一直都在琢磨怎样将最先进的技术应用于量化分析,自然语言处理作为人工智能领域最重要的技术之一,在量化方面同样具有研究价值,据我所知许多机构团队都在做这方面研究,而且取得不错的效果。自然语言处理可以从舆论中提取行为金融学和市场情绪信息。我试着把自己学习到的这方面知识和思考和大家分享。
一、自然语言处理为什么可以应用于量化分析
传统的量化分析数据基本都是数字型,包括宏观数据、行业数据、企业基本面数据以及行情数据等。每一位宽客使用的数据源基本相同,更多的是在量化思想和算法上探索策略。但是,经验告诉我们,市场情绪很大程度上受舆论氛围影响,财经新闻一定程度上反应对市场是悲观还是乐观,对行业的关注程度、措辞的情感、经济学家的言论等都会影响到行情走势。总之,财经舆论中含有有价值的信息。若能将此类信息提取,将会拓展量化分析的数据源,增加分析维度,这无疑是一件有意义的事情。
二、怎样将自然语言处理应用于量化分析
将自然语言处理技术应用于量化分析的方法多种多样,例如将不同性质的词分类,使用贝叶斯定理计算概率,或者建立语料库,使用GRU、LSTM等神经网络算法进行情感分析。本文后面代码实现第二种方法,无论那种方法都需要有训练数据,建立语料库是一件繁琐的事情,本文后面实例采用已经共享的语料,但是语料并非金融领域。如果能构建金融领域语料,算法可以直接移植。希望手上有金融语料的小伙伴可以分享,共同开发。
三、自然语言处理基础知识
(一)词向量
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是用来表示词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌入(word embedding)。近年来,词嵌入已逐渐成为自然语言处理的基础知识。
简单的做法是使用one-hot编码,就像我们在对行业中性化时使用的方法,虽然one-hot词向量构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。对于向量 x,y∈Rdx,y∈Rd ,它们的余弦相似度是它们之间夹角的余弦值。由于任何两个不同词的one-hot向量是正交的,余弦相似度都为0,多个不同词之间的相似度难以通过one-hot向量准确地体现出来,这就损失了大量的信息。
为了解决上面这个问题 ,将每个词表示成一个定长的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系。通常有两个模型,即跳字模型(skip-gram) 和连续词袋模型(continuous bag of words,CBOW)。关于这两个模型的的具体算法和训练有兴趣的小伙伴可以深入学习,即使不懂也没有关系,不影响后面的使用,因为这些工作已经有成熟的团队做好并分享出来。我们只需要理解词向量是什么,便可以做后续工作。
目前比较好的预训练词向量是北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者开源的"chinese-word-vectors"
幸运的是,此预训练词向量库中有专门的供金融领域使用。
对于做量化的小伙伴来说,有了词向量,自然语言处理大部分繁琐的工作都免去了,后面的工作就变的轻松多了。
(二)中文分词
有了词向量之后,接下来就要对语言分词,将文章分词后的每一个词语都会找到对应的词向量,这样,我们就成功的将文字信息转化成了数字信息,再作为神经网络或者其他机器学习算法的输入数据。
中文分词用到的是中科院的jieba库。
(三)语料
语料的意思是训练数据库,本文使用了谭松波老师的酒店评论语料,我会分享给大家。此语料共有2000个正例和2000个反例,共有4000个训练样本,这样大小的样本数据在NLP中属于非常小的。构建语料是一件繁琐的工作,但是语料的数量和质量直接影响到训练结果,非常希望有金融语料的小伙伴共同分享。缺乏语料是大部分小伙伴无法将自然语言处理用于量化分析的主要原因。建议聚宽平台可以发起一个项目,大家可以共同参与,一起建立金融语料,共同开发,毕竟人多力量大。
本文下面的实例是从网上引用,为自然语言处理用于量化分析提供了很好的思路。如果有金融语料,可以直接移植。
本文的后续实现采用了tensorflow,
本文内容大部分非原创,借用前人内容,只是在思路上向金融量化靠近。
需要的库
numpy
jieba 用于分词
gensim 用于加载预训练的词向量
tensorflow 用于构建神经网络
matplotlib
# 首先加载必用的库import numpy as npimport matplotlib.pyplot as pltimport reimport jieba # 结巴分词# gensim用来加载预训练word vectorfrom gensim.models import KeyedVectorsimport warningswarnings.filterwarnings("ignore")导入预训练词向量
本文使用了北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者开源的"chinese-word-vectors"
提取码:pp2z
将下载的文件解压到自己指定的目录,由于聚宽云平台上存储空间有限,本文未使用金融行业词向量,因为这个要1.2G左右,所以使用知乎内容训练的词向量,如果在本机跑数据,直接更换即可。
# 使用gensim加载预训练中文分词embeddingcn_model = KeyedVectors.load_word2vec_format('sgns.zhihu.bigram',
binary=False)词向量模型
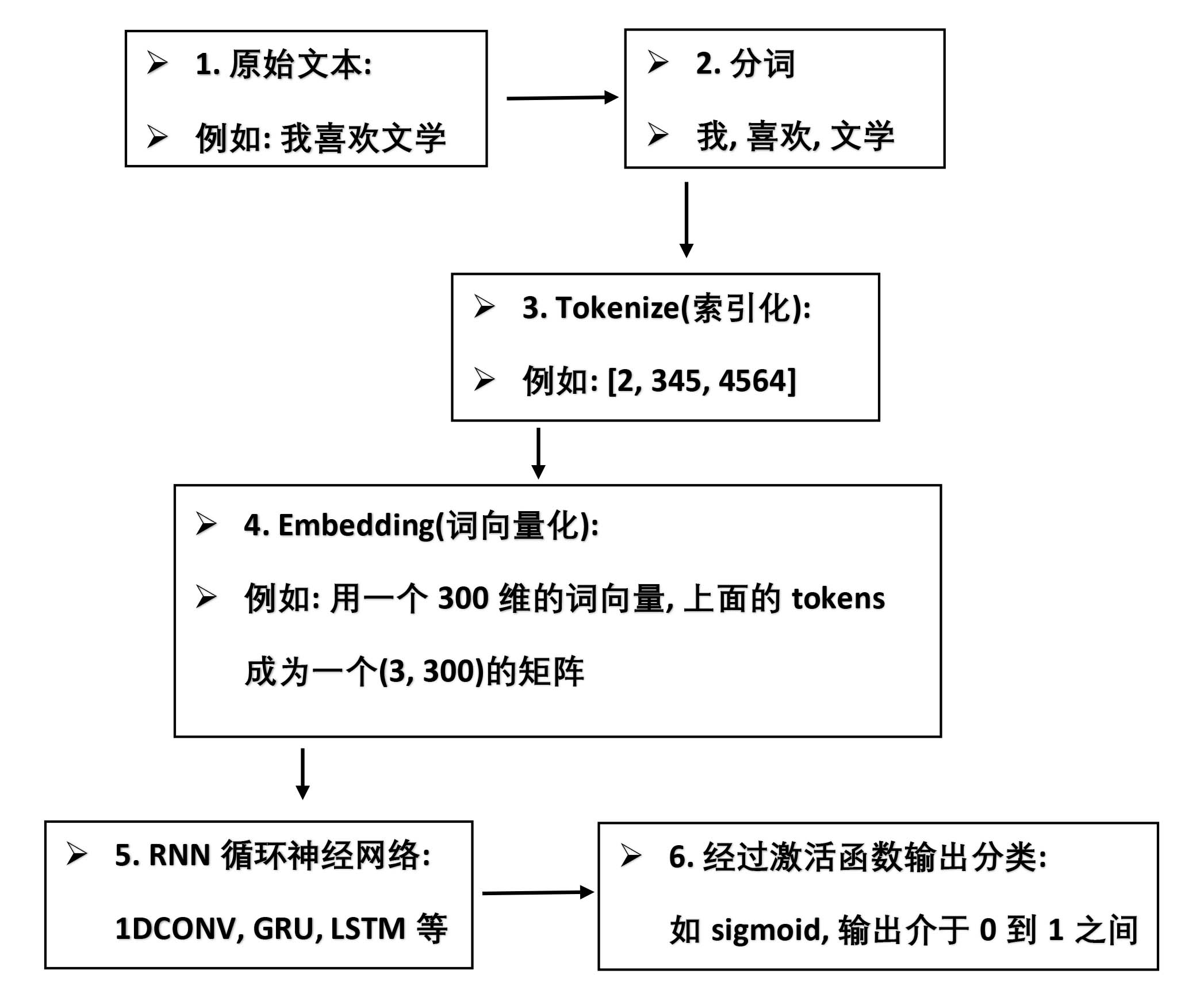
在这个词向量模型里,每一个词是一个索引,对应的是一个长度为300的向量,我们今天需要构建的LSTM神经网络模型并不能直接处理汉字文本,需要先进行分次并把词汇转换为词向量。
第一步:使用jieba进行分词,将文章句子转化成切分成词语
第二步:将词语索引化,加载的词向量模型中包括所有中文词语,按照使用频率大小排列,每个词语对应一个索引值
第三步:词向量化。每个索引对应一个词向量,词向量就是用向量方式描述词语,成功实现由语言向数值的转换。一般常用的词向量都是300维的,也就是说一个汉语词语用一个300维的向量表示,向量数值已经标准化,取值在[-1,1]之间
第四步:构建循环神经网络,可以使用RNN,GRU,LSTM具体那个方法好取决于不同的问题,需要多尝试。
第五步:使用构建好的语料训练神经网络,最后用训练好的神经网络做预测。
# 由此可见每一个词都对应一个长度为300的向量,取值在[-1,1]之间embedding_dim = cn_model['经济'].shape[0]print('词向量的长度为{}'.format(embedding_dim))cn_model['经济']词向量的长度为300
array([-2.396690e-01, -3.567240e-01, 4.677700e-01, 2.141670e-01, -3.500290e-01, 4.018380e-01, 4.653440e-01, 5.534600e-02, 6.083980e-01, 5.947400e-02, -1.625660e-01, -8.766720e-01, 9.338880e-01, -2.870250e-01, 1.140090e-01, -5.247980e-01, -1.589250e-01, 6.000930e-01, -1.897780e-01, -4.909920e-01, -9.078330e-01, -3.205800e-01, -5.568500e-02, -3.721040e-01, -5.866070e-01, 6.174240e-01, 2.401990e-01, -1.458610e-01, -3.530770e-01, -1.605180e-01, -9.974810e-01, 4.631440e-01, 5.570830e-01, -3.614700e-01, 4.148400e-01, 2.875030e-01, 4.653940e-01, 8.227210e-01, -1.010968e+00, 7.174100e-02, -3.356350e-01, -1.347710e-01, -1.587090e-01, -3.270040e-01, -4.501400e-01, 9.417530e-01, 2.876830e-01, -9.110630e-01, 6.963410e-01, 4.072300e-01, -1.278500e-01, -4.103610e-01, -9.203600e-02, 4.585510e-01, -3.342900e-02, 5.387000e-02, -1.006304e+00, 8.692700e-02, -1.047476e+00, 7.075440e-01, 3.545700e-02, -7.266920e-01, 4.257520e-01, 3.456520e-01, 7.412360e-01, 6.224470e-01, -7.271400e-02, -1.422410e-01, -4.692200e-01, 3.464910e-01, -6.772900e-02, 3.606330e-01, -4.774120e-01, -4.083100e-02, 3.844860e-01, -4.429360e-01, 7.991900e-01, 2.974500e-02, 4.860380e-01, -4.036300e-01, -4.771270e-01, 3.438810e-01, -2.092600e-01, 3.028080e-01, -7.325400e-02, -2.499460e-01, -1.755500e-01, -6.635370e-01, 4.466530e-01, 2.767070e-01, 8.363700e-02, 2.469910e-01, -3.914760e-01, -5.252300e-01, 5.871400e-01, -8.774930e-01, -5.951000e-01, -1.538680e-01, -5.894520e-01, 3.646890e-01, 2.173200e-02, 2.905020e-01, 2.942850e-01, -9.107460e-01, 7.130000e-03, -1.637040e-01, 3.258820e-01, 1.523470e-01, 1.634920e-01, 3.563770e-01, 6.760130e-01, -4.606400e-02, 1.657130e-01, -4.491630e-01, 6.945020e-01, -2.995250e-01, -5.785520e-01, -8.837800e-01, 1.311330e-01, -6.266160e-01, 3.861030e-01, -4.896980e-01, 2.926410e-01, -1.736290e-01, -4.847690e-01, -3.627800e-01, -1.531190e-01, 6.630610e-01, 5.853300e-02, -1.242330e-01, -1.346705e+00, -1.624240e-01, -2.445880e-01, -2.930160e-01, -2.915000e-01, 2.062850e-01, 4.947310e-01, 9.186500e-02, 2.065520e-01, -5.160920e-01, -1.328098e+00, -3.203380e-01, -3.327640e-01, -3.168090e-01, 1.161072e+00, -6.144800e-01, 1.657420e-01, -1.801400e-01, 1.539300e-02, 5.503800e-02, -1.246780e-01, -2.087320e-01, -3.451090e-01, 1.056183e+00, 6.571700e-02, 1.501530e-01, 7.759740e-01, 2.417140e-01, 8.249940e-01, -1.267720e-01, -6.420160e-01, 3.265010e-01, -4.800470e-01, -1.129058e+00, 6.980720e-01, -2.922740e-01, -5.546340e-01, 7.632400e-02, 1.305360e-01, -8.170800e-02, 6.318200e-02, -3.938130e-01, -1.220160e-01, 9.245180e-01, 3.308060e-01, 2.319940e-01, 6.100150e-01, 3.882970e-01, 2.141180e-01, -6.167720e-01, -6.032300e-02, -4.954190e-01, 8.221720e-01, 4.844350e-01, 9.184220e-01, 2.808570e-01, 8.291180e-01, -9.605700e-02, 9.154800e-01, 4.191600e-02, -6.156900e-02, 8.039500e-02, 3.878950e-01, 3.293940e-01, -1.280560e-01, 2.398880e-01, -3.472300e-01, -6.469200e-02, -3.757200e-01, 5.318150e-01, -2.422990e-01, 8.999340e-01, -2.369120e-01, 8.697540e-01, -5.668770e-01, -5.031100e-01, -2.780000e-03, 6.453220e-01, -3.178610e-01, -4.594980e-01, 1.635440e-01, 3.803330e-01, -3.352420e-01, 3.750950e-01, 7.458900e-01, 8.752570e-01, -4.022000e-01, 2.241820e-01, -2.435550e-01, 8.788200e-02, 1.499270e-01, -1.418900e-01, -8.153700e-02, -7.199810e-01, 5.339580e-01, -3.651480e-01, -3.889490e-01, -4.812870e-01, -4.227000e-03, 9.219700e-02, -4.594130e-01, -1.257910e-01, 1.233135e+00, -3.365700e-02, 2.034940e-01, 4.231740e-01, -3.840330e-01, 1.037215e+00, -4.234000e-03, -1.616330e-01, -5.090250e-01, -2.272190e-01, -8.890700e-02, -1.558140e-01, -8.038340e-01, -9.874400e-02, 5.564860e-01, -1.044699e+00, 4.494040e-01, -3.383300e-02, 3.238380e-01, 1.070323e+00, 3.617810e-01, -1.439320e-01, -7.328900e-01, 3.132720e-01, 8.950000e-04, 3.836680e-01, -4.693520e-01, -2.376270e-01, 1.563370e-01, -3.266340e-01, 2.377840e-01, 9.014000e-02, -5.491140e-01, -1.688840e-01, 9.014340e-01, -6.530700e-02, -4.275410e-01, -4.609910e-01, 5.701430e-01, -9.849820e-01, -1.924640e-01, -1.642360e-01, -2.360110e-01, -3.353050e-01, 1.025720e-01, 3.607090e-01, 1.547120e-01, 1.568580e-01, 2.841010e-01, 3.820600e-01, 1.867240e-01, -1.483470e-01, 4.533820e-01, -5.153370e-01, -1.071630e-01, -4.341560e-01, 5.763650e-01, 6.109820e-01, -3.946330e-01, 3.435790e-01, 2.951080e-01, 6.270620e-01, 6.202350e-01, -1.834110e-01, 2.478530e-01, -3.715410e-01, -2.154660e-01, 6.356240e-01], dtype=float32)
模型自带的api可以计算相似度,原理是计算两个向量的余弦相似度,即向量点乘后除以两个向量的模。
# 计算相似度cn_model.similarity('橘子', '橙子')0.71512985
# dot('橘子'/|'橘子'|, '橙子'/|'橙子'| )np.dot(cn_model['橘子']/np.linalg.norm(cn_model['橘子']), cn_model['橙子']/np.linalg.norm(cn_model['橙子']))
0.71512985
# 找出最相近的10个词,余弦相似度,此功能可用于扩大同类词范围,在使用贝叶斯方法时,可以填充备选词库cn_model.most_similar(positive=['牛市'], topn=10)
# 找出不同的词test_words = '老师 会计师 程序员 律师 医生 老人'test_words_result = cn_model.doesnt_match(test_words.split())print('在 '+test_words+' 中:\n不是同一类别的词为: %s' %test_words_result)在 老师 会计师 程序员 律师 医生 老人 中: 不是同一类别的词为: 老人
#cn_model.most_similar(positive=['女人','女儿'], negative=['男人'], topn=1)
训练语料
语料下载和上面词向量云盘下载在一个地方。
解压后分别为pos和neg,每个文件夹里有2000个txt文件,每个文件内有一段评语,共有4000个训练样本,这样大小的样本数据在NLP中属于非常迷你的:
# 获得样本的索引,样本存放于两个文件夹中,# 分别为 正面评价'pos'文件夹 和 负面评价'neg'文件夹# 每个文件夹中有2000个txt文件,每个文件中是一例评价import ospos_txts = os.listdir('pos')neg_txts = os.listdir('neg')print( '样本总共: '+ str(len(pos_txts) + len(neg_txts)) )
样本总共: 4000
# 现在我们将所有的评价内容放置到一个list里train_texts_orig = [] # 存储所有评价,每例评价为一条string# 添加完所有样本之后,train_texts_orig为一个含有4000条文本的list# 其中前2000条文本为正面评价,后2000条为负面评价for i in range(len(pos_txts)):with open('pos/'+pos_txts[i], 'r', errors='ignore') as f:text = f.read().strip()train_texts_orig.append(text)for i in range(len(neg_txts)):with open('neg/'+neg_txts[i], 'r', errors='ignore') as f:text = f.read().strip()train_texts_orig.append(text)len(train_texts_orig)
4000
# 我们使用tensorflow的keras接口来建模from tensorflow.python.keras.models import Sequentialfrom tensorflow.python.keras.layers import Dense, GRU, Embedding, LSTM, Bidirectionalfrom tensorflow.python.keras.preprocessing.text import Tokenizerfrom tensorflow.python.keras.preprocessing.sequence import pad_sequencesfrom tensorflow.python.keras.optimizers import RMSpropfrom tensorflow.python.keras.optimizers import Adamfrom tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, ReduceLROnPlateau
分词和tokenize
首先我们去掉每个样本的标点符号,然后用jieba分词,jieba分词返回一个生成器,没法直接进行tokenize,所以我们将分词结果转换成一个list,并将它索引化,这样每一例评价的文本变成一段索引数字,对应着预训练词向量模型中的词。
# 进行分词和tokenize# train_tokens是一个长长的list,其中含有4000个小list,对应每一条评价train_tokens = []for text in train_texts_orig:# 去掉标点text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",text)# 结巴分词cut = jieba.cut(text)# 结巴分词的输出结果为一个生成器# 把生成器转换为listcut_list = [ i for i in cut ]for i, word in enumerate(cut_list):try:# 将词转换为索引indexcut_list[i] = cn_model.vocab[word].indexexcept KeyError:# 如果词不在字典中,则输出0cut_list[i] = 0train_tokens.append(cut_list)Building prefix dict from the default dictionary ... Loading model from cache C:\Users\jinan\AppData\Local\Temp\jieba.cache Loading model cost 0.672 seconds. Prefix dict has been built succesfully.
索引长度标准化
因为每段评语的长度是不一样的,我们如果单纯取最长的一个评语,并把其他评填充成同样的长度,这样十分浪费计算资源,所以我们取一个折衷的长度。
# 获得所有tokens的长度num_tokens = [ len(tokens) for tokens in train_tokens ]num_tokens = np.array(num_tokens)
# 平均tokens的长度np.mean(num_tokens)
71.4495
# 最长的评价tokens的长度np.max(num_tokens)
1540
plt.hist(np.log(num_tokens), bins = 100)plt.xlim((0,10))plt.ylabel('number of tokens')plt.xlabel('length of tokens')plt.title('Distribution of tokens length')plt.show()# 取tokens平均值并加上两个tokens的标准差,# 假设tokens长度的分布为正态分布,则max_tokens这个值可以涵盖95%左右的样本max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)max_tokens = int(max_tokens)max_tokens
236
# 取tokens的长度为236时,大约95%的样本被涵盖# 我们对长度不足的进行padding,超长的进行修剪np.sum( num_tokens < max_tokens ) / len(num_tokens)
0.9565
反向tokenize
我们定义一个function,用来把索引转换成可阅读的文本,这对于debug很重要。
# 用来将tokens转换为文本def reverse_tokens(tokens):text = ''for i in tokens:if i != 0:text = text + cn_model.index2word[i]else:text = text + ' 'return text
reverse = reverse_tokens(train_tokens[0])
以下可见,训练样本的极性并不是那么精准,比如说下面的样本,对早餐并不满意,但被定义为正面评价,这会迷惑我们的模型,不过我们暂时不对训练样本进行任何修改。
# 经过tokenize再恢复成文本# 可见标点符号都没有了reverse
'早餐太差无论去多少人那边也不加食品的酒店应该重视一下这个问题了房间本身很好'
# 原始文本train_texts_orig[0]
'早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。\n\n房间本身很好。'
准备Embedding Matrix
现在我们来为模型准备embedding matrix(词向量矩阵),根据keras的要求,我们需要准备一个维度为$(numwords, embeddingdim)$的矩阵,num words代表我们使用的词汇的数量,emdedding dimension在我们现在使用的预训练词向量模型中是300,每一个词汇都用一个长度为300的向量表示。
注意我们只选择使用前50k个使用频率最高的词,在这个预训练词向量模型中,一共有260万词汇量,如果全部使用在分类问题上会很浪费计算资源,因为我们的训练样本很小,一共只有4k,如果我们有100k,200k甚至更多的训练样本时,在分类问题上可以考虑减少使用的词汇量。
embedding_dim
300
# 只使用前20000个词num_words = 50000# 初始化embedding_matrix,之后在keras上进行应用embedding_matrix = np.zeros((num_words, embedding_dim))# embedding_matrix为一个 [num_words,embedding_dim] 的矩阵# 维度为 50000 * 300for i in range(num_words):embedding_matrix[i,:] = cn_model[cn_model.index2word[i]]embedding_matrix = embedding_matrix.astype('float32')# 检查index是否对应,# 输出300意义为长度为300的embedding向量一一对应np.sum( cn_model[cn_model.index2word[333]] == embedding_matrix[333] )
300
# embedding_matrix的维度,# 这个维度为keras的要求,后续会在模型中用到embedding_matrix.shape
(50000, 300)
padding(填充)和truncating(修剪)
我们把文本转换为tokens(索引)之后,每一串索引的长度并不相等,所以为了方便模型的训练我们需要把索引的长度标准化,上面我们选择了236这个可以涵盖95%训练样本的长度,接下来我们进行padding和truncating,我们一般采用'pre'的方法,这会在文本索引的前面填充0,因为根据一些研究资料中的实践,如果在文本索引后面填充0的话,会对模型造成一些不良影响。
# 进行padding和truncating, 输入的train_tokens是一个list# 返回的train_pad是一个numpy arraytrain_pad = pad_sequences(train_tokens, maxlen=max_tokens,padding='pre', truncating='pre')
# 超出五万个词向量的词用0代替train_pad[ train_pad>=num_words ] = 0
# 可见padding之后前面的tokens全变成0,文本在最后面train_pad[0]
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 290, 3053, 57, 169, 73, 1, 25, 11216, 49, 163, 15985, 0, 0, 30, 8, 0, 1, 228, 223, 40, 35, 653, 0, 5, 1642, 29, 11216, 2751, 500, 98, 30, 3159, 2225, 2146, 371, 6285, 169, 27396, 1, 1191, 5432, 1080, 20055, 57, 562, 1, 22671, 40, 35, 169, 2567, 0, 42665, 7761, 110, 0, 0, 41281, 0, 110, 0, 35891, 110, 0, 28781, 57, 169, 1419, 1, 11670, 0, 19470, 1, 0, 0, 169, 35071, 40, 562, 35, 12398, 657, 4857])
# 准备target向量,前2000样本为1,后2000为0train_target = np.concatenate( (np.ones(2000),np.zeros(2000)) )
# 进行训练和测试样本的分割from sklearn.model_selection import train_test_split
# 90%的样本用来训练,剩余10%用来测试X_train, X_test, y_train, y_test = train_test_split(train_pad,train_target,test_size=0.1,random_state=12)
# 查看训练样本,确认无误print(reverse_tokens(X_train[35]))print('class: ',y_train[35])房间很大还有海景阳台走出酒店就是沙滩非常不错唯一遗憾的就是不能刷 不方便 class: 1.0
现在我们用keras搭建LSTM模型,模型的第一层是Embedding层,只有当我们把tokens索引转换为词向量矩阵之后,才可以用神经网络对文本进行处理。
keras提供了Embedding接口,避免了繁琐的稀疏矩阵操作。
在Embedding层我们输入的矩阵为:$$(batchsize, maxtokens)$$
输出矩阵为: $$(batchsize, maxtokens, embeddingdim)$$
# 用LSTM对样本进行分类model = Sequential()
# 模型第一层为embeddingmodel.add(Embedding(num_words,embedding_dim,weights=[embedding_matrix],input_length=max_tokens,trainable=False))
model.add(Bidirectional(LSTM(units=32, return_sequences=True)))model.add(LSTM(units=16, return_sequences=False))
构建模型
我在这个教程中尝试了几种神经网络结构,因为训练样本比较少,所以我们可以尽情尝试,训练过程等待时间并不长:
GRU:如果使用GRU的话,测试样本可以达到87%的准确率,但我测试自己的文本内容时发现,GRU最后一层激活函数的输出都在0.5左右,说明模型的判断不是很明确,信心比较低,而且经过测试发现模型对于否定句的判断有时会失误,我们期望对于负面样本输出接近0,正面样本接近1而不是都徘徊于0.5之间。
BiLSTM:测试了LSTM和BiLSTM,发现BiLSTM的表现最好,LSTM的表现略好于GRU,这可能是因为BiLSTM对于比较长的句子结构有更好的记忆,有兴趣的朋友可以深入研究一下。
Embedding之后第,一层我们用BiLSTM返回sequences,然后第二层16个单元的LSTM不返回sequences,只返回最终结果,最后是一个全链接层,用sigmoid激活函数输出结果。
# GRU的代码# model.add(GRU(units=32, return_sequences=True))# model.add(GRU(units=16, return_sequences=True))# model.add(GRU(units=4, return_sequences=False))
model.add(Dense(1, activation='sigmoid'))# 我们使用adam以0.001的learning rate进行优化optimizer = Adam(lr=1e-3)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# 我们来看一下模型的结构,一共90k左右可训练的变量model.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 236, 300) 15000000 _________________________________________________________________ bidirectional_1 (Bidirection (None, 236, 64) 85248 _________________________________________________________________ lstm_2 (LSTM) (None, 16) 5184 _________________________________________________________________ dense_1 (Dense) (None, 1) 17 ================================================================= Total params: 15,090,449 Trainable params: 90,449 Non-trainable params: 15,000,000 _________________________________________________________________
# 建立一个权重的存储点path_checkpoint = 'sentiment_checkpoint.keras'checkpoint = ModelCheckpoint(filepath=path_checkpoint, monitor='val_loss', verbose=1, s*e_weights_only=True, s*e_best_only=True)
# 尝试加载已训练模型try:model.load_weights(path_checkpoint)except Exception as e:print(e)
# 定义early stoping如果3个epoch内validation loss没有改善则停止训练earlystopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
# 自动降低learning ratelr_reduction = ReduceLROnPlateau(monitor='val_loss', factor=0.1, min_lr=1e-5, patience=0, verbose=1)
# 定义callback函数callbacks = [earlystopping, checkpoint,lr_reduction]
# 开始训练model.fit(X_train, y_train, validation_split=0.1, epochs=20, batch_size=128, callbacks=callbacks)
结论
我们首先对测试样本进行预测,得到了还算满意的准确度。
之后我们定义一个预测函数,来预测输入的文本的极性,可见模型对于否定句和一些简单的逻辑结构都可以进行准确的判断。
result = model.evaluate(X_test, y_test)print('Accuracy:{0:.2%}'.format(result[1]))400/400 [==============================] - 5s 12ms/step Accuracy:87.50%
def predict_sentiment(text):print(text)# 去标点text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",text)# 分词cut = jieba.cut(text)cut_list = [ i for i in cut ]# tokenizefor i, word in enumerate(cut_list):try:cut_list[i] = cn_model.vocab[word].indexexcept KeyError:cut_list[i] = 0# paddingtokens_pad = pad_sequences([cut_list], maxlen=max_tokens, padding='pre', truncating='pre')# 预测result = model.predict(x=tokens_pad)coef = result[0][0]if coef >= 0.5:print('是一例正面评价','output=%.2f'%coef)else:print('是一例负面评价','output=%.2f'%coef)test_list = ['酒店设施不是新的,服务态度很不好','酒店卫生条件非常不好','床铺非常舒适','房间很凉,不给开暖气','房间很凉爽,空调冷气很足','酒店环境不好,住宿体验很不好','房间隔音不到位' ,'晚上回来发现没有打扫卫生','因为过节所以要我临时加钱,比团购的价格贵']for text in test_list:predict_sentiment(text)
酒店设施不是新的,服务态度很不好 是一例负面评价 output=0.14 酒店卫生条件非常不好 是一例负面评价 output=0.09 床铺非常舒适 是一例正面评价 output=0.76 房间很凉,不给开暖气 是一例负面评价 output=0.17 房间很凉爽,空调冷气很足 是一例正面评价 output=0.66 酒店环境不好,住宿体验很不好 是一例负面评价 output=0.06 房间隔音不到位 是一例负面评价 output=0.17 晚上回来发现没有打扫卫生 是一例负面评价 output=0.25 因为过节所以要我临时加钱,比团购的价格贵 是一例负面评价 output=0.06
错误分类的文本经过查看,发现错误分类的文本的含义大多比较含糊,就算人类也不容易判断极性,如index为101的这个句子,好像没有一点满意的成分,但这例子评价在训练样本中被标记成为了正面评价,而我们的模型做出的负面评价的预测似乎是合理的。
y_pred = model.predict(X_test)y_pred = y_pred.T[0]y_pred = [1 if p>= 0.5 else 0 for p in y_pred]y_pred = np.array(y_pred)
y_actual = np.array(y_test)
# 找出错误分类的索引misclassified = np.where( y_pred != y_actual )[0]
# 输出所有错误分类的索引len(misclassified)print(len(X_test))
400
# 我们来找出错误分类的样本看看idx=101print(reverse_tokens(X_test[idx]))print('预测的分类', y_pred[idx])print('实际的分类', y_actual[idx])由于2007年 有一些新问题可能还没来得及解决我因为工作需要经常要住那里所以慎重的提出以下 :1 后 的 淋浴喷头的位置都太高我换了房间还是一样很不好用2 后的一些管理和服务还很不到位尤其是前台入住和 时代效率太低每次 都超过10分钟好像不符合 宾馆的要求 预测的分类 0 实际的分类 1.0
idx=1print(reverse_tokens(X_test[idx]))print('预测的分类', y_pred[idx])print('实际的分类', y_actual[idx])还是很 设施也不错但是 和以前 比急剧下滑了 和客房 的服务极差幸好我不是很在乎 预测的分类 0 实际的分类 1.0

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程