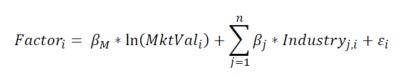目前因子去极值、中性化、标准化没有标准的流程,券商研报对此语焉不详,不同平台处理各有特色,甚至将中性化、标准化混淆。查阅了一些资料,结合自己的理解,总结如下:
1、去极值。在处理金融事件序列的数据时,经常性会遇到极值的情况存在,如长尾效应,极值会影响数据的适用程度,比如拉大标准差、造成统计偏见等问题。一般去极值的处理方法就是确定该项指标的上下限,然后超过或者低于限值的数据统统即为限值。其中上下限数值判断标准有三种,分别为 MAD、 3σ、百分位法。本文使用3σ法。
2、标准化。在多因子体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。本文使用‘’Z-score标准化”法。
3、中性化。在使用因子进行选股时,经常会因为其它因子的影响,而导致选出来的股票具有一些我们不希望看到的偏向。比如说,市净率pb会与市值有很高的相关性,这时如果我们使用未进行市值中性化的市净率,选股的结果会比较集中。同时朝阳行业和夕阳行业的市盈率在大致上也有一定的特点,比如银行股的市盈率特别的低,而互联网行业的市盈率就特别的高,也就是说行业对估值因子也有影响,如果未进行行业中性化那么我们得到的结果是具有一些行业性的偏好。还有一些大类风格因子也会对选股产生影响,比如贝塔、动量、盈利、成长、杠杆等。这种情况下你就需要进行数据中性化处理。本文以市值和行业中性化为例进行说明。 中性化处理概念:为了在用某一因子时能剔除其他因素的影响,使得选出的股票更加分散。标准化用于多个不同量级指标之间需要互相比较或者数据需要变得集中,而中性化的目的在于消除因子中的偏差和不需要的影响。
具体方法:根据大部分的研报对于中性化的处理,主要的方法是利用回归得到一个与风险因子线性无关的因子,即通过建立线性回归,提取残差作为中性化后的新因子。这样处理后的中性化因子与风险因子之间的相关性严格为零。
将这些功能写在函数里,方便大家调用,一条语句可以完成市值、行业的去极值、标准化、中性化。水平有限希望大神来挑刺和改进。
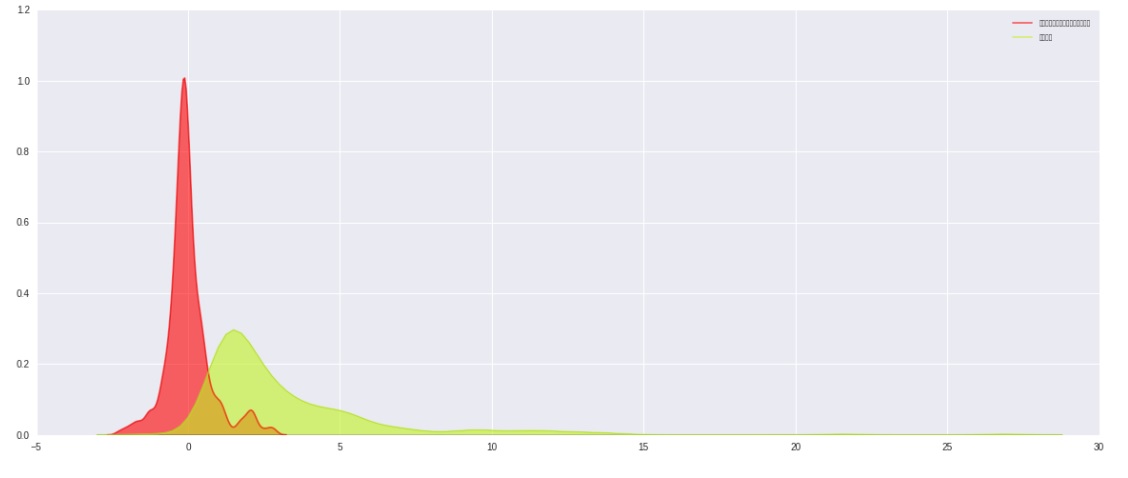
去极值、标准化、中性化前后的分布图对比
# 导入函数库
import jqdata
import numpy as np
import pandas as pd
import math
from statsmodels import regression
import statsmodels.api as sm
import matplotlib.pyplot as plt
def winsorize(factor, std=3, have_negative = True):
'''
去极值函数
factor:以股票code为index,因子值为value的Series
std为几倍的标准差,have_negative 为布尔值,是否包括负值
输出Series
'''
r=factor.dropna().copy()
if have_negative == False:
r = r[r>=0]
else:
pass
#取极值
edge_up = r.mean()+std*r.std()
edge_low = r.mean()-std*r.std()
r[r>edge_up] = edge_up
r[r<edge_low] = edge_low
return r
#标准化函数:
def standardize(s,ty=2):
'''
s为Series数据
ty为标准化类型:1 MinMax,2 Standard,3 maxabs
'''
data=s.dropna().copy()
if int(ty)==1:
re = (data - data.min())/(data.max() - data.min())
elif ty==2:
re = (data - data.mean())/data.std()
elif ty==3:
re = data/10**np.ceil(np.log10(data.abs().max()))
return re
#中性化函数
#传入:mkt_cap:以股票为index,市值为value的Series,
#factor:以股票code为index,因子值为value的Series,
#输出:中性化后的因子值series
def neutralization(factor,mkt_cap = False, industry = True):
y = factor
if type(mkt_cap) == pd.Series:
LnMktCap = mkt_cap.apply(lambda x:math.log(x))
if industry: #行业、市值
dummy_industry = get_industry_exposure(factor.index)
x = pd.concat([LnMktCap,dummy_industry.T],axis = 1)
else: #仅市值
x = LnMktCap
elif industry: #仅行业
dummy_industry = get_industry_exposure(factor.index)
x = dummy_industry.T
result = sm.OLS(y.astype(float),x.astype(float)).fit()
return result.resid
#为股票池添加行业标记,return df格式 ,为中性化函数的子函数
def get_industry_exposure(stock_list):
df = pd.DataFrame(index=jqdata.get_industries(name='sw_l1').index, columns=stock_list)
for stock in stock_list:
try:
df[stock][get_industry_code_from_security(stock)] = 1
except:
continue
return df.fillna(0)#将NaN赋为0
#查询个股所在行业函数代码(申万一级) ,为中性化函数的子函数
def get_industry_code_from_security(security,date=None):
industry_index=jqdata.get_industries(name='sw_l1').index
for i in range(0,len(industry_index)):
try:
index = get_industry_stocks(industry_index[i],date=date).index(security)
return industry_index[i]
except:
continue
return u'未找到'
#a=get_industry_code_from_security('600519.XSHG', date=pd.datetime.today())
#print a
#stocks_industry=get_industry_exposure(stocks)
#print stocks_industry
def get_win_stand_neutra(stocks):
h=get_fundamentals(query(valuation.pb_ratio,valuation.code,valuation.market_cap)\
.filter(valuation.code.in_(stocks)))
stocks_pb_se=pd.Series(list(h.pb_ratio),index=list(h.code))
stocks_pb_win_standse=standardize(winsorize(stocks_pb_se))
stocks_mktcap_se=pd.Series(list(h.market_cap),index=list(h.code))
stocks_neutra_se=neutralization(stocks_pb_win_standse,stocks_mktcap_se)
return stocks_neutra_se
#对沪深300成分股完成
stocks=get_index_stocks('000300.XSHG')
print get_win_stand_neutra(stocks)
000001.XSHE -0.013790
000002.XSHE -0.108788
000008.XSHE 0.114547
000060.XSHE -0.509379
000063.XSHE 0.250793
000069.XSHE -0.290520
000100.XSHE -0.740104
000157.XSHE -0.499939
000166.XSHE -0.129296
000333.XSHE 0.039815
000338.XSHE -0.181432
000402.XSHE -0.282417
000413.XSHE -1.640085
000415.XSHE -0.136226
000423.XSHE -1.270119
000425.XSHE -0.323668
000503.XSHE 2.178354
000538.XSHE -0.634710
000540.XSHE 0.116073
000559.XSHE 0.909363
000568.XSHE -0.148495
000623.XSHE -2.024256
000625.XSHE -0.410519
000627.XSHE 0.155043
000630.XSHE -0.778900
000651.XSHE -0.091205
000671.XSHE 0.074495
000686.XSHE -0.042734
000709.XSHE -0.059121
000723.XSHE 0.463084
...
601788.XSHG -0.184681
601800.XSHG -0.303928
601818.XSHG -0.074857
601857.XSHG -0.688380
601866.XSHG -0.036738
601872.XSHG -0.292435
601877.XSHG -0.127317
601878.XSHG 0.494662
601881.XSHG -0.092312
601888.XSHG 0.538350
601898.XSHG -0.420418
601899.XSHG -0.532487
601901.XSHG -0.126128
601919.XSHG 0.115174
601933.XSHG 0.601026
601939.XSHG -0.257613
601958.XSHG -0.694780
601966.XSHG 0.054701
601985.XSHG -0.024628
601988.XSHG -0.297110
601989.XSHG -0.756536
601991.XSHG -0.378050
601992.XSHG -0.412648
601997.XSHG 0.334631
601998.XSHG -0.094642
603160.XSHG 1.951462
603799.XSHG 2.100664
603833.XSHG 0.804125
603858.XSHG -1.560785
603993.XSHG 0.008446
dtype: float64
import seaborn as sns
fig = plt.figure(figsize = (20, 8))
h=get_fundamentals(query(valuation.pb_ratio,valuation.code,valuation.market_cap)\
.filter(valuation.code.in_(stocks)))
stocks_pb_se=pd.Series(list(h.pb_ratio),index=list(h.code))
sns.kdeplot(get_win_stand_neutra(stocks), label = '去极值、中性化、标准化后的数据', color="#FF0000", alpha=.6, shade=True)
sns.kdeplot(stocks_pb_se, label = '原始数据', color="#C1F320", alpha=.6, shade=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f8cf2778090>
/opt/conda/envs/python2/lib/python2.7/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
if self._edgecolors == str('face'):


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...