].values
date_list_new = deb_date.time
pe = []
cir_market_ratio = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['circulating_market_cap']<45])
#print(df_temp['circulating_market_cap'].quantile(0.5))
c = df_temp['pe_ratio'].quantile(0.5)
cir_market_ratio.append(b/a)
pe.append(c)
df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%'])
df_4['returns'] = deb_date['returns']
df_4['1/returns'] = 100/deb_date['returns']
df_4['cir_market_ratio'] = cir_market_ratio
#df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns']
return df_4[['pe_50%','1/returns','cir_market_ratio']]
#全市场成交额
#输出两个市场成交额数据变化
def f5(self,date_list):
s,e = date_list[0],date_list[-1]
pl = get_price(['399001.XSHE','000001.XSHG'],start_date=s,end_date=e,fields=['money'])['money']
pl['money'] = pl['399001.XSHE']+pl['000001.XSHG']
return pl['money']
#个股成交的冷淡
#返回个股成交金额
def f6(self,date_list):
l_money_mean = []
for i in date_list:
all_stock = list(get_all_securities(types='stock',date=i).index)
df_money = get_price(all_stock,end_date=i,count=1)['money']
df_money = df_money.dropna(axis=1)
money_mean = sum(df_money.T)/df_money.shape[1]
l_money_mean.append(money_mean.values)
df_money_mean = pd.DataFrame(l_money_mean,index=date_list,columns=['money_mean'])
return df_money_mean
#个股区间最大跌幅中位数
def f7(self,date_list):
date = date_list[-1]
#all_stock = list(get_all_securities(types='stock',date=date).index)
all_stock = get_index_stocks('000300.XSHG')
df_temp = get_price(all_stock,start_date='2005-4-1',end_date=date,fields=['close'])['close']
se_l = []
for i in date_list:
df_temp_1 = df_temp[df_temp.index<i]
#回撤
se = 1-df_temp_1[-1:]/df_temp_1.max()
#格式为series
se_l.append(se.T.quantile(0.5))
return pd.concat(se_l)
#次新股的破发率
#获取次新股和全市场股票的PE中位数
def f8(self,date_list):
sec_new_pe = []
pe = []
p_ratio_l = []
all_stock = get_all_securities(types='stock',date=date_list[-1])
all_stock['fir_open'] = [get_price(stock,end_date=all_stock.loc[stock]['start_date'],count=1,fields=['open'])['open'].values[0] for stock in all_stock.index]
for d in date_list:
df_temp = get_price('000001.XSHG',end_date=d,count=252)
year_1,month_1,day_1 = int(str(df_temp.index[0])[:4]), int(str(df_temp.index[0])[5:7]), int(str(df_temp.index[0])[8:10])
year,month,day = int(str(df_temp.index[-1])[:4]), int(str(df_temp.index[-1])[5:7]), int(str(df_temp.index[-1])[8:10])
sec_new_stock_df = all_stock[(all_stock['start_date']>datetime.date(year_1,month_1,day_1)) & (all_stock['start_date']<datetime.date(year,month,day))]
sec_new_stock = sec_new_stock_df.index
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(sec_new_stock)),date=d)
df_temp_1 = get_fundamentals(query(valuation.code,valuation.pe_ratio),date=d)
pe_sec = df_temp['pe_ratio'].quantile(0.5)
pe_all = df_temp_1['pe_ratio'].quantile(0.5)
sec_new_pe.append(pe_sec)
pe.append(pe_all)
#获取次新股当前价格
sec_new_price = get_price(list(sec_new_stock),end_date=d,fields=['close'],count=1)['close'].T
sec_new_price.columns=['fir_open']
p_ratio = sec_new_price['fir_open']/all_stock.loc[sec_new_price.index,:]['fir_open']
po_ratio = len(p_ratio[p_ratio<1])/len(p_ratio)
p_ratio_l.append(po_ratio)
df_pe = pd.DataFrame(sec_new_pe,index=date_list,columns=['sec_pe'])
df_pe['pe'] = pe
df_pe['p_ratio'] = p_ratio_l
return df_pe
#市场大底,行业一片惨淡,无一例外
#行业PE估值
def f9(self,date_list):
#指数用成分股,pe值做市值加权处理
index_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE']
index_name = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板']
pe_fin = []
for i in date_list:
pe_index = []
for j in index_list:
stock_list = get_index_stocks(j,i)
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(stock_list)),date=i)
pe = df_temp['pe_ratio'].quantile(0.5)
pe_index.append(pe)
pe_fin.append(pe_index)
pe_df = pd.DataFrame(pe_fin,index=date_list,columns=index_name)
return pe_df
a = f()
date_list = a.get_tradeday_list('2005-7-17','2018-7-17')
df1 = a.f1(date_list)
df1.plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f67db8ce668>

df2 = a.f2(date_list)
df2.plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f67f80112b0>

df3 = a.f3(date_list)
#df3.plot(figsize=(10,7))
df3['market_50'] = df3['market_50%']*10**3
df3[['market_50','M2/总市值中位数']].plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f67e2c38908>

df4 = a.f4_1(date_list)
df4.plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f67e6a24780>

df4[['pe_50%','1/returns']].plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f6805a19898>

df7 = a.f7(date_list)
df7.plot(figsize=(10,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f67ddb6db38>


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...