本周市场依然是下跌态势,自破了3千点后,又连续下挫3周,以上是个指标数据
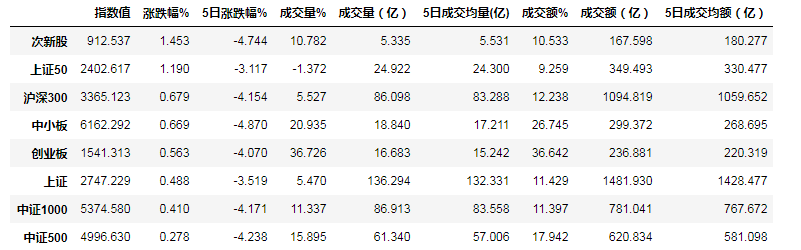
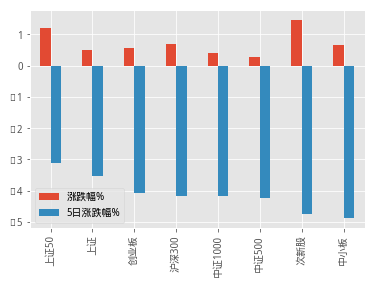
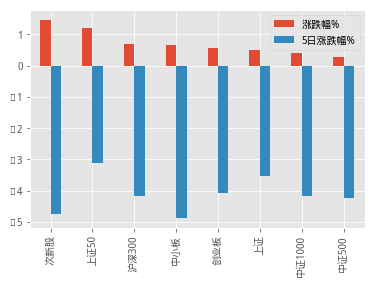
先按照5日涨跌进行排序,发现各指标本周下跌幅度均已超过3%,从不同市值分布的走势情况看,除上证50将上证指数周跌拉扯至4%以内,其他市值区间的指数,如中证500,中证1000的涨跌幅均已超过4%,板块方面,板块指数跌势中小板、次新股先跌为敬,直逼5%
今天市场反弹就是由本周跌势较猛的次新股引领,上证50紧随其后,难道是国家队开要行动了么(滑稽脸)
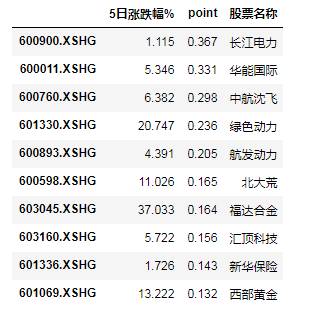
以下是本周上证指数涨跌贡献度最大的10只股票
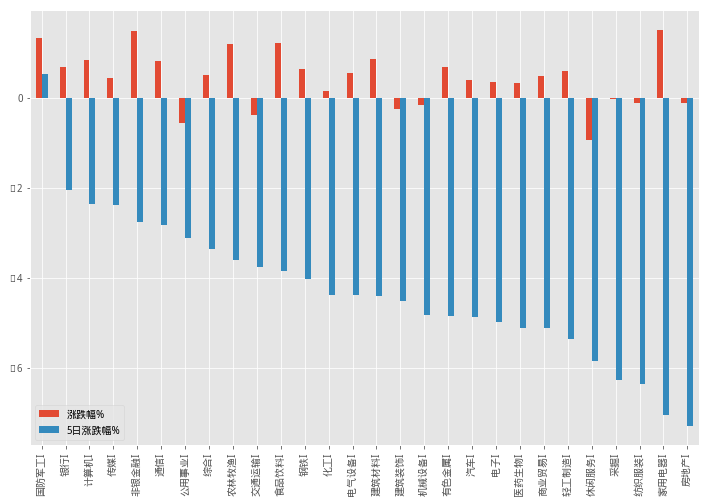
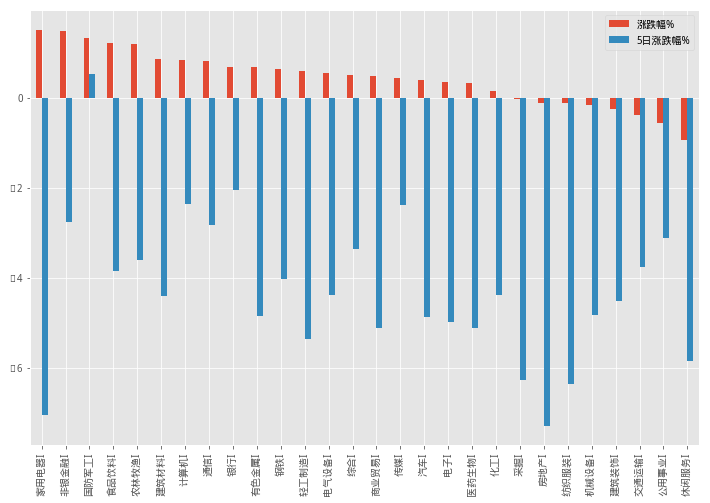
行业方面,以下是本周申万一级行业指数的走势统计,除了国防军工还坚守在0轴之上,其他的27个行业均在紧随市场步调,房地产行业则借棚改货币化政策收紧的利空消息,首当其冲,带动家电行业一起下坠。顺带再贴下今天的行业走势
再来看下最近的因子跟踪情况
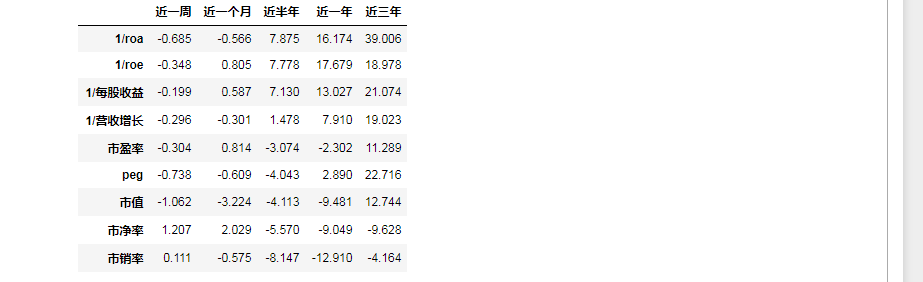
目前,先选取了9个因子,按因子值从小到大进行了排序分组,统计分组的多空组合收益,按照不同的因子,不同的时间周期进行了统计计算,以下是近一周、近一个月、近半年、近一年、近三年的组合表现
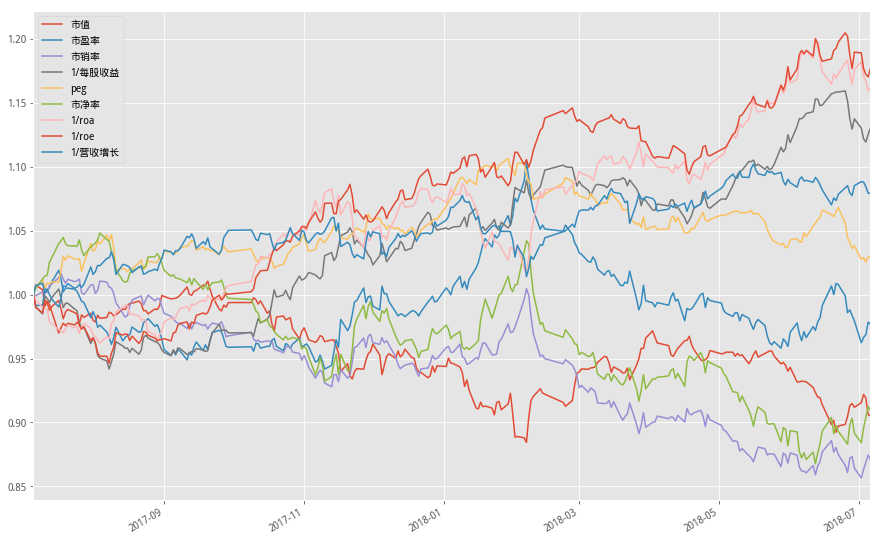
便于更直观的展示效果,这里进行了各个因子组合近一年的多空组合累计收益曲线
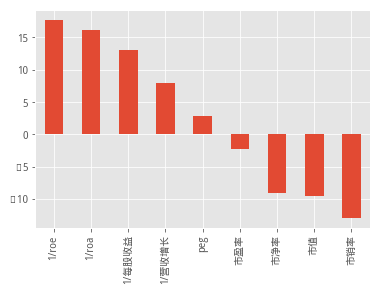
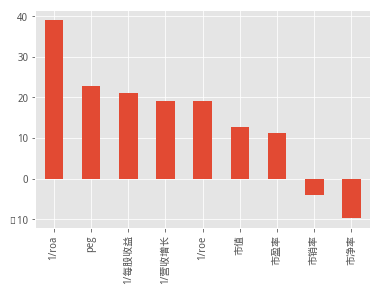
从图中看出,近一年的时间里,较高的roa、roe、每股收益的组合走势收益最大
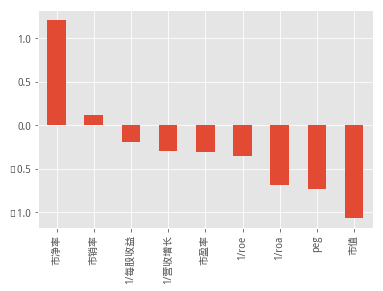
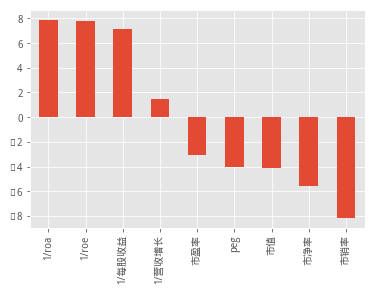
以下是展示了近一周的表现,从结果看到,近一周市净率较低的组合收益最高,后面的分别为近半年、近一年、近三年的组合收益结果
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from jqdata import jy
pd.set_option('precision', 3)
import datetime
import jqdata
from jqdata import *
import matplotlib.pyplot as plt
plt.style.use('ggplot')
#统计各指数当天涨跌
#输入日期
#返回df
class report():
#1.指数涨跌
def get_index_pct(self,date):
#指数涨跌幅统计
#总数据
zhishu_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE']
pl = get_price(zhishu_list,end_date=date,count=6)#.ix[:,0,:]
#涨跌幅数据
pl_pct = (pl.iloc[:,-1,:]/pl.iloc[:,-2,:]-1)*100
pl_pct_5 = (pl.iloc[:,-1,:]/pl.iloc[:,-6,:]-1)*100
#5日money均量
df_money = pl.loc['money',:,:]
def f(x):
return x.mean()
se_money = df_money.apply(f)
#5日volume均量
df_volume = pl.loc['volume',:,:]
def f(x):
return x.mean()
se_volume = df_volume.apply(f)
#最新一天指数值数据
zv = pl.iloc[:,-1,:]
zv['name'] = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板']
df_fin = pd.concat([zv['close'],pl_pct['close'],pl_pct_5['close'],pl_pct['volume'],zv['volume']/(10**8),se_volume/(10**8),pl_pct['money'],zv['money']/(10**8),se_money/(10**8)],axis=1)
df_fin.index = zv['name'].values
df_fin.columns = ['指数值','涨跌幅%','5日涨跌幅%','成交量%','成交量(亿)','5日成交均量(亿)','成交额%','成交额(亿)','5日成交均额(亿)']
return df_fin
#2.行业涨跌幅统计
def get_hy_pct(self,y=2018,m=7,d=6,days = 5):
#行业涨跌幅
def get_SW_index(SW_index = 801010,start_date = '2017-01-31',end_date = '2018-01-31'):
index_list = ['PrevClosePrice','OpenPrice','HighPrice','LowPrice','ClosePrice','TurnoverVolume','TurnoverValue','TurnoverDeals','ChangePCT','UpdateTime']
jydf = jy.run_query(query(jy.SecuMain).filter(jy.SecuMain.SecuCode==str(SW_index)))
link=jydf[jydf.SecuCode==str(SW_index)]
rows=jydf[jydf.SecuCode==str(SW_index)].index.tolist()
result=link['InnerCode'][rows]
df = jy.run_query(query(jy.QT_SYWGIndexQuote).filter(jy.QT_SYWGIndexQuote.InnerCode==str(result[0]),\
jy.QT_SYWGIndexQuote.TradingDay>=start_date,\
jy.QT_SYWGIndexQuote.TradingDay<=end_date
))
df.index = df['TradingDay']
df = df[index_list]
return df
def ShiftTradingDay(date,shift=5):
# 获取所有的交易日,返回一个包含所有交易日的 list,元素值为 datetime.date 类型.
tradingday = get_all_trade_days()
# 得到date之后shift天那一天在列表中的行标号 返回一个数
shiftday_index = list(tradingday).index(date)+shift
# 根据行号返回该日日期 为datetime.date类型
return tradingday[shiftday_index]
date = datetime.date(y,m,d)
date_s = ShiftTradingDay(date,-days)
#指数涨跌幅统计
#总数据
sw_hy = jqdata.get_industries(name='sw_l1')
sw_hy_dict = {}
for i in sw_hy.index:
value = get_SW_index(i,start_date=date_s,end_date=date)
sw_hy_dict[i] = value
pl_hy = pd.Panel(sw_hy_dict)
pl = pl_hy.transpose(2,1,0)
pl = pl.loc[['PrevClosePrice','OpenPrice','HighPrice','LowPrice','ClosePrice','TurnoverVolume','TurnoverValue'],:,:]
#涨跌幅数据
pl_pct = (pl.iloc[:,-1,:]/pl.iloc[:,-2,:]-1)*100
pl_pct_5 = (pl.iloc[:,-1,:]/pl.iloc[:,-6,:]-1)*100
#5日money均量
df_money = pl.loc['TurnoverValue',:,:]
def f(x):
return x.mean()
se_money = df_money.apply(f)
#5日volume均量
df_volume = pl.loc['TurnoverVolume',:,:]
def f(x):
return x.mean()
se_volume = df_volume.apply(f)
#最新一天指数值数据
zv = pl.iloc[:,-1,:]
zv['name'] = sw_hy['name']
df_fin = pd.concat([zv['ClosePrice'],pl_pct['ClosePrice'],pl_pct_5['ClosePrice'],pl_pct['TurnoverVolume'],zv['TurnoverVolume']/(10**8),se_volume/(10**8),pl_pct['TurnoverValue'],zv['TurnoverValue']/(10**8),se_money/(10**8)],axis=1)
df_fin.columns = ['指数值','涨跌幅%','5日涨跌幅%','成交量%','成交量(亿)','5日成交均量(亿)','成交额%','成交额(亿)','5日成交均额(亿)']
df_fin['name'] = sw_hy['name']
df_fin['code'] = df_fin.index
df_fin.index = df_fin['name'].values
del df_fin['name']
return df_fin.sort_values(by = '涨跌幅%',ascending=0)
#指数贡献点数
def get_index_contribution(self,date='2018-6-30',index='000001.XSHG'):
def get_pct(date,pool):
#指数涨跌幅统计
#总数据
#zhishu_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE']
zhishu_list = pool#[:8]
pl = get_price(zhishu_list,end_date=date,count=6)#.ix[:,0,:]
#涨跌幅数据
pl_pct = (pl.iloc[:,-1,:]/pl.iloc[:,-2,:]-1)*100
pl_pct_5 = (pl.iloc[:,-1,:]/pl.iloc[:,-6,:]-1)*100
#5日money均量
df_money = pl.loc['money',:,:]
def f(x):
return x.mean()
se_money = df_money.apply(f)
#5日volume均量
df_volume = pl.loc['volume',:,:]
def f(x):
return x.mean()
se_volume = df_volume.apply(f)
#最新一天指数值数据
zv = pl.iloc[:,-1,:]
#zv['name'] = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板']
zv['name'] = zhishu_list
df_fin = pd.concat([zv['close'],pl_pct['close'],pl_pct_5['close'],pl_pct['volume'],zv['volume']/(10**8),se_volume/(10**8),pl_pct['money'],zv['money']/(10**8),se_money/(10**8)],axis=1)
df_fin.index = zv['name'].values
df_fin.columns = ['当前价格','涨跌幅%','5日涨跌幅%','成交量%','成交量(亿)','5日成交均量(亿)','成交额%','成交额(亿)','5日成交均额(亿)']
return df_fin
#获取大盘成分股权重
def get_weight():
q = query(jy.LC_IndexComponentsWeight).filter(jy.LC_IndexComponentsWeight.UpdateTime>'2018-6-1',\
jy.LC_IndexComponentsWeight.IndexCode == '1')
df = jy.run_query(q)
df_weight = df[['InnerCode','Weight']]
#获取证券主表
df_code_main = jy.run_query(query(jy.SecuMain).filter(jy.SecuMain.InnerCode.in_(list(df_weight['InnerCode'].values))))
df_code = df_code_main[['InnerCode','SecuCode']]
#print(df_code)
#进行拼接,得到股票的权重数据
df_weight_tab = pd.merge(df_code,df_weight,on='InnerCode')
#转换成需要的代码格式即可
df_weight_tab['code'] = [normalize_code(i) for i in df_weight_tab['SecuCode'].values]
df_weight_tab.index = df_weight_tab.code
weight_se = df_weight_tab['Weight']/100.0
return weight_se
pool = get_index_stocks(index)
df_weight_main = get_pct(date,pool)
weight_se = get_weight()
#5天前大盘的值
point = get_price('000001.XSHG',end_date=date,count=5)['close'][0]
#5天贡献点数计算
df_weight_main['weight_se'] = weight_se
df_weight_main['point'] = df_weight_main['weight_se']*df_weight_main['5日涨跌幅%']*point/100.0
df_index_weight = df_weight_main.sort_values(by='point',ascending=0)
df_index_weight = df_index_weight[['5日涨跌幅%','point']]
f_pool = df_index_weight[:10]
b_pool = df_index_weight.dropna()[-10:]
return f_pool,b_pool
a = report()
index_pct_df = a.get_index_pct('2018-7-6')
hy_pct_df = a.get_hy_pct(2018,7,6)
index_crb_df = a.get_index_contribution('2018-7-6')
/opt/conda/envs/python3new/lib/python3.6/site-packages/ipykernel_launcher.py:3: DeprecationWarning: Panel is deprecated and will be removed in a future version. The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/. Pandas provides a `.to_xarray()` method to help automate this conversion. This is separate from the ipykernel package so we can avoid doing imports until
index_pct_df = index_pct_df.sort_values(by='涨跌幅%',ascending=0)
index_pct_df
| 指数值 | 涨跌幅% | 5日涨跌幅% | 成交量% | 成交量(亿) | 5日成交均量(亿) | 成交额% | 成交额(亿) | 5日成交均额(亿) | |
|---|---|---|---|---|---|---|---|---|---|
| 次新股 | 912.537 | 1.453 | -4.744 | 10.782 | 5.335 | 5.531 | 10.533 | 167.598 | 180.277 |
| 上证50 | 2402.617 | 1.190 | -3.117 | -1.372 | 24.922 | 24.300 | 9.259 | 349.493 | 330.477 |
| 沪深300 | 3365.123 | 0.679 | -4.154 | 5.527 | 86.098 | 83.288 | 12.238 | 1094.819 | 1059.652 |
| 中小板 | 6162.292 | 0.669 | -4.870 | 20.935 | 18.840 | 17.211 | 26.745 | 299.372 | 268.695 |
| 创业板 | 1541.313 | 0.563 | -4.070 | 36.726 | 16.683 | 15.242 | 36.642 | 236.881 | 220.319 |
| 上证 | 2747.229 | 0.488 | -3.519 | 5.470 | 136.294 | 132.331 | 11.429 | 1481.930 | 1428.477 |
| 中证1000 | 5374.580 | 0.410 | -4.171 | 11.337 | 86.913 | 83.558 | 11.397 | 781.041 | 767.672 |
| 中证500 | 4996.630 | 0.278 | -4.238 | 15.895 | 61.340 | 57.006 | 17.942 | 620.834 | 581.098 |
def get_name(code,Type='stock'):
all_data = get_all_securities(types=Type)
i = list(all_data.index).index(code)
return all_data['display_name'][i]
name_list0 = [get_name(i) for i in index_crb_df[0].index]
name_list1 = [get_name(i) for i in index_crb_df[1].index]
index_crb_df[0]['股票名称'] = name_list0
index_crb_df[1]['股票名称'] = name_list1
index_crb_df[0]
| 5日涨跌幅% | point | 股票名称 | |
|---|---|---|---|
| 600900.XSHG | 1.115 | 0.367 | 长江电力 |
| 600011.XSHG | 5.346 | 0.331 | 华能国际 |
| 600760.XSHG | 6.382 | 0.298 | 中航沈飞 |
| 601330.XSHG | 20.747 | 0.236 | 绿色动力 |
| 600893.XSHG | 4.391 | 0.205 | 航发动力 |
| 600598.XSHG | 11.026 | 0.165 | 北大荒 |
| 603045.XSHG | 37.033 | 0.164 | 福达合金 |
| 603160.XSHG | 5.722 | 0.156 | 汇顶科技 |
| 601336.XSHG | 1.726 | 0.143 | 新华保险 |
| 601069.XSHG | 13.222 | 0.132 | 西部黄金 |
index_crb_df[1]
| 5日涨跌幅% | point | 股票名称 | |
|---|---|---|---|
| 601288.XSHG | -1.453 | -1.363 | 农业银行 |
| 600104.XSHG | -3.630 | -1.376 | 上汽集团 |
| 601668.XSHG | -7.143 | -1.519 | 中国建筑 |
| 601318.XSHG | -2.800 | -1.647 | 中国平安 |
| 600048.XSHG | -13.279 | -1.780 | 保利地产 |
| 600028.XSHG | -3.390 | -1.949 | 中国石化 |
| 600276.XSHG | -7.629 | -1.974 | 恒瑞医药 |
| 600519.XSHG | -2.371 | -2.019 | 贵州茅台 |
| 601138.XSHG | -6.562 | -2.209 | 工业富联 |
| 601857.XSHG | -3.372 | -3.903 | 中国石油 |
#图表展示
#指数单日和5日涨跌幅
index_pct_df = index_pct_df.sort_values(by='5日涨跌幅%',ascending=0)
index_pct_df[['涨跌幅%','5日涨跌幅%']].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae719588>

#图表展示
#指数单日和5日涨跌幅
index_pct_df = index_pct_df.sort_values(by='涨跌幅%',ascending=0)
index_pct_df[['涨跌幅%','5日涨跌幅%']].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae4c6c88>

index_pct_df = index_pct_df.sort_values(by='成交量%',ascending=0)
index_pct_df[['涨跌幅%','成交量%','成交额%']].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae70cc88>

hy_pct_df = hy_pct_df.sort_values(by = '涨跌幅%',ascending=0)
hy_pct_df[['涨跌幅%','5日涨跌幅%']].plot(kind='bar',figsize=(12,8))
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae2b9d30>

hy_pct_df = hy_pct_df.sort_values(by = '5日涨跌幅%',ascending=0)
hy_pct_df[['涨跌幅%','5日涨跌幅%']].plot(kind='bar',figsize=(12,8))
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae1856a0>

'''
因子效果统计
'''
#指定时间段的收益拼接(多空组合)
def get_fact_ret(fact,pool_index='000300.XSHG',fdate='2017-01-01',e_date='2017-02-01'):
#获取因子值(主要是财务因子值)
def get_df(pool,fdate):
q = query(
valuation.code,
valuation.circulating_market_cap,
valuation.pe_ratio,
valuation.ps_ratio, # PS 市销率
indicator.eps,
valuation.pe_ratio/indicator.inc_net_profit_year_on_year,
valuation.pb_ratio,
indicator.roa, # ROA
indicator.roe, # ROE
indicator.inc_revenue_year_on_year
).filter(
valuation.code.in_(pool))
df = get_fundamentals(q, fdate)
df.columns=['code','circulating_market_cap','pe_ratio','ps_ratio','eps','peg','pb_ratio','roa','roe','inc_revenue_year_on_year']
df = df[df['pe_ratio']>0]
df = df[df['ps_ratio']>0]
df = df[df['eps']>0]
df = df[df['peg']>0]
df = df[df['pb_ratio']>0]
df = df[df['roa']>0]
df = df[df['roe']>0]
df = df[df['inc_revenue_year_on_year']>0]
#调整排序
df['eps'] = 1/df['eps']
df['roa'] = 1/df['roa']
df['roe'] = 1/df['roe']
df['inc_revenue_year_on_year'] = 1/df['inc_revenue_year_on_year']
#print(df)
return df
#获取股票池的组合收益
def ret_se_1(sl,start_date=fdate,end_date=e_date):
#得到股票的历史价格数据
df = get_price(sl,start_date=start_date,end_date=end_date,fields=['close']).close
df = df.dropna(axis=1)
#print(df.head(3))
#相当于昨天的百分比变化
pct = df.pct_change()+1
pct.iloc[0,:] = 1
#pct = pct.dropna(axis=0)
#累积相乘得到总收益的变化情况
#df1 = pct.cumprod()
#等权重平均收益结果
se1 = pct.cumsum(axis=1).iloc[:,-1]/pct.shape[1]
return se1
#获取股票池的组合收益(市值加权的方式)
def ret_se(sl,start_date=fdate,end_date=e_date):
#得到股票的历史价格数据
df = get_price(sl,start_date=start_date,end_date=end_date,fields=['close']).close
df = df.dropna(axis=1)
#获取列表中的股票流通市值对数值
df_mkt = get_fundamentals(query(valuation.code,valuation.circulating_market_cap).filter(valuation.code.in_(df.columns)))
df_mkt.index = df_mkt['code'].values
fact_se =pd.Series(df_mkt['circulating_market_cap'].values,index = df_mkt['code'].values)
fact_se = np.log(fact_se)
#print(fact_se)
#相当于昨天的百分比变化
pct = df.pct_change()+1
pct.iloc[0,:] = 1
#df1 = pct.cumprod()
#等权重平均收益结果
#按权重的方式计算
se1 = (pct*fact_se).cumsum(axis=1).iloc[:,-1]/sum(fact_se)
return se1
#获取因子值,进行排序
pool = get_index_stocks(pool_index)
df = get_df(pool,fdate=fdate)
df.index = df['code'].values
#将因子值进行排序,从小到大
#print(df)
df_d1 = df.sort_values(by=fact,axis=0)
#print(df_d1.head(3))
#step2 分组
part = list(df_d1.index)
a = len(df_d1)//5
part1 = list(df_d1.index)[:a]
part2 = list(df_d1.index)[a:2*a]
part3 = list(df_d1.index)[2*a:-2*a]
part4 = list(df_d1.index)[-2*a:-a]
part5 = list(df_d1.index)[-a:]
#step3 计算收益
se = ret_se(part)
se1 = ret_se(part1)
se2 = ret_se(part2)
se3 = ret_se(part3)
se4 = ret_se(part4)
se5 = ret_se(part5)
return se,se1,se2,se3,se4,se5
#数据组拼接
def fact_return_df(fact,l_all):
l1 = l_all[:-1]
l2 = l_all[1:]
date_list = list(zip(l1,l2))
num = 1
for i,j in date_list:
se,se1,se2,se3,se4,se5 = get_fact_ret(fact,fdate=i,e_date=j)
if num == 1:
#se_list = [ for i in se_list]
df_all_1 = pd.concat([se,se1,se2,se3,se4,se5],axis=1)
df_all_1.columns = ['benchmark','part1','part2','part3','part4','part5']
#df_all_1.ix[0,:] = 1
num = 0
#print(df_all_1)
else:
df_all_2 = pd.concat([se,se1,se2,se3,se4,se5],axis=1)
df_all_2.columns = ['benchmark','part1','part2','part3','part4','part5']
#df_all_2.ix[0,:] = 1
#将各个月份的收益拼接为大表
df_all_1 = pd.concat([df_all_1,df_all_2])
#print(df_all_1)
df_all_1 = df_all_1.drop_duplicates()
return df_all_1.cumprod()
#获取时间段内的月初首个交易日日期
#获取每个月的第一个交易日日期
'''
def date_list(start,end):
df_date = pd.read_csv('df_date.csv')
df_1=df_date[(df_date['dt_list']>=start) & (df_date['dt_list']<=end) ]
df_2 = df_1.drop_duplicates(['year','month'])
l_3 = [i for i in df_2.dt_list.values]
return l_3
'''
#每天进行组合调整
def date_list(start,end):
l = get_price('000001.XSHG',start_date=start,end_date=end)
return list(l.index)
'''
多空组合收益部分内容(折线图)
'''
#输入起止日期
l_date=date_list('2017-7-6','2018-7-6')
#输入目标因子进行分组测试
fact_list = ['circulating_market_cap','pe_ratio','ps_ratio','eps','peg','pb_ratio','roa','roe','inc_revenue_year_on_year']
fact_se = []
for fact in fact_list:
df = fact_return_df(fact,l_date)
print('准备计算 %s 因子累计收益'%fact)
#做多第一组,做空第五组(从小到大排序)
se_long_part1 = df['part1']
se_short_part5 = 1+(1-df['part5'])
se = se_short_part5*0.5+se_long_part1*0.5
#se = df['part5']-df['part1']
#print(se)
fact_se.append(se)
fact_df = pd.concat(fact_se,axis=1)
name_list = ['市值','市盈率','市销率','1/每股收益','peg','市净率','1/roa','1/roe','1/营收增长']
fact_df.columns = name_list
fact_df
准备计算 circulating_market_cap 因子累计收益 准备计算 pe_ratio 因子累计收益 准备计算 ps_ratio 因子累计收益 准备计算 eps 因子累计收益 准备计算 peg 因子累计收益 准备计算 pb_ratio 因子累计收益 准备计算 roa 因子累计收益 准备计算 roe 因子累计收益 准备计算 inc_revenue_year_on_year 因子累计收益
| 市值 | 市盈率 | 市销率 | 1/每股收益 | peg | 市净率 | 1/roa | 1/roe | 1/营收增长 | |
|---|---|---|---|---|---|---|---|---|---|
| 2017-07-06 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 2017-07-07 | 1.007 | 0.992 | 0.999 | 0.991 | 1.006 | 1.005 | 0.995 | 0.990 | 1.007 |
| 2017-07-10 | 1.004 | 0.992 | 1.002 | 0.985 | 1.011 | 1.012 | 0.990 | 0.986 | 1.009 |
| 2017-07-11 | 0.991 | 1.005 | 1.003 | 0.999 | 1.005 | 1.014 | 0.989 | 0.996 | 1.001 |
| 2017-07-12 | 0.995 | 1.003 | 1.002 | 0.997 | 1.009 | 1.015 | 0.989 | 0.994 | 1.004 |
| 2017-07-13 | 0.992 | 1.005 | 1.007 | 0.994 | 1.008 | 1.025 | 0.979 | 0.988 | 1.000 |
| 2017-07-14 | 0.987 | 1.010 | 1.008 | 0.998 | 1.010 | 1.029 | 0.977 | 0.991 | 0.996 |
| 2017-07-17 | 0.970 | 1.019 | 1.013 | 1.004 | 1.010 | 1.040 | 0.973 | 0.995 | 0.990 |
| 2017-07-18 | 0.974 | 1.012 | 1.017 | 0.998 | 1.019 | 1.042 | 0.971 | 0.989 | 0.997 |
| 2017-07-19 | 0.978 | 1.002 | 1.012 | 0.990 | 1.030 | 1.045 | 0.970 | 0.981 | 1.007 |
| 2017-07-20 | 0.976 | 1.005 | 1.009 | 0.993 | 1.027 | 1.040 | 0.973 | 0.986 | 1.006 |
| 2017-07-21 | 0.978 | 1.005 | 1.012 | 0.993 | 1.030 | 1.038 | 0.976 | 0.988 | 1.008 |
| 2017-07-24 | 0.976 | 1.004 | 1.010 | 0.989 | 1.028 | 1.038 | 0.974 | 0.986 | 1.005 |
| 2017-07-25 | 0.978 | 1.003 | 1.011 | 0.987 | 1.028 | 1.038 | 0.975 | 0.985 | 1.006 |
| 2017-07-26 | 0.977 | 0.999 | 1.012 | 0.978 | 1.028 | 1.043 | 0.970 | 0.976 | 1.008 |
| 2017-07-27 | 0.984 | 0.995 | 1.001 | 0.975 | 1.018 | 1.035 | 0.975 | 0.973 | 1.006 |
| 2017-07-28 | 0.982 | 0.994 | 1.000 | 0.975 | 1.024 | 1.030 | 0.977 | 0.975 | 1.008 |
| 2017-07-31 | 0.985 | 0.982 | 1.007 | 0.962 | 1.040 | 1.037 | 0.974 | 0.964 | 1.022 |
| 2017-08-01 | 0.980 | 0.987 | 1.008 | 0.966 | 1.034 | 1.039 | 0.969 | 0.966 | 1.016 |
| 2017-08-02 | 0.978 | 0.982 | 1.001 | 0.962 | 1.035 | 1.040 | 0.967 | 0.962 | 1.018 |
| 2017-08-03 | 0.984 | 0.974 | 1.003 | 0.952 | 1.042 | 1.043 | 0.965 | 0.955 | 1.023 |
| 2017-08-04 | 0.981 | 0.976 | 1.011 | 0.950 | 1.040 | 1.048 | 0.962 | 0.952 | 1.023 |
| 2017-08-07 | 0.982 | 0.971 | 1.010 | 0.948 | 1.047 | 1.043 | 0.967 | 0.952 | 1.028 |
| 2017-08-08 | 0.986 | 0.967 | 1.006 | 0.942 | 1.042 | 1.042 | 0.966 | 0.946 | 1.029 |
| 2017-08-09 | 0.986 | 0.961 | 1.005 | 0.947 | 1.047 | 1.034 | 0.977 | 0.954 | 1.033 |
| 2017-08-10 | 0.983 | 0.966 | 1.001 | 0.953 | 1.036 | 1.030 | 0.980 | 0.959 | 1.027 |
| 2017-08-11 | 0.984 | 0.974 | 0.994 | 0.963 | 1.019 | 1.019 | 0.987 | 0.970 | 1.016 |
| 2017-08-14 | 0.989 | 0.964 | 0.985 | 0.960 | 1.020 | 1.011 | 0.990 | 0.968 | 1.024 |
| 2017-08-15 | 0.988 | 0.967 | 0.982 | 0.958 | 1.020 | 1.010 | 0.992 | 0.969 | 1.023 |
| 2017-08-16 | 0.991 | 0.968 | 0.984 | 0.958 | 1.018 | 1.010 | 0.991 | 0.969 | 1.022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-05-25 | 0.952 | 0.963 | 0.875 | 1.102 | 1.041 | 0.899 | 1.149 | 1.148 | 1.094 |
| 2018-05-28 | 0.946 | 0.958 | 0.865 | 1.115 | 1.039 | 0.885 | 1.162 | 1.164 | 1.096 |
| 2018-05-29 | 0.947 | 0.965 | 0.876 | 1.112 | 1.040 | 0.896 | 1.157 | 1.160 | 1.089 |
| 2018-05-30 | 0.945 | 0.963 | 0.874 | 1.114 | 1.036 | 0.895 | 1.161 | 1.166 | 1.086 |
| 2018-05-31 | 0.940 | 0.959 | 0.868 | 1.125 | 1.037 | 0.882 | 1.174 | 1.178 | 1.090 |
| 2018-06-01 | 0.943 | 0.971 | 0.876 | 1.119 | 1.043 | 0.894 | 1.165 | 1.168 | 1.088 |
| 2018-06-04 | 0.932 | 0.978 | 0.874 | 1.132 | 1.044 | 0.893 | 1.168 | 1.176 | 1.084 |
| 2018-06-05 | 0.932 | 0.969 | 0.865 | 1.138 | 1.041 | 0.877 | 1.183 | 1.188 | 1.090 |
| 2018-06-06 | 0.932 | 0.964 | 0.862 | 1.138 | 1.041 | 0.872 | 1.189 | 1.191 | 1.092 |
| 2018-06-07 | 0.932 | 0.971 | 0.862 | 1.139 | 1.048 | 0.876 | 1.188 | 1.188 | 1.089 |
| 2018-06-08 | 0.932 | 0.966 | 0.861 | 1.142 | 1.045 | 0.871 | 1.191 | 1.191 | 1.089 |
| 2018-06-11 | 0.927 | 0.975 | 0.866 | 1.143 | 1.054 | 0.877 | 1.185 | 1.187 | 1.088 |
| 2018-06-12 | 0.923 | 0.972 | 0.859 | 1.153 | 1.056 | 0.868 | 1.200 | 1.200 | 1.092 |
| 2018-06-13 | 0.920 | 0.979 | 0.866 | 1.153 | 1.059 | 0.876 | 1.194 | 1.196 | 1.089 |
| 2018-06-14 | 0.919 | 0.982 | 0.869 | 1.148 | 1.060 | 0.883 | 1.184 | 1.187 | 1.086 |
| 2018-06-15 | 0.914 | 0.991 | 0.877 | 1.148 | 1.066 | 0.893 | 1.174 | 1.182 | 1.082 |
| 2018-06-19 | 0.898 | 1.007 | 0.886 | 1.157 | 1.062 | 0.904 | 1.165 | 1.184 | 1.070 |
| 2018-06-20 | 0.902 | 1.000 | 0.877 | 1.158 | 1.061 | 0.891 | 1.172 | 1.191 | 1.076 |
| 2018-06-21 | 0.892 | 1.009 | 0.880 | 1.158 | 1.065 | 0.898 | 1.169 | 1.193 | 1.074 |
| 2018-06-22 | 0.897 | 1.008 | 0.875 | 1.158 | 1.068 | 0.893 | 1.173 | 1.197 | 1.078 |
| 2018-06-25 | 0.899 | 0.999 | 0.866 | 1.159 | 1.056 | 0.886 | 1.181 | 1.205 | 1.083 |
| 2018-06-26 | 0.905 | 0.986 | 0.861 | 1.152 | 1.045 | 0.883 | 1.183 | 1.202 | 1.085 |
| 2018-06-27 | 0.913 | 0.988 | 0.872 | 1.138 | 1.041 | 0.898 | 1.172 | 1.187 | 1.080 |
| 2018-06-28 | 0.915 | 0.984 | 0.873 | 1.129 | 1.036 | 0.903 | 1.165 | 1.177 | 1.077 |
| 2018-06-29 | 0.912 | 0.979 | 0.864 | 1.137 | 1.038 | 0.892 | 1.176 | 1.190 | 1.085 |
| 2018-07-02 | 0.915 | 0.962 | 0.857 | 1.130 | 1.028 | 0.884 | 1.182 | 1.189 | 1.088 |
| 2018-07-03 | 0.922 | 0.967 | 0.863 | 1.122 | 1.029 | 0.896 | 1.171 | 1.177 | 1.088 |
| 2018-07-04 | 0.919 | 0.969 | 0.869 | 1.119 | 1.025 | 0.904 | 1.167 | 1.172 | 1.084 |
| 2018-07-05 | 0.906 | 0.978 | 0.875 | 1.125 | 1.030 | 0.912 | 1.159 | 1.170 | 1.079 |
| 2018-07-06 | 0.905 | 0.977 | 0.871 | 1.130 | 1.029 | 0.910 | 1.162 | 1.177 | 1.079 |
246 rows × 9 columns
fact_df.plot(figsize=(15,10))
<matplotlib.axes._subplots.AxesSubplot at 0x7f59d1021978>

#计算多空因子组合收益
end_date = '2018-7-6'
date_week = date_list('2018-6-29',end_date)
date_mouth = date_list('2018-6-6',end_date)
date_halfyear = date_list('2018-1-6',end_date)
date_year = date_list('2017-7-6',end_date)
date_3year = date_list('2015-7-6',end_date)
#输入目标因子进行分组测试
fact_list = ['circulating_market_cap','pe_ratio','ps_ratio','eps','peg','pb_ratio','roa','roe','inc_revenue_year_on_year']
fact_fin = []
for i in [date_week,date_mouth,date_halfyear,date_year,date_3year]:
fact_se = []
for fact in fact_list:
df = fact_return_df(fact,i)
#print(df)
se_long_part1 = df['part1']
se_short_part5 = 1+(1-df['part5'])
se = se_short_part5*0.5+se_long_part1*0.5
#se = df['part5']-df['part1']
fact_se.append(se)
fact_df = pd.concat(fact_se,axis=1)
name_list = ['市值','市盈率','市销率','1/每股收益','peg','市净率','1/roa','1/roe','1/营收增长']
fact_df.columns = name_list
print('当前时间周期因子计算完毕')
fact_fin.append(fact_df)
df_tab = pd.DataFrame(index =['市值','市盈率','市销率','1/每股收益','peg','市净率','1/roa','1/roe','1/营收增长'],columns=['近一周','近一个月','近半年','近一年','近三年'])
df_tab['近一周'] = 100*(fact_fin[0].iloc[-1,:]-1)
df_tab['近一个月'] = 100*(fact_fin[1].iloc[-1,:]-1)
df_tab['近半年'] = 100*(fact_fin[2].iloc[-1,:]-1)
df_tab['近一年'] = 100*(fact_fin[3].iloc[-1,:]-1)
df_tab['近三年'] = 100*(fact_fin[4].iloc[-1,:]-1)
df_tab
当前时间周期因子计算完毕 当前时间周期因子计算完毕 当前时间周期因子计算完毕 当前时间周期因子计算完毕 当前时间周期因子计算完毕
| 近一周 | 近一个月 | 近半年 | 近一年 | 近三年 | |
|---|---|---|---|---|---|
| 市值 | -1.062 | -3.224 | -4.113 | -9.481 | NaN |
| 市盈率 | -0.304 | 0.814 | -3.074 | -2.302 | NaN |
| 市销率 | 0.111 | -0.575 | -8.147 | -12.910 | NaN |
| 1/每股收益 | -0.199 | 0.587 | 7.130 | 13.027 | NaN |
| peg | -0.738 | -0.609 | -4.043 | 2.890 | NaN |
| 市净率 | 1.207 | 2.029 | -5.570 | -9.049 | NaN |
| 1/roa | -0.685 | -0.566 | 7.875 | 16.174 | NaN |
| 1/roe | -0.348 | 0.805 | 7.778 | 17.679 | NaN |
| 1/营收增长 | -0.296 | -0.301 | 1.478 | 7.910 | NaN |
df_tab.sort_values(by='近半年',ascending=0)
| 近一周 | 近一个月 | 近半年 | 近一年 | 近三年 | |
|---|---|---|---|---|---|
| 1/roa | -0.685 | -0.566 | 7.875 | 16.174 | 39.006 |
| 1/roe | -0.348 | 0.805 | 7.778 | 17.679 | 18.978 |
| 1/每股收益 | -0.199 | 0.587 | 7.130 | 13.027 | 21.074 |
| 1/营收增长 | -0.296 | -0.301 | 1.478 | 7.910 | 19.023 |
| 市盈率 | -0.304 | 0.814 | -3.074 | -2.302 | 11.289 |
| peg | -0.738 | -0.609 | -4.043 | 2.890 | 22.716 |
| 市值 | -1.062 | -3.224 | -4.113 | -9.481 | 12.744 |
| 市净率 | 1.207 | 2.029 | -5.570 | -9.049 | -9.628 |
| 市销率 | 0.111 | -0.575 | -8.147 | -12.910 | -4.164 |
df_tab = df_tab.sort_values(by='近一周',ascending=0)
df_tab['近一周'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59b4be1a20>

df_tab = df_tab.sort_values(by='近一个月',ascending=0)
df_tab['近一个月'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59b4c00518>

df_tab = df_tab.sort_values(by='近半年',ascending=0)
df_tab['近半年'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59aea00940>

df_tab = df_tab.sort_values(by='近一年',ascending=0)
df_tab['近一年'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59adffada0>

df_tab = df_tab.sort_values(by='近三年',ascending=0)
df_tab['近三年'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f59ae882cc0>


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程