注:文末有思考题噢
本文参考银河证券:《经典模型系列之一:基于Beneish模型的A 股指数增强策略》
Beneish 模型是一个西方金融市场上常用的财务模型,它通过分析公司的财务指标,对公司的财务合理程度进行打分,从而判断一家公司是否有认为操控盈利数据、财务报表作假的现象。虽然如今的金融市场发展迅速,相关的法律监管越来越完善,公司财务报表作假的现象正在逐渐改善,但财务操纵的行为在整个世界范围内还是依然存在的。为了保护投资者的权益,提高监管效率,Beneish 模型对于检验上市公司财务数据的有效性,检验市场信息的对称性是十分有意义的。
Beneish 模型是由Messod D. Beneish(1999)在文章中提出的,文中模拟建立了一个检测利润操纵的模型,模型的变量用来补货利润操纵的可能结果或是可能促使公司进行利润操纵的先决条件。该模型通过对公司的一些财务比率进行分析计算,为公司进行打分,称为M 打分法,其具体的加权打分计算方式如下:
MScore=?4.840 0.920×DSRI 0.528×GMI 0.404×AQI 0.892×SGI 0.115×DEPI?0.172×SGAI?0.327×LVGI 4.697×TATAMScore=?4.840 0.920×DSRI 0.528×GMI 0.404×AQI 0.892×SGI 0.115×DEPI?0.172×SGAI?0.327×LVGI 4.697×TATA
<br>MScore=?4.840 0.920×DSRI 0.528×GMI 0.404×AQI 0.892×SGI 0.115×DEPI?<br>0.172×SGAI?0.327×LVGI 4.697×TATA<br>
分数越高,表明一家公司财务操纵的可能性越大,通常当M Score 大于-2.22 则认为公司很有可能出现了财务操纵的行为。综合考虑以上8 个指数,历史研究证明该模型可以较有效地判断公司是否有财务操纵行为。其中打分计算中各个指数的系数,是其论文中以1982-1992年被美国证监会(SEC)查处的74 家财务造假公司为观察样本,按照行业和年度配比了2332个控制样本,通过统计估计而得来的。
由此可见,该打分方法主要综合考虑了8 个财务指标,以下部分将分别对这8 个财务指标进行说明,以及测试其在中国A 市场上的效果:
(一)可调整的资产负债表指标(DSRI、AQI、TATA)
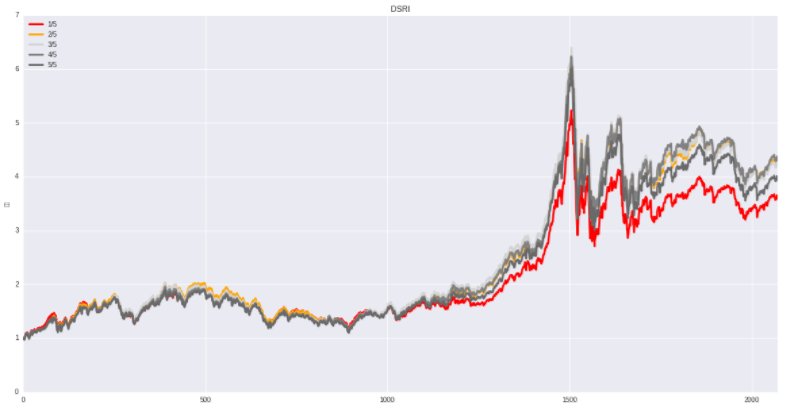
DSRI(Days' sales in receivable index):应收账款指数
计算公式:DSRI=(本期应收账款.本期营业收入)/(上期应收账款.上期营业收入)
显然DSRI 指数过高,表明公司可能操控应收账款项目来对营业收入与利润进行控制(测试中并不明显)
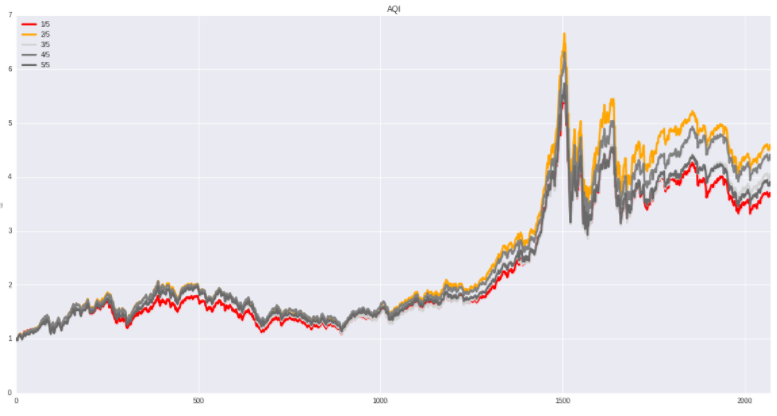
AQI(Asset quality index):资产质量指数
计算公式:AQI=本期非实物资产比例/上期非实物资产比例
AQI 指数检测公司是否可能通过操控非实物资产项目来控制利润率,从图中可知,本期非实物资产比例向下变动
的组别更受A 股投资者欢迎
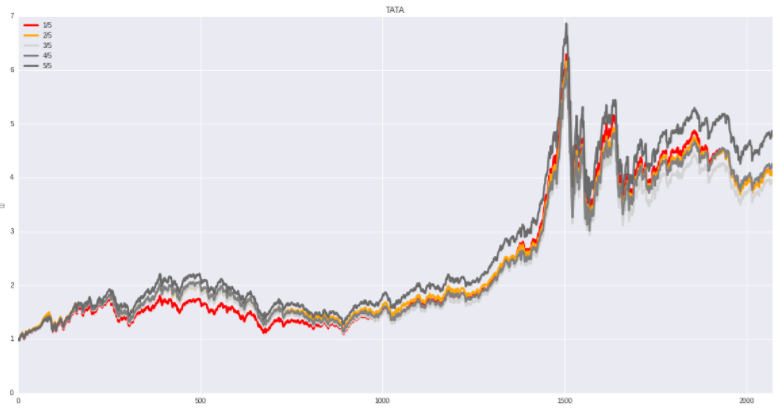
TATA(Total accruals to total assets):总应计项
计算公式:TATA=应计项/总资产=((Δ流动资产-Δ货币资金)-(Δ流动负债-Δ一年内到期长期负债-Δ应交税费)-折旧费用)/总资产
TATA 指数检测公司的非货币类的流动资产、流动负债有无异常变动情况,因为非货币类或长期应计项的认为操控也可以直接影响到最终的利润结果
(二)可调整的费用类指标
DEPI(Depreciation index):折旧率指数
计算公式:DEPI=(上期折旧费用.上期固定资产原值)/(本期折旧费用.本期固定资产原值)
DEPI 指数检测公司的折旧处理是否在合理范围内,因为折旧费用在报表中较难获得,本费用类指标暂不考虑
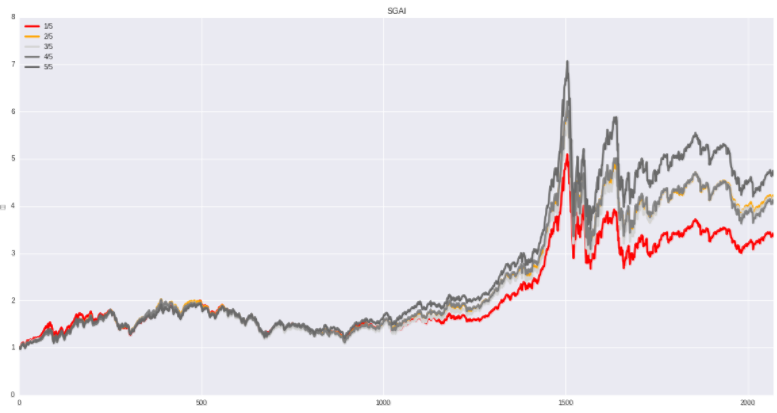
SGAI(Sales and general and administrative expenses index):销售管理费用指数
计算公式:SGAI=(((本期管理费用 本期销售费用)).本期营业收入)/(((上期管理费用 上期销售费用)).上期营业收入)
SGAI 指数检测公司的费用数据是否合理,检测公司是否有可能通过减少费用报告来操纵利润数据,本期管理销售费用比例向上变动的组别更受A 股投资者欢迎
(三)可调整的收益率
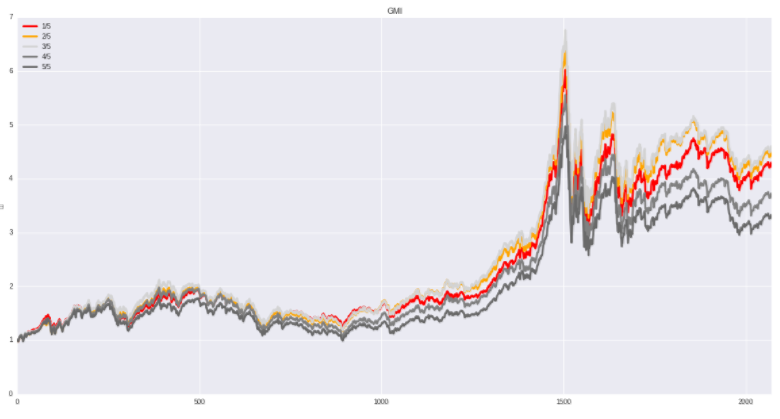
GMI(Gross margin index):毛利率指数
计算公式:GMI=上期毛利率/本期毛利率
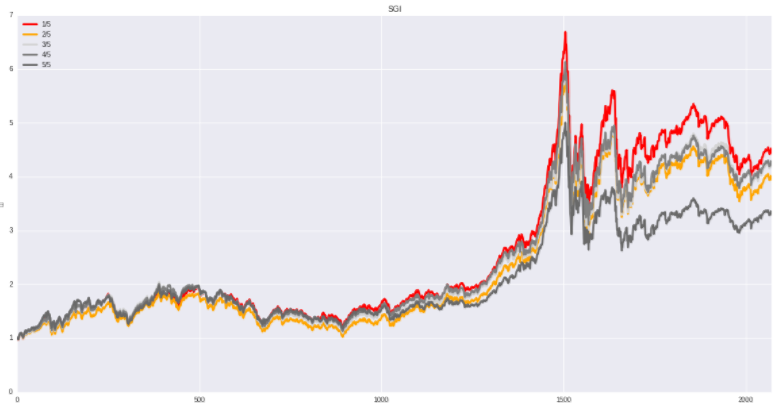
SGI(Sales growth index):营业收入指数
计算公式:SGI=本期营业收入/上期营业收入
SGI 指数检验营业收入是否有异常变动,操控利润通常都要通过操控营业收入
(四)应该调整的杠杆率指标
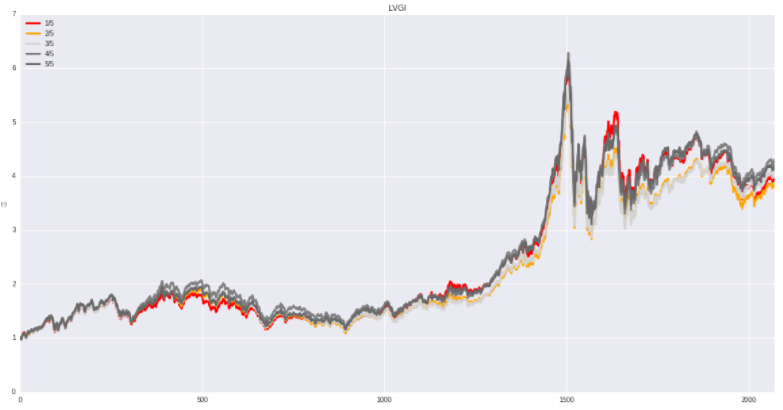
LVGI(Leverage index):财务杠杆指数
计算公式:LVGI=本期资产负债率/上期资产负债率
在本文中,我们每个季度进行一次调仓,根据各指标的得分进行排序构造投资组合,同时观察各组合的累计净值,可以发现部分指标的表现和理论不太一致。一个有可能的原因是:在季度进行调仓时,可能财报已经发布了一段时间,例如1.1和4.1分别调仓,但是1.1的财报数据可能是两个月前的,而4.1日的财报也可能是两个月前的,这时股票价格可能已经反映了指标变化。理论上,财报公布当天就需要进行调仓选股,但是又必须兼顾指标排序,这个问题怎么解决呢?一个解决方案是获取财报公布时间,然后再判断指标属于哪个区间,这个过程涉及了许多data.frame的处理和逻辑,读者可以进行尝试。后面的文章,我们将直接根据银河证券给出的回归方程构造策略。
·作者:JoeyQ
注:文末有思考题噢
本文参考银河证券:《经典模型系列之一:基于Beneish模型的A 股指数增强策略》
Beneish 模型是一个西方金融市场上常用的财务模型,它通过分析公司的财务指标,对公司的财务合理程度进行打分,从而判断一家公司是否有认为操控盈利数据、财务报表作假的现象。虽然如今的金融市场发展迅速,相关的法律监管越来越完善,公司财务报表作假的现象正在逐渐改善,但财务操纵的行为在整个世界范围内还是依然存在的。为了保护投资者的权益,提高监管效率,Beneish 模型对于检验上市公司财务数据的有效性,检验市场信息的对称性是十分有意义的。
Beneish 模型是由Messod D. Beneish(1999)在文章中提出的,文中模拟建立了一个检测利润操纵的模型,模型的变量用来补货利润操纵的可能结果或是可能促使公司进行利润操纵的先决条件。该模型通过对公司的一些财务比率进行分析计算,为公司进行打分,称为M 打分法,其具体的加权打分计算方式如下: $$ MScore=-4.840+0.920×DSRI+0.528×GMI+0.404×AQI+0.892×SGI+0.115×DEPI-0.172×SGAI-0.327×LVGI+4.697×TATA $$ 分数越高,表明一家公司财务操纵的可能性越大,通常当M Score 大于-2.22 则认为公司很有可能出现了财务操纵的行为。综合考虑以上8 个指数,历史研究证明该模型可以较有效地判断公司是否有财务操纵行为。其中打分计算中各个指数的系数,是其论文中以1982-1992年被美国证监会(SEC)查处的74 家财务造假公司为观察样本,按照行业和年度配比了2332个控制样本,通过统计估计而得来的。 由此可见,该打分方法主要综合考虑了8 个财务指标,以下部分将分别对这8 个财务指标进行说明,以及测试其在中国A 市场上的效果:
(一)可调整的资产负债表指标(DSRI、AQI、TATA)
DSRI(Days' sales in receivable index):应收账款指数
计算公式:DSRI=(本期应收账款.本期营业收入)/(上期应收账款.上期营业收入)
显然DSRI 指数过高,表明公司可能操控应收账款项目来对营业收入与利润进行控制(测试中并不明显)
AQI(Asset quality index):资产质量指数
计算公式:AQI=本期非实物资产比例/上期非实物资产比例
AQI 指数检测公司是否可能通过操控非实物资产项目来控制利润率,从图中可知,本期非实物资产比例向下变动
的组别更受A 股投资者欢迎
TATA(Total accruals to total assets):总应计项
计算公式:TATA=应计项/总资产=((Δ流动资产-Δ货币资金)-(Δ流动负债-Δ一年内到期长期负债-Δ应交税费)-折旧费用)/总资产
TATA 指数检测公司的非货币类的流动资产、流动负债有无异常变动情况,因为非货币类或长期应计项的认为操控也可以直接影响到最终的利润结果
(二)可调整的费用类指标
DEPI(Depreciation index):折旧率指数
计算公式:DEPI=(上期折旧费用.上期固定资产原值)/(本期折旧费用.本期固定资产原值)
DEPI 指数检测公司的折旧处理是否在合理范围内,因为折旧费用在报表中较难获得,本费用类指标暂不考虑
SGAI(Sales and general and administrative expenses index):销售管理费用指数
计算公式:SGAI=(((本期管理费用+本期销售费用)).本期营业收入)/(((上期管理费用+上期销售费用)).上期营业收入)
SGAI 指数检测公司的费用数据是否合理,检测公司是否有可能通过减少费用报告来操纵利润数据,本期管理销售费用比例向下变动的组别更受A 股投资者欢迎
(三)可调整的收益率
GMI(Gross margin index):毛利率指数
计算公式:GMI=上期毛利率/本期毛利率
SGI(Sales growth index):营业收入指数
计算公式:SGI=本期营业收入/上期营业收入
SGI 指数检验营业收入是否有异常变动,操控利润通常都要通过操控营业收入
(四)应该调整的杠杆率指标
LVGI(Leverage index):财务杠杆指数
计算公式:LVGI=本期资产负债率/上期资产负债率
在本文中,我们每个季度进行一次调仓,根据各指标的得分进行排序构造投资组合,同时观察各组合的累计净值,可以发现部分指标的表现和理论不太一致。一个有可能的原因是:在季度进行调仓时,可能财报已经发布了一段时间,例如1.1和4.1分别调仓,但是1.1的财报数据可能是两个月前的,而4.1日的财报也可能是两个月前的,这时股票价格可能已经反映了指标变化。理论上,财报公布当天就需要进行调仓选股,但是又必须兼顾指标排序,这个问题怎么解决呢?一个解决方案是获取财报公布时间,然后再判断指标属于哪个区间,这个过程涉及了许多data.frame的处理和逻辑,读者可以进行尝试。后面的文章,我们将直接根据银河证券给出的回归方程构造策略。
import pandas as pdimport seabornimport numpy as npimport matplotlib.pyplot as pltfrom jqdata import *from datetime import timedelta, date
##生成季度时间time=[]for i in arange(2009,2018):for j in arange(1,13,3):tempt=datetime.date(i,j,1) for jj in arange(14):if tempt in get_all_trade_days():breakelse:tempt=tempt+timedelta(days = 1)time.append(tempt)
def trade(name):##交易函数##输入name:DSRI应收账款指数,AQI资产质量指数,TATA总应计项,SGAI销售管理费用指数,GMI毛利率指数,SGI营业收入指数,LVGI财务杠杆指数##输出:分组排列绘图allstore=pd.DataFrame()for i in arange(len(time)-2):##########stocks=get_index_stocks('000001.XSHG',date=time[i])+get_index_stocks('399106.XSHE',date=time[i])if name=='DSRI':q=query(valuation.code, #代码balance.account_receivable, #应收账款income.operating_revenue #营业收入).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1])df2[name]=(df2['account_receivable']/df2['operating_revenue'])/(df1['account_receivable']/df1['operating_revenue'])elif name=='AQI':q=query(valuation.code, #代码balance.total_assets, #总资产balance.intangible_assets #无形资产).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=(df2['intangible_assets']/df2['total_assets'])/(df1['intangible_assets']/df1['total_assets'])elif name=='TATA':q=query(valuation.code, #代码balance.total_assets, #总资产balance.accounts_payable #应付账款).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=df2['accounts_payable']/df2['total_assets']elif name=='SGAI':q=query(valuation.code, #代码income.administration_expense, #管理费用income.sale_expense, #销售费用income.operating_revenue ).filter(# 这里不能使用 in 操作, 要使用in_()函数 valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=((df2['administration_expense']+df2['sale_expense'])/df2['operating_revenue'])/((df2['administration_expense']+df1['sale_expense'])/df1['operating_revenue'])elif name=='GMI':q=query(valuation.code, #代码indicator.gross_profit_margin, #毛利率).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=df1['gross_profit_margin']/df2['gross_profit_margin']elif name=='SGI':q=query(valuation.code, #代码income.operating_revenue #营业收入).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=df2['operating_revenue']/df1['operating_revenue']elif name=='LVGI':q=query(valuation.code, #代码balance.total_assets, #总资产balance.total_liability #总负债).filter(# 这里不能使用 in 操作, 要使用in_()函数valuation.code.in_(stocks))df1 = get_fundamentals(q, date=time[i])df2= get_fundamentals(q, date=time[i+1]) df2[name]=(df2['total_liability']/df2['total_assets'])/(df1['total_liability']/df1['total_assets'])store=df2.dropna()###处理一下store,主要是把不变的删去,因为会影响结果store=store[(True-store[name].isin([1]))]
num=len(store)store1=pd.DataFrame()for j in arange(5):stock1=store.sort(name)['code'][(num/5)*j:(num/5)*(j+1)] #每个组合,从小到大排列storerate=pd.DataFrame()for stock in list(stock1):price=get_price(stock,start_date=time[i+1],end_date=time[i+2],fields='close',frequency='1d')['close']storerate[stock]=price.diff(1)[1:]/list(price[:-1])store1[str(j)]=storerate.mean(axis=1)allstore=pd.concat([allstore,store1],axis=0)#画图netvalue=pd.DataFrame()for i3 in arange(5):tempt1=[] tempt=1for i4 in arange(len(allstore['0'])):tempt=tempt*(1+list(allstore[str(i3)])[i4])tempt1.append(tempt)netvalue[str(i3)]=tempt1plt.figure(figsize=(20,10))plt.plot(netvalue['0'],label='1/5',color='red',linewidth=3)plt.plot(netvalue['1'],label='2/5',color='orange',linewidth=3)plt.plot(netvalue['2'],label='3/5',color='lightgray',linewidth=3)plt.plot(netvalue['3'],label='4/5',color='gray',linewidth=3)plt.plot(netvalue['4'],label='5/5',color='dimgray',linewidth=3)plt.title(name)plt.ylabel('净值')plt.legend(loc='upper left')plt.xlim(0,len(netvalue)+1)store=trade('DSRI')/opt/conda/envs/python2/lib/python2.7/site-packages/pandas/computation/expressions.py:190: UserWarning: evaluating in Python space because the '-' operator is not supported by numexpr for the bool dtype, use '^' instead unsupported[op_str]))
trade('AQI')trade('TATA')trade('SGAI')trade('GMI')trade('SGI')trade('LVGI')
本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程