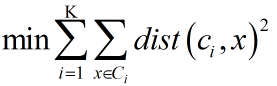这篇帖子是参考【申万宏源-风格切换下的PB-ROE选股研究】的研报内容,按照研报的思路在研究里面进行模型搭建,具体如下:
PB-ROE选股策略
静态PB-ROE组合表现
基于聚类的风格切换识别
PB-ROE聚类选股组合
结合市值的聚类选股组合
根据报告思路,我们先进行了低市净率、高ROE的股票收益组合搭建
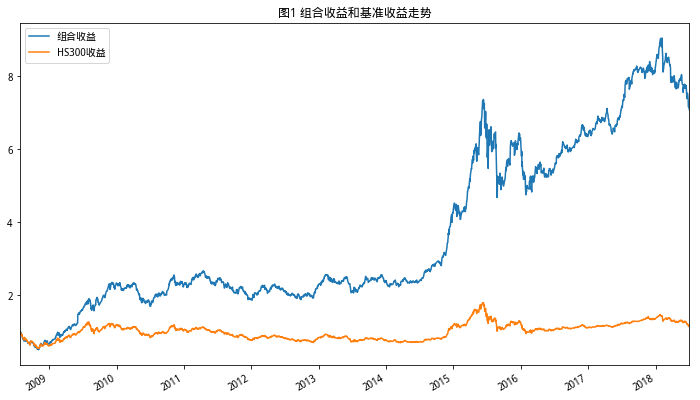
十年回测,组合测试时间从2008年7月到2018年7月
选取市场中高ROE,低PB的前50只股票
每月进行组合调整
我们直接上图,先看效果
可以看到,单是基于PB、ROE两个因子的综合打分策略,已经就有了不错的表现,下面就来看下PB、ROE这两个指标的内容
PB,是市净率,在PB-ROE选股模型中,PB,即市净率,是典型的价值指标,能够简单有效地衡量估值水平高低;但是股票低估值的原因可能是较差的经营业绩,或其他制约因素,因此单纯的低PB并不能直接成为投资理由。
引入ROE可以弥补PB单一指标的不足
ROE,即净资产收益率,反映企业自有资本的盈利能力。ROE是一个成长指标,部分成长风格指数,也将ROE作为成长选股指标之一。通过将PB与ROE相结合,便可以衡量相对于盈利能力,股票是否具有投资价值。
直观意义上,PB-ROE策略的核心思想,是寻找当前估值较低,同时具有稳定成长特性的股票,即低PB和高ROE的股票。
选择出不同PB、不同ROE股票,在历史行情中进行组合测试,观察其市场表现
这里选择了前30%市值的股票进行组合构建,研报中并没有说明这么做的原因,从第一部分内容我们看到,实际上包含了中小市值股票后收益会更高,初步推测1.为了降低小市值因子暴露2.大市值股票更能反映市场风格3.因为基准是HS300
选取总市值前30%的股票
选股空间为将PB升序,ROE降序,选择综合排名前100只股票
选取总市值前30%的股票
选股空间为将PB降序,ROE降序,选择综合排名前100只股票
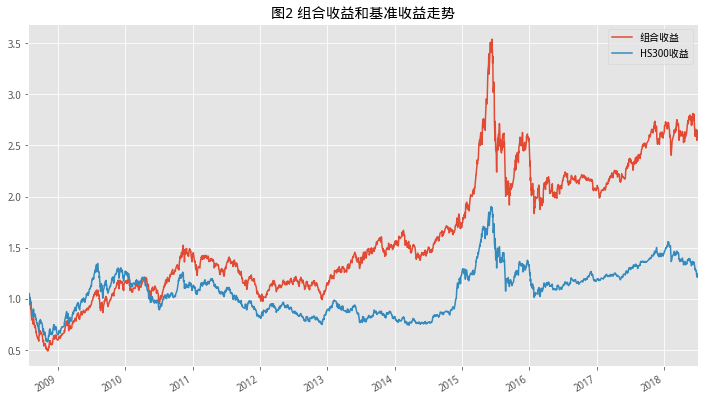
我们看到,主要的利润贡献都在2016年到2018年之间,股灾的时候都在回撤,今年上半年在高PB和底PB之前有不同的表现。
直观理解,都是PB越低,股票越是被市场低估,ROE越高,股票的成长性越好,然而市场是具有多个维度的,如果考虑到行业属性在内,这么操作可能会将组合集中在某些特定行业,比如钢铁、银行都有较高的PB,导致较高的风险暴露,基于此,就可以进行一个设想,可以通过固定的时点去检查市场周期内的表现,寻找出组合收益最好的PB、ROE值,即构建市场风格切换下的动态组合,与市场风格契合。
应用K-Mean聚类分组,动态识别市场风格,进行切换跟随
聚类是一种无监督的学习,将相似的对象归到同一个簇中。聚类与分类的最大不同在于分类的目标事先已知,而聚类则不知道,没有训练过程,可以直接将数据进行聚类分组。
下面我们拿近期的数据做一次聚类分组的演示
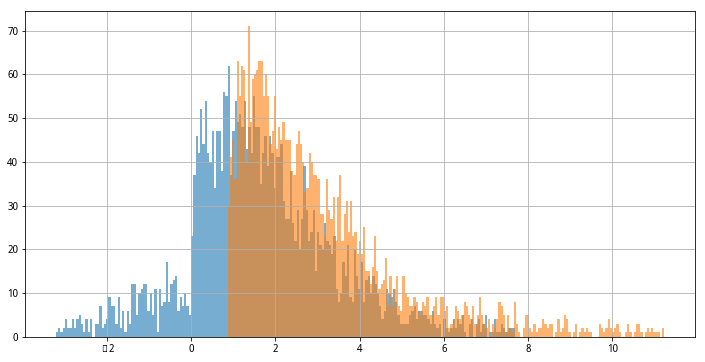
首先,获取所需数据,取全市场股票的PB、ROE数据,为了避免极端值对分组的影响,做了去极值处理,处理后全市场PB、ROE分布情况如下
K-Means算法的思路,就是让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
实现过程如下:
选取k个质心
将任意一个点分配到离质心最近的簇。
用每个簇的均值作为质心。
重复2和3直到所有点的分配结果不再发生变化,或者误差小于给定误差。
kmenas算法选择K个初始质心,代表所期望的簇的个数,即我们希望给市场划分的风格种类。研报中将股票的PB-ROE数据分布,在以PB、ROE为轴的坐标系中展示,习惯性的将因子按高低大小进行了划分,即在模型中让k=4,但如何有效的确定K值,是需要探讨的内容。kmean算法中关于距离的计算方法就有好几类,这里采用欧式距离,目标函数为最小化对象到其簇质心的距离的平方和,如下:
接下来我们将之前准备的数据进行K-Mean算法分组,以下是分组结果
后面要做的事情,就是按此方法进行区域划分,收益监控,动态切换风格
市场对PB、ROE的偏好变化
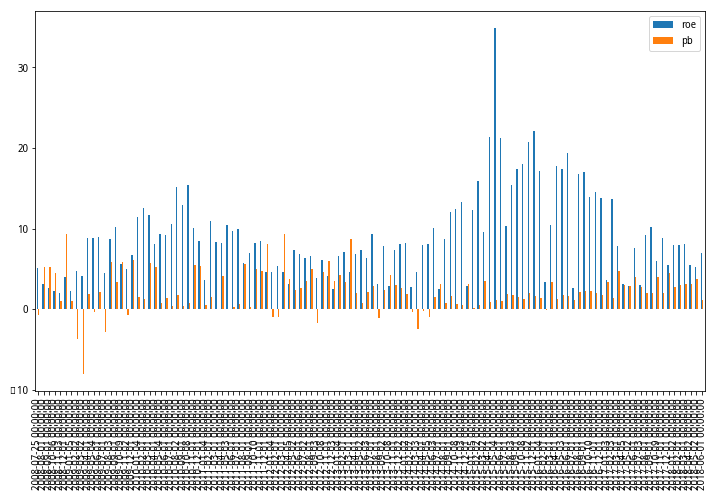
下图将10年的行情数据,通过每月固定时间检查本周期内,组合收益最好的PB、ROE值,可以看到,他们是不断变化的。
通过PB、ROE两个指标聚类的基础之上,识别当前最优市场风格,作为下期选股风格基准
总市值前30%组合,收益大盘市值加权(A组)
全市场股票组合,收益等权重(B组)
PE(PB/ROE)小于100,ROE>=8%限制(不限制C组,限制D组)
设置不同组合更新频率,月度、季度、半年度(月、季、年分别为E、F、G组)
按照上述分类,这里更新频率取E、F两类,总共可以构建8种组合
下面是个组合的表现
分组D保留了研报的限制条件,导致过程中有未选出股票的时段,均按空仓进行了处理,从结果看,这里的这个条件限制达反而是表现出了较好的择时效果,后面可以尝试作为策略的择时指标
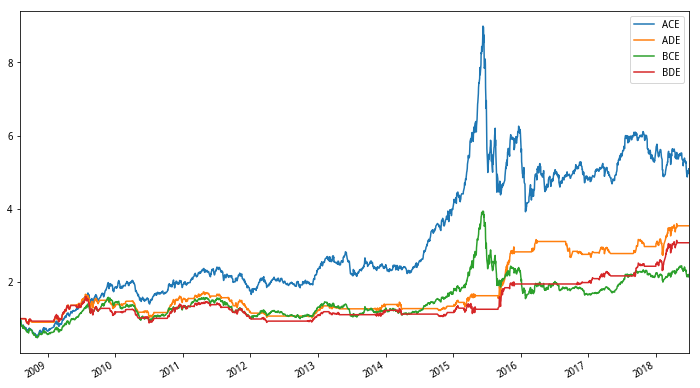
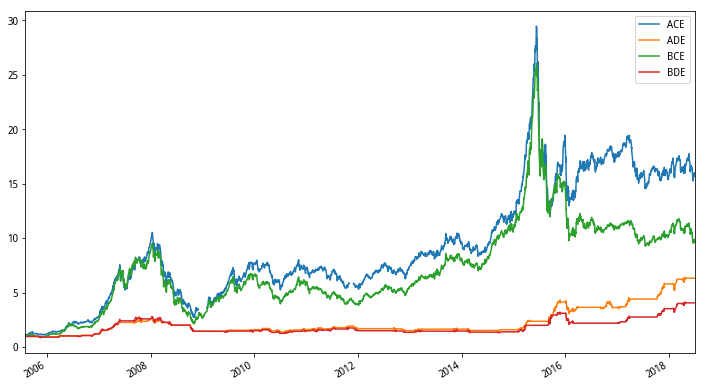
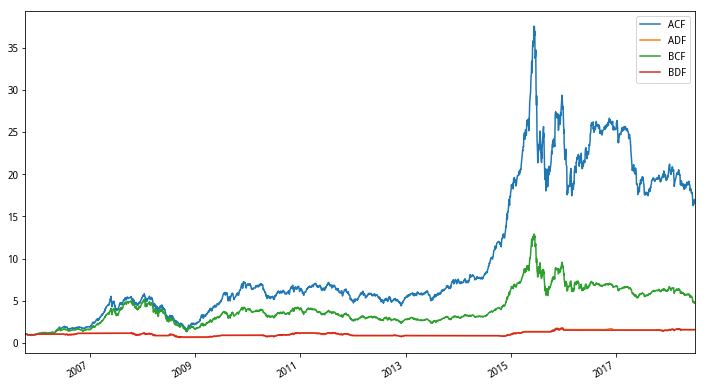
综合看起来ACF是表现最好的组合,这两张图,对比其效果时需要控制变量进行比较,比如,我们想知道AB分组的不同表现,就可以比较如ACE和BCE、ADE和BDE、ADF和BDF,即保持其他两个条件不变,根据这个思路,我们发现
前30%市值表现更好
条件限制下回撤更小
季度频率调仓让C系列收益更高,月度调仓让D系列收益更高
市值风格是一直是股票走势最重要的影响因素之一,这里将其纳入选股分组的判别因子
将市值加入分类标签中(取原始数据时加入市值)
将分类组合分为6类(K-Mean距离分组k=6)
组合的收益表现
下面是个组合的表现
具体的分析方法如第四部分说描述
这部分内容想必会有争议,因为已经纳入了市值因子进行分类划分,这里的组合收益却保留了AB的分类,因为代码中B类分组是全市场,且本人较懒就没有再去掉这个分组,对比效果时注意下这一点就好。
正如报告中所言,PB、ROE可以作为价值、成长的代表性指标,但2个选股因子蕴含的信息有限,且受市场风格不断切换的影响,在应用K-Mean聚类分组方法,在进行风格切换处理后,组合获得了更优异的表现。
有了本篇的内容,类似的,我们可以应用此方法,可以加入更多的指标因子,可以做指数或行业内的分组,可以做分组的分组,进行策略开发。
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt#plt.style.use('ggplot')PB-ROE选股策略
静态PB-ROE组合表现
基于聚类的风格切换识别
PB-ROE聚类选股组合
结合市值的聚类选股组合
用于计算交易日列表函数
用于计算组合收益函数
组合收益取市值加权
组合收益平均权重
#工具函数#获取日期列表def get_tradeday_list(s='2017-1-1',e='2018-7-25',label='month',count=None):if count != None:df = get_price('000001.XSHG',end_date=e,count=count)else:df = get_price('000001.XSHG',start_date=s,end_date=e)if label==None:return df.indexelse:df['year-month'] = [str(i)[0:7] for i in df.index]if label == 'month':return df.drop_duplicates('year-month').indexelif label == 'quarter':df['month'] = [str(i)[5:7] for i in df.index]df = df[(df['month']=='01') | (df['month']=='04') | (df['month']=='07') | (df['month']=='10') ]return df.drop_duplicates('year-month').indexelif label =='halfyear':df['month'] = [str(i)[5:7] for i in df.index]df = df[(df['month']=='01') | (df['month']=='06')]return df.drop_duplicates('year-month').index
#获取股票池的组合收益(市值加权的方式)def ret_se(sl,start_date='2018-6-1',end_date='2018-7-1'):if len(sl) !=0:#得到股票的历史价格数据df = get_price(list(sl),start_date=start_date,end_date=end_date,fields=['close']).closedf = df.dropna(axis=1)#获取列表中的股票流通市值对数值df_mkt = get_fundamentals(query(valuation.code,valuation.circulating_market_cap).filter(valuation.code.in_(df.columns)))df_mkt.index = df_mkt['code'].valuesfact_se =pd.Series(df_mkt['circulating_market_cap'].values,index = df_mkt['code'].values)fact_se = np.log(fact_se)else:df = get_price('000001.XSHG',start_date=start_date,end_date=end_date,fields=['close'])df['v'] = [1]*len(df)del df['close']pct = df.pct_change()+1pct.iloc[0,:] = 1return pct.cumsum(axis=1).iloc[:,-1]/pct.shape[1]#相当于昨天的百分比变化pct = df.pct_change()+1pct.iloc[0,:] = 1#df1 = pct.cumprod()#等权重平均收益结果#按权重的方式计算se = (pct*fact_se).cumsum(axis=1).iloc[:,-1]/sum(fact_se)return se#获取股票池的组合收益(不进行市值加权)def ret_se1(sl,start_date='2018-6-1',end_date='2018-7-1'):if len(sl) != 0:#得到股票的历史价格数据df = get_price(list(sl),start_date=start_date,end_date=end_date,fields=['close']).closedf = df.dropna(axis=1)#获取列表中的股票流通市值对数值df_mkt = get_fundamentals(query(valuation.code,valuation.circulating_market_cap).filter(valuation.code.in_(df.columns)))df_mkt.index = df_mkt['code'].valuesfact_se =pd.Series(df_mkt['circulating_market_cap'].values,index = df_mkt['code'].values)fact_se = np.log(fact_se)else:df = get_price('000001.XSHG',start_date=start_date,end_date=end_date,fields=['close'])df['v'] = [1]*len(df)del df['close']#相当于昨天的百分比变化pct = df.pct_change()+1pct.iloc[0,:] = 1#df1 = pct.cumprod()#等权重平均收益结果#按权重的方式计算se1 = pct.cumsum(axis=1).iloc[:,-1]/pct.shape[1]return se1def f_sum(x):return sum(x)根据报告思路,我们先进行了低市净率、高ROE的股票收益统计
获取选股策略的时间列表
每月进行调仓
选取每月市场中高ROE,低PB的前50只股票
#设置回测时间start,end = '2008-7-27','2018-7-27'#获取交易日列表trade_list = get_tradeday_list(start,end,'month')num = 1for s,e in zip(trade_list[:-1],trade_list[1:]): #获取满足条件的股票列表df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap),date = s)#df = df[df['circulating_market_cap']>df['circulating_market_cap'].quantile(0.7)]df = df[(df['roe']>0) & (df['pb_ratio']>0)].sort_values('pb_ratio')df.index = df['code'].valuesdf['1/roe'] = 1/df['roe']#获取排序综合得分df['point'] = df[['pb_ratio','1/roe']].rank().T.apply(f_sum)df = df.sort_values('point')[:100]pool = df.index''' #0为从大到小 df1 = df.sort_values('roe',ascending=0)[:500] pool = [] for i in df.index[:500]: if i in df1.index: pool.append(i) '''if num == 0:df_returns1 = ret_se(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:df_returns = ret_se(pool,s,e)num = 0#获取基准收益 df_hs300 = get_price('000300.XSHG',start_date=trade_list[0],end_date=trade_list[-1],fields=['pre_close','close'])df_hs300['retunrs'] = df_hs300['close']/df_hs300['pre_close']df_returns.cumprod().plot(figsize=(12,7),legend=True,label='组合收益',title='图1 组合收益和基准收益走势')df_hs300['retunrs'].cumprod().plot(figsize=(12,7),legend=True,label='HS300收益')
<matplotlib.axes._subplots.AxesSubplot at 0x7f6ffaaed7f0>
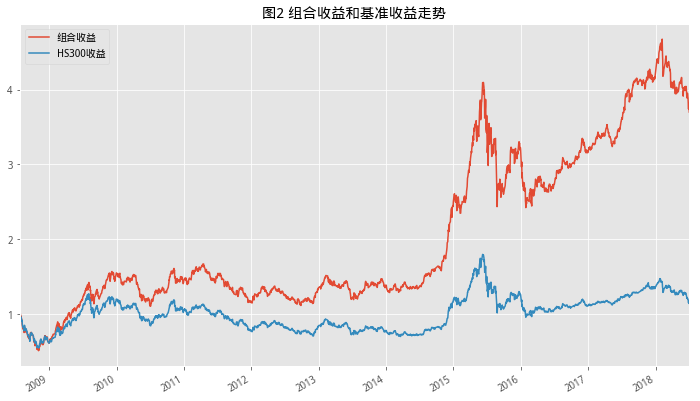
我们首先对静态低PB、高ROE股票组合测试,观察其市场表现
静态组合构建
选取总市值前30%的股票
选股空间为将PB升序,ROE降序,选择综合排名前100只股票
风格切换说明
下面是低PB,高ROE
#设置回测时间start,end = '2008-7-25','2018-7-25'#获取交易日列表trade_list = get_tradeday_list(start,end,'month')num = 1for s,e in zip(trade_list[:-1],trade_list[1:]): #获取满足条件的股票列表df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap),date = s)df = df[(df['roe']>0) & (df['pb_ratio']>0)].sort_values('pb_ratio')df = df[df['circulating_market_cap']>df['circulating_market_cap'].quantile(0.7)]df.index = df['code'].valuesdf['1/roe'] = 1/df['roe']#获取排序综合得分df['point'] = df[['pb_ratio','1/roe']].rank().T.apply(f_sum)df = df.sort_values('point')[:100]pool = df.indexif num == 0:df_returns1 = ret_se(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:df_returns = ret_se(pool,s,e)num = 0#获取基准收益 df_hs300 = get_price('000300.XSHG',start_date=trade_list[0],end_date=trade_list[-1],fields=['pre_close','close'])df_hs300['retunrs'] = df_hs300['close']/df_hs300['pre_close']#进行图表展示df_returns.cumprod().plot(figsize=(12,7),legend=True,label='组合收益',title='图2 组合收益和基准收益走势')df_hs300['retunrs'].cumprod().plot(figsize=(12,7),legend=True,label='HS300收益')<matplotlib.axes._subplots.AxesSubplot at 0x7f74b3015f98>
下面是选择高PB,高ROE的收组合
#设置回测时间start,end = '2008-7-20','2018-7-20'#获取交易日列表trade_list = get_tradeday_list(start,end,'month')num = 1def f_sum(x):return sum(x)for s,e in zip(trade_list[:-1],trade_list[1:]): #获取满足条件的股票列表df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap),date = s)df = df[(df['roe']>0) & (df['pb_ratio']>0)].sort_values('pb_ratio')df = df[df['circulating_market_cap']>df['circulating_market_cap'].quantile(0.7)]df.index = df['code'].valuesdf['1/roe'] = 1/df['roe']df['1/pb_ratio'] = 1/df['pb_ratio']#获取排序综合得分df['point'] = df[['1/pb_ratio','1/roe']].rank().T.apply(f_sum)df = df.sort_values('point')[:100]pool = df.indexif num == 0:df_returns1 = ret_se(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:df_returns = ret_se(pool,s,e)num = 0#获取基准收益 df_hs300 = get_price('000300.XSHG',start_date=trade_list[0],end_date=trade_list[-1],fields=['pre_close','close'])df_hs300['retunrs'] = df_hs300['close']/df_hs300['pre_close']#进行图表展示df_returns.cumprod().plot(figsize=(12,7),legend=True,label='组合收益',title='图2 组合收益和基准收益走势')df_hs300['retunrs'].cumprod().plot(figsize=(12,7),legend=True,label='HS300收益')<matplotlib.axes._subplots.AxesSubplot at 0x7f74b3ab5a90>
#设置回测时间start,end = '2008-7-25','2018-7-25'#获取交易日列表trade_list = get_tradeday_list(start,end,'month')num = 1for s,e in zip(trade_list[:-1],trade_list[1:]): #获取满足条件的股票列表df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap),date = s)df = df[(df['roe']>0) & (df['pb_ratio']>0)].sort_values('pb_ratio')df = df[df['circulating_market_cap']>df['circulating_market_cap'].quantile(0.7)]df.index = df['code'].valuesdf['1/roe'] = 1/df['roe']#获取排序综合得分df['point'] = df[['pb_ratio','roe']].rank().T.apply(f_sum)df = df.sort_values('point')[:100]pool = df.indexif num == 0:df_returns1 = ret_se(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:df_returns = ret_se(pool,s,e)num = 0#获取基准收益 df_hs300 = get_price('000300.XSHG',start_date=trade_list[0],end_date=trade_list[-1],fields=['pre_close','close'])df_hs300['retunrs'] = df_hs300['close']/df_hs300['pre_close']#进行图表展示df_returns.cumprod().plot(figsize=(12,7),legend=True,label='组合收益',title='图2 组合收益和基准收益走势')df_hs300['retunrs'].cumprod().plot(figsize=(12,7),legend=True,label='HS300收益')应用聚类分组,动态识别市场风格,进行切换跟随
对PB-ROE体系的直观描述
PB-ROE体系图示
动态识别风格偏好
K均值聚类方法介绍
市场对PB、ROE的偏好变化
#K均值聚类方法演示#聚类部分代码from numpy import *#这部分代码为K-mean聚类的基础代码def loadDataSet(fileName):dataSet = []f = open(fileName)for line in f.readlines():curLine = line.strip().split('\t')fltLine = map(float, curLine)dataSet.append(fltLine)return mat(dataSet)def distEclud(vecA, vecB):return sqrt(sum(power(vecA - vecB, 2)))def randCent(dataSet, k):n = shape(dataSet)[1] #n是列数centroids = mat(zeros((k, n)))for j in range(n):minJ = min(dataSet[:, j]) #找到第j列最小值rangeJ = float(max(dataSet[:, j]) - minJ) #求第j列最大值与最小值的差centroids[:, j] = minJ + rangeJ * random.rand(k, 1) #生成k行1列的在(0, 1)之间的随机数矩阵return centroids#k-mean聚类的逻辑代码def KMeans(dataSet, k, distMeas=distEclud, createCent=randCent):m = shape(dataSet)[0] #数据集的行clusterAssment = mat(zeros((m, 2)))centroids = createCent(dataSet, k)clusterChanged = Truewhile clusterChanged:clusterChanged = Falsefor i in range(m): #遍历数据集中的每一行数据minDist = inf;minIndex = -1for j in range(k): #寻找最近质心distJI = distMeas(centroids[j, :], dataSet[i, :])if distJI < minDist: #更新最小距离和质心下标minDist = distJI; minIndex = jif clusterAssment[i, 0] != minIndex:clusterChanged = TrueclusterAssment[i, :] = minIndex, minDist**2 #记录最小距离质心下标,最小距离的平方#print(centroids)for cent in range(k): #更新质心位置ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #获得距离同一个质心最近的所有点的下标,即同一簇的坐标centroids[cent,:] = mean(ptsInClust, axis=0) #求同一簇的坐标平均值,axis=0表示按列求均值return centroids, clusterAssment#k-mean聚类代码改进版#二分K均值聚类算法def biKmeans(dataSet, k, distMeas=distEclud):m = shape(dataSet)[0]clusterAssment = mat(zeros((m,2)))centroid0 = mean(dataSet, axis=0).tolist()[0] #求所有数据的平均值,创建一个初始簇质心centList =[centroid0]for j in range(m): #计算初始误差平方和clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2while (len(centList) < k): #只要聚类的个数小于等于klowestSSE = inffor i in range(len(centList)):ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #获得属于cent簇的数据centroidMat, splitClustAss = KMeans(ptsInCurrCluster, 2, distMeas) #对一个簇中的数据进行kMeanssseSplit = sum(splitClustAss[:,1]) #计算本次划分误差平方和sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #计算不属于cent簇的误差平方和#print ("sseSplit, and notSplit: ",sseSplit,sseNotSplit)if (sseSplit + sseNotSplit) < lowestSSE: #如果有效降低了误差平方和,则记录bestCentToSplit = ibestNewCents = centroidMatbestClustAss = splitClustAss.copy()lowestSSE = sseSplit + sseNotSplitbestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #将划分簇的编号转为新加簇的编号bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #更新原始的该簇质心编号#print ('the bestCentToSplit is: ',bestCentToSplit)#print ('the len of bestClustAss is: ', len(bestClustAss))centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#将一个质心更新为两个质心centList.append(bestNewCents[1,:].tolist()[0])clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss #更新数据的编号以及误差平方和return mat(centList), clusterAssment#将数据可视化import matplotlib.pyplot as pltdef showCluster(dataSet, k, clusterAssment, centroids):fig = plt.figure(figsize=(10,7))plt.title("K-means")ax = fig.add_subplot(111)data = []for cent in range(k): #提取出每个簇的数据ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #获得属于cent簇的数据data.append(ptsInClust)for cent, c, marker in zip( range(k), ['r', 'g', 'b', 'y'], ['^', 'o', '*', 's'] ): #画出数据点散点图ax.scatter((data[cent][:, 0]).tolist(),(data[cent][:, 1]).tolist(), s=80, c=c, marker=marker)ax.scatter(centroids[:, 0].tolist(), centroids[:, 1].tolist(), s=1000, c='black', marker='+', alpha=1) #画出质心点ax.set_xlabel('X Label')ax.set_ylabel('Y Label')plt.show()#算法演示
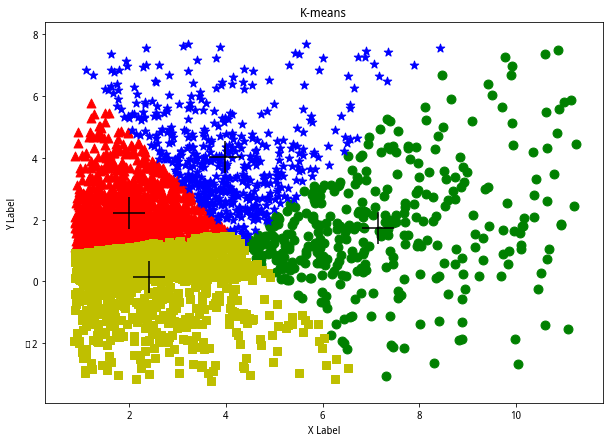
#未去极端值df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe))d_matrix = np.mat(df[['pb_ratio','roe']])k1,k2 = KMeans(d_matrix,4)showCluster(d_matrix,4,k2,k1)
#分位数方法去掉极端值min_roe,max_roe = df['roe'].quantile([0.025, 0.975])min_pb,max_pb = df['pb_ratio'].quantile([0.025, 0.975])#获取pb,roe数据df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe))df2 = df[(df['roe']>min_roe) & (df['roe']<max_roe) & (df['pb_ratio']>min_pb) & (df['pb_ratio']<max_pb)]#橘黄色的为PB分布,蓝色的为roe分布df2['roe'].hist(bins=200,figsize=(12,6),alpha=0.6)df2['pb_ratio'].hist(bins=200,figsize=(12,6),alpha=0.6)
<matplotlib.axes._subplots.AxesSubplot at 0x7f70b6728f98>
d_matrix = np.mat(df2[['pb_ratio','roe']])k1,k2 = KMeans(d_matrix,4)showCluster(d_matrix,4,k2,k1)
k1,k2 = biKmeans(d_matrix,4)showCluster(d_matrix,4,k2,k1)
可以根据初始值获取不同的收益序列
K值为4,设定的聚类个数为4个
K值为6,设定的聚类个数为6个
#得到聚类分组后股票列表4组#获取pb,roe数据def get_stock_pool(date):df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap,valuation.pe_ratio),date=date)min_roe,max_roe = df['roe'].quantile([0.025, 0.975])min_pb,max_pb = df['pb_ratio'].quantile([0.025, 0.975])df = df[(df['roe']>min_roe) & (df['roe']<max_roe) & (df['pb_ratio']>min_pb) & (df['pb_ratio']<max_pb)]d_matrix = np.mat(df[['pb_ratio','roe']])k1,k2 = biKmeans(d_matrix,4)#showCluster(d_matrix,4,k2,k1)label = [i[0] for i in k2.tolist()]dist = [i[1] for i in k2.tolist()]df['label'] = labeldf['1/roe'] = 1/df['roe']#获取排序综合得分df['point'] = df[['pb_ratio','1/roe']].rank().T.apply(f_sum)df['dist'] = distl1 = df[df['label'] == 0]['code'].valuesl2 = df[df['label'] == 1]['code'].valuesl3 = df[df['label'] == 2]['code'].valuesl4 = df[df['label'] == 3]['code'].valuesreturn l1,l2,l3,l4,k1,k2,df#得到聚类分组后股票列表6组#获取pb,roe,市值数据def get_stock_pool_6(date):df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe,valuation.circulating_market_cap,valuation.pe_ratio),date=date)min_roe,max_roe = df['roe'].quantile([0.025, 0.975])min_pb,max_pb = df['pb_ratio'].quantile([0.025, 0.975])df['mkt'] = np.log(df['circulating_market_cap'])df = df[(df['roe']>min_roe) & (df['roe']<max_roe) & (df['pb_ratio']>min_pb) & (df['pb_ratio']<max_pb)]d_matrix = np.mat(df[['pb_ratio','roe','mkt']])k1,k2 = biKmeans(d_matrix,6)#showCluster(d_matrix,4,k2,k1)label = [i[0] for i in k2.tolist()]dist = [i[1] for i in k2.tolist()]df['1/roe'] = 1/df['roe']#获取排序综合得分df['point'] = df[['pb_ratio','1/roe']].rank().T.apply(f_sum)df['dist'] = distdf['label'] = labell1 = df[df['label'] == 0]['code'].valuesl2 = df[df['label'] == 1]['code'].valuesl3 = df[df['label'] == 2]['code'].valuesl4 = df[df['label'] == 3]['code'].valuesl5 = df[df['label'] == 4]['code'].valuesl6 = df[df['label'] == 5]['code'].valuesreturn l1,l2,l3,l4,l5,l6,k1,k2,df
记录每期组合收益最高的值标签
将最优组合值构建成df
#记录时间段内收益最好的pb,roe的值pb_roe_list = []label_list = []label_dict = {}dist_dict = {}df_all_values = {}#获取交易列表,按月trade_list = get_tradeday_list('2008-7-25','2018-7-25',label='month')note_year = str(trade_list[0])[:4]for s,e in zip(trade_list[:-1],trade_list[1:]):date = eif str(date)[:4] == note_year:print('正在计算%s年数据......'%str(date)[:4])note_year = str(int(note_year)+1)#获取数据,得出分组l1,l2,l3,l4,k1,k2,df = get_stock_pool(date)#获取分组收益se1 = ret_se(l1,s,e)se2 = ret_se(l2,s,e)se3 = ret_se(l3,s,e)se4 = ret_se(l4,s,e)df_all = pd.concat([se1,se2,se3,se4],axis=1)df_all.columns = [0,1,2,3]#获取收益最高组的标签label_1 = (df_all.cumprod()).iloc[-1].sort_values().index[-1]label_list.append(label_1)df_all_values[date] = dfpb_roe_list.append(k1[label_1].tolist())print('计算完毕')正在计算2008年数据...... 正在计算2009年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2010年数据...... 正在计算2011年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2012年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2013年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2014年数据...... 正在计算2015年数据...... 正在计算2016年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2017年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2018年数据...... 计算完毕
#构建每期的最优标签、值的dfroe = [i[0][0] for i in pb_roe_list]pb = [i[0][1] for i in pb_roe_list]df_cent = pd.DataFrame(roe,index=trade_list[:-1],columns=['roe'])df_cent['pb'] = pbdf_cent['label'] = label_listdf_cent[['roe','pb']].plot(kind='bar',figsize=(12,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f70b46ac978>
通过PB、ROE两个指标聚类的基础之上,识别当前最优市场风格,作为下期选股风格基准
总市值前30%组合,收益大盘市值加权(A组)
总市值后50%组合,收益等权重(B组)
PE(PB/ROE)小于100,ROE>=8%限制(不限制C组,限制D组)
设置不同组合更新频率,月度、季度、半年度(月、季、年分别为E、F、G组)
按照上述分类,这里更新频率取E、F两类,总共可以构建8种组合
根据日期确定聚类标签
从df_all_values中找到标签对应的股票,按距离远近选出组合
进行收益统计
以下为按月频率更新
#记录时间段内收益最好的pb,roe的值pb_roe_list = []label_list = []label_dict = {}dist_dict = {}df_all_values = {}#获取交易列表,按月trade_list = get_tradeday_list('2008-7-25','2018-7-25',label='month')note_year = str(trade_list[0])[:4]for s,e in zip(trade_list[:-1],trade_list[1:]):date = eif str(date)[:4] == note_year:print('正在计算%s年数据......'%str(date)[:4])note_year = str(int(note_year)+1)#获取数据,得出分组l1,l2,l3,l4,k1,k2,df = get_stock_pool(date)#获取分组收益se1 = ret_se(l1,s,e)se2 = ret_se(l2,s,e)se3 = ret_se(l3,s,e)se4 = ret_se(l4,s,e)df_all = pd.concat([se1,se2,se3,se4],axis=1)df_all.columns = [0,1,2,3]#获取收益最高组的标签label_1 = (df_all.cumprod()).iloc[-1].sort_values().index[-1]label_list.append(label_1)df_all_values[date] = dfpb_roe_list.append(k1[label_1].tolist()) #构建每期的最优标签、值的dfroe = [i[0][0] for i in pb_roe_list]pb = [i[0][1] for i in pb_roe_list]df_cent = pd.DataFrame(roe,index=trade_list[:-1],columns=['roe'])df_cent['pb'] = pbdf_cent['label'] = label_listprint('计算完毕')正在计算2008年数据...... 正在计算2009年数据...... 正在计算2010年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2011年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2012年数据...... 正在计算2013年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2014年数据...... 正在计算2015年数据...... 正在计算2016年数据...... 正在计算2017年数据...... 正在计算2018年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
计算完毕
df_returns_m_dict = {}for i in ['ACE','ADE','BCE','BDE']:stock_num = 20num = 1trade_list_e = trade_list[1:]print('正在计算%s分组收益......'%i)for s,e in zip(trade_list_e[:-1],trade_list_e[1:]):#获取到聚类最优的标签label = df_cent.loc[s,'label']df_values = df_all_values[s]#市值筛选条件if i[0] == 'B':df_values = df_values[(df_values['label']==label) & (df_values['circulating_market_cap']>df_values['circulating_market_cap'].quantile(0.7))].sort_values('point')else:df_values = df_values[df_values['label']==label].sort_values('point')#pe,roe筛选条件if i[1] == 'C':pool = df_values[:stock_num]['code'].valueselse:pool = df_values[(df_values['pe_ratio']<100) & (df_values['roe']>8)].sort_values('point')[:stock_num]['code'].values
if num == 0:if i[0] == 'A':df_returns1 = ret_se(pool,s,e) else:df_returns1 = ret_se1(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:if i[0] == 'A':df_returns = ret_se(pool,s,e)else:df_returns = ret_se1(pool,s,e)num = 0df_returns_m_dict[i] = df_returnsprint('月度收益计算完毕')正在计算ACE分组收益...... 正在计算ADE分组收益...... 正在计算BCE分组收益...... 正在计算BDE分组收益...... 月度收益计算完毕
构建组合收益df
df_returns_all_m = pd.DataFrame(df_returns_m_dict)df_returns_all_m.cumprod().plot(figsize=(12,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f6ff9b87b38>
以下为按季度频率更新
#记录时间段内收益最好的pb,roe的值pb_roe_list = []label_list = []label_dict = {}dist_dict = {}df_all_values = {}#获取交易列表,按月trade_list = get_tradeday_list('2005-7-25','2018-7-25',label='quarter')note_year = str(trade_list[0])[:4]for s,e in zip(trade_list[:-1],trade_list[1:]):date = eif str(date)[:4] == note_year:print('正在计算%s年数据......'%str(date)[:4])note_year = str(int(note_year)+1)#获取数据,得出分组l1,l2,l3,l4,k1,k2,df = get_stock_pool(date)#获取分组收益se1 = ret_se(l1,s,e)se2 = ret_se(l2,s,e)se3 = ret_se(l3,s,e)se4 = ret_se(l4,s,e)df_all = pd.concat([se1,se2,se3,se4],axis=1)df_all.columns = [0,1,2,3]#获取收益最高组的标签label_1 = (df_all.cumprod()).iloc[-1].sort_values().index[-1]label_list.append(label_1)df_all_values[date] = dfpb_roe_list.append(k1[label_1].tolist()) #构建每期的最优标签、值的dfroe = [i[0][0] for i in pb_roe_list]pb = [i[0][1] for i in pb_roe_list]df_cent = pd.DataFrame(roe,index=trade_list[:-1],columns=['roe'])df_cent['pb'] = pbdf_cent['label'] = label_listprint('计算完毕')正在计算2005年数据...... 正在计算2006年数据...... 正在计算2007年数据...... 正在计算2008年数据...... 正在计算2009年数据...... 正在计算2010年数据...... 正在计算2011年数据...... 正在计算2012年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2013年数据...... 正在计算2014年数据...... 正在计算2015年数据...... 正在计算2016年数据...... 正在计算2017年数据...... 正在计算2018年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
计算完毕
df_returns_q_dict = {}for i in ['ACF','ADF','BCF','BDF']:stock_num = 20num = 1trade_list_e = trade_list[1:]print('正在计算%s分组收益......'%i)for s,e in zip(trade_list_e[:-1],trade_list_e[1:]):#获取到聚类最优的标签label = df_cent.loc[s,'label']df_values = df_all_values[s]#市值筛选条件if i[0] == 'B':df_values = df_values[(df_values['label']==label) & (df_values['circulating_market_cap']>df_values['circulating_market_cap'].quantile(0.7))].sort_values('point')else:df_values = df_values[df_values['label']==label].sort_values('point')#pe,roe筛选条件if i[1] == 'C':pool = df_values[:stock_num]['code'].valueselse:pool = df_values[(df_values['pe_ratio']<100) & (df_values['roe']>8)].sort_values('point')[:stock_num]['code'].values
if num == 0:if i[0] == 'A':df_returns1 = ret_se(pool,s,e) else:df_returns1 = ret_se1(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:if i[0] == 'A':df_returns = ret_se(pool,s,e)else:df_returns = ret_se1(pool,s,e)num = 0df_returns_q_dict[i] = df_returnsprint('计算完毕')df_returns_all_q = pd.DataFrame(df_returns_q_dict)正在计算ACF分组收益...... 正在计算ADF分组收益...... 正在计算BCF分组收益...... 正在计算BDF分组收益...... 计算完毕
df_returns_all_q = pd.DataFrame(df_returns_q_dict)
df_returns_all_q.cumprod().plot(figsize=(12,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f6ff9a78748>
月度统计
## 记录时间段内收益最好的pb,roe的值pb_roe_list = []label_list = []label_dict = {}dist_dict = {}df_all_values = {}#获取交易列表,按月trade_list = get_tradeday_list('2005-7-25','2018-7-25',label='month')note_year = str(trade_list[0])[:4]for s,e in zip(trade_list[:-1],trade_list[1:]):date = eif str(date)[:4] == note_year:print('正在计算%s年数据......'%str(date)[:4])note_year = str(int(note_year)+1)#获取数据,得出分组l1,l2,l3,l4,l5,l6,k1,k2,df = get_stock_pool_6(date)#获取分组收益se1 = ret_se(l1,s,e)se2 = ret_se(l2,s,e)se3 = ret_se(l3,s,e)se4 = ret_se(l4,s,e)se5 = ret_se(l5,s,e)se6 = ret_se(l6,s,e)df_all = pd.concat([se1,se2,se3,se4,se5,se6],axis=1)df_all.columns = [0,1,2,3,4,5]#获取收益最高组的标签label_1 = (df_all.cumprod()).iloc[-1].sort_values().index[-1]label_list.append(label_1)df_all_values[date] = dfpb_roe_list.append(k1[label_1].tolist()) #构建每期的最优标签、值的dfroe = [i[0][0] for i in pb_roe_list]pb = [i[0][1] for i in pb_roe_list]mkt = [i[0][2] for i in pb_roe_list]df_cent = pd.DataFrame(roe,index=trade_list[:-1],columns=['roe'])df_cent['pb'] = pbdf_cent['mkt'] = mktdf_cent['label'] = label_listprint('K聚类分组计算完毕')df_returns_m_dict = {}for i in ['ACE','ADE','BCE','BDE']:stock_num = 20num = 1trade_list_e = trade_list[1:]print('正在计算%s分组收益......'%i)for s,e in zip(trade_list_e[:-1],trade_list_e[1:]):#获取到聚类最优的标签label = df_cent.loc[s,'label']df_values = df_all_values[s]#市值筛选条件if i[0] == 'B':df_values = df_values[(df_values['label']==label) & (df_values['circulating_market_cap']>df_values['circulating_market_cap'].quantile(0.7))].sort_values('point')else:df_values = df_values[df_values['label']==label].sort_values('point')#pe,roe筛选条件if i[1] == 'C':pool = df_values[:stock_num]['code'].valueselse:pool = df_values[(df_values['pe_ratio']<100) & (df_values['roe']>8)].sort_values('point')[:stock_num]['code'].values
if num == 0:if i[0] == 'A':df_returns1 = ret_se(pool,s,e) else:df_returns1 = ret_se1(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:if i[0] == 'A':df_returns = ret_se(pool,s,e)else:df_returns = ret_se1(pool,s,e)num = 0df_returns_m_dict[i] = df_returnsprint('月度收益计算完毕')正在计算2005年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2006年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2007年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2008年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2009年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2011年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2012年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2013年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2014年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2015年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2016年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2017年数据...... 正在计算2018年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
K聚类分组计算完毕 正在计算ACE分组收益...... 正在计算ADE分组收益...... 正在计算BCE分组收益...... 正在计算BDE分组收益...... 月度收益计算完毕
季度统计
#记录时间段内收益最好的pb,roe的值pb_roe_list = []label_list = []label_dict = {}dist_dict = {}df_all_values = {}#获取交易列表,按月trade_list = get_tradeday_list('2005-7-25','2018-7-25',label='quarter')note_year = str(trade_list[0])[:4]for s,e in zip(trade_list[:-1],trade_list[1:]):date = eif str(date)[:4] == note_year:print('正在计算%s年数据......'%str(date)[:4])note_year = str(int(note_year)+1)#获取数据,得出分组l1,l2,l3,l4,l5,l6,k1,k2,df = get_stock_pool_6(date)#获取分组收益se1 = ret_se(l1,s,e)se2 = ret_se(l2,s,e)se3 = ret_se(l3,s,e)se4 = ret_se(l4,s,e)df_all = pd.concat([se1,se2,se3,se4],axis=1)df_all.columns = [0,1,2,3]#获取收益最高组的标签label_1 = (df_all.cumprod()).iloc[-1].sort_values().index[-1]label_list.append(label_1)df_all_values[date] = dfpb_roe_list.append(k1[label_1].tolist()) #构建每期的最优标签、值的dfroe = [i[0][0] for i in pb_roe_list]pb = [i[0][1] for i in pb_roe_list]df_cent = pd.DataFrame(roe,index=trade_list[:-1],columns=['roe'])df_cent['pb'] = pbdf_cent['label'] = label_listprint('K聚类分组计算完毕')df_returns_q_dict = {}for i in ['ACF','ADF','BCF','BDF']:stock_num = 20num = 1trade_list_e = trade_list[1:]print('正在计算%s分组收益......'%i)for s,e in zip(trade_list_e[:-1],trade_list_e[1:]):#获取到聚类最优的标签label = df_cent.loc[s,'label']df_values = df_all_values[s]#市值筛选条件if i[0] == 'B':df_values = df_values[(df_values['label']==label) & (df_values['circulating_market_cap']>df_values['circulating_market_cap'].quantile(0.7))].sort_values('point')else:df_values = df_values[df_values['label']==label].sort_values('point')#pe,roe筛选条件if i[1] == 'C':pool = df_values[:stock_num]['code'].valueselse:pool = df_values[(df_values['pe_ratio']<100) & (df_values['roe']>8)].sort_values('point')[:stock_num]['code'].values
if num == 0:if i[0] == 'A':df_returns1 = ret_se(pool,s,e) else:df_returns1 = ret_se1(pool,s,e) df_returns = pd.concat([df_returns,df_returns1])else:if i[0] == 'A':df_returns = ret_se(pool,s,e)else:df_returns = ret_se1(pool,s,e)num = 0df_returns_q_dict[i] = df_returnsprint('计算完毕')正在计算2005年数据...... 正在计算2006年数据...... 正在计算2007年数据...... 正在计算2008年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2009年数据...... 正在计算2010年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2011年数据...... 正在计算2012年数据...... 正在计算2013年数据...... 正在计算2014年数据...... 正在计算2015年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2016年数据......
/opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/matrixlib/defmatrix.py:549: RuntimeWarning: Mean of empty slice. return N.ndarray.mean(self, axis, dtype, out, keepdims=True)._collapse(axis) /opt/conda/envs/python3new/lib/python3.6/site-packages/numpy/core/_methods.py:73: RuntimeWarning: invalid value encountered in true_divide ret, rcount, out=ret, casting='unsafe', subok=False)
正在计算2017年数据...... 正在计算2018年数据...... K聚类分组计算完毕 正在计算ACF分组收益...... 正在计算ADF分组收益...... 正在计算BCF分组收益...... 正在计算BDF分组收益...... 计算完毕
df_returns_all_m = pd.DataFrame(df_returns_m_dict)#df_returns_all_q = pd.DataFrame(df_returns_q_dict)
df_returns_all_m.cumprod().plot(figsize=(12,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f6ffa5b8cf8>
df_returns_all_q.cumprod().plot(figsize=(12,7))
<matplotlib.axes._subplots.AxesSubplot at 0x7f6ffa746278>

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程