写本篇文章的目的是解决我上一篇文章《【机器学习的简单套用】轮动选股模型》一个遗留小问题:如何通过统计逻辑解决因子筛选问题?
上一篇文章link: https://www.joinquant.com/view/community/detail/50d78ca39cf9e6cdec7c7126c75580a8?type=1
PS: 小弟今年大三金融,以下是小弟刷了一些报告后自己整合出来的因子测试框架逻辑(感觉print出来的结果怪怪的),如果在逻辑和编程上有错误,还请各位大佬多多指出,多多交流!!
欢迎各种Q,能加我微信交流就最好了哈哈~(Howard董先森: dhl19988882)
参考国盛证券: 《20190116-国盛证券-多因子系列之一:多因子选股体系的思考》 page 21
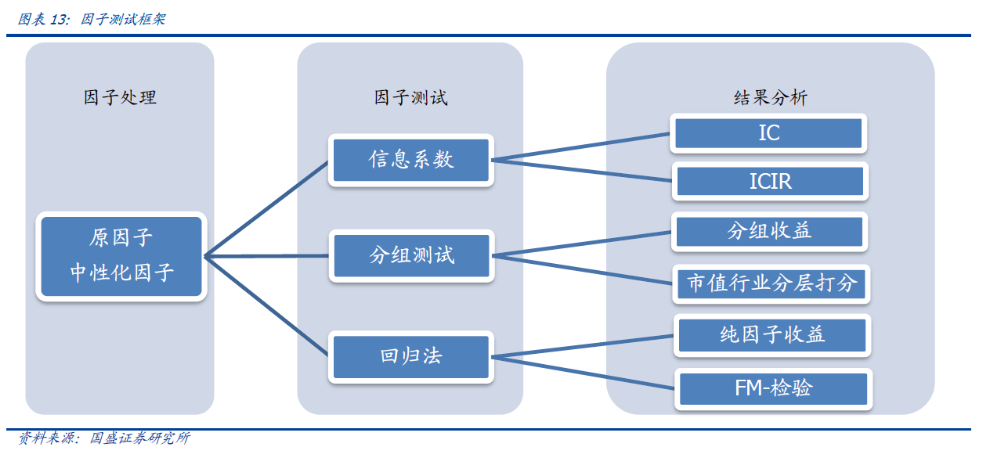
公式来源:国盛证券: 《20190116-国盛证券-多因子系列之一:多因子选股体系的思考》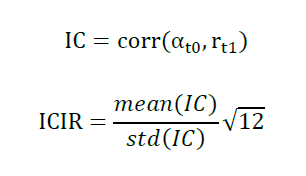
IC: 某时点 T0 某因子在全部股票的暴露值与其下期 (T0-T1) 回报的截面相关系数
Rank IC: 某时点 T0 某因子在全部股票暴露值排名与其下期 (T0-T1) 回报排名的截面相关系数
IC 和 Rank IC: 判断因子对下一期标的收益率的预测能力,线性框架下,IC越高,因子预测股票收益能力越强
IR 和 Rank IR: 判断预测能力的稳定性情况
自变量X:T0时间点因子暴露(因子值大小)
因变量Y: T0-T1时间段股票收益率
回归算法(RLM):Robust Regression 稳健回归常见于单因子回归测试,RLM 通过迭代的赋权回归可以有效的减小OLS 最小二乘法中异常值(outliers)对参数估计结果有效性和稳定性的影响。(来自:光大证券:《20170501-光大证券-多因子系列报告之三:多因子组合光大Alpha_1.0》, page 5)
因子收益率: 因子暴露X对股票收益率Y的回归后出来的,回归系数
因子收益率T值: 每个因子单因子回归后的T值,衡量显著性大小
衡量因子区分度, 单调性越强的因子,在分层回溯的情况下,对股票的区分度越好
常见做法是将股票池中按照因子的大小等分组(我的模型是分为10组)构建投资组合,观察十个投资组合的表现是否依照因子值呈现单调性
灵感来自光大证券:《20170501-光大证券-多因子系列报告之三:多因子组合光大Alpha_1.0》 page 6
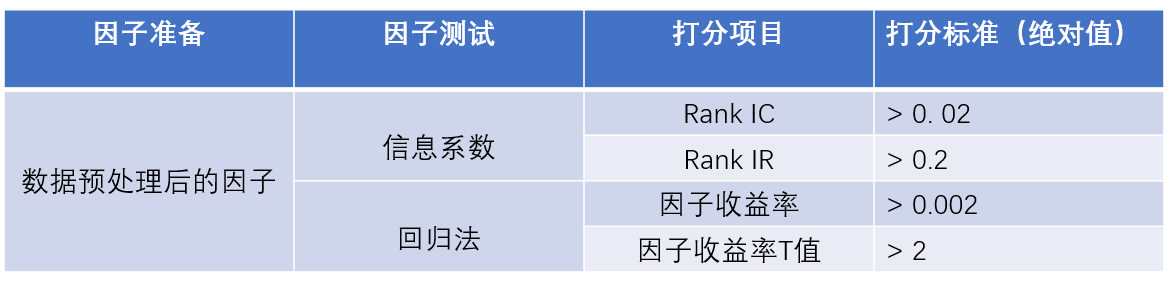
由于单调性指标提取时间很漫长,本文先通过回归法和信息系数法,来对因子进行初步筛选,然后再用分层回测方法看检测单个因子的单调性
下面说一下对于这个因子筛选框架的待解决问题和对于该问题的一些思考:
有些因子在样本时间段内有很好的表现,可能在别的时间段就没有这种表现,那么这种 “泛化” 问题如何解决?能不能用半衰期 (先计算T0因子暴露对T0-T1、T1-T2……各种滞后时间周期的标的收益率的IC值,然后记录IC减少到初始值的一半所用时间为半衰期), 用半衰期的各种统计指标如平均值,来衡量待测因子的预测有效性?
对于筛选掉(剔除掉)的因子,难道它们对于以后的标的收益率的预测就没有贡献吗?能不能通过降维来达到 “筛选” 的目的?
上网查了一下知乎,发现有一篇讲因子测试的知乎推文讲的蛮好的(知乎求职广告打得很溜,学习了):https://zhuanlan.zhihu.com/p/31733061
Fama和Barra两个体系下的因子指标定义or介绍(主要是两位大佬对因子暴露理解不一样,其他个人认为还好),链接: https://henix.github.io/feeds/zhuanlan.factor-investing/2018-08-05-41339443.html
IC相关介绍,请看:《关于多因子模型的“IC信息系数”那些事》
https://zhuanlan.zhihu.com/p/24616859
上一篇文章link: https://www.joinquant.com/view/community/detail/50d78ca39cf9e6cdec7c7126c75580a8?type=1
PS: 小弟今年大三金融,以下是小弟刷了一些报告后自己整合出来的因子测试框架逻辑(感觉print出来的结果怪怪的),如果在逻辑和编程上有错误,还请各位大佬多多指出,多多交流!!
欢迎各种Q,能加我微信交流就最好了哈哈~(Howard董先森: dhl19988882)
网盘资料:包含先处理好的数据,以及一些研报等参考资料 链接:https://pan.baidu.com/s/1hL77LHW_-ot9XL3Ac8Ldtw 提取码:vzi5
参考国盛证券: 《20190116-国盛证券-多因子系列之一:多因子选股体系的思考》 page 21
公式来源:国盛证券: 《20190116-国盛证券-多因子系列之一:多因子选股体系的思考》
IC: 某时点 T0 某因子在全部股票的暴露值与其下期 (T0-T1) 回报的截面相关系数
Rank IC: 某时点 T0 某因子在全部股票暴露值排名与其下期 (T0-T1) 回报排名的截面相关系数
IC 和 Rank IC: 判断因子对下一期标的收益率的预测能力,线性框架下,IC越高,因子预测股票收益能力越强
IR 和 Rank IR: 判断预测能力的稳定性情况
自变量X:T0时间点因子暴露(因子值大小)
因变量Y: T0-T1时间段股票收益率
回归算法(RLM):Robust Regression 稳健回归常见于单因子回归测试,RLM 通过迭代的赋权回归可以有效的减小OLS 最小二乘法中异常值(outliers)对参数估计结果有效性和稳定性的影响。(来自:光大证券:《20170501-光大证券-多因子系列报告之三:多因子组合光大Alpha_1.0》, page 5)
因子收益率: 因子暴露X对股票收益率Y的回归后出来的,回归系数
因子收益率T值: 每个因子单因子回归后的T值,衡量显著性大小
衡量因子区分度, 单调性越强的因子,在分层回溯的情况下,对股票的区分度越好
常见做法是将股票池中按照因子的大小等分组(我的模型是分为10组)构建投资组合,观察十个投资组合的表现是否依照因子值呈现单调性
灵感来自光大证券:《20170501-光大证券-多因子系列报告之三:多因子组合光大Alpha_1.0》 page 6
由于单调性指标提取时间很漫长,本文先通过回归法和信息系数法,来对因子进行初步筛选,然后再用分层回测方法看检测单个因子的单调性
下面是我自己包装好的一些框架函数,大家有需要就用,replicate时给我credit就好~
第一行是我之前做的套用机器学习轮动选股的框架,link: https://www.joinquant.com/view/community/detail/50d78ca39cf9e6cdec7c7126c75580a8?type=1
# 【基础框架函数】轮动框架 v9
# coding: utf-8
# 制作人:Howard董先森, wechat:dhl19988882,e-mail: 16hldong.stu.edu.cn
# copy并分享的时候记得给小弟一下credit就好~
import warnings
warnings.filterwarnings("ignore")
'''
导入函数库
'''
import pandas as pd
import numpy as np
import time
import datetime
import statsmodels.api as sm
import pickle
import warnings
from itertools import combinations
import itertools
from jqfactor import get_factor_values
from jqdata import *
from jqfactor import neutralize
from jqfactor import standardlize
from jqfactor import winsorize
from jqfactor import neutralize
import calendar
from scipy import stats
import statsmodels.api as sm
from statsmodels import regression
import csv
from six import StringIO
from jqlib.technical_analysis import *
#导入pca
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.grid_search import GridSearchCV
from sklearn import metrics
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.pyplot as plt
from jqfactor import neutralize
'''
普通工具
'''
# 多重列表分解函数
def splitlist(b):
alist = []
a = 0
for sublist in b:
try: #用try来判断是列表中的元素是不是可迭代的,可以迭代的继续迭代
for i in sublist:
alist.append (i)
except TypeError: #不能迭代的就是直接取出放入alist
alist.append(sublist)
for i in alist:
if type(i) == type([]):#判断是否还有列表
a =+ 1
break
if a==1:
return printlist(alist) #还有列表,进行递归
if a==0:
return alist
#PCA降维
def pca_analysis(data,n_components='mle'):
index = data.index
model = PCA(n_components=n_components)
model.fit(data)
data_pca = model.transform(data)
df = pd.DataFrame(data_pca,index=index)
return df
'''
数据准备
'''
# 指数池子清洗函数
def get_stock_code(index, date):
# 指数池子提取
stockList = get_index_stocks(index , date=date)
#剔除ST股
st_data=get_extras('is_st',stockList, count = 1,end_date = start_date)
stockList = [stock for stock in stockList if not st_data[stock][0]]
#剔除停牌、新股及退市股票
stockList=delect_stop(stockList,date,date)
return stockList
# 因子排列组合函数
def factor_combins(data):
'''
输入:
格式为Dataframe
data
输出:
格式为list
所有因子的排列组合
'''
# 排列组合
factor_combins =[]
for i in range(len(data.columns)+1):
combins = [c for c in combinations((data.columns),i)]
factor_combins.append(combins)
# 剔除排列组合中空的情况
factor_combins.pop(0)
# 多层列表展开平铺成一层
factor_list = list(itertools.chain(*factor_combins))
return factor_list
#获取时间为date的全部因子数据
def get_factor_data(stock_list,date):
data=pd.DataFrame(index=stock_list)
# 第一波因子提取
q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(stock_list))
df = get_fundamentals(q, date)
df['market_cap']=df['market_cap']*100000000
df.index = df['code']
del df['code'],df['id']
# 第二波因子提取
factor_data=get_factor_values(stock_list,['roe_ttm','roa_ttm','total_asset_turnover_rate',\
'net_operate_cash_flow_ttm','net_profit_ttm',\
'cash_to_current_liability','current_ratio',\
'gross_income_ratio','non_recurring_gain_loss',\
'operating_revenue_ttm','net_profit_growth_rate'],end_date=date,count=1)
# 第二波因子转dataframe格式
factor=pd.DataFrame(index=stock_list)
for i in factor_data.keys():
factor[i]=factor_data[i].iloc[0,:]
#合并得大表
df=pd.concat([df,factor],axis=1)
# 有些因子没有的,用别的近似代替
df.fillna(0, inplace = True)
# profitability 因子
# proft/net revenue
data['gross_profit_margin'] = df['gross_profit_margin']
data['net_profit_margin'] = df['net_profit_margin']
data['operating_profit_margin'] = df['operating_profit']/(df['total_operating_revenue']-df['total_operating_cost'])
data['pretax_margin'] = (df['net_profit'] + df['income_tax_expense'])/(df['total_operating_revenue']-df['total_operating_cost'])
# profit/capital
data['ROA'] = df['roa']
data['EBIT_OA'] = df['operating_profit']/df['total_assets']
data['ROTC'] = df['operating_profit']/(df['total_owner_equities'] + df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])
data['ROE'] = df['roe']
# Others
data['inc_total_revenue_annual'] = df['inc_total_revenue_annual']
# Activity 因子
# inventory
data['inventory_turnover'] = df['operating_cost']/df['inventories']
data['inventory_processing_period'] = 365/data['inventory_turnover']
# account receivables
data['receivables_turnover'] =df['total_operating_revenue']/df['account_receivable']
data['receivables_collection_period'] = 365/data['receivables_turnover']
# activity cycle
data['operating_cycle'] = data['receivables_collection_period']+data['inventory_processing_period']
# Other turnovers
data['total_asset_turnover'] = df['operating_revenue']/df['total_assets']
data['fixed_assets_turnover'] = df['operating_revenue']/df['fixed_assets']
data['working_capital_turnover'] = df['operating_revenue']/(df['total_current_assets']-df['total_current_liability'])
# Liquidity 因子
data['current_ratio'] =df['current_ratio']
data['quick_ratio'] =(df['total_current_assets']-df['inventories'])/df['total_current_liability']
data['cash_ratio'] = (df['cash_equivalents']+df['proxy_secu_proceeds'])/df['total_current_liability']
# leverage
data['debt_to_equity'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_owner_equities']
data['debt_to_capital'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/(df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable']+df['total_owner_equities'])
data['debt_to_assets'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_assets']
data['financial_leverage'] = df['total_assets'] / df['total_owner_equities']
# Valuation 因子
# Price
data['EP']=df['net_profit_ttm']/df['market_cap']
data['PB']=df['pb_ratio']
data['PS']=df['ps_ratio']
data['P_CF']=df['market_cap']/df['net_operate_cash_flow']
# 技术面 因子
# 下面技术因子来自于西交大元老师量化小组的SVM研究,report,https://www.joinquant.com/view/community/detail/15371
stock = stock_list
#个股60个月收益与上证综指回归的截距项与BETA
stock_close=get_price(stock, count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
SZ_close=get_price('000001.XSHG', count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']
stock_pchg=stock_close.pct_change().iloc[1:]
SZ_pchg=SZ_close.pct_change().iloc[1:]
beta=[]
stockalpha=[]
for i in stock:
temp_beta, temp_stockalpha = stats.linregress(SZ_pchg, stock_pchg[i])[:2]
beta.append(temp_beta)
stockalpha.append(temp_stockalpha)
#此处alpha beta为list
data['alpha']=stockalpha
data['beta']=beta
#动量
data['return_1m']=stock_close.iloc[-1]/stock_close.iloc[-20]-1
data['return_3m']=stock_close.iloc[-1]/stock_close.iloc[-60]-1
data['return_6m']=stock_close.iloc[-1]/stock_close.iloc[-120]-1
data['return_12m']=stock_close.iloc[-1]/stock_close.iloc[-240]-1
#取换手率数据
data_turnover_ratio=pd.DataFrame()
data_turnover_ratio['code']=stock
trade_days=list(get_trade_days(end_date=date, count=240*2))
for i in trade_days:
q = query(valuation.code,valuation.turnover_ratio).filter(valuation.code.in_(stock))
temp = get_fundamentals(q, i)
data_turnover_ratio=pd.merge(data_turnover_ratio, temp,how='left',on='code')
data_turnover_ratio=data_turnover_ratio.rename(columns={'turnover_ratio':i})
data_turnover_ratio=data_turnover_ratio.set_index('code').T
#个股个股最近N个月内用每日换手率乘以每日收益率求算术平均值
data['wgt_return_1m']=mean(stock_pchg.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['wgt_return_3m']=mean(stock_pchg.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['wgt_return_6m']=mean(stock_pchg.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['wgt_return_12m']=mean(stock_pchg.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#个股个股最近N个月内用每日换手率乘以函数exp(-x_i/N/4)再乘以每日收益率求算术平均值
temp_data=pd.DataFrame(index=data_turnover_ratio[-240:].index,columns=stock)
temp=[]
for i in range(240):
if i/20<1:
temp.append(exp(-i/1/4))
elif i/20<3:
temp.append(exp(-i/3/4))
elif i/20<6:
temp.append(exp(-i/6/4))
elif i/20<12:
temp.append(exp(-i/12/4))
temp.reverse()
for i in stock:
temp_data[i]=temp
data['exp_wgt_return_1m']=mean(stock_pchg.iloc[-20:]*temp_data.iloc[-20:]*data_turnover_ratio.iloc[-20:])
data['exp_wgt_return_3m']=mean(stock_pchg.iloc[-60:]*temp_data.iloc[-60:]*data_turnover_ratio.iloc[-60:])
data['exp_wgt_return_6m']=mean(stock_pchg.iloc[-120:]*temp_data.iloc[-120:]*data_turnover_ratio.iloc[-120:])
data['exp_wgt_return_12m']=mean(stock_pchg.iloc[-240:]*temp_data.iloc[-240:]*data_turnover_ratio.iloc[-240:])
#波动率
data['std_1m']=stock_pchg.iloc[-20:].std()
data['std_3m']=stock_pchg.iloc[-60:].std()
data['std_6m']=stock_pchg.iloc[-120:].std()
data['std_12m']=stock_pchg.iloc[-240:].std()
#股价
data['ln_price']=np.log(stock_close.iloc[-1])
#换手率
data['turn_1m']=mean(data_turnover_ratio.iloc[-20:])
data['turn_3m']=mean(data_turnover_ratio.iloc[-60:])
data['turn_6m']=mean(data_turnover_ratio.iloc[-120:])
data['turn_12m']=mean(data_turnover_ratio.iloc[-240:])
data['bias_turn_1m']=mean(data_turnover_ratio.iloc[-20:])/mean(data_turnover_ratio)-1
data['bias_turn_3m']=mean(data_turnover_ratio.iloc[-60:])/mean(data_turnover_ratio)-1
data['bias_turn_6m']=mean(data_turnover_ratio.iloc[-120:])/mean(data_turnover_ratio)-1
data['bias_turn_12m']=mean(data_turnover_ratio.iloc[-240:])/mean(data_turnover_ratio)-1
#技术指标
data['PSY']=pd.Series(PSY(stock, date, timeperiod=20))
data['RSI']=pd.Series(RSI(stock, date, N1=20))
data['BIAS']=pd.Series(BIAS(stock,date, N1=20)[0])
dif,dea,macd=MACD(stock, date, SHORT = 10, LONG = 30, MID = 15)
data['DIF']=pd.Series(dif)
data['DEA']=pd.Series(dea)
data['MACD']=pd.Series(macd)
# 去inf
a = np.array(data)
where_are_inf = np.isinf(a)
a[where_are_inf] = nan
factor_data =pd.DataFrame(a, index=data.index, columns = data.columns)
return factor_data
# 行业代码获取函数
def get_industry(date,industry_old_code,industry_new_code):
'''
输入:
date: str, 时间点
industry_old_code: list, 旧的行业代码
industry_new_code: list, 新的行业代码
输出:
list, 行业代码
'''
#获取行业因子数据
if datetime.datetime.strptime(date,"%Y-%m-%d").date()<datetime.date(2014,2,21):
industry_code=industry_old_code
else:
industry_code=industry_new_code
len(industry_code)
return industry_code
#取股票对应行业
def get_industry_name(i_Constituent_Stocks, value):
return [k for k, v in i_Constituent_Stocks.items() if value in v]
#缺失值处理
def replace_nan_indu(factor_data, stockList, industry_code, date):
'''
输入:
factor_data: dataframe, 有缺失值的因子值
stockList: list, 指数池子所有标的
industry_code: list, 行业代码
date: str, 时间点
输出:
格式为list
所有因子的排列组合
'''
# 创建一个字典,用于储存每个行业对应的成分股(行业标的和指数标的取交集)
i_Constituent_Stocks={}
# 创建一个行业因子数据表格,待填因子数据(暂定为均值)
ind_factor_data = pd.DataFrame(index=industry_code,columns=factor_data.columns)
# 遍历所有行业
for i in industry_code:
# 获取单个行业所有的标的
stk_code = get_industry_stocks(i, date)
# 储存每个行业对应的所有成分股到刚刚创建的字典中(行业标的和指数标的取交集)
i_Constituent_Stocks[i] = list(set(stk_code).intersection(set(stockList)))
# 对于某个行业,根据提取出来的指数池子,把所有交集内的因子值取mean,赋值到行业因子值的表格上
ind_factor_data.loc[i]=mean(factor_data.loc[i_Constituent_Stocks[i],:])
# 对于行业值缺失的(行业标的和指数标的取交集),用所有行业的均值代替
for factor in ind_factor_data.columns:
# 提取行业缺失值所在的行业,并放到list去
null_industry=list(ind_factor_data.loc[pd.isnull(ind_factor_data[factor]),factor].keys())
# 遍历行业缺失值所在的行业
for i in null_industry:
# 所有行业的均值代替,行业缺失的数值
ind_factor_data.loc[i,factor]=mean(ind_factor_data[factor])
# 提取含缺失值的标的
null_stock=list(factor_data.loc[pd.isnull(factor_data[factor]),factor].keys())
# 用行业值(暂定均值)去填补,指数因子缺失值
for i in null_stock:
industry = get_industry_name(i_Constituent_Stocks, i)
if industry:
factor_data.loc[i, factor] = ind_factor_data.loc[industry[0], factor]
else:
factor_data.loc[i, factor] = mean(factor_data[factor])
return factor_data
#去除上市距beginDate不足1年且退市在endDate之后的股票
def delect_stop(stocks,beginDate,endDate,n=365):
stockList=[]
beginDate = datetime.datetime.strptime(beginDate, "%Y-%m-%d")
endDate = datetime.datetime.strptime(endDate, "%Y-%m-%d")
for stock in stocks:
start_date=get_security_info(stock).start_date
end_date=get_security_info(stock).end_date
if start_date<(beginDate-datetime.timedelta(days=n)).date() and end_date>endDate.date():
stockList.append(stock)
return stockList
# 获取预处理后的因子
def prepare_data(date,index):
'''
输入:
date: str, 时间点
index: 指数
输出:
data: 预备处理好的了dataframe
'''
# 指数清洗(剔除ST、退市、新上市不足三个月的标的)
stockList = get_stock_code(index, date)
# 获取数据
factor_data = get_factor_data(stockList, date)
# 数据预处理
# 缺失值处理
data = replace_nan_indu(factor_data, stockList, industry_code, date)
# 启动内置函数去极值
data = winsorize(data, qrange=[0.05,0.93], inclusive=True, inf2nan=True, axis=0)
# 启动内置函数标准化
data = standardlize(data, inf2nan=True, axis=0)
# 启动内置函数中性化,行业为'sw_l1'
data = neutralize(data, how=['sw_l1','market_cap'], date=date , axis=0)
return data
'''
时间准备
'''
# 时间管理函数
def time_handle(start_date, end_date, period, period_pre,index):
'''
输入:
start_date: 开始时间,str
end_date: 截至时间,str
period: 周期间隔,str(转换为周是'W',月'M',季度线'Q',五分钟'5min',12天'12D')
period_pre: 小周期间隔,str(为了提取第一个T0数据,作为辅助用途)
输出:
格式为dataframe
columns:
T0: T0时间点的集合
T1: T1时间点的集合
T2: T2时间点的集合
'''
# 设定转换周期 period_type 转换为周是'W',月'M',季度线'Q',五分钟'5min',12天'12D'
time = get_price(index ,start_date,end_date,'daily',fields=['close'])
# 记录每个周期中最后一个交易日
time['date']=time.index
# 进行转换,周线的每个变量都等于那一周中最后一个交易日的变量值
period_handle=time.resample(period,how='last')
period_handle['t1'] = period_handle['date']
# 创造超前数据T2
period_handle['t2']=period_handle['t1'].shift(-1)
# 重新设定index,设为模型运行次数
period_handle.index = range(len(period_handle))
# 构建T0
period_handle['t0'] = period_handle['t1'].shift(1)
# 重新获取小一个周期的数据
time1 = get_price(index ,start_date, end_date,'daily',fields=['close'])
# 记录每个周期中最后一个交易日
time1['date']=time1.index
# 进行转换,周线的每个变量都等于那一周中最后一个交易日的变量值
ph =time1.resample(period_pre,how='last').dropna()
# 通过更小的周期来提取的最后一个交易日的值,来提取大表格的第一个T0
period_handle['t0'][0] = ph['date'][0]
# 记录模型运行次数
period_handle['Replication#'] = period_handle.index
period_handle['Replication'] = period_handle['Replication#'].shift(-1)
del period_handle['Replication#']
del period_handle['date']
# 重新排列列表顺序
period_handle['T0'] = period_handle['t0']
period_handle['T1'] = period_handle['t1']
period_handle['T2'] = period_handle['t2']
del period_handle['close']
del period_handle['t0']
del period_handle['t1']
del period_handle['t2']
period_handle.to_csv('period_handle.csv')
return period_handle
# 时间格式修改(从timestamp改为str)
def time_fix(period_handle):
# 导入时间周期管理函数
p = time_handle(start_date, end_date, period, period_pre,index)
# dropna 并且list化
datelist_T0 = list(p.dropna()['T0'])
datelist_T1 = list(p.dropna()['T1'])
datelist_T2 = list(p.dropna()['T2'])
# timestamp 转str
datelist_T0 = list(np.vectorize(lambda s: s.strftime('%Y-%m-%d'))(datelist_T0))
datelist_T1 = list(np.vectorize(lambda s: s.strftime("%Y-%m-%d"))(datelist_T1))
datelist_T2 = list(np.vectorize(lambda s: s.strftime("%Y-%m-%d"))(datelist_T2))
# list字典化,并转为dateframe
t = {'T0': datelist_T0, 'T1':datelist_T1, 'T2':datelist_T2}
test_timing = pd.DataFrame(t)
return test_timing
'''
分类函数
'''
# 获取指数在所有周期内的池子,然后取不重复set的并集,变成新的池子
def get_all_index_stock(index, period_handle):
'''
输入:
stock_list: 所有周期池子的出现过的股票, list
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
stock_list: list, 所有周期内,于指数出现过的标的池子
'''
# 时间周期管理
p = time_handle(start_date, end_date, period, period_pre,index)
# 大池子提取
stock_list_pre = []
for date in p['T0']:
# 获取每个T0的指数池子
stk_list = get_index_stocks(index , date=date)
# 放到stock_list里面
stock_list_pre.append(stk_list)
# 分解多重列表,去重复,返回list
s = splitlist(stock_list_pre)
stock_list = list(set(s))
return stock_list
# 所有周期,指数池子里面所有股票的周期收益率
def get_index_big_pool_return(stock_list, period_handle):
'''
输入:
stock_list: 所有周期池子的出现过的股票, list
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns:
T0: T0时间点的集合
code1: 标的1在T0到T1的收益率
code2: 标的2在T0到T1的收益率
以此类推
'''
# 获取指数池子所有的索引
stock_code = stock_list
p = time_handle(start_date, end_date, period, period_pre,index)
# 获取时间表格,剔除T1、T2和Replication列
stk_return = p.copy()
# 收益率计算
for j in stock_code:
j_str = str(j)
p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,1]]
p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]
a = [(m-n)/n for m,n in zip (p1,p0)]
stk_return[str(j)] = a
# 删除T1列,保留T0列 ,并赋值给index
del stk_return['T1']
stk_return.index = stk_return['T0']
del stk_return['T0']
del stk_return['T2']
del stk_return['Replication']
# 缺失值用0填补
stk_return.fillna(0)
# 保存
stk_return.to_csv('stock_return.csv')
return stk_return
# 训练:分类函数
def train_classification(stk_return, index_return):
'''
输入:
skt_retun: 所有标的在T0-T1时间集当中的周期收益率, dataframe
index_return: 指数在T0-T1时间集合中的周期收益率, dataframe
输出:
格式为dataframe
columns:
T0: T0时间点的集合
index:
code1: 在T0-T1这个周期里面是否跑赢大盘,跑赢为'1',否则为'0'
code2: 是否跑赢大盘,分类数据
以此类推
'''
# 复制skt_return的dataframe为最终的输出格式
stock_cl = stk_return.copy()
# 遍历比较,赋值
for j in range(len(stock_cl.index)):
for i in range(len(stock_cl.columns)):
if stock_cl.iloc[j,i] > index_return.iloc[j,0]:
stock_cl.iloc[j,i] = 1
else:
stock_cl.iloc[j,i] = 0
# 转置
stock_cl = stock_cl.T
# 保存
stock_cl.to_csv('stock_classification_data.csv')
return stock_cl
# 获取T0 到 T1时间段,指数周期收益率
def get_index_return_train(index,period_handle):
'''
输入:
index: 指数, 元素str
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns:
T0: T0时间点的集合
index_return: 指数在T0到T1的收益率
'''
# 获取时间表格,剔除T1、T2和Replication列
p = time_handle(start_date, end_date, period, period_pre,index)
index_return = p.copy()
del index_return['Replication']
del index_return['T2']
# 收益率计算
p0 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,1]]
p1 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,2]]
a = [(m-n)/n for m,n in zip(p1,p0) ]
index_return['index_return'] = a
del index_return['T1']
index_return.index = index_return['T0']
del index_return['T0']
# 保存现成的表格
index_return.to_csv('index_return.csv')
return index_return
# 获取T1 到 T2 时间段, 指数周期的收益率
def get_index_return_test(index,period_handle):
'''
输入:
index: 指数, 元素str
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns:
T2: T2时间点的集合
index_return: 指数在T0到T1的收益率
'''
# 获取时间表格,剔除T1、T2和Replication列
p = time_handle(start_date, end_date, period, period_pre,index).dropna()
index_return = p.copy()
del index_return['Replication']
del index_return['T0']
# 收益率计算
p0 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,2]]
p1 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,3]]
a = [(m-n)/n for m,n in zip(p1,p0) ]
index_return['index_return'] = a
del index_return['T1']
index_return.index = index_return['T2']
del index_return['T2']
# 保存现成的表格
index_return.to_csv('index_return.csv')
return index_return
# 获取T0 到 T1时间段,指数池子里面所有股票的周期收益率
def get_stock_return_train(data, period_handle):
'''
输入:
data: 因子提取的大表格, dataframe
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns:
T0: T0时间点的集合
code1: 标的1在T0到T1的收益率
code2: 标的2在T0到T1的收益率
以此类推
'''
# 获取指数池子所有的索引
stock_code = list(data.index)
p = time_handle(start_date, end_date, period, period_pre,index)
# 获取时间表格,剔除T1、T2和Replication列
stk_return = p.copy()
# 收益率计算
for j in stock_code:
j_str = str(j)
p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,1]]
p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]
a = [(m-n)/n for m,n in zip (p1,p0)]
stk_return[str(j)] = a
# 删除T1列,保留T0列 ,并赋值给index
del stk_return['T1']
stk_return.index = stk_return['T0']
del stk_return['T0']
del stk_return['T2']
del stk_return['Replication']
# 保存文件
stk_return.to_csv('stk_return_train.csv')
return stk_return
# 获取 T1 到 T2时间段,预测池子里面所有股票的周其收益率
def get_stock_return_test(pool_list, period_handle):
'''
输入:
pool_list: 根据预测出来的标的池子, list
period_handle: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns: T2时间点集合
index: 股票对应的收益率
'''
p = time_handle(start_date, end_date, period, period_pre,index)
# 获取时间表格,剔除T1、T2和Replication列
stk_return = p.copy()
# 收益率计算
for j in pool_list:
j_str = str(j)
p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]
p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,3]]
a = [(m-n)/n for m,n in zip (p1,p0)]
stk_return[str(j)] = a
# 删除T1列,保留T0列 ,并赋值给index
del stk_return['T1']
stk_return.index = stk_return['T0']
del stk_return['T0']
del stk_return['T2']
del stk_return['Replication']
# 保存文件
stk_return.to_csv('stk_return_train.csv')
return stk_return
'''
训练和回测准备
'''
# 根据预测并提取预测池子函数
def model_pool(stock_cl, num, clf, clf1, test_timing):
'''
输入:
stock_cl: 用以训练的分类数据
num = 第几次
clf: 模型
test_timing: str化的时间周期
输出:
pool_list: 根据模型出来的股票池子
'''
# 获取T0时间点的因子数据
data = prepare_data(test_timing['T0'][num], index)
# 获取T1时间点的因子数据
data_test = prepare_data(test_timing['T1'][num],index)
# 如果 T0 和 T1 两个时间点出来的因子数据,因为某标的剔除导致index不匹配
if len(data.index) != len(data_test.index):
# 取交集作为分类值,训练还有预测值
data_adj = data.loc[data.index & data_test.index,:]
data_test_adj = data_test.loc[data.index & data_test.index,:]
stock_cl_adj = stock_cl.loc[data.index & data_test.index,:]
# 训练
X_train = np.array(data_adj)
Y_train = np.array(stock_cl_adj.T)[num]
# 算法训练
clf.fit(X_train, Y_train)
# 预测
X_predict = np.array(data_test_adj)
# 根据T0到T1的训练模型,基于T1的因子数据,做T1-T2的分类结果预测
Y_predict = clf.predict(X_predict)
# 如果用第一种算法预测结果都为0,用第二种算法fit一次
if all (Y_predict == 0):
# 算法训练第二次
clf1.fit(X_train, Y_train)
# 预测第二遍
X_predict = np.array(data_test)
Y_predict = clf1.predict(X_predict)
# 如果匹配则,按照原计划进行
else:
X_train = np.array(data)
stock_cl_adj = stock_cl.loc[data.index,:]
Y_train = np.array(stock_cl_adj.T)[num]
# 算法训练
clf.fit(X_train, Y_train)
# 预测
data_test_adj = data_test.copy()
X_predict = np.array(data_test_adj)
# 根据T0到T1的训练模型,基于T1的因子数据,做T1-T2的分类结果预测
Y_predict = clf.predict(X_predict)
# 如果用第一种算法预测结果都为0,用第二种算法fit一次
if all (Y_predict == 0):
# 算法训练第二次
clf1.fit(X_train, Y_train)
# 预测第二遍
X_predict = np.array(data_test_adj)
Y_predict = clf1.predict(X_predict)
# 构建在T1预测T2的分类表格
s = {'predict_clf': list(Y_predict)}
s = pd.DataFrame(s)
s.index = data_test_adj.index
# 获取预测池子的平均收益率
model_predict = []
pool_list = []
# 提取预测的分类值为1的标的
for a in range(len(s)):
if s.iloc[a,0] == 1:
# 捕捉分类为1的index,添加到信的list中
pool_list.append(str(s.index[a]))
return pool_list
# 根据模型筛选的股票池子出来的平均收益率
def get_model_return(pool_list, test_timing,num):
'''
输入:
pool_list: 筛选出来的股票池子
test_timing: 周期函数
输出:
model_mean_return: 预测出来标的的平均收益率
'''
return_test_list = []
for j in pool_list:
j_str = str(j)
datelist_T1 = test_timing['T1']
datelist_T2 = test_timing['T2']
p1 = [float(get_price(j, datelist_T1[num],datelist_T1[num])['close'])]
p2 = [float(get_price(j, datelist_T2[num],datelist_T2[num])['close'])]
a = [(m-n)/n for m,n in zip (p2,p1)]
# 捕捉分类为1的index,添加到信的list中
return_test_list.append(a[0])
stk_test = {'pool_list':pool_list, 'return_test_list':return_test_list}
stk_test = pd.DataFrame(stk_test)
stk_test.index = stk_test['pool_list']
del stk_test['pool_list']
# 收益率获取
model_mean_return = stk_test.mean()
return model_mean_return
# 将预测出来的股票池子转化为dataframe格式
def predict_pool(pool_list):
# 字典化为dataframe
predict_pool ={'predict_pool':pool_list, 'predict_score':1}
predict_pool = pd.DataFrame(predict_pool)
predict_pool.index = predict_pool['predict_pool']
del predict_pool['predict_pool']
return predict_pool
# 实际分类池子函数
def actural_pool(act_cl, test_timing):
'''
输入:
act_cl: 分类池子
test_timing: str化的时间周期
输出:
格式为dataframe
实际分类池子
'''
# 提取真实的分类数据
act_c = act_cl.copy()
del act_c[(act_c.columns)[0]]
act_c.columns = test_timing['T2']
actural_cl = act_c[act_c.columns[num]]
# 字典化为dataframe
actural_pool = {'act_pool':actural_cl.index, 'act_score':(actural_cl)}
actural_pool = pd.DataFrame(actural_pool)
del actural_pool['act_pool']
return actural_pool
# 大模型测试函数
# 自动化生成对比收益率函数
def test_return(start_date, end_date, period, period_pre, index, clf, clf1):
'''
输入:
index: 指数
clf: 模型
输出:
格式为dataframe
index: T2时间节点
index_return: 大盘在T1-T2的收益
model_return: 模型在T1-T2的收益
pool_number: 模型在T1-T2预测池子数量
'''
# 获取时间周期
p = time_handle(start_date, end_date, period, period_pre,index)
test_timing = time_fix(p)
# 辅助
data = prepare_data(start_date,index)
# 获取 T0 到 T1 时间段,指数池子里面所有股票的周期收益率
stk_return = get_stock_return_train(data,p)
# 获取 T0 到 T1 时间段,指数周期收益率
index_return = get_index_return_train(index,p)
# 获取用来训练的分类数据
stock_cl = train_classification(stk_return, index_return)
# 回测分类,实际的分类情况获取
act_cl = actural_classification(p, stock_cl)
# 剔除最后一列(因为p的最后一行的T2是nan值)
del stock_cl[stock_cl.columns[-1]]
# 获取T1 到 T2 时间段, 指数周期的收益率
index_return_test = get_index_return_test(index,p)
# 模型收益率提取
predict_return = []
# 每一次预测池子标的数量提取
pool_num = []
for num in range(len(test_timing['T0'])):
print('正在进行第'+str(num+1)+'次训练、预测')
# 获取预测的pool
pool = model_pool(stock_cl,num,clf, clf1, test_timing)
# 根据预测的pool获取周期均收益率
model_mean_return = get_model_return(pool, test_timing, num)
# 把均收益率放到predict_return这个list中
predict_return.append(model_mean_return)
# 记录预测池子数量
pool_num.append(len(pool))
# 对比预测池子周期均收益率和大盘周期均收益率
compare = index_return_test.copy()
cp_return = pd.DataFrame(predict_return)
cp_return.index = compare.index
cp_return['index_return'] = compare['index_return']
cp_return['model_return'] = cp_return['return_test_list']
del cp_return['return_test_list']
cp_return['premium'] = cp_return['model_return'] - cp_return['index_return']
# 记录预测池子数量
cp_return['pool_number'] = pool_num
print('所有周期数据训练、预测已经完成')
return cp_return
# 结果可视化
def visualization(df):
'''
输入:
df: 自动化生成对比收益率表格
输出:
可视化结果
'''
del df['pool_number']
df.columns = ['指数大盘收益率','模型收益率','模型超额收益率']
df.plot(figsize=(15,8),title= "模型收益率(折线图)")
df.plot.bar(figsize=(15,8),title= "模型收益率(柱状图)")
# 跑赢or输结果
# 记录对比大盘结果的次数
count1 = []
for j in range(len(df)):
if df.iloc[j,2] < 0:
count1.append(j)
count2 = []
for j in range(len(df)):
if df.iloc[j,2] > 0:
count2.append(j)
return df.plot(figsize=(15,8),title= "模型收益率(折线图)"), df.plot.bar(figsize=(15,8),title= "模型收益率(柱状图)"), '总回测次数:', len(df), '跑输的次数:', len(count1), '跑赢的次数:', len(count2)
# 【因子测试函数】测试框架 v4
# 制作人:Howard董先森, wechat:dhl19988882,e-mail: 16hldong.stu.edu.cn
# copy并分享的时候记得给小弟一下credit就好~
'''
导入库
'''
from sklearn import linear_model
regr = linear_model.LinearRegression()
'''
筛选辅助工具函数以及数据准备函数
'''
# 提取超额收益率函数
def premium_dataframe(index_return, stock_return):
# 构建待填补的dataframe,index和inde_return的index相同
premium_df = pd.DataFrame(index = index_return.index)
# 遍历stk_return的所有标的
for i in stk_return[stk_return.columns]:
# 列运算,把结果赋值给premium_df
premium_df[i] = stk_return[i] - index_return['index_return']
return premium_df
# 已知标的池子,获取T0-T1周期收益率
def get_group_return(group, test_timing):
'''
输入:
group: 标的池子的list
test_timing: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns:
T0: T0时间点的集合
code1: 标的1在T0到T1的收益率
code2: 标的2在T0到T1的收益率
以此类推
'''
# 获取时间表格,剔除T1、T2和Replication列
stk_group_return = test_timing.copy()
# 收益率计算
for j in group:
j_str = str(j)
p0 = [float(get_price(j,i,i)['close'])for i in test_timing.iloc[:,1]]
p1 = [float(get_price(j,i,i)['close'])for i in test_timing.iloc[:,2]]
a = [(m-n)/n for m,n in zip (p1,p0)]
stk_group_return[str(j)] = a
# 表格整理
del stk_group_return['T0']
del stk_group_return['T1']
del stk_group_return['T2']
return stk_group_return
# 已知标的池子,获取T0-T1周期收益率
def get_single_period_group_return(group, test_timing):
'''
输入:
group: 标的池子的list
test_timing: 周期管理函数出来的时间集合, dataframe
输出:
格式为dataframe
columns: 单个标的的T0-T1周期收益率
index: 各种标的代码
'''
# 创建字典,代填入单个标的单个周期的收益率
stk_group_return = {}
# 创建list,代填入单个标的单个周期的收益率
stk_return_list = []
# 收益率计算
for j in group:
time_t0 = test_timing.iloc[num,1]
time_t1 = test_timing.iloc[num,0]
j_str = str(j)
p0 = float(get_price(j,time_t0,time_t0)['close']) # 获得T0时间点的价格
p1 = float(get_price(j,time_t1,time_t1)['close']) # 获得T1时间点的价格
ret = (p1-p0)/p0 # 获得单个标的在T0-T1时间点的收益率
stk_return_list.append(ret)
# 构建表格
stk_group_return = pd.DataFrame(stk_return_list,index = group)
stk_group_return[str(test_timing.iloc[num,0])] = stk_group_return[stk_group_return.columns[0]]
del stk_group_return[stk_group_return.columns[0]]
return stk_group_return
# 提取因子大表格数据函数
def get_big_data(test_timing):
'''
输入:
test_timing: dataframe格式, 时间周期管理函数
输出:
big_data_t0: 字典,存放T0所有时间点的因子数据
big_data_t1: 字典,存放T1所有时间点的因子数据
'''
# 提取因子大表格数据,放在字典里面
big_data_t0 = {}
big_data_t1 = {}
for i in range(len(test_timing['T0'])):
print('提取第'+str(i+1)+'个周期的T0因子数据')
t0 = test_timing['T0'][i]
t1 = test_timing['T1'][i]
big_data_t0[t0] = prepare_data(t0, index)
print('提取第'+str(i+1)+'个周期的T1因子数据')
big_data_t1[t1] = prepare_data(t1, index)
i = i+1
print('提取成功!周期数为:'+ str(i))
return big_data_t0,big_data_t1
'''
Normal IC框架
'''
# Normal IC 情况下,因子收益率(回归系数)、因子收益率的T值、IC值 (原始数据表格获取)
def get_normal_ic_original_factor_testing_data(stk_return, test_timing, big_data):
'''
输入:
stk_return: dataframe格式, 所有标的在所有周期的收益率
test_timing: dataframe格式, 时间周期管理函数
big_data: 两个dict:
big_data_t0: 字典,存放T0所有时间点的因子数据
big_data_t1: 字典,存放T1所有时间点的因子数据
输出:
normal_ic_df: dataframe格式, Normal_ic表格
t_df: dataframe格式,因子数值(Barra因子暴露)对标的周期收益率RLM回归后的T值
param_df: dataframe格式, 因子收益率(回归系数)表格
'''
# 因子收益率(回归系数)、因子收益率序列的T值、IC值 三个表格获取
# 周期因子IC提取
# 收益率数据准备
stk_return1 = stk_return.T
# 构建字典,待存放因子IC值
factor_for_ic = {}
# 构建字典,待存放因子t_value
factor_for_t = {}
# 构建字典,待存放因子parameter
factor_for_parameter = {}
# 遍历所有的T0时间点
for num in range(len(test_timing['T0'])):
print('正在进行第'+str(num+1)+'周期因子测试原始数据获取……')
# 获取单周期的因子值
big_data_t0 = big_data[0]
big_Data_t1 = big_data[1]
t0 = test_timing['T0'][num]
t1 = test_timing['T1'][num]
data = big_data_t0[t0]
data1 = big_data_t1[t1]
# 调整stk_return的index
stk_return2 = stk_return1.loc[data.index,:]
del stk_return2[stk_return2.columns[-1]]
stk_return2.columns = test_timing['T0']
# 对于T0有因子值,T1没有的情况,提取T0和T1两个index的交集
data_adj = data.loc[data.index & data1.index,:]
stk_return2_adj = stk_return2.loc[data_adj.index & stk_return2.index,:]
# list1,待存放ic
list1 = []
# list2, 待存放t—value
list2 = []
# list3, 待存放parameter
list3 = []
# 求相关系数和T值,对于第i个因子
for i in range(len(data_adj.columns)):
IC_X = list(data_adj[data_adj.columns[i]])
IC_Y = list((stk_return2_adj[stk_return2_adj.columns[num]]))
# 将单个周期所有因子ic值放到cor中
cor = (list(corrcoef(IC_X, IC_Y)[0])[-1])
# 回归
rlm_model = sm.RLM(IC_Y , IC_X , M=sm.robust.norms.HuberT()).fit()
# 存放相关系数cor
list1.append(cor)
# 存放t_value
list2.append(float(rlm_model.tvalues))
# 存放parameter
list3.append(float(rlm_model.params))
# 相关系数,放到字典里
factor_for_ic[num] = list1
# t_value, 放到字典里
factor_for_t[num] = list2
# parameter, 放到字典里
factor_for_parameter[num] =list3
# 整合
# Normal ICdf整合
normal_ic_df = pd.DataFrame(factor_for_ic)
normal_ic_df.index = data.columns
normal_ic_df.index.name = 'factor'
normal_ic_df.columns = test_timing['T0']
# t值整合
t_df = pd.DataFrame(factor_for_t)
t_df.index = data.columns
t_df.index.name ='factor'
t_df.columns = test_timing['T0']
# Barra体系下的因子收益率(回归系数)整合
param_df = pd.DataFrame(factor_for_parameter)
param_df.index = data.columns
param_df.index.name = 'factor'
param_df.columns = test_timing['T0']
print('所有周期因子测试在Normal_IC框架下原始数据获取完毕!')
return normal_ic_df, t_df, param_df
# 根据 Normal_IC原始数据,提取各种打分指标
def get_pre_scoring_data_for_normal_ic(normal_ic_og):
'''
输入:
normal_ic_og: dataframe,原始数据大表格
输出:
factor_mean_return: dataframe, 因子年化收益率均值
ic_indicator_df: dataframe, normal_ic各项指标
'''
# 初始数据准备
t_df = normal_ic_og[1]
normal_ic_df = normal_ic_og[0]
param_df = normal_ic_og[2]
# 提取因子收益率年化均值
factor_mean_list =[]
factor_return = param_df.T
# 遍历每个因子
for i in factor_return.columns:
# 计算单个因子所有周期的均值
mean_return = (factor_return[i].mean())
# 转为年化收益率
annualized_mean_return = (1+mean_return)**12 - 1
# 计算单个因子所有周期年化均值,放到list中去
factor_mean_list.append((annualized_mean_return))
# 转为dataframe格式
factor_mean_return = pd.DataFrame(factor_return.columns)
factor_mean_return['abs_annualized_factor_mean_return'] = factor_mean_list
factor_mean_return.index = factor_mean_return[factor_mean_return.columns[0]]
del factor_mean_return[factor_mean_return.columns[0]]
# IC各种指标提取
ic = normal_ic_df.T
# 创建字典,待提取每一个因子的所有ic值序列
features_ic = {}
# 创建字典,待填入每一个因子的IC各种指标
ic_indicator ={}
# 创建dataframe
indicator = pd.DataFrame(columns = ic.columns)
# 提取每个factor的ic值,转为列表
for i in ic.columns:
# 提取每一个因子的所有ic值序列,放到字典中
features_ic[i] = list(ic[i])
# 提取空值,放到字典ic_indicator中
ic_indicator[i] = list(indicator[i])
# 提取每一个因子的所有indicator
for i in ic.columns:
# 计算IC值的均值
ic_indicator[i].append(mean(features_ic[i]))
# 计算IC值的标准差
ic_indicator[i].append(std(features_ic[i]))
# IC大于0的比例
ic_indicator[i].append(sum(pd.Series(features_ic[i])>0)/len(features_ic[i]))
# IC绝对值大于0.02的比例
abs_list = []
for d in ic_indicator[i]:
abs_list.append(abs(d))
ic_indicator[i].append(sum(pd.Series(abs_list)>0.02)/len(features_ic[i]))
# IC绝对值
ic_indicator[i].append(mean(abs_list))
# IR值
ic_indicator[i].append(mean(features_ic[i])/std(features_ic[i]))
# IR绝对值
ic_indicator[i].append(abs(mean(features_ic[i])/std(features_ic[i])))
# 整合成表格
ic_indicator_df = pd.DataFrame(ic_indicator, index = ['Normal_IC_mean','Normal_IC_std','Normal_IC>0_%','Normal_IC>0.02_%','abs_Normal_IC','Normal_IR','abs_IR']).T
# T值各种指标提取
t = t_df.T
# 创建字典,待提取每一个因子的所有t值序列
features_t = {}
# 创建字典,待填入每一个因子的t各种指标
t_indicator ={}
# 创建dataframe
indicator = pd.DataFrame(columns = t.columns)
# 提取每个factor的ic值,转为列表
for i in t.columns:
# 提取每一个因子的所有ic值序列,放到字典中
features_t[i] = list(t[i])
# 提取空值,放到字典ic_indicator中
t_indicator[i] = list(indicator[i])
# 提取每一个因子的所有indicator
for i in t.columns:
# T值均值
t_indicator[i].append(mean(features_t[i]))
# 计算T绝对值的均值
abs_list = []
for d in features_t[i]:
abs_list.append(abs(d))
t_indicator[i].append(mean(abs_list))
# T绝对值大于2的比例
t_indicator[i].append(sum(pd.Series(abs_list)> 2 )/len(features_t[i]))
# 整合成表格
t_indicator_df = pd.DataFrame(t_indicator, index = ['T_mean','abs(t_value)_mean','abs(t_value)_>_2_%']).T
return factor_mean_return, t_indicator_df, ic_indicator_df
# 参照光大的因子初步筛选打分表格
def get_scoring_data_for_normal_ic(pre_scoring_data):
'''
输入:
pre_scoring_data: dataframe,原始数据大表格处理过后的三个各种打分指标表格
输出:
factor_test: dataframe, 因子初步筛选打分表格
'''
# 三个表格整合,参考光大打分表格
factor_indicator = pd.concat([pre_scoring_data[0].T,pre_scoring_data[1].T, pre_scoring_data[2].T],axis =0)
# 参照光大打分框架
factor_test = pd.DataFrame(index = factor_indicator.columns)
factor_test['Factor_Mean_Return'] = factor_indicator.T['abs_annualized_factor_mean_return']
factor_test['Factor_Return_tstat'] = factor_indicator.T['T_mean']
factor_test['IC_mean'] = factor_indicator.T['Normal_IC_mean']
factor_test['IR'] = factor_indicator.T['Normal_IR']
# 保存和读取
factor_test.to_csv('normal_ic_test.csv')
factor_test = pd.read_csv('normal_ic_test.csv')
factor_test.index = factor_test[factor_test.columns[0]]
del factor_test[factor_test.columns[0]]
return factor_test
# 单调性检测以及分组回溯函数提取
def get_monotony_and_grouping_return_for_normal_ic(big_data):
'''
输入:
big_data: 两个dict:
big_data_t0: 字典,存放T0所有时间点的因子数据
big_data_t1: 字典,存放T1所有时间点的因子数据
输出:
monotony_outcome: dict, key是每个周期的T0时间点
values是指单个周期的所有因子的单调性指标,格式为list
group_return_dict: dict, key是每个周期的T0时间点
values是指单个周期所有因子,每个因子按照数值大小排列后,提取对标的的当期收益率进行分组提取,格式为dataframe
'''
# 辅助
data = big_data_t0[test_timing['T0'][0]]
print('总的单调性数据提取周期为:'+str(len(test_timing.index)))
print('总的因子数量为:'+str(len(data.columns)))
# 创建字典,填入所有因子的单调性和分层回溯周期收益率
monotony_outcome ={}
group_return_dict = {}
# 分组数量
group_num = 5
# 遍历所有T0
for i in range(len(test_timing['T0'])):
print('--------第'+str(i+1)+'个周期多空提取中......')
print('-----第'+str(i+1)+'个周期因子数据表格提取中......')
# 获取单周期的因子值
data = big_data_t0[test_timing['T0'][i]]
data1 = big_data_t1[test_timing['T1'][i]]
# 对于T0有因子值,T1没有的情况,提取T0和T1两个index的交集
data_adj = data.loc[data.index & data1.index,:]
# 创建字典,待填入单个周期,单个因子的单调性指标
monotony = {}
# 分层回溯
group_return = {'group1':[],'group2':[],'group3':[],'group4':[],'group5':[]}
# 遍历所有因子
for num in range(len(data_adj.columns)):
factor_list = list(data_adj.columns)
factor = factor_list[num]
print('---提取'+str(factor)+'因子')
# 提取单个因子
factor_test = data_adj[data_adj.columns[num]]
# 排序分层提取(降序)
sort_df = factor_test.sort_values(ascending = False)
# 每组分的标的数量
code_num = int(len(factor_test)/group_num)
# 创建字典pool_dict,用来放置分好组的标的池子
pool_dict = {}
# 提取降序后的所有index
sort_index = list(sort_df.index)
# 分组开始,取得dict
a = 0
for q in range((group_num)):
# 每组命名
j = 'group'+str((q+1))
# 提取
pool_dict[j] = sort_index[a:code_num]
a= code_num
code_num = code_num + int(len(data_adj)/group_num)
# 提取标的池子名字
group_name = list(pool_dict.keys())
# 创建字典mean_return_dict,用来放置分好组的标的池子的周期算术平均收益率
mean_return_dict = {}
# 根据每组的index提取所有周期的累计收益率
for group in group_name:
stk_group_return = get_group_return(pool_dict[group], test_timing)
# 提取一个周期的,选出标的池子的算术平均,放到list中
mean_return_dict[group] = (list(stk_group_return.mean(axis =1))[i])
# 转为dataframe格式
mean_return_df = pd.DataFrame(mean_return_dict, index =[i])
# 收益率提取
R1_m = mean_return_df[mean_return_df.columns[0]]
R2_m = mean_return_df[mean_return_df.columns[1]]
R3_m = mean_return_df[mean_return_df.columns[2]]
R4_m = mean_return_df[mean_return_df.columns[3]]
R5_m = mean_return_df[mean_return_df.columns[4]]
# 将回溯周期收益率放到字典group_return中
group_return['group1'].extend(R1_m)
group_return['group2'].extend(R2_m)
group_return['group3'].extend(R3_m)
group_return['group4'].extend(R4_m)
group_return['group5'].extend(R5_m)
print("--已经获取"+factor+"因子第"+str(i+1)+'周期的分组回溯周期收益率')
# 年化收益率提取
R1 = (1+R1_m)**12 - 1
R2 = (1+R2_m)**12 - 1
R3 = (1+R3_m)**12 - 1
R4 = (1+R4_m)**12 - 1
R5 = (1+R5_m)**12 - 1
df = pd.DataFrame(index = mean_return_df.index)
df['R1-R5'] = R1 - R5
df['R2-R4'] = R2 - R4
df['Monotony'] = df['R1-R5']/df['R2-R4']
# 将单调性指标放到字典monotony字典中
monotony[factor] = float(df['Monotony'])
print("-已经获取"+factor+"因子单调性指标")
# 转为 dataframe
monotony_df = pd.DataFrame(monotony,index=[0])
group_return_df = pd.DataFrame(group_return,index=data.columns)
# 将单个周期的所有因子单调性指标转为 list,并放在字典monotony_outcome中
monotony_outcome[test_timing['T0'][i]] = list((monotony_df.T)[monotony_df.T.columns[0]])
# 将单周期的所有因子分组回溯周期收益率,放到字典group_return_dict中
group_return_dict[test_timing['T0'][i]] = group_return_df
print("所有因子所有周期的单调性指标已经获取完毕!")
return monotony_outcome, group_return_dict
'''
Rank IC框架
'''
# Rank框架下,因子收益率(回归系数)、因子收益率序列的T值、IC值 三个表格获取
def get_rank_ic_original_factor_testing_data(stk_return, test_timing, big_data):
'''
输入:
stk_return: dataframe格式, 所有标的在所有周期的收益率
test_timing: dataframe格式, 时间周期管理函数
big_data: 两个dict:
big_data_t0: 字典,存放T0所有时间点的因子数据
big_data_t1: 字典,存放T1所有时间点的因子数据
输出:
rank_ic_df: dataframe格式, Normal_ic表格
rank_t_df: dataframe格式,因子数值(Barra因子暴露)对标的周期收益率RLM回归后的T值
rank_param_df: dataframe格式, 因子收益率(回归系数)表格
'''
# 收益率数据准备
stk_return1 = stk_return.T
# 构建字典,待存放因子Rank_IC值
factor_for_ic = {}
# 构建字典,待存放因子t_value
factor_for_t = {}
# 构建字典,待存放因子parameter
factor_for_parameter = {}
# 遍历所有的T0时间点
for num in range(len(test_timing['T0'])):
print('正在进行第'+str(num+1)+'周期因子测试原始数据获取……')
# 获取单周期的因子值
data = big_data_t0[test_timing['T0'][num]]
data1 = big_data_t1[test_timing['T1'][num]]
# 对于T0有因子值,T1没有的情况,提取T0和T1两个index的交集
data_adj = data.loc[data.index & data1.index,:]
# list1,待存放ic
list1 = []
# list2, 待存放t—value
list2 = []
# list3, 待存放parameter
list3 = []
# 求相关系数和T值,对于第i个因子
for i in range(len(data_adj.columns)):
# 提取单个因子
factor_test = pd.DataFrame(data_adj[data_adj.columns[i]])
# 提取 X
factor_test['X_Rank'] = factor_test.rank(ascending = True, method = 'dense')
X = list(factor_test['X_Rank'])
# 提取 Y
# 提取收益率
stk_group_return = get_single_period_group_return(list(factor_test.index), test_timing)
Y = list(stk_group_return[test_timing['T0'][num]])
# 将单个周期所有因子ic值放到cor中
cor = (list(corrcoef(X, Y)[0])[-1])
# 回归
rlm_model = sm.RLM(Y , X , M=sm.robust.norms.HuberT()).fit()
# 存放相关系数cor
list1.append(cor)
# 存放t_value
list2.append(float(rlm_model.tvalues))
# 存放parameter
list3.append(float(rlm_model.params))
# 相关系数,放到字典里
factor_for_ic[num] = list1
# t_value, 放到字典里
factor_for_t[num] = list2
# parameter, 放到字典里
factor_for_parameter[num] =list3
# 整合
# Normal ICdf整合
rank_ic_df = pd.DataFrame(factor_for_ic)
rank_ic_df.index = data.columns
rank_ic_df.index.name = 'factor'
rank_ic_df.columns = test_timing['T0']
# t值整合
rank_t_df = pd.DataFrame(factor_for_t)
rank_t_df.index = data.columns
rank_t_df.index.name ='factor'
rank_t_df.columns = test_timing['T0']
# Barra体系下的因子收益率(回归系数)整合
rank_param_df = pd.DataFrame(factor_for_parameter)
rank_param_df.index = data.columns
rank_param_df.index.name = 'factor'
rank_param_df.columns = test_timing['T0']
print('所有周期Rank_IC框架下,因子测试原始数据获取完毕!')
return rank_ic_df, rank_t_df, rank_param_df
# 根据 Rank_IC原始数据,提取各种打分指标
def get_pre_scoring_data_for_rank_ic(rank_ic_og):
'''
输入:
rank_ic_og: dataframe,原始数据大表格
输出:
factor_mean_return: dataframe, 因子年化收益率均值
ic_indicator_df: dataframe, normal_ic各项指标
'''
# 初始数据准备
normal_ic_df = rank_ic_og[0]
t_df = rank_ic_og[1]
param_df = rank_ic_og[2]
# 提取因子收益率年化均值
factor_mean_list =[]
factor_return = param_df.T
# 遍历每个因子
for i in factor_return.columns:
# 计算单个因子所有周期的均值
mean_return = (factor_return[i].mean())
# 转为年化收益率
annualized_mean_return = (1+mean_return)**12 - 1
# 计算单个因子所有周期年化均值,放到list中去
factor_mean_list.append((annualized_mean_return))
# 转为dataframe格式
factor_mean_return = pd.DataFrame(factor_return.columns)
factor_mean_return['abs_annualized_factor_mean_return'] = factor_mean_list
factor_mean_return.index = factor_mean_return[factor_mean_return.columns[0]]
del factor_mean_return[factor_mean_return.columns[0]]
# IC各种指标提取
ic = normal_ic_df.T
# 创建字典,待提取每一个因子的所有ic值序列
features_ic = {}
# 创建字典,待填入每一个因子的IC各种指标
ic_indicator ={}
# 创建dataframe
indicator = pd.DataFrame(columns = ic.columns)
# 提取每个factor的ic值,转为列表
for i in ic.columns:
# 提取每一个因子的所有ic值序列,放到字典中
features_ic[i] = list(ic[i])
# 提取空值,放到字典ic_indicator中
ic_indicator[i] = list(indicator[i])
# 提取每一个因子的所有indicator
for i in ic.columns:
# 计算IC值的均值
ic_indicator[i].append(mean(features_ic[i]))
# 计算IC值的标准差
ic_indicator[i].append(std(features_ic[i]))
# IC大于0的比例
ic_indicator[i].append(sum(pd.Series(features_ic[i])>0)/len(features_ic[i]))
# IC绝对值大于0.02的比例
abs_list = []
for d in ic_indicator[i]:
abs_list.append(abs(d))
ic_indicator[i].append(sum(pd.Series(abs_list)>0.02)/len(features_ic[i]))
# IC绝对值
ic_indicator[i].append(mean(abs_list))
# IR值
ic_indicator[i].append(mean(features_ic[i])/std(features_ic[i]))
# IR绝对值
ic_indicator[i].append(abs(mean(features_ic[i])/std(features_ic[i])))
# 整合成表格
ic_indicator_df = pd.DataFrame(ic_indicator, index = ['Normal_IC_mean','Normal_IC_std','Normal_IC>0_%','Normal_IC>0.02_%','abs_Normal_IC','Normal_IR','abs_IR']).T
# T值各种指标提取
t = t_df.T
# 创建字典,待提取每一个因子的所有t值序列
features_t = {}
# 创建字典,待填入每一个因子的t各种指标
t_indicator ={}
# 创建dataframe
indicator = pd.DataFrame(columns = t.columns)
# 提取每个factor的ic值,转为列表
for i in t.columns:
# 提取每一个因子的所有ic值序列,放到字典中
features_t[i] = list(t[i])
# 提取空值,放到字典ic_indicator中
t_indicator[i] = list(indicator[i])
# 提取每一个因子的所有indicator
for i in t.columns:
# T值均值
t_indicator[i].append(mean(features_t[i]))
# 计算T绝对值的均值
abs_list = []
for d in features_t[i]:
abs_list.append(abs(d))
t_indicator[i].append(mean(abs_list))
# T绝对值大于2的比例
t_indicator[i].append(sum(pd.Series(abs_list)> 2 )/len(features_t[i]))
# 整合成表格
t_indicator_df = pd.DataFrame(t_indicator, index = ['T_mean','abs(t_value)_mean','abs(t_value)_>_2_%']).T
return factor_mean_return, t_indicator_df, ic_indicator_df
# 参照光大的因子初步筛选打分表格
def get_scoring_data_for_rank_ic(pre_scoring_data_for_rank_ic):
'''
输入:
pre_scoring_data: dataframe,原始数据大表格处理过后的三个各种打分指标表格
输出:
factor_test: dataframe, 因子初步筛选打分表格
'''
# 三个表格整合,参考光大打分表格
pre_scoring_data = pre_scoring_data_for_rank_ic
factor_indicator = pd.concat([pre_scoring_data[0].T,pre_scoring_data[1].T, pre_scoring_data[2].T],axis =0)
# 参照光大打分框架
factor_test = pd.DataFrame(index = factor_indicator.columns)
factor_test['Factor_Mean_Return'] = factor_indicator.T['abs_annualized_factor_mean_return']
factor_test['Factor_Return_tstat'] = factor_indicator.T['T_mean']
factor_test['IC_mean'] = factor_indicator.T['Normal_IC_mean']
factor_test['IR'] = factor_indicator.T['Normal_IR']
# 保存和读取
factor_test.to_csv('rank_ic_test.csv')
factor_test = pd.read_csv('rank_ic_test.csv')
factor_test.index = factor_test[factor_test.columns[0]]
del factor_test[factor_test.columns[0]]
factor_test.columns = ['Factor_Mean_Return', 'Factor_Return_tstat', 'Rank_IC', 'Rank_IR']
return factor_test
'''
打分模型
'''
# 打分模型(rank_ir)
def get_score_data_ir(scoring_rank_df):
'''
输入:
scoring_rank_df: dataframe格式,打分前的数据
输出:
score_result: dataframe格式,最终打分表格
'''
a = scoring_rank_df.T
a=a.T
# 构建,待填补每个因子的总得分
total_factor_score = {}
for i in range(len(a)):
# 构建list,待填补单个因子的得分
score_list = []
factor_return = a.iloc[i,0]
factor_t = a.iloc[i,1]
factor_ic = a.iloc[i,2]
factor_ir = a.iloc[i,3]
if abs(factor_return) > 0.002:
score_list.append(1)
else:
score_list.append(0)
if abs(factor_t) > 2:
score_list.append(1)
else:
score_list.append(0)
if abs(factor_ic) > 0.02:
score_list.append(1)
else:
score_list.append(0)
if abs(factor_ir) > 0.2:
score_list.append(1)
else:
score_list.append(0)
total_factor_score[str(a.index[i])] = score_list
# 转为dataframe
score_outcome = pd.DataFrame(total_factor_score, index = a.columns)
score = score_outcome.T
score['Total_score'] = score_outcome.sum()
a['Total_score'] = score['Total_score']
score_result = a.sort_values(by='Total_score',ascending = False)
return score_result
'''
分层回溯模型
'''
# 提取每个因子的年化均收益率表格
def get_annualized_factor_return(gr):
'''
输入:
gr: dict:
key为时间周期
values为每个周期的所有因子的组合收益率
输出:
annual_df: dataframe, 所有因子在所有周期的年化收益率
'''
# 提取keys
key = list(gr.keys())
# 多空组合提取
for k in list(key):
# 单个多空组合因子收益率提取
gr[k]['long_short'] = gr[k]['group5']-gr[k]['group1']
# 创建取值为0的表格,待累加
sum_gr = pd.DataFrame(index = gr[key[2]].index, columns = gr[key[2]].columns)
sum_gr = sum_gr.fillna(0)
# 遍历 key
for k in list(key):
# 累加
sum_gr = sum_gr + gr[k]
# 平均值
mean_gr = sum_gr/len(key)
# 年化
annualized_mean = {}
for i in range(len(mean_gr.index)):
factor = mean_gr.index[i]
annualized_return = []
for j in range(len(mean_gr.columns)):
# 年化
annualized_return.append((mean_gr.iloc[i,j] + 1)**12 -1)
annualized_mean[factor] = annualized_return
# 转为dataframe
annual_df = pd.DataFrame(annualized_mean, index = mean_gr.columns).T
return annual_df
# 提取每个因子年化收益率的大表格
def get_annualized_grouping_return(gr):
'''
输入:
gr: dict:
key为时间周期
values为每个周期的所有因子的组合收益率
输出:
factor_dict:
key为因子名字
values为单个因子所有周期的组合收益率
'''
# 提取单个因子的多空组合累计收益率,可视化
# 创建字典group_dict, keys为因子名字,values为单个因子所有周期内的,分组收益
group_dict = {}
# 提取keys
key = list(gr.keys())
# 多空组合提取
for k in list(key):
# 单个多空组合因子收益率提取
gr[k]['long_short'] = gr[k]['group5']-gr[k]['group1']
# 重新提取factor字典
factor_dict= {}
factor_list = list(gr[list(gr.keys())[0]].index)
for factor in factor_list:
# 创建分组收益率字典,key为时间,values为分组收益
factor_return_dict = {}
# 遍历分组收益率
for k in list(gr.keys()):
factor_return_dict[k] = list(gr[k].ix[factor])
# 转为dataframe,作为单个因子,所有周期的分组收益率
return_df = pd.DataFrame(factor_return_dict).T
return_df.columns = gr[k].ix[factor].index
# 年化
annualized = {}
for i in range(len(return_df.index)):
factor_time = return_df.index[i]
annualized_return = []
for j in range(len(return_df.columns)):
# 年化
annualized_return.append((return_df.iloc[i,j] + 1)**12 -1)
annualized[factor_time] = annualized_return
# 转为dataframe,作为单个因子,所有周期的分组收益率
return_df = pd.DataFrame(annualized).T
return_df.columns = gr[k].ix[factor].index
# 将单个因子所有周期的分组收益率表格,存放到字典中
factor_dict[factor] = return_df
return factor_dict
# 提取每个因子周期收益率的大表格
def get_grouping_return(gr):
'''
输入:
gr: dict:
key为时间周期
values为每个周期的所有因子的组合收益率
输出:
factor_dict:
key为因子名字
values为单个因子所有周期的组合收益率
'''
# 提取单个因子的多空组合累计收益率,可视化
# 创建字典group_dict, keys为因子名字,values为单个因子所有周期内的,分组收益
group_dict = {}
# 提取keys
key = list(gr.keys())
# 多空组合提取
for k in list(key):
# 单个多空组合因子收益率提取
gr[k]['long_short'] = gr[k]['group5']-gr[k]['group1']
# 重新提取factor字典
factor_dict= {}
factor_list = list(gr[list(gr.keys())[0]].index)
for factor in factor_list:
# 创建分组收益率字典,key为时间,values为分组收益
factor_return_dict = {}
# 遍历分组收益率
for k in list(gr.keys()):
factor_return_dict[k] = list(gr[k].ix[factor])
# 转为dataframe,作为单个因子,所有周期的分组收益率
return_df = pd.DataFrame(factor_return_dict).T
return_df.columns = gr[k].ix[factor].index
# 将单个因子所有周期的分组收益率表格,存放到字典中
factor_dict[factor] = return_df
return factor_dict
# 时间等参数准备
import time
start = time.clock()
print('--------------------基本框架--------------------')
# 参数
date = '2016-01-01'
start_date ='2016-01-01'
end_date = '2019-03-01'
period = 'M'
period_pre = 'D'
S = '399905.XSHE' # 中证500 指数
index = S
# 行业:申万一级
industry_old_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230']
industry_new_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\
'801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750',\
'801760','801770','801780','801790','801880','801890']
# 行业获取
industry_code = get_industry(date,industry_old_code,industry_new_code)
from sklearn.neural_network import MLPClassifier
# 算法模型
# 算法一
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(5, 2), random_state=1)
# 辅助算法二,用于预测值都为0的状况
regressor = svm.SVC()
# SVM算法参数设计
parameters = {'kernel':['rbf'],'C':[0.01,0.03,0.1,0.3,1,3,10],\
'gamma':[1e-4,3e-4,1e-3,3e-3,0.01,0.03,0.1,0.3,1]}
# 创建网格搜索 scoring:指定多个评估指标 cv: N折交叉验证
clf1 = GridSearchCV(regressor,parameters,cv=10)
# 各种准备
# 获取时间周期
print('时间周期获取中……')
p = time_handle(start_date, end_date, period, period_pre,index)
test_timing = time_fix(p)
# 辅助因子表格
print('辅助因子表格获取中……')
data = prepare_data(date,index)
# 获取指数周期收益率
print('指数周期收益率获取中……')
index_return = get_index_return_train(S,p)
# 获取中证500在所有周期内的池子,然后取不重复set的交集,变成新的池子
print('分类表格获取中……')
stock_list = get_all_index_stock(index, p)
# 获取该池子的stk_return
stk_return = get_index_big_pool_return(stock_list,p)
# 获取所有周期所有指数池子在所有周期的分类值
stock_cl = train_classification(stk_return, index_return)
# 剔除最后一列(因为T2是nan值)
del stock_cl[stock_cl.columns[-1]]
# 获取T1-T2指数收益率数据,用以测试
print('T1-T2收益率表格获取中……')
index_return_test = get_index_return_test(index,p)
elapsed = (time.clock()- start)
print('所有周期数量为:'+str(len(test_timing)))
print('---------------基本框架准备工作完成!-------------------')
print('所用时间:', elapsed)
--------------------基本框架-------------------- 时间周期获取中…… 辅助因子表格获取中…… 指数周期收益率获取中…… 分类表格获取中…… T1-T2收益率表格获取中…… 所有周期数量为:38 ---------------基本框架准备工作完成!------------------- 所用时间: 177.79108100000002
下面一行的代码是提取所有周期所有因子的数据,提取时间漫长,可以直接用保存好的pickle
# 因子测试数据准备
import time
start = time.clock()
print('--------------------因子测试框架--------------------')
print('因子大表格dict提取中……')
big_data = get_big_data(test_timing)
big_data_t0 = big_data[0]
big_data_t1 = big_data[1]
print('----------------因子测试框架数据准备完成!--------------------')
elapsed = (time.clock()- start)
print('所用时间:', elapsed)
--------------------因子测试框架-------------------- 因子大表格dict提取中…… 提取第1个周期的T0因子数据 提取第1个周期的T1因子数据 提取第2个周期的T0因子数据 提取第2个周期的T1因子数据 提取第3个周期的T0因子数据 提取第3个周期的T1因子数据 提取第4个周期的T0因子数据 提取第4个周期的T1因子数据 提取第5个周期的T0因子数据 提取第5个周期的T1因子数据 提取第6个周期的T0因子数据 提取第6个周期的T1因子数据 提取第7个周期的T0因子数据 提取第7个周期的T1因子数据 提取第8个周期的T0因子数据 提取第8个周期的T1因子数据 提取第9个周期的T0因子数据 提取第9个周期的T1因子数据 提取第10个周期的T0因子数据 提取第10个周期的T1因子数据 提取第11个周期的T0因子数据 提取第11个周期的T1因子数据 提取第12个周期的T0因子数据 提取第12个周期的T1因子数据 提取第13个周期的T0因子数据 提取第13个周期的T1因子数据 提取第14个周期的T0因子数据 提取第14个周期的T1因子数据 提取第15个周期的T0因子数据 提取第15个周期的T1因子数据 提取第16个周期的T0因子数据 提取第16个周期的T1因子数据 提取第17个周期的T0因子数据 提取第17个周期的T1因子数据 提取第18个周期的T0因子数据 提取第18个周期的T1因子数据 提取第19个周期的T0因子数据 提取第19个周期的T1因子数据 提取第20个周期的T0因子数据 提取第20个周期的T1因子数据 提取第21个周期的T0因子数据 提取第21个周期的T1因子数据 提取第22个周期的T0因子数据 提取第22个周期的T1因子数据 提取第23个周期的T0因子数据 提取第23个周期的T1因子数据 提取第24个周期的T0因子数据 提取第24个周期的T1因子数据 提取第25个周期的T0因子数据 提取第25个周期的T1因子数据 提取第26个周期的T0因子数据 提取第26个周期的T1因子数据 提取第27个周期的T0因子数据 提取第27个周期的T1因子数据 提取第28个周期的T0因子数据 提取第28个周期的T1因子数据 提取第29个周期的T0因子数据 提取第29个周期的T1因子数据 提取第30个周期的T0因子数据 提取第30个周期的T1因子数据 提取第31个周期的T0因子数据 提取第31个周期的T1因子数据 提取第32个周期的T0因子数据 提取第32个周期的T1因子数据 提取第33个周期的T0因子数据 提取第33个周期的T1因子数据 提取第34个周期的T0因子数据 提取第34个周期的T1因子数据 提取第35个周期的T0因子数据 提取第35个周期的T1因子数据 提取第36个周期的T0因子数据 提取第36个周期的T1因子数据 提取第37个周期的T0因子数据 提取第37个周期的T1因子数据 提取第38个周期的T0因子数据 提取第38个周期的T1因子数据 提取成功!周期数为:38 ----------------因子测试框架数据准备完成!-------------------- 所用时间: 2279.4079020000004
# 【保存】pickle
import pickle
dic_file = open('big_data_t0.pickle','wb')
pickle.dump(big_data[0], dic_file)
dic_file.close()
dic_file = open('big_data_t1.pickle','wb')
pickle.dump(big_data[1], dic_file)
dic_file.close()
# 【读取】pickle
df_file=open('big_data_t0.pickle','rb')
big_data_t0 = pickle.load(df_file)
df_file=open('big_data_t1.pickle','rb')
big_data_t1 = pickle.load(df_file)
big_data = tuple([big_data_t0, big_data_t1])
虽然以下代码会提取Normal IC,但是我们只用因子收益率和对应T值作为打分项
因为数据提取需要漫长的时间,小伙伴们可以直接print下面的代码读取我保存好的数据
# 提取因子收益率、Normal_IC
import time
start = time.clock()
print('Normal_IC 除单调性指标提取中……')
# 因子收益率(回归系数)、因子收益率序列的T值、IC值 三个表格获取
normal_ic_og = get_normal_ic_original_factor_testing_data(stk_return, test_timing, big_data)
# 根据 Normal_IC原始数据,提取各种打分指标
pre_scoring_data_for_normal_ic = get_pre_scoring_data_for_normal_ic(normal_ic_og)
# 提取参照光大的打分表格(单调性指标除外)
normal_ic_prescoring = get_scoring_data_for_normal_ic(pre_scoring_data_for_normal_ic)
# 保存
normal_ic_prescoring.to_csv('normal_ic_pre.csv')
elapsed = (time.clock()- start)
print('所用时间:', elapsed)
Normal_IC 除单调性指标提取中…… 正在进行第1周期因子测试原始数据获取…… 正在进行第2周期因子测试原始数据获取…… 正在进行第3周期因子测试原始数据获取…… 正在进行第4周期因子测试原始数据获取…… 正在进行第5周期因子测试原始数据获取…… 正在进行第6周期因子测试原始数据获取…… 正在进行第7周期因子测试原始数据获取…… 正在进行第8周期因子测试原始数据获取…… 正在进行第9周期因子测试原始数据获取…… 正在进行第10周期因子测试原始数据获取…… 正在进行第11周期因子测试原始数据获取…… 正在进行第12周期因子测试原始数据获取…… 正在进行第13周期因子测试原始数据获取…… 正在进行第14周期因子测试原始数据获取…… 正在进行第15周期因子测试原始数据获取…… 正在进行第16周期因子测试原始数据获取…… 正在进行第17周期因子测试原始数据获取…… 正在进行第18周期因子测试原始数据获取…… 正在进行第19周期因子测试原始数据获取…… 正在进行第20周期因子测试原始数据获取…… 正在进行第21周期因子测试原始数据获取…… 正在进行第22周期因子测试原始数据获取…… 正在进行第23周期因子测试原始数据获取…… 正在进行第24周期因子测试原始数据获取…… 正在进行第25周期因子测试原始数据获取…… 正在进行第26周期因子测试原始数据获取…… 正在进行第27周期因子测试原始数据获取…… 正在进行第28周期因子测试原始数据获取…… 正在进行第29周期因子测试原始数据获取…… 正在进行第30周期因子测试原始数据获取…… 正在进行第31周期因子测试原始数据获取…… 正在进行第32周期因子测试原始数据获取…… 正在进行第33周期因子测试原始数据获取…… 正在进行第34周期因子测试原始数据获取…… 正在进行第35周期因子测试原始数据获取…… 正在进行第36周期因子测试原始数据获取…… 正在进行第37周期因子测试原始数据获取…… 正在进行第38周期因子测试原始数据获取…… 所有周期因子测试在Normal_IC框架下原始数据获取完毕! 所用时间: 20.940897999999834
# 【读取】 Normal_IC打分表格以及单调性表格 ,并且将两个表格合并
normal_ic_pre = pd.read_csv('normal_ic_pre.csv')
normal_ic_pre.index = data.columns
del normal_ic_pre['factor']
scoring_df = normal_ic_pre
scoring_df.T
| gross_profit_margin | net_profit_margin | operating_profit_margin | pretax_margin | ROA | EBIT_OA | ROTC | ROE | inc_total_revenue_annual | inventory_turnover | inventory_processing_period | receivables_turnover | receivables_collection_period | operating_cycle | total_asset_turnover | fixed_assets_turnover | working_capital_turnover | current_ratio | quick_ratio | cash_ratio | debt_to_equity | debt_to_capital | debt_to_assets | financial_leverage | EP | PB | PS | P_CF | alpha | beta | return_1m | return_3m | return_6m | return_12m | wgt_return_1m | wgt_return_3m | wgt_return_6m | wgt_return_12m | exp_wgt_return_1m | exp_wgt_return_3m | exp_wgt_return_6m | exp_wgt_return_12m | std_1m | std_3m | std_6m | std_12m | ln_price | turn_1m | turn_3m | turn_6m | turn_12m | bias_turn_1m | bias_turn_3m | bias_turn_6m | bias_turn_12m | PSY | RSI | BIAS | DIF | DEA | MACD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factor_Mean_Return | 0.024913 | 0.039644 | 0.006964 | 0.008663 | 0.063763 | 0.064521 | 0.066540 | 0.065960 | 0.028127 | 0.006526 | -0.006821 | 0.033949 | -0.038931 | -0.022561 | 0.032482 | -0.006660 | -0.000821 | 0.004220 | 0.001696 | 0.003574 | -0.012076 | -0.016205 | -0.016928 | -0.005443 | 0.052065 | -0.023845 | -0.029597 | 0.025890 | -0.032955 | 0.012726 | -0.035944 | -0.012331 | -0.001606 | -0.001167 | -0.061921 | -0.054796 | -0.048949 | -0.045525 | -0.028063 | -0.031640 | -0.039920 | -0.048847 | -0.051130 | -0.060115 | -0.048649 | -0.047344 | -0.013278 | -0.079870 | -0.069640 | -0.058243 | -0.051794 | -0.062177 | -0.052382 | -0.036574 | -0.027618 | -0.018306 | -0.015904 | -0.028032 | -0.025254 | -0.020726 | -0.015331 |
| Factor_Return_tstat | 0.418934 | 0.748148 | 0.150735 | 0.162242 | 1.202828 | 1.219424 | 1.267310 | 1.232419 | 0.516816 | 0.176312 | -0.150962 | 0.655397 | -0.740874 | -0.397377 | 0.647758 | -0.177082 | -0.008243 | 0.163432 | 0.105801 | 0.118359 | -0.275605 | -0.375970 | -0.396427 | -0.115368 | 1.022297 | -0.465801 | -0.637103 | 0.521274 | -0.578835 | 0.268573 | -0.660557 | -0.070509 | 0.013499 | 0.110115 | -1.310960 | -1.062731 | -1.072732 | -0.975550 | -0.426800 | -0.474831 | -0.697986 | -0.893118 | -1.290042 | -1.408935 | -1.188907 | -1.067332 | -0.186787 | -1.851943 | -1.578883 | -1.299817 | -1.119324 | -1.404706 | -1.130069 | -0.799020 | -0.594777 | -0.352318 | -0.149641 | -0.373485 | -0.427569 | -0.342193 | -0.266390 |
| IC_mean | 0.018613 | 0.036629 | 0.006409 | 0.008379 | 0.056611 | 0.057563 | 0.060059 | 0.059813 | 0.029561 | 0.010008 | -0.006225 | 0.032496 | -0.036580 | -0.018236 | 0.031251 | -0.008715 | -0.000642 | 0.001463 | -0.001362 | 0.000384 | -0.011952 | -0.016153 | -0.017390 | -0.004108 | 0.045627 | -0.023445 | -0.031019 | 0.022805 | -0.027961 | 0.022481 | -0.020221 | -0.001532 | 0.002328 | 0.005556 | -0.041793 | -0.035310 | -0.037342 | -0.035369 | -0.009371 | -0.011785 | -0.020660 | -0.029275 | -0.030390 | -0.039092 | -0.032520 | -0.031116 | -0.010069 | -0.060638 | -0.054226 | -0.047034 | -0.042357 | -0.039580 | -0.033452 | -0.024352 | -0.017027 | -0.003353 | 0.002723 | -0.008961 | -0.010656 | -0.011054 | -0.004207 |
| IR | 0.341608 | 0.549153 | 0.148862 | 0.246074 | 0.738959 | 0.732429 | 0.729736 | 0.733115 | 0.745386 | 0.201865 | -0.100413 | 0.456553 | -0.482462 | -0.270411 | 0.489804 | -0.195926 | -0.012224 | 0.023527 | -0.021770 | 0.006567 | -0.196953 | -0.255183 | -0.284508 | -0.070057 | 0.523168 | -0.277252 | -0.404496 | 0.440555 | -0.347022 | 0.330303 | -0.179444 | -0.012358 | 0.019503 | 0.050443 | -0.466727 | -0.406895 | -0.457959 | -0.421779 | -0.078002 | -0.094172 | -0.168027 | -0.253269 | -0.221266 | -0.295830 | -0.287554 | -0.309132 | -0.114850 | -0.491734 | -0.478225 | -0.469748 | -0.470770 | -0.358945 | -0.337192 | -0.296568 | -0.250094 | -0.045825 | 0.021958 | -0.074638 | -0.096416 | -0.093198 | -0.057466 |
下面一行运行时间有点长,可以直接用我保存好的数据
# 提取除单调性之外的打分表格
# 收益率数据准备
stk_return1 = stk_return.T
# 构建字典,待存放因子Rank_IC值
factor_for_ic = {}
# 构建字典,待存放因子t_value
factor_for_t = {}
# 构建字典,待存放因子parameter
factor_for_parameter = {}
# 遍历所有的T0时间点
for num in range(len(test_timing['T0'])):
print('正在进行第'+str(num+1)+'周期因子测试原始数据获取……')
# 获取单周期的因子值
data = big_data_t0[test_timing['T0'][num]]
data1 = big_data_t1[test_timing['T1'][num]]
# 对于T0有因子值,T1没有的情况,提取T0和T1两个index的交集
data_adj = data.loc[data.index & data1.index,:]
# list1,待存放ic
list1 = []
# list2, 待存放t—value
list2 = []
# list3, 待存放parameter
list3 = []
# 求相关系数和T值,对于第i个因子
for i in range(len(data_adj.columns)):
# 提取单个因子
factor_test = pd.DataFrame(data_adj[data_adj.columns[i]])
# 提取 X
factor_test['X_Rank'] = factor_test.rank(ascending = True, method = 'dense')
X = list(factor_test['X_Rank'])
# 提取 Y
# 提取收益率
stk_group_return = get_single_period_group_return(list(factor_test.index), test_timing)
Y = list(stk_group_return[test_timing['T0'][num]])
# 将单个周期所有因子ic值放到cor中
cor = (list(corrcoef(X, Y)[0])[-1])
# 回归
rlm_model = sm.RLM(Y , X , M=sm.robust.norms.HuberT()).fit()
# 存放相关系数cor
list1.append(cor)
# 存放t_value
list2.append(float(rlm_model.tvalues))
# 存放parameter
list3.append(float(rlm_model.params))
# 相关系数,放到字典里
factor_for_ic[num] = list1
# t_value, 放到字典里
factor_for_t[num] = list2
# parameter, 放到字典里
factor_for_parameter[num] =list3
# 整合
# Normal ICdf整合
rank_ic_df = pd.DataFrame(factor_for_ic)
rank_ic_df.index = data.columns
rank_ic_df.index.name = 'factor'
rank_ic_df.columns = test_timing['T0']
# t值整合
rank_t_df = pd.DataFrame(factor_for_t)
rank_t_df.index = data.columns
rank_t_df.index.name ='factor'
rank_t_df.columns = test_timing['T0']
# Barra体系下的因子收益率(回归系数)整合
rank_param_df = pd.DataFrame(factor_for_parameter)
rank_param_df.index = data.columns
rank_param_df.index.name = 'factor'
rank_param_df.columns = test_timing['T0']
print('所有周期Rank_IC框架下,因子测试原始数据获取完毕!')
正在进行第1周期因子测试原始数据获取…… 正在进行第2周期因子测试原始数据获取…… 正在进行第3周期因子测试原始数据获取…… 正在进行第4周期因子测试原始数据获取…… 正在进行第5周期因子测试原始数据获取…… 正在进行第6周期因子测试原始数据获取…… 正在进行第7周期因子测试原始数据获取…… 正在进行第8周期因子测试原始数据获取…… 正在进行第9周期因子测试原始数据获取…… 正在进行第10周期因子测试原始数据获取…… 正在进行第11周期因子测试原始数据获取…… 正在进行第12周期因子测试原始数据获取…… 正在进行第13周期因子测试原始数据获取…… 正在进行第14周期因子测试原始数据获取…… 正在进行第15周期因子测试原始数据获取…… 正在进行第16周期因子测试原始数据获取…… 正在进行第17周期因子测试原始数据获取…… 正在进行第18周期因子测试原始数据获取…… 正在进行第19周期因子测试原始数据获取…… 正在进行第20周期因子测试原始数据获取…… 正在进行第21周期因子测试原始数据获取…… 正在进行第22周期因子测试原始数据获取…… 正在进行第23周期因子测试原始数据获取…… 正在进行第24周期因子测试原始数据获取…… 正在进行第25周期因子测试原始数据获取…… 正在进行第26周期因子测试原始数据获取…… 正在进行第27周期因子测试原始数据获取…… 正在进行第28周期因子测试原始数据获取…… 正在进行第29周期因子测试原始数据获取…… 正在进行第30周期因子测试原始数据获取…… 正在进行第31周期因子测试原始数据获取…… 正在进行第32周期因子测试原始数据获取…… 正在进行第33周期因子测试原始数据获取…… 正在进行第34周期因子测试原始数据获取…… 正在进行第35周期因子测试原始数据获取…… 正在进行第36周期因子测试原始数据获取…… 正在进行第37周期因子测试原始数据获取…… 正在进行第38周期因子测试原始数据获取…… 所有周期Rank_IC框架下,因子测试原始数据获取完毕!
# 【读取】分层回溯的数据,pickle文档
df_file= open('rank_ic_og.pickle','rb')
rank_ic_og = pickle.load(df_file)
# 【打分】根据 Normal_IC原始数据,提取各种打分指标
pre_scoring_data_for_rank_ic = get_pre_scoring_data_for_rank_ic(rank_ic_og)
# 提取参照光大的打分表格(单调性指标除外)
rank_ic_prescoring = get_scoring_data_for_rank_ic(pre_scoring_data_for_rank_ic)
# 打分
scoring_rank_df = pd.DataFrame()
scoring_rank_df['Factor_Mean_Return'] = normal_ic_pre['Factor_Mean_Return']
scoring_rank_df['Factor_Return_tstat'] = normal_ic_pre['Factor_Return_tstat']
scoring_rank_df['Rank_IC'] = rank_ic_prescoring['Rank_IC']
scoring_rank_df['Rank_IR'] = rank_ic_prescoring['Rank_IR']
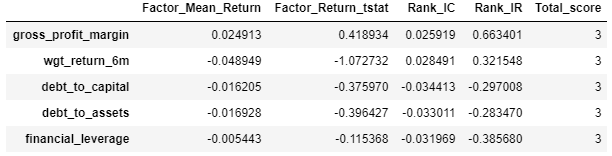
score_result = get_score_data_ir(scoring_rank_df)
score_result.head()
| Factor_Mean_Return | Factor_Return_tstat | Rank_IC | Rank_IR | Total_score | |
|---|---|---|---|---|---|
| gross_profit_margin | 0.024913 | 0.418934 | 0.025919 | 0.663401 | 3 |
| wgt_return_6m | -0.048949 | -1.072732 | 0.028491 | 0.321548 | 3 |
| debt_to_capital | -0.016205 | -0.375970 | -0.034413 | -0.297008 | 3 |
| debt_to_assets | -0.016928 | -0.396427 | -0.033011 | -0.283470 | 3 |
| financial_leverage | -0.005443 | -0.115368 | -0.031969 | -0.385680 | 3 |
# 将总分大于3分的因子提取出来
features_list = []
for i in range(len(score_result)):
if score_result.iloc[i,4] >2:
features_list.append(score_result.index[i])
print('共有'+str(len(features_list))+'个因子分数为三分')
print(features_list)
共有27个因子分数为三分 ['gross_profit_margin', 'wgt_return_6m', 'debt_to_capital', 'debt_to_assets', 'financial_leverage', 'PS', 'alpha', 'beta', 'net_profit_margin', 'std_1m', 'cash_ratio', 'turn_1m', 'turn_3m', 'turn_6m', 'turn_12m', 'bias_turn_1m', 'BIAS', 'DIF', 'debt_to_equity', 'MACD', 'inventory_processing_period', 'fixed_assets_turnover', 'operating_profit_margin', 'pretax_margin', 'total_asset_turnover', 'operating_cycle', 'ROA']
# 回测框架
class parameter_analysis(object):
# 定义函数中不同的变量
def __init__(self, algorithm_id=None):
self.algorithm_id = algorithm_id # 回测id
self.params_df = pd.DataFrame() # 回测中所有调参备选值的内容,列名字为对应修改面两名称,对应回测中的 g.XXXX
self.results = {} # 回测结果的回报率,key 为 params_df 的行序号,value 为
self.evaluations = {} # 回测结果的各项指标,key 为 params_df 的行序号,value 为一个 dataframe
self.backtest_ids = {} # 回测结果的 id
# 新加入的基准的回测结果 id,可以默认为空 '',则使用回测中设定的基准
self.benchmark_id = ''
self.benchmark_returns = [] # 新加入的基准的回测回报率
self.returns = {} # 记录所有回报率
self.excess_returns = {} # 记录超额收益率
self.log_returns = {} # 记录收益率的 log 值
self.log_excess_returns = {} # 记录超额收益的 log 值
self.dates = [] # 回测对应的所有日期
self.excess_max_drawdown = {} # 计算超额收益的最大回撤
self.excess_annual_return = {} # 计算超额收益率的年化指标
self.evaluations_df = pd.DataFrame() # 记录各项回测指标,除日回报率外
# 定义排队运行多参数回测函数
def run_backtest(self, #
algorithm_id=None, # 回测策略id
running_max=10, # 回测中同时巡行最大回测数量
start_date='2016-01-01', # 回测的起始日期
end_date='2016-04-30', # 回测的结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测的初始持仓金额
param_names=[], # 回测中调整参数涉及的变量
param_values=[] # 回测中每个变量的备选参数值
):
# 当此处回测策略的 id 没有给出时,调用类输入的策略 id
if algorithm_id == None: algorithm_id=self.algorithm_id
# 生成所有参数组合并加载到 df 中
# 包含了不同参数具体备选值的排列组合中一组参数的 tuple 的 list
param_combinations = list(itertools.product(*param_values))
# 生成一个 dataframe, 对应的列为每个调参的变量,每个值为调参对应的备选值
to_run_df = pd.DataFrame(param_combinations)
# 修改列名称为调参变量的名字
to_run_df.columns = param_names
to_run_df['backtestID']=''
to_run_df['state']='waiting'
to_run_df['times']=0
# 设定运行起始时间和保存格式
start = time.time()
# 记录结束的运行回测
finished_backtests = {}
# 记录运行中的回测
running_backtests = {}
failed_backtests={}
running_count=0
# 总运行回测数目,等于排列组合中的元素个数
total_backtest_num = len(param_combinations)
# 记录回测结果的回报率
all_results = {}
# 记录回测结果的各项指标
all_evaluations = {}
# 在运行开始时显示
print('【已完成|运行中|待运行||失败】:' )
# 当运行回测开始后,如果没有全部运行完全的话:
while len(to_run_df[(to_run_df.state=='waiting') | (to_run_df.state=='running')].index)>0:
# 显示运行、完成和待运行的回测个数
print('[%s|%s|%s||%s].' % (len(finished_backtests),
len(running_backtests),
(total_backtest_num-len(finished_backtests)-len(running_backtests)- len(failed_backtests)),
len(failed_backtests)
)),
# 把可用的空位进行跑回测
for index in (to_run_df[to_run_df.state=='waiting'].index):
# 备选的参数排列组合的 df 中第 i 行变成 dict,每个 key 为列名字,value 为 df 中对应的值
if running_count>=running_max:
continue
params = to_run_df.ix[index,param_names].to_dict()
# 记录策略回测结果的 id,调整参数 extras 使用 params 的内容
backtest = create_backtest(algorithm_id = algorithm_id,
start_date = start_date,
end_date = end_date,
frequency = frequency,
initial_cash = initial_cash,
extras = params,
# 再回测中把改参数的结果起一个名字,包含了所有涉及的变量参数值
name =str( params).replace('{','').replace('}','').replace('\'','')
)
# 记录运行中 i 回测的回测 id
to_run_df.at[index,'backtestID'] = backtest
to_run_df.at[index,'state']='running'
to_run_df.at[index,'times']=to_run_df.at[index,'times']+1
running_count=running_count+1
# 获取回测结果
failed = []
finished = []
# 对于运行中的回测,key 为 to_run_df 中所有排列组合中的序数
for index in to_run_df[to_run_df.state=='running'].index:
# 研究调用回测的结果,running_backtests[key] 为运行中保存的结果 id
bt = get_backtest(to_run_df.at[index,'backtestID'])
# 获得运行回测结果的状态,成功和失败都需要运行结束后返回,如果没有返回则运行没有结束
status = bt.get_status()
# 当运行回测失败
if status in [ 'failed','canceled','deleted']:
# 失败 list 中记录对应的回测结果 id
failed.append(index)
# 当运行回测成功时
elif status == 'done':
# 成功 list 记录对应的回测结果 id,finish 仅记录运行成功的
finished.append(index)
# 回测回报率记录对应回测的回报率 dict, key to_run_df 中所有排列组合中的序数, value 为回报率的 dict
# 每个 value 一个 list 每个对象为一个包含时间、日回报率和基准回报率的 dict
all_results[index] = bt.get_results()
# 回测回报率记录对应回测结果指标 dict, key to_run_df 中所有排列组合中的序数, value 为回测结果指标的 dataframe
all_evaluations[index] = bt.get_risk()
# 记录运行中回测结果 id 的 list 中删除失败的运行
for index in failed:
if to_run_df.at[index,'times']<3:
to_run_df.at[index,'state']='waiting'
else:
to_run_df.at[index,'state']='failed'
# 在结束回测结果 dict 中记录运行成功的回测结果 id,同时在运行中的记录中删除该回测
for index in finished:
to_run_df.at[index,'state']='done'
running_count=len(to_run_df[to_run_df.state=='running'].index)
running_backtests=to_run_df[to_run_df.state=='running']['backtestID'].to_dict()
finished_backtests=to_run_df[to_run_df.state=='done']['backtestID'].to_dict()
failed_backtests=to_run_df[to_run_df.state=='failed']['backtestID'].to_dict()
# 当一组同时运行的回测结束时报告时间
if len(finished_backtests) != 0 and len(finished_backtests) % running_max == 0 :
# 记录当时时间
middle = time.time()
# 计算剩余时间,假设没工作量时间相等的话
remain_time = (middle - start) * (total_backtest_num - len(finished_backtests)) / len(finished_backtests)
# print 当前运行时间
print('[已用%s时,尚余%s时,请不要关闭浏览器].' % (str(round((middle - start) / 60.0 / 60.0,3)),
str(round(remain_time / 60.0 / 60.0,3)))),
# 5秒钟后再跑一下
time.sleep(5)
# 记录结束时间
end = time.time()
print('')
print('【回测完成】总用时:%s秒(即%s小时)。' % (str(int(end-start)),
str(round((end-start)/60.0/60.0,2)))),
# 对应修改类内部对应
self.params_df = to_run_df.ix[:,param_names]
self.results = all_results
self.evaluations = all_evaluations
self.backtest_ids = finished_backtests
#7 最大回撤计算方法
def find_max_drawdown(self, returns):
# 定义最大回撤的变量
result = 0
# 记录最高的回报率点
historical_return = 0
# 遍历所有日期
for i in range(len(returns)):
# 最高回报率记录
historical_return = max(historical_return, returns[i])
# 最大回撤记录
drawdown = 1-(returns[i] + 1) / (historical_return + 1)
# 记录最大回撤
result = max(drawdown, result)
# 返回最大回撤值
return result
# log 收益、新基准下超额收益和相对与新基准的最大回撤
def organize_backtest_results(self, benchmark_id=None):
# 若新基准的回测结果 id 没给出
if benchmark_id==None:
# 使用默认的基准回报率,默认的基准在回测策略中设定
self.benchmark_returns = [x['benchmark_returns'] for x in self.results[0]]
# 当新基准指标给出后
else:
# 基准使用新加入的基准回测结果
self.benchmark_returns = [x['returns'] for x in get_backtest(benchmark_id).get_results()]
# 回测日期为结果中记录的第一项对应的日期
self.dates = [x['time'] for x in self.results[0]]
# 对应每个回测在所有备选回测中的顺序 (key),生成新数据
# 由 {key:{u'benchmark_returns': 0.022480100091729405,
# u'returns': 0.03184566700000002,
# u'time': u'2006-02-14'}} 格式转化为:
# {key: []} 格式,其中 list 为对应 date 的一个回报率 list
for key in self.results.keys():
self.returns[key] = [x['returns'] for x in self.results[key]]
# 生成对于基准(或新基准)的超额收益率
for key in self.results.keys():
self.excess_returns[key] = [(x+1)/(y+1)-1 for (x,y) in zip(self.returns[key], self.benchmark_returns)]
# 生成 log 形式的收益率
for key in self.results.keys():
self.log_returns[key] = [log(x+1) for x in self.returns[key]]
# 生成超额收益率的 log 形式
for key in self.results.keys():
self.log_excess_returns[key] = [log(x+1) for x in self.excess_returns[key]]
# 生成超额收益率的最大回撤
for key in self.results.keys():
self.excess_max_drawdown[key] = self.find_max_drawdown(self.excess_returns[key])
# 生成年化超额收益率
for key in self.results.keys():
self.excess_annual_return[key] = (self.excess_returns[key][-1]+1)**(252./float(len(self.dates)))-1
# 把调参数据中的参数组合 df 与对应结果的 df 进行合并
self.evaluations_df = pd.concat([self.params_df, pd.DataFrame(self.evaluations).T], axis=1)
# self.evaluations_df =
# 获取最总分析数据,调用排队回测函数和数据整理的函数
def get_backtest_data(self,
algorithm_id=None, # 回测策略id
benchmark_id=None, # 新基准回测结果id
file_name='results1.pkl', # 保存结果的 pickle 文件名字
running_max=10, # 最大同时运行回测数量
start_date='2006-01-01', # 回测开始时间
end_date='2016-11-30', # 回测结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测初始持仓资金
param_names=[], # 回测需要测试的变量
param_values=[] # 对应每个变量的备选参数
):
# 调运排队回测函数,传递对应参数
self.run_backtest(algorithm_id=algorithm_id,
running_max=running_max,
start_date=start_date,
end_date=end_date,
frequency=frequency,
initial_cash=initial_cash,
param_names=param_names,
param_values=param_values
)
# 回测结果指标中加入 log 收益率和超额收益率等指标
self.organize_backtest_results(benchmark_id)
# 生成 dict 保存所有结果。
results = {'returns':self.returns,
'excess_returns':self.excess_returns,
'log_returns':self.log_returns,
'log_excess_returns':self.log_excess_returns,
'dates':self.dates,
'benchmark_returns':self.benchmark_returns,
'evaluations':self.evaluations,
'params_df':self.params_df,
'backtest_ids':self.backtest_ids,
'excess_max_drawdown':self.excess_max_drawdown,
'excess_annual_return':self.excess_annual_return,
'evaluations_df':self.evaluations_df}
# 保存 pickle 文件
pickle_file = open(file_name, 'wb')
pickle.dump(results, pickle_file)
pickle_file.close()
# 读取保存的 pickle 文件,赋予类中的对象名对应的保存内容
def read_backtest_data(self, file_name='results.pkl'):
pickle_file = open(file_name, 'rb')
results = pickle.load(pickle_file)
self.returns = results['returns']
self.excess_returns = results['excess_returns']
self.log_returns = results['log_returns']
self.log_excess_returns = results['log_excess_returns']
self.dates = results['dates']
self.benchmark_returns = results['benchmark_returns']
self.evaluations = results['evaluations']
self.params_df = results['params_df']
self.backtest_ids = results['backtest_ids']
self.excess_max_drawdown = results['excess_max_drawdown']
self.excess_annual_return = results['excess_annual_return']
self.evaluations_df = results['evaluations_df']
# 回报率折线图
def plot_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.returns[key])), self.returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), self.benchmark_returns, label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.returns[0]))
# 多空组合图
def plot_long_short(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
a1 = [i+1 for i in self.returns[0]]
a2 = [i+1 for i in self.returns[4]]
a1.insert(0,1)
a2.insert(0,1)
b = []
for i in range(len(a1)-1):
b.append((a1[i+1]/a1[i]-a2[i+1]/a2[i])/2)
c = []
c.append(1)
for i in range(len(b)):
c.append(c[i]*(1+b[i]))
ax.plot(range(len(c)), c)
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
ax.set_title("Strategy's long_short performances",fontsize=20)
# 设置图片标题样式
plt.xlim(0, len(c))
# 获取不同年份的收益及排名分析
def get_profit_year(self):
profit_year = {}
for key in self.returns.keys():
temp = []
date_year = []
for i in range(len(self.dates)-1):
if self.dates[i][:4] != self.dates[i+1][:4]:
temp.append(self.returns[key][i])
date_year.append(self.dates[i][:4])
temp.append(self.returns[key][-1])
date_year.append(self.dates[-1][:4])
temp1 = []
temp1.append(temp[0])
for i in range(len(temp)-1):
temp1.append((temp[i+1]+1)/(temp[i]+1)-1)
profit_year[key] = temp1
result = pd.DataFrame(index = list(self.returns.keys()), columns = date_year)
for key in self.returns.keys():
result.loc[key,:] = profit_year[key]
return result
# 超额收益率图
def plot_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.excess_returns[key])), self.excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('excess returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.excess_returns[0]))
# log回报率图
def plot_log_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_returns[key])), self.log_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [log(x+1) for x in self.benchmark_returns], label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_returns[0]))
# 超额收益率的 log 图
def plot_log_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_excess_returns[key])), self.log_excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log excess returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_excess_returns[0]))
# 回测的4个主要指标,包括总回报率、最大回撤夏普率和波动
def get_eval4_bar(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
fig = plt.figure(figsize=(20,7))
# 定义位置
ax1 = fig.add_subplot(221)
# 设定横轴为对应分位,纵轴为对应指标
ax1.bar(range(len(indices)),
[self.evaluations[x]['algorithm_return'] for x in indices], 0.6, label = 'Algorithm_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax1.legend(loc='best',fontsize=15)
# 设置y标签样式
ax1.set_ylabel('Algorithm_return', fontsize=15)
# 设置y标签样式
ax1.set_yticklabels([str(x*100)+'% 'for x in ax1.get_yticks()])
# 设置图片标题样式
ax1.set_title("Strategy's of Algorithm_return performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax2 = fig.add_subplot(224)
# 设定横轴为对应分位,纵轴为对应指标
ax2.bar(range(len(indices)),
[self.evaluations[x]['max_drawdown'] for x in indices], 0.6, label = 'Max_drawdown')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax2.legend(loc='best',fontsize=15)
# 设置y标签样式
ax2.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax2.set_yticklabels([str(x*100)+'% 'for x in ax2.get_yticks()])
# 设置图片标题样式
ax2.set_title("Strategy's of Max_drawdown performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax3 = fig.add_subplot(223)
# 设定横轴为对应分位,纵轴为对应指标
ax3.bar(range(len(indices)),
[self.evaluations[x]['sharpe'] for x in indices], 0.6, label = 'Sharpe')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax3.legend(loc='best',fontsize=15)
# 设置y标签样式
ax3.set_ylabel('Sharpe', fontsize=15)
# 设置x标签样式
ax3.set_yticklabels([str(x*100)+'% 'for x in ax3.get_yticks()])
# 设置图片标题样式
ax3.set_title("Strategy's of Sharpe performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax4 = fig.add_subplot(222)
# 设定横轴为对应分位,纵轴为对应指标
ax4.bar(range(len(indices)),
[self.evaluations[x]['algorithm_volatility'] for x in indices], 0.6, label = 'Algorithm_volatility')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax4.legend(loc='best',fontsize=15)
# 设置y标签样式
ax4.set_ylabel('Algorithm_volatility', fontsize=15)
# 设置x标签样式
ax4.set_yticklabels([str(x*100)+'% 'for x in ax4.get_yticks()])
# 设置图片标题样式
ax4.set_title("Strategy's of Algorithm_volatility performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
#14 年化回报和最大回撤,正负双色表示
def get_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.evaluations[x]['max_drawdown'] for x in indices], color = '#32CD32',
width = 0.6, label = 'Max_drawdown', zorder=10)
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.evaluations[x]['annual_algo_return'] for x in indices], color = 'r',
width = 0.6, label = 'Annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
#14 超额收益的年化回报和最大回撤
# 加入新的benchmark后超额收益和
def get_excess_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.excess_max_drawdown[x] for x in indices], color = '#32CD32',
width = 0.6, label = 'Excess_max_drawdown')
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.excess_annual_return[x] for x in indices], color = 'r',
width = 0.6, label = 'Excess_annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
def group_backtest(start_date,end_date):
warnings.filterwarnings("ignore")
pa = parameter_analysis('78c119654ae4be5678a2e92ac6565b3f')
pa.get_backtest_data(file_name = 'results_1.pkl',
running_max = 5,
start_date=start_date,
end_date=end_date,
frequency = 'day',
initial_cash = '10000000',
param_names = ['factor', 'quantile'],#变量名,即在策略中的g.xxxx变量
param_values = [['svm'], tuple(zip(range(0,50,10), range(10,51,10)))]
)
# 写入自己的回测id
pa = parameter_analysis('f66b0e48aa76014f1b68a6823b3a123e')
# 回测开始(需要回测拿一个就用拿一个的facor)
# PS: 有一些因子在研究环境可以print,但是在策略环境中就不行,这个有点尴尬,不过绝大多数的因子还是可以共用两个环境的
factor = 'gross_profit_margin'
pa.get_backtest_data(file_name = 'results.pkl',
running_max = 10,
benchmark_id = None,
start_date = '2012-01-01',#回测开始日期,自己设定
end_date = '2019-01-23',#回测结束日期,自己设定
frequency = 'day',
initial_cash = '1000000',
param_names = ['factor', 'quantile'],
param_values = [[factor], tuple(zip(range(0,100,10), range(10,101,10)))]#因子,自己设定,测试哪个就写哪个
)
【已完成|运行中|待运行||失败】: [0|0|10||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [0|10|0||0]. [3|7|0||0]. [6|4|0||0]. [7|3|0||0]. [7|3|0||0]. [7|3|0||0]. [7|3|0||0]. [7|3|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [8|2|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [9|1|0||0]. [已用0.143时,尚余0.0时,请不要关闭浏览器]. 【回测完成】总用时:519秒(即0.14小时)。
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-22-2c7ea77bc281> in <module> 10 initial_cash = '1000000', 11 param_names = ['factor', 'quantile'], ---> 12 param_values = [[factor], tuple(zip(range(0,100,10), range(10,101,10)))]#因子,自己设定,测试哪个就写哪个 13 ) <ipython-input-20-6a900666cd20> in get_backtest_data(self, algorithm_id, benchmark_id, file_name, running_max, start_date, end_date, frequency, initial_cash, param_names, param_values) 242 ) 243 # 回测结果指标中加入 log 收益率和超额收益率等指标 --> 244 self.organize_backtest_results(benchmark_id) 245 # 生成 dict 保存所有结果。 246 results = {'returns':self.returns, <ipython-input-20-6a900666cd20> in organize_backtest_results(self, benchmark_id) 204 # 生成 log 形式的收益率 205 for key in self.results.keys(): --> 206 self.log_returns[key] = [log(x+1) for x in self.returns[key]] 207 # 生成超额收益率的 log 形式 208 for key in self.results.keys(): <ipython-input-20-6a900666cd20> in <listcomp>(.0) 204 # 生成 log 形式的收益率 205 for key in self.results.keys(): --> 206 self.log_returns[key] = [log(x+1) for x in self.returns[key]] 207 # 生成超额收益率的 log 形式 208 for key in self.results.keys(): TypeError: 'Logger' object is not callable
# 分层回测结果
pa.plot_returns()

# 多空净值看单调
pa.plot_long_short()
No handles with labels found to put in legend.

# 其他结果
pa.get_eval4_bar()

下面说一下对于这个因子筛选框架的待解决问题和对于该问题的一些思考:
上网查了一下知乎,发现有一篇讲因子测试的知乎推文讲的蛮好的(知乎求职广告打得很溜,学习了):https://zhuanlan.zhihu.com/p/31733061
Fama和Barra两个体系下的因子指标定义or介绍(主要是两位大佬对因子暴露理解不一样,其他个人认为还好),链接: https://henix.github.io/feeds/zhuanlan.factor-investing/2018-08-05-41339443.html
IC相关介绍,请看:《关于多因子模型的“IC信息系数”那些事》 https://zhuanlan.zhihu.com/p/24616859

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...







