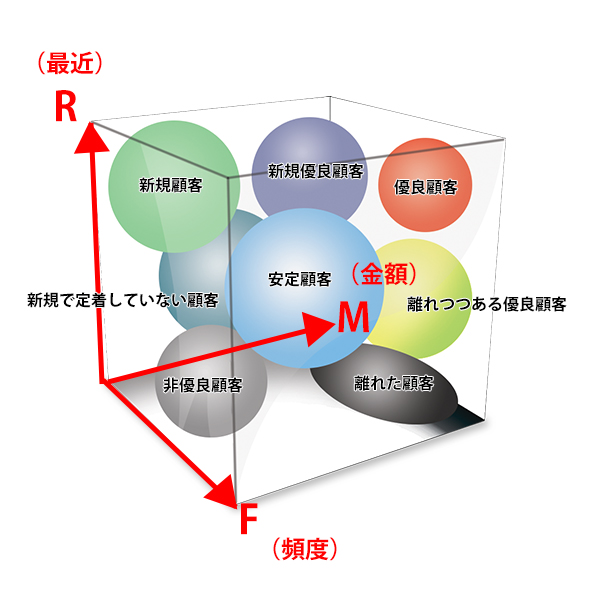
金融行业、零售行业、电信行业等经常要对用户进行划分,以标记不同的标签,从而进行个性化的精准化营销行为。RFM模型,是以用户的实际交易或消费或购买或充值等(以下统称“交易”)一系列行为数据作为基础,从而进行用户群体的划分的,简单而又具有实际价值。RFM模型由三个指标组成,分别为:
(图1 用户分类)(*看到一张日文的描述得比较好的图,就採用了,应该能够看懂)
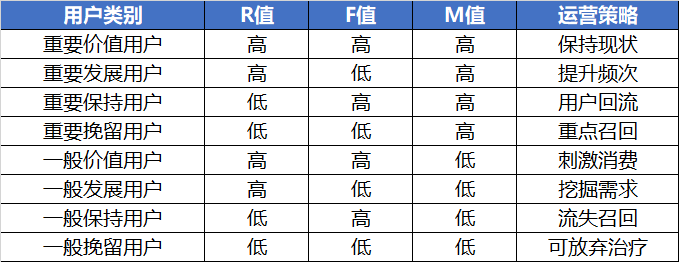
可以把R、F、M每个方向定义为:高、低,两个方向,我们找出R、F、M的中值,R=最近一次消费,高于中值就是高,低于中值就是低,这样就是222=8种用户分类,从而分析出高价值用户,重点发展用户,流失用户等群体进行针对性营销动作。制定运营策略既要结合各类用户在产品中的占比,也要结合产品的实际业务逻辑。参考表1所示:
(表1 不同用户分类的运营策略例)
从csv文件(某电商某段期间的真实运营数据)获取数据,包括用户ID,交易日期,交易金额等字段。数据概况如下:
对原始数据做缺失值处理和异常值处理。由于本次数据没有缺失值,则不需要处理。(如有,可根据需要进行删除或补充处理。)对于交易金额为0.01的交易金额数据,经确认为运营测试数据,做删除处理。对交易日期(ORDERDATE)进行日期转换,以便后续进行时间间隔的计算。
1、指定最近时间截点
由于数据中,最近的交易日期为2018年12月5日,则指定该日期为最近时间截点,所有时间间隔的计算都以该日期为参考点。
2、R、F、M数值计算
以用户ID(USERID)为主键,分别对交易日期(ORDERDATE)求最大值、对交易日期(ORDERDATE)做计数统计、对交易金额(AMOUNTINFO)求和,结合上述1中得到的最近时间截点,得到R、F、M的数值。
对得到的R、F、M的数值使用分位法做区间划分,一般分为5份。同时通过labels标签指定区间标志。对R而言,数值越大,离最近时间截点越远,其区间标志越小。F、M则和R刚好相反。
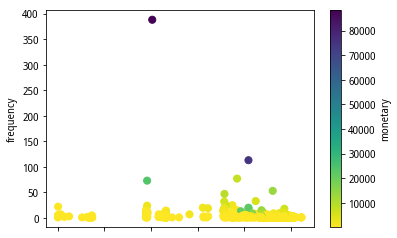
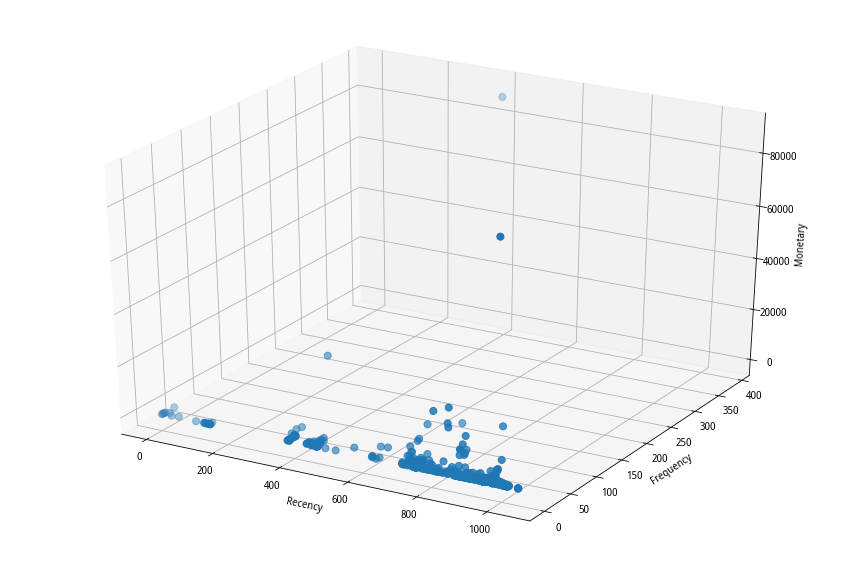
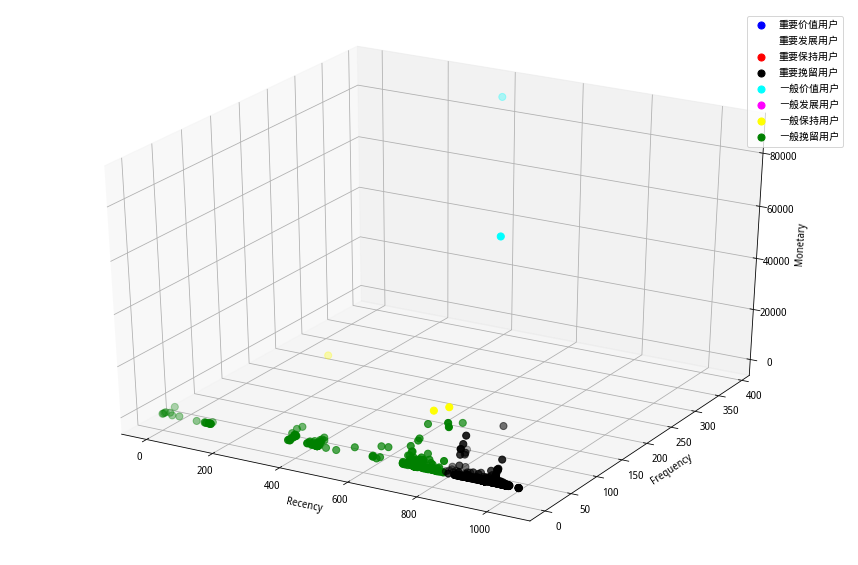
经过计算后的RFM数据分布可参考图2、图3所示:
(图2 RFM-散点图分布)
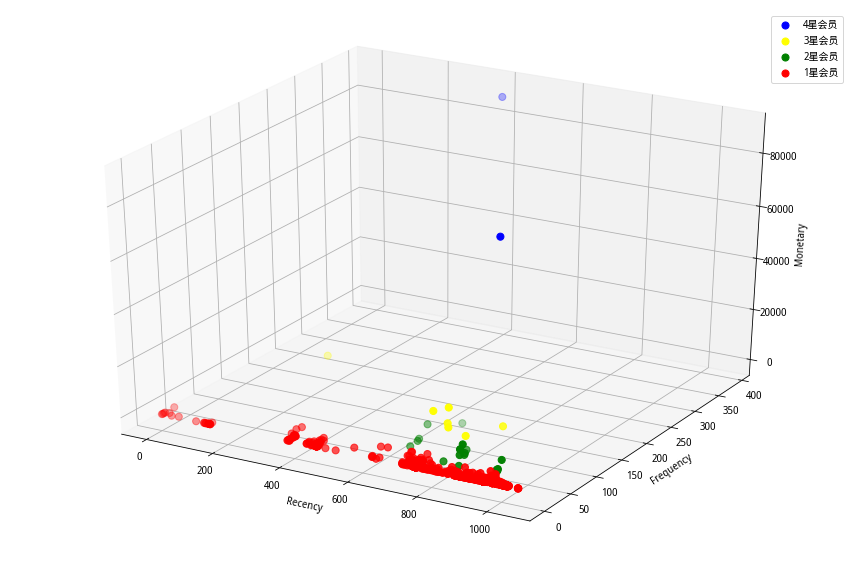
(图3 RFM-3D图分布)
从图2、图3可知,该用户群的早期客户数较多,交易频度集中在50以内,交易金额普遍不是很高。
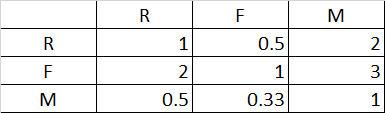
一般来说,权重计算多采用层次分析法(AHP)。金融公司中常用于个人信用风险评级模型的开发,而零售行业中的借贷评级,也可以借鉴该方法。利用AHP方法,先通过两两比较确定各个因素的相对重要性,再通过求解相对重要性计算指标权重。指标权重需经过一致性检验,即随机一次性比率指标CR越小越好(一般要求CR<0.1)。专家评分矩阵可参考表2所示:
(表2 专家评分矩阵)
最终确定权重为:[W_R 、W_F 、W_M] = [ 0.30、0.54、0.16 ](详细的计算过程省略)
由于本案例的指标只有3个,数量较少,不易混淆,所以也可以简单地直接设定。
第一种的分类方法是利用RFM区间标志 分类规则的方法(宋天龙,2017),可参考表1所示。以R为例,其中“RS分布”指RS的平均值,“高”指高于平均值。F、M雷同。其分类结果可参考图4所示:
(图4 基于方法一的分类结果)
从图4可知,该用户群主要由重要挽留用户 一般挽留客户组成,另外有少部分一般价值客户和一般保持用户,严重缺乏重要价值用户和重要发展客户。
第二种方法是直接使用RFM的实际数值,结合K-means聚类方法进行分类,不使用RFM区间标签。在使用该方法的时候,要注意:
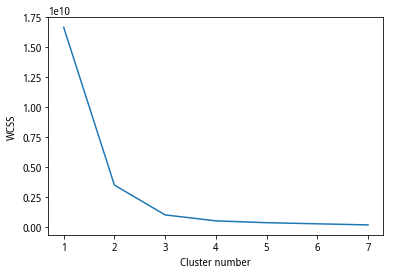
离散值和标准化处理可按照常规的处理办法。离散值处理可使用MAD法,也可简单地按照取对数的处理。标准化处理可用z-score方法。本案例中,只进行了标准化处理。至于按照几类进行分类,可通过elbow method(详细可参考https://en.wikipedia.org/wi/Determining_the_number_of_clusters_in_a_data_set)方法,来推断使用分类数,如图5所示,取图中曲线下降趋势缓和的节点即可,即k=4。
(图5 elbow method)
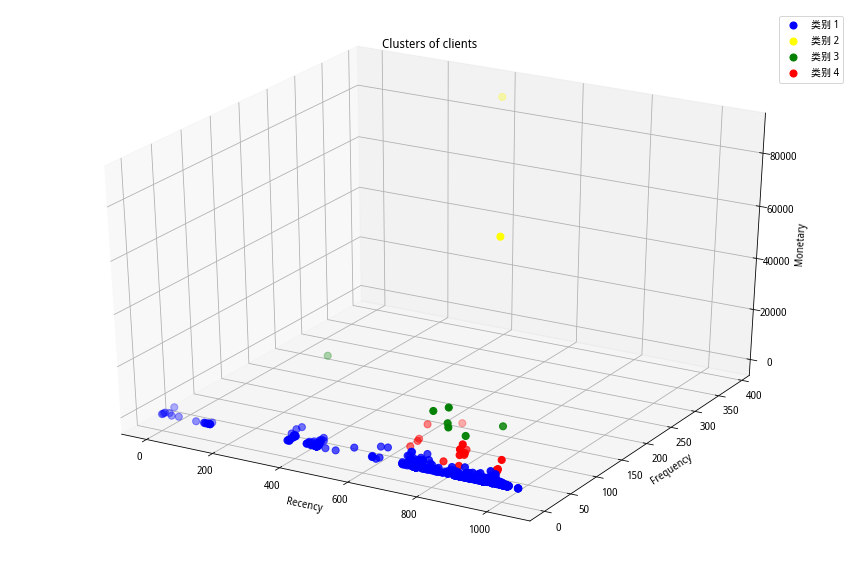
根据分类数=4进行K-means聚类分析。由于此时的分类类别不再是固定的8类,所以我们可将客户简单的分为k类星级客户。分类结果参考图6所示:
(图6 基于方法二的分类结果)
此时的用户分类只是简单地将用户进行分类,尚没有体现不同分类用户之间的区别。此时可取各分类的质心,并将其排名显示,结合了排名的分类结果可参考图7所示:
(图7 基于方法二的分类 排名结果)
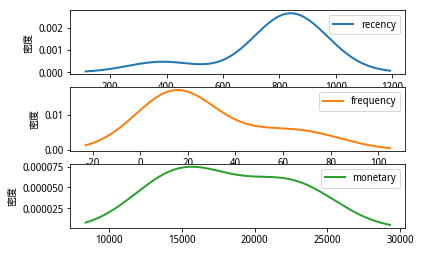
可通过概率密度图来查看各排名用户类别的RFM分布情况(watermelon12138,2019),以3星会员为例,参考图8所示:
(图8 3星会员的概率密度图)
由图8可知,该类用户访问天数在800天前后,其交易频率集中20附近,而其交易金额则分布较广,从15000到25000不等。
从两种不同的分类结果来看,虽然基本都是分为4类,但4类的分法各自不同。前者在分类规则上更容易按照运营人员的期望进行分类,后者更加注重利用机器学习的自动学习能力,把更多的任务交给K-mean聚类来完成。前者虽然也计算用户的价值分数,但前者的分类并不依赖用户价值分数,用户价值分数仅仅只是参考;而后者通过K-means进行聚类,但无法进行用户类别排名,用户类别排名主要依赖于用户价值分数及RFM权重。
参考文献:
1 宋天龙. 《Python数据分析与数据化运营》
2 HarveyLau.《RFM-Clustering》 https://github.com/HarveyLau/RFM-Clustering
3 watermelon12138.《K-means聚类算法、Pandas绘制概率密度图和TSNE展示聚类结果》
https://blog.csdn.net/watermelon12138/article/details/86549474
4 Wilame Lima Vallantin.《Apply RFM principles to cluster customers with K-Means》
# -*- coding: utf-8 -*-
'''
描述:基于RFM及K-means聚类的客户价值度分析
时间:2019-2-19
程序开发环境:JointQuant
程序输入:sales.csv(包含用户ID,订单日期,订单金额等客户属性)
程序输出:RFM得分数据写本地文件rfm_score.csv
参考文献:
1 宋天龙. 《Python数据分析与数据化运营》
2 HarveyLau.《RFM-Clustering》 https://github.com/HarveyLau/RFM-Clustering
3 watermelon12138.《K-means聚类算法、Pandas绘制概率密度图和TSNE展示聚类结果》
https://blog.csdn.net/watermelon12138/article/details/86549474
4 Wilame Lima Vallantin.《Apply RFM principles to cluster customers with K-Means》
'''
# 导入库
import time # 导入时间库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
from scipy import stats
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
#-- 参数初始化 --#
# input,output文件指定
inputfile = 'sales.csv' # 销量及其他属性数据
outputfile = 'rfm_score.csv' # 保存结果的文件名
# 权重
W = [0.30, 0.54, 0.16]
# 原始数据参数
dtypes = {'ORDERDATE': object, 'ORDERID': object, 'AMOUNTINFO': np.float32} # 设置每列数据类型_
index_column = 'USERID'
### 数据读取
data = pd.read_csv(inputfile, dtype=dtypes, index_col=index_column) # 读取数据
# 原始数据审查和校验
# 原始数据概览
print ('Data Overview:')
print (data.head(4)) # 打印原始数据前4条
print ('-' * 60)
print ('Data before initial:')
print (data.describe()) # 打印原始数据基本描述性信息
print ('-' * 60)
#print ('Unique data:')
#print (data.nunique()) #
#print ('-' * 60)
Data Overview:
ORDERDATE ORDERID AMOUNTINFO
USERID
135197 2016/1/21 1.50701E+13 80.0
135214 2016/1/21 1.50701E+13 43.0
135238 2016/1/22 1.50701E+13 38.0
135214 2016/1/22 1.50701E+13 75.0
------------------------------------------------------------
Data before initial:
AMOUNTINFO
count 4442.000000
mean 142.146942
std 341.469452
min 0.010000
25% 5.280000
50% 51.500000
75% 116.379997
max 9188.000000
------------------------------------------------------------
### 数据初始化
# 1,缺失值处理
# 2,无效业务数据处理,比如订单金额<=1的订单
# 3,日期格式转换
#
def initial_data(raw_data):
# 缺失值审查
na_cols = raw_data.isnull().any(axis=0) # 查看每一列是否具有缺失值
print ('NA Cols:')
print (na_cols) # 查看具有缺失值的列
print ('-' * 60)
na_lines = raw_data.isnull().any(axis=1) # 查看每一行是否具有缺失值
print ('NA Recors:')
print ('Total number of NA lines is: {0}'.format(na_lines.sum())) # 查看具有缺失值的行总记录数
print (raw_data[na_lines]) # 只查看具有缺失值的行信息
print ('-' * 60)
# 缺失值处理
data = raw_data.dropna() # 丢弃带有缺失值的行记录
data = data[data['AMOUNTINFO'] > 1] # 丢弃订单金额<=1的记录
data = data[data['AMOUNTINFO'] < 9000] # 丢弃订单金额>=9000的记录
# 日期格式转换
data['ORDERDATE'] = pd.to_datetime(data['ORDERDATE'], format='%Y-%m-%d') # 将字符串转换为日期格
return data
# 原始数据初始化
data = initial_data(data)
print ('Data after initial:')
print (data.describe()) # 打印原始数据基本描述性信息
print ('-' * 60)
NA Cols:
ORDERDATE False
ORDERID False
AMOUNTINFO False
dtype: bool
------------------------------------------------------------
NA Recors:
Total number of NA lines is: 0
Empty DataFrame
Columns: [ORDERDATE, ORDERID, AMOUNTINFO]
Index: []
------------------------------------------------------------
Data after initial:
AMOUNTINFO
count 3926.000000
mean 158.404785
std 328.920837
min 1.020000
25% 11.080000
50% 66.019997
75% 134.822498
max 4048.000000
------------------------------------------------------------
print('Most recent invoice is from:')
print(data['ORDERDATE'].max())
print ('-' * 60)
Most recent invoice is from: 2018-12-05 00:00:00 ------------------------------------------------------------
# To calculate recency, we’ll look into the ‘ORDERDATE’.
# Since the date of our last invoice was 2018–12–06,
# we’ll consider it as the most recent one.
# Then, we’ll subtract each day from the day after to calculate the other ‘recencies’.
deadline_date = pd.datetime(2018, 12, 5) # 指定一个时间节点,用于计算其他时间与该时间的距离
def tran2rfm_pd(sales_data):
# 数据转换
recency_value = sales_data['ORDERDATE'].groupby(sales_data.index).max() # 计算原始最近一次订单时间
frequency_value = sales_data['ORDERDATE'].groupby(sales_data.index).count() # 计算原始订单频率
monetary_value = sales_data['AMOUNTINFO'].groupby(sales_data.index).sum() # 计算原始订单总金额
# 计算RFM得分
# 分别计算R、F、M得分
r_interval = (deadline_date - recency_value).dt.days # 计算R间隔
r_score = pd.cut(r_interval, 5, labels=[5, 4, 3, 2, 1]) # 计算R得分
f_score = pd.cut(frequency_value, 5, labels=[1, 2, 3, 4, 5]) # 计算F得分
m_score = pd.cut(monetary_value, 5, labels=[1, 2, 3, 4, 5]) # 计算M得分
# R、F、M标签数据
rfm_list = [r_score, f_score, m_score] # 将r、f、m三个维度组成列表
rfm_cols = ['R', 'F', 'M'] # 设置r、f、m三个维度列名
rfm_pd = pd.DataFrame(np.array(rfm_list).transpose(), dtype=np.int32, columns=rfm_cols,
index=frequency_value.index) # 建立r、f、m数据框
# R、F、M实际数据
rfm_pd['recency'] = r_interval
rfm_pd['frequency'] = frequency_value
rfm_pd['monetary'] = monetary_value
return rfm_pd
# RFM DataFrame做成
rfm_pd = tran2rfm_pd(data)
# 打印输出和保存结果
# 打印结果
print ('RFM Scores Overview:')
print (rfm_pd.head())
print ('-' * 60)
print ('RFM Scores Describe:')
print (rfm_pd.describe())
print ('-' * 60)
RFM Scores Overview:
R F M recency frequency monetary
USERID
135194 1 1 1 972 4 279.000000
135195 1 1 1 972 2 170.000000
135196 1 1 1 846 8 1784.760010
135197 4 1 2 383 73 24076.330078
135198 3 1 1 520 1 44.759998
------------------------------------------------------------
RFM Scores Describe:
R F M recency frequency \
count 1157.000000 1157.000000 1157.000000 1157.000000 1157.000000
mean 1.593777 1.004322 1.009507 831.893691 3.393258
std 0.850949 0.121191 0.173742 185.216052 12.753047
min 1.000000 1.000000 1.000000 0.000000 1.000000
25% 1.000000 1.000000 1.000000 751.000000 1.000000
50% 1.000000 1.000000 1.000000 892.000000 1.000000
75% 2.000000 1.000000 1.000000 950.000000 3.000000
max 5.000000 5.000000 5.000000 1045.000000 388.000000
monetary
count 1157.000000
mean 537.510864
std 3792.002197
min 1.120000
25% 11.080000
50% 38.000000
75% 175.000000
max 88395.390625
------------------------------------------------------------
# 散点图展示
rfm_pd.plot.scatter(x='recency',y='frequency',c='monetary',cmap='viridis_r', s=50)
<matplotlib.axes._subplots.AxesSubplot at 0x7f3c30096048>

# 3D图展示
fig = plt.figure(figsize=(15,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(rfm_pd['recency'], rfm_pd['frequency'], rfm_pd['monetary'], s=50)
ax.set_xlabel('Recency')
ax.set_ylabel('Frequency')
ax.set_zlabel('Monetary')
Text(0.5,0,'Monetary')

# RFM总分计算
def compute(r,f,m):
return r*W[0] + f*W[1] + m*W[2]
#------------------ 方法一:基于RFM区间标志 + 分类规则的分类 ------------------#
# 客户分类
H = [u'重要价值用户', #分类1
u'重要发展用户', #分类2
u'重要保持用户', #分类3
u'重要挽留用户', #分类4
u'一般价值用户', #分类5
u'一般发展用户', #分类6
u'一般保持用户', #分类7
u'一般挽留用户'] #分类8
def set_rfm_level(rs):
'''
r_mean = rs['R'][100:-100].mean() #剔除最高,前100 降低平均值
f_mean = rs['F'][100:-1].mean()
m_mean = rs['M'][100:-350].mean() #剔除最高,前350 降低平均值
'''
r_mean = rs['R'].mean()
f_mean = rs['F'].mean()
m_mean = rs['M'].mean()
for index in rs.index:
rs.loc[index, u'用户价值分数'] = compute(rs.loc[index]['R'],rs.loc[index]['F'],rs.loc[index]['M'])
if rs.loc[index]['R'] < r_mean:
if rs.loc[index]['F'] > f_mean:
if rs.loc[index]['M'] > m_mean:
rs.loc[index, u'用户分类'] = H[0]
rs.loc[index, u'用户分类id'] = 0
else:
rs.loc[index, u'用户分类'] = H[1]
rs.loc[index, u'用户分类id'] = 1
else:
if rs.loc[index]['M'] > m_mean:
rs.loc[index, u'用户分类'] = H[2]
rs.loc[index, u'用户分类id'] = 2
else:
rs.loc[index, u'用户分类'] = H[3]
rs.loc[index, u'用户分类id'] = 3
else:
if rs.loc[index]['F'] > f_mean:
if rs.loc[index]['M'] > m_mean:
rs.loc[index, u'用户分类'] = H[4]
rs.loc[index, u'用户分类id'] = 4
else:
rs.loc[index, u'用户分类'] = H[5]
rs.loc[index, u'用户分类id'] = 5
else:
if rs.loc[index]['M'] > m_mean:
rs.loc[index, u'用户分类'] = H[6]
rs.loc[index, u'用户分类id'] = 6
else:
rs.loc[index, u'用户分类'] = H[7]
rs.loc[index, u'用户分类id'] = 7
return rs
#
rs = set_rfm_level(rfm_pd)
print ('Fianl RFM Scores Overview:')
print(rs.head(10))
print ('-' * 60)
Fianl RFM Scores Overview:
R F M recency frequency monetary 用户价值分数 用户分类 用户分类id
USERID
135194 1 1 1 972 4 279.000000 1.00 重要挽留用户 3.0
135195 1 1 1 972 2 170.000000 1.00 重要挽留用户 3.0
135196 1 1 1 846 8 1784.760010 1.00 重要挽留用户 3.0
135197 4 1 2 383 73 24076.330078 2.06 一般保持用户 6.0
135198 3 1 1 520 1 44.759998 1.60 一般挽留用户 7.0
135199 1 1 1 889 8 815.869995 1.00 重要挽留用户 3.0
135201 2 1 1 748 2 16.830000 1.30 一般挽留用户 7.0
135207 1 1 1 1009 1 106.000000 1.00 重要挽留用户 3.0
135214 4 1 1 383 24 2380.979980 1.90 一般挽留用户 7.0
135215 1 1 1 898 7 1103.130005 1.00 重要挽留用户 3.0
------------------------------------------------------------
# 3D图表示
fig = plt.figure(figsize=(15,10))
dx = fig.add_subplot(111, projection='3d')
# 根据分类种类,定义区分颜色
colors = ['blue', 'white', 'red', 'black' , 'cyan', 'magenta' , 'yellow', 'green']
# c+: cyan + + 表示形式
# y-: yellow + - 表现形式
for i in range(0,8):
'''
dx.scatter(rs[rs[u'用户分类id'] == i].recency,
rs[rs[u'用户分类id'] == i].frequency,
rs[rs[u'用户分类id'] == i].monetary,
c = colors[i],
label = '分类 ' + str(i+1),
s=50)
'''
dx.scatter(rs[rs[u'用户分类id'] == i].recency,
rs[rs[u'用户分类id'] == i].frequency,
rs[rs[u'用户分类id'] == i].monetary,
c = colors[i],
label = H[i],
s=50)
#dx.set_title('Clusters of clients')
dx.set_xlabel('Recency')
dx.set_ylabel('Frequency')
dx.set_zlabel('Monetary')
dx.legend()
<matplotlib.legend.Legend at 0x7f3c18a4c908>

#------------------ 方法二:基于RFM实际数值 + K-means的分类 ------------------#
def winsorize(rfm_pd):
# 离散值处理
rfm_pd['recency'] = np.log10(rfm_pd['recency'])
rfm_pd['frequency'] = np.log10(rfm_pd['frequency'])
rfm_pd['monetary'] = np.log10(rfm_pd['monetary'])
return rfm_pd
# 离散值处理
rfm_pd = winsorize(rfm_pd)
rfm_pd.plot.scatter(x='recency',y='frequency',c='monetary',cmap='viridis_r', s=50)
def standardlize(rfm_pd):
# 标准化处理
rfm_pd['recency'] = stats.zscore(rfm_pd['recency'])
rfm_pd['frequency'] = stats.zscore(rfm_pd['frequency'])
rfm_pd['monetary'] = stats.zscore(rfm_pd['monetary'])
return rfm_pd
# 标准化处理
rfm_pd = standardlize(rfm_pd)
rfm_pd.plot.scatter(x='recency',y='frequency',c='monetary',cmap='viridis_r', s=50)
<matplotlib.axes._subplots.AxesSubplot at 0x7f3c189a67b8>

def get_wcss_kmeans(X_train):
wcss = []
for i in range(1,8):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=0)
kmeans.fit(X_train)
wcss.append(kmeans.inertia_)
return wcss
X = rfm_pd.iloc[:,3:] # 取RFM实际数据作为训练集
plt.plot(range(1,8), get_wcss_kmeans(X))
#plt.title('Elbow graph')
plt.xlabel('Cluster number')
plt.ylabel('WCSS')
plt.show()

# K-means聚类
# Elbow graph(wcss) shows that an optimal number of clusters would be ?.
# This is the point where line starts to do a soft descent.
k = 4
iterations = 500
rank = pd.Series([4, 3, 2, 1]) #根据k值,设定排名,从到小
# 客户分类
H = [ #分类1
u'4星会员', #分类2
u'3星会员', #分类3
u'2星会员', #分类4
u'1星会员']
def get_kmeans(X_train):
model = KMeans(n_clusters=k, n_jobs=-1, max_iter=iterations) # 分为k类
#model = KMeans(n_clusters=k) # 分为k类
model.fit(X_train) # 开始聚类
return model
#
def set_rfm_level(data,model):
rfm = pd.concat([data, pd.Series(model.labels_, index=data.index)], axis=1) # 详细输出每个样本对应的类别
rfm.columns = list(data.columns) + [u'聚类类别'] # 重命名表头
return rfm
kmeans = get_kmeans(X)
rfm_level_pd = set_rfm_level(rfm_pd,kmeans)
# 散点图表示
#rfm_level_pd.plot.scatter(x='recency',y='frequency',c=kmeans.labels_,cmap='viridis_r', s=50)
#rfm_level_pd.plot.scatter(x='recency',y='frequency',c='聚类类别',cmap='viridis_r', s=50)
# 3D图表示
fig = plt.figure(figsize=(15,10))
dx = fig.add_subplot(111, projection='3d')
# 根据分类种类,定义区分颜色
colors = ['blue', 'yellow', 'green', 'red', 'black']
for i in range(0,k):
dx.scatter(rfm_level_pd[rfm_level_pd[u'聚类类别'] == i].recency,
rfm_level_pd[rfm_level_pd[u'聚类类别'] == i].frequency,
rfm_level_pd[rfm_level_pd[u'聚类类别'] == i].monetary,
c = colors[i],
label = '类别 ' + str(i+1),
s=50)
dx.set_title('Clusters of clients')
dx.set_xlabel('Recency')
dx.set_ylabel('Frequency')
dx.set_zlabel('Monetary')
dx.legend()
<matplotlib.legend.Legend at 0x7f3c18a4c9b0>

def clear_k_means(model):
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
#r3 = pd.Series(r2[0] * W[0] + r2[1] * W[1] + r2[2] * W[2])
r3 = pd.Series(compute(r2[0],r2[1],r2[2]))
r = pd.concat([r2, r1, r3], axis=1) # axis=1 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = [u'R_质心'] + [u'F_质心'] + [u'M_质心'] + [u'类别数目'] + [u'分数'] # 重命名表头
r = r.sort_values(by=[u'分数'])
s = pd.Series(pd.DataFrame(r).index)
s1 = pd.concat([s,rank],axis=1)
s1.columns = [u'聚类类别'] + [u'排名']
# rs = pd.concat([r, r4],axis=1)
# rs.columns = [u'R_质心'] + [u'F_质心'] + [u'M_质心'] + [u'类别数目'] + [u'分数'] + [u'排名']
return r,s1
r,s = clear_k_means(kmeans)
print(r)
print ('-' * 60)
print(s)
print ('-' * 60)
R_质心 F_质心 M_质心 类别数目 分数 0 832.199291 2.552702 184.271284 1129 280.521652 3 857.421053 18.000000 6461.531995 19 1300.791435 2 776.285714 28.714286 18267.926897 7 3171.259732 1 611.500000 250.500000 81605.355469 2 13375.576875 ------------------------------------------------------------ 聚类类别 排名 0 0 4 1 3 3 2 2 2 3 1 1 ------------------------------------------------------------
# 设置排名
def init_clear_data(rs,s):
rs['USERID'] = rs.index
# 按照rs,s相同名字的列合并
rs = pd.merge(rs,s,how='left')
rs.sort_values(by='R')
rs.index = rs['USERID']
del rs['USERID']
return rs
#rs = init_clear_data(data=rfm_level_pd,model=kmeans,s=s)
rs2 = init_clear_data(rs=rfm_level_pd,s=s)
print(rs2.head(10))
print ('-' * 60)
R F M recency frequency monetary 聚类类别 排名 USERID 135194 1 1 1 972 4 279.000000 0 4 135195 1 1 1 972 2 170.000000 0 4 135196 1 1 1 846 8 1784.760010 0 4 135197 4 1 2 383 73 24076.330078 2 2 135198 3 1 1 520 1 44.759998 0 4 135199 1 1 1 889 8 815.869995 0 4 135201 2 1 1 748 2 16.830000 0 4 135207 1 1 1 1009 1 106.000000 0 4 135214 4 1 1 383 24 2380.979980 0 4 135215 1 1 1 898 7 1103.130005 0 4 ------------------------------------------------------------
# 3D图表示
fig = plt.figure(figsize=(15,10))
dx = fig.add_subplot(111, projection='3d')
# 根据分类种类,定义区分颜色
colors = ['blue', 'yellow', 'green', 'red']
for i in range(0,k):
dx.scatter(rfm_pd[rs2[u'排名'] == i+1].recency,
rfm_pd[rs2[u'排名'] == i+1].frequency,
rfm_pd[rs2[u'排名'] == i+1].monetary,
c = colors[i],
label = H[i],
s=50)
#dx.set_title('Clusters of clients')
dx.set_xlabel('Recency')
dx.set_ylabel('Frequency')
dx.set_zlabel('Monetary')
dx.legend()
<matplotlib.legend.Legend at 0x7f3c2836e1d0>

def density_plot(data):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# subplots=True表示dataframe格式的数据中每一列绘制一幅子图
p = data.plot(kind='kde', linewidth=2, subplots=True, sharex=False)
# p[1]代表第1个子图
[p[i].set_ylabel(u'密度') for i in range(3)]
plt.legend()
return plt
# 取RFM实际数据
X2 = rfm_pd.iloc[:,3:]
pic_output = 'pd_' #概率密度图文件名前缀
for i in range(k):
# rs[u'聚类类别'] == i返回的是index+boolen(注意:rs的index事先不能丢失)
# X2[]返回的是只有true的行
#density_plot(X2[rs[u'聚类类别'] == i]).show()
density_plot(X2[rs2[u'排名']==i+1]).savefig(u'%s%s.png' %(pic_output, i))




#write_csv(rs_=rs)

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程