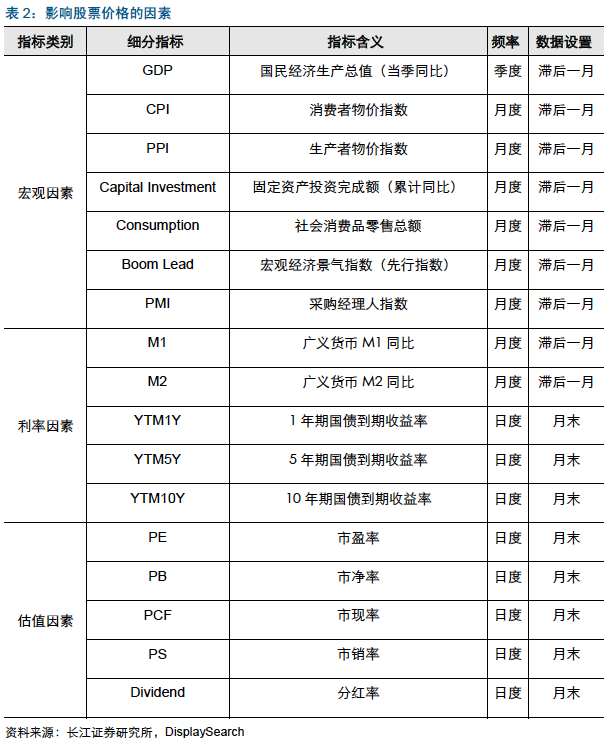
初学机器学习算法,研究长江证券< 大类资产配置之机器学习应用于股票资产的趋势预测》(2017-04-19)研报,并尝试复现。该报表综合考量影响股票收益率的因素,大致归类成宏观经济因素、利率因素及估值因素三大类,共计17个细分指标。本文据此收集相关数据,构建Logistic、DecisionTree及SVM模型预测沪深300行情趋势,并编写对应交易策略进行回测检验。
输入的指标:估值指标(月末值\变化值\均值)、利率指标、宏观经济指标、
所有指标;
训练集选择:18 个月、24 个月、30 个月、36 个月;
预测规则:采取训练集滚动的方式进行预测,例如第1~18 个月数据训练后
用于预测第19 个月的大盘走势;
数据来源包括:JQData、Tushare、Investing.com
因分红率数据获取问题,暂未纳入研究中
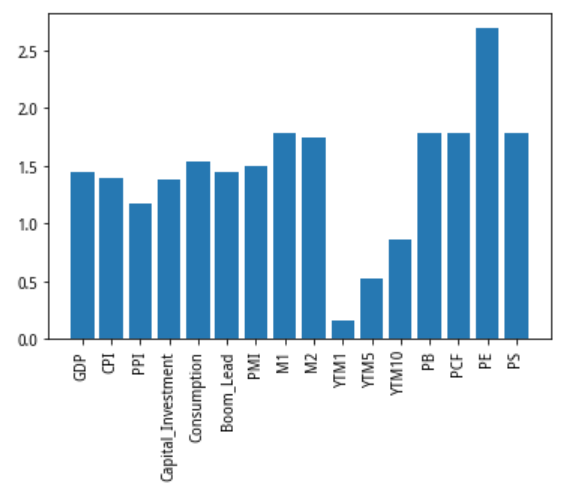
利用 SelectKBest 筛选特征值,结果如下图所示:
PE的贡献率最高,而1、5、10年期国债到期收益率的贡献率偏低。
通过多次回测,保留目前较好结果
标的及基准:沪深300指数(000300.XSHG)
模型:DecisionTree模型,以30个月为周期预测
回测时间:2007-11至2017-12
其余细节在研究中展示,模型还有很多地方需要改进,欢迎大神前来指教!
import numpy as np
import pandas as pd
from jqdata import *
import datetime
import warnings
warnings.filterwarnings("ignore")
start_date = '2005-05'
end_date = '2017-12'
q1 = query(macro.MAC_AREA_GDP_QUARTER.stat_quarter,
macro.MAC_AREA_GDP_QUARTER.gdp_yoy_sin,
).filter(macro.MAC_AREA_GDP_QUARTER.stat_quarter >= start_date,
macro.MAC_AREA_GDP_QUARTER.stat_quarter <= end_date,
macro.MAC_AREA_GDP_QUARTER.area_name == '中国'
).order_by(macro.MAC_AREA_GDP_QUARTER.stat_quarter.asc()
)
q2 = query(macro.MAC_AREA_CPI_MONTH.stat_month,
macro.MAC_AREA_CPI_MONTH.item_value
).filter(macro.MAC_AREA_CPI_MONTH.stat_month >= start_date,
macro.MAC_AREA_CPI_MONTH.stat_month <= end_date,
macro.MAC_AREA_CPI_MONTH.area_name == '中国',
macro.MAC_AREA_CPI_MONTH.item_name == '居民消费价格指数(上月=100)'
).order_by(macro.MAC_AREA_CPI_MONTH.stat_month.asc()
)
q3 = query(macro.MAC_FIXED_INVESTMENT.stat_month,
macro.MAC_FIXED_INVESTMENT.fixed_assets_investment_yoy
).filter(macro.MAC_FIXED_INVESTMENT.stat_month >= start_date,
macro.MAC_FIXED_INVESTMENT.stat_month <= end_date,
).order_by(macro.MAC_FIXED_INVESTMENT.stat_month.asc()
)
q4 = query(macro.MAC_SALE_RETAIL_MONTH.stat_month,
macro.MAC_SALE_RETAIL_MONTH.retail_sin
).filter(macro.MAC_SALE_RETAIL_MONTH.stat_month >= start_date,
macro.MAC_SALE_RETAIL_MONTH.stat_month <= end_date,
).order_by(macro.MAC_SALE_RETAIL_MONTH.stat_month.asc()
)
q5 = query(macro.MAC_ECONOMIC_BOOM_IDX.stat_month,
macro.MAC_ECONOMIC_BOOM_IDX.leading_idx
).filter(macro.MAC_ECONOMIC_BOOM_IDX.stat_month >= start_date,
macro.MAC_ECONOMIC_BOOM_IDX.stat_month <= end_date
).order_by(macro.MAC_ECONOMIC_BOOM_IDX.stat_month.asc()
)
q6 = query(macro.MAC_MANUFACTURING_PMI.stat_month,
macro.MAC_MANUFACTURING_PMI.pmi
).filter(macro.MAC_MANUFACTURING_PMI.stat_month >= start_date,
macro.MAC_MANUFACTURING_PMI.stat_month <= end_date
).order_by(macro.MAC_MANUFACTURING_PMI.stat_month.asc()
)
df_gdp = macro.run_query(q1)
df_cpi = macro.run_query(q2)
df_CI = macro.run_query(q3)
df_Consumption = macro.run_query(q4)
df_BL = macro.run_query(q5)
df_pmi = macro.run_query(q6)
df_gdp.rename(columns=({'stat_quarter': 'stat_month','gdp_yoy_sin':'GDP'}), inplace=True)
df_cpi.rename(columns=({'item_value': 'CPI'}), inplace=True)
df_CI.rename(columns=({'fixed_assets_investment_yoy': 'Capital_Investment'}), inplace=True)
df_Consumption.rename(columns=({'retail_sin': 'Consumption'}), inplace=True)
df_BL.rename(columns=({'leading_idx':'Boom_Lead'}), inplace=True)
df_pmi.rename(columns={'pmi':'PMI'},inplace=True)
利用Tushare获取ppi数据
import tushare as ts
ts.set_token('3fd8b7ae1b055ce47295b9fe352db0f1f172117f6af30ffec9c4f680')
df_ppi = ts.get_ppi()[['month','ppi']]
date = pd.to_datetime(df_ppi.month,format='%Y.%m')
df_ppi['month'] = date.apply(lambda x: x.strftime('%Y-%m'))
df_ppi.rename(columns={'month':'stat_month','ppi':'PPI'},inplace=True)
df_ppi = df_ppi.sort_values(by=['stat_month'])
df_ppi = df_ppi[(df_ppi.stat_month > '2005-04') & (df_ppi.stat_month < '2018-01')].reset_index(drop=True)
整理Macro数据
df_macro = pd.DataFrame(df_cpi.stat_month)
for factor in [df_gdp,df_cpi,df_ppi,df_CI,df_Consumption,df_BL,df_pmi]:
df_macro = pd.merge(df_macro,factor,how = 'outer', on='stat_month')
df_macro = df_macro.sort_values(by="stat_month")
df_macro = df_macro.fillna(method='backfill')
df_macro.head().append(df_macro.tail())
| stat_month | GDP | CPI | PPI | Capital_Investment | Consumption | Boom_Lead | PMI | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2005-05 | 111.1 | 99.8000 | 108.2 | 26.4000 | 4899.2000 | 102.58 | 52.9 |
| 1 | 2005-06 | 111.1 | 99.1800 | 107.2 | 27.1000 | 4935.0000 | 102.59 | 51.7 |
| 2 | 2005-07 | 110.8 | 100.0000 | 107.1 | 27.2000 | 4934.9000 | 102.47 | 51.1 |
| 3 | 2005-08 | 110.8 | 100.2000 | 107.3 | 27.4000 | 5040.7875 | 102.41 | 52.6 |
| 4 | 2005-09 | 110.8 | 100.7300 | 106.2 | 27.7205 | 5495.2000 | 102.30 | 55.1 |
| 146 | 2017-08 | 106.7 | 100.4157 | 108.3 | 7.8000 | 30329.7000 | 100.21 | 51.7 |
| 147 | 2017-09 | 106.7 | 100.5389 | 109.1 | 7.5000 | 30870.3000 | 100.37 | 52.4 |
| 148 | 2017-10 | 106.7 | 100.1122 | 109.0 | 7.3000 | 34240.9000 | 100.59 | 51.6 |
| 149 | 2017-11 | 106.7 | 100.0128 | 107.5 | 7.2000 | 34108.2000 | 100.88 | 51.8 |
| 150 | 2017-12 | 106.7 | 100.3360 | 106.4 | 7.2000 | 34734.1000 | 100.53 | 51.6 |
q = query(macro.MAC_MONEY_SUPPLY_MONTH.stat_month,
macro.MAC_MONEY_SUPPLY_MONTH.m1_yoy,
macro.MAC_MONEY_SUPPLY_MONTH.m2_yoy
).filter(macro.MAC_MONEY_SUPPLY_MONTH.stat_month >= start_date,
macro.MAC_MONEY_SUPPLY_MONTH.stat_month <= end_date
).order_by(macro.MAC_MONEY_SUPPLY_MONTH.stat_month.asc()
)
df_M = macro.run_query(q)
df_M.rename(columns={'m1_yoy':'M1','m2_yoy':'M2'},inplace=True)
df_M.head()
| stat_month | M1 | M2 | |
|---|---|---|---|
| 0 | 2005-05 | 10.4 | 14.7 |
| 1 | 2005-06 | 11.3 | 15.7 |
| 2 | 2005-07 | 11.0 | 16.3 |
| 3 | 2005-08 | 11.5 | 17.3 |
| 4 | 2005-09 | 11.6 | 17.9 |
平台暂无国债收益率数据,导入预先下载好的数据
def ytm(name):
temp = pd.read_csv('./data/'+str(name) +'.csv')[['日期','收盘']]
date = pd.to_datetime(temp.日期,format='%Y年%m月')
temp['日期'] = date.apply(lambda x: x.strftime('%Y-%m'))
temp.rename(columns={'日期':'stat_month','收盘':name},inplace=True)
return temp
ytm1 = ytm('YTM1')
ytm5 = ytm('YTM5')
ytm10 = ytm('YTM10')
df_interest = pd.DataFrame(df_M.stat_month)
for factor in [df_M,ytm1,ytm5,ytm10]:
df_interest = pd.merge(df_interest,factor,how = 'outer', on='stat_month')
df_interest = df_interest.sort_values(by="stat_month")
def get_index_pricing(code,date):
'''指定日期的指数PE_PB(等权重)'''
stocks = get_index_stocks(code, date)
q = query(valuation).filter(valuation.code.in_(stocks))
df = get_fundamentals(q, date)
if len(df)>0:
pe = len(df)/sum([1/p if p>0 else 0 for p in df.pe_ratio])
pb = len(df)/sum([1/p if p>0 else 0 for p in df.pb_ratio])
ps = len(df)/sum([1/p if p>0 else 0 for p in df.ps_ratio])
pcf = len(df)/sum([1/p if p>0 else 0 for p in df.pcf_ratio])
return (round(pe,2), round(pb,2),round(ps,2),round(pcf,2))
else:
return float('NaN')
def get_index_his_pricing(code, start_date=None, end_date=None):
'''指数历史Pricing'''
if start_date is None:
start_date = get_security_info(code).start_date
if end_date is None:
end_date = pd.datetime.today() - timedelta(1)
x = get_price(code, start_date=start_date, end_date=end_date, frequency='daily', fields='close')
date_list = x.index.tolist()
pe_list = []
pb_list = []
ps_list = []
pcf_list = []
for d in date_list: #交易日
pricing = get_index_pricing(code,d)
pe_list.append(pricing[0])
pb_list.append(pricing[1])
ps_list.append(pricing[2])
pcf_list.append(pricing[3])
df = pd.DataFrame({'PE': pd.Series(pe_list, index=date_list),
'PB': pd.Series(pb_list, index=date_list),
'PS':pd.Series(pb_list, index=date_list),
'PCF':pd.Series(pb_list, index=date_list)})
return df
index = '000300.XSHG'
df_pricing = get_index_his_pricing(index, '2005-05-09','2017-12-31')
df_pricing_M = df_pricing.groupby(pd.TimeGrouper('M')).apply(lambda i:i.iloc[-1])
说明:股指数据中分红率因数据获取原因暂未纳入
df = get_price('000300.XSHG',start_date = '2005-04-09',end_date='2017-12-31',
frequency='daily',fields=['close'])
df = df.groupby(pd.TimeGrouper('M')).apply(lambda i:(i.iloc[-1]-i.iloc[1])/i.iloc[1])
df[df.close > 0.0] = 1
df[df.close <= 0.0] = 0
df_stock = df_stock.dropna().reset_index(drop = True)
将所有数据获取、处理完成,以csv文件写入研究中存储,方便下次调用
factor = pd.read_csv('./Data/Factor1.csv')
hs = pd.read_csv('./Data/HS300.csv')
factor.head().append(factor.tail())
| GDP | CPI | PPI | Capital_Investment | Consumption | Boom_Lead | PMI | M1 | M2 | YTM1 | YTM5 | YTM10 | PB | PCF | PE | PS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 111.1 | 99.8000 | 108.2 | 26.4000 | 4899.2000 | 102.58 | 52.9 | 10.4 | 14.70 | 1.702 | 3.435 | 4.133 | 1.44 | 1.44 | 16.90 | 1.44 |
| 1 | 111.1 | 99.1800 | 107.2 | 27.1000 | 4935.0000 | 102.59 | 51.7 | 11.3 | 15.70 | 1.575 | 3.061 | 3.874 | 1.43 | 1.43 | 16.88 | 1.43 |
| 2 | 110.8 | 100.0000 | 107.1 | 27.2000 | 4934.9000 | 102.47 | 51.1 | 11.0 | 16.30 | 1.503 | 2.647 | 3.548 | 1.37 | 1.37 | 15.77 | 1.37 |
| 3 | 110.8 | 100.2000 | 107.3 | 27.4000 | 5040.7875 | 102.41 | 52.6 | 11.5 | 17.30 | 1.402 | 2.606 | 3.518 | 1.50 | 1.50 | 16.90 | 1.50 |
| 4 | 110.8 | 100.7300 | 106.2 | 27.7205 | 5495.2000 | 102.30 | 55.1 | 11.6 | 17.90 | 1.248 | 2.587 | 3.325 | 1.47 | 1.47 | 16.89 | 1.47 |
| 147 | 106.7 | 100.4157 | 108.3 | 7.8000 | 30329.7000 | 100.21 | 51.7 | 14.0 | 8.56 | 3.428 | 3.635 | 3.675 | 2.39 | 2.39 | 22.46 | 2.39 |
| 148 | 106.7 | 100.5389 | 109.1 | 7.5000 | 30870.3000 | 100.37 | 52.4 | 14.0 | 8.98 | 3.460 | 3.630 | 3.638 | 2.37 | 2.37 | 22.38 | 2.37 |
| 149 | 106.7 | 100.1122 | 109.0 | 7.3000 | 34240.9000 | 100.59 | 51.6 | 13.0 | 8.88 | 3.583 | 3.963 | 3.916 | 2.27 | 2.27 | 22.13 | 2.27 |
| 150 | 106.7 | 100.0128 | 107.5 | 7.2000 | 34108.2000 | 100.88 | 51.8 | 12.7 | 9.11 | 3.700 | 3.876 | 3.917 | 2.22 | 2.22 | 21.91 | 2.22 |
| 151 | 106.7 | 100.3360 | 106.4 | 7.2000 | 34734.1000 | 100.53 | 51.6 | 11.8 | 8.20 | 3.803 | 3.860 | 3.915 | 2.19 | 2.19 | 21.59 | 2.19 |
hs.head().append(hs.tail())
| close | |
|---|---|
| 0 | 0.0 |
| 1 | 0.0 |
| 2 | 1.0 |
| 3 | 1.0 |
| 4 | 1.0 |
| 148 | 1.0 |
| 149 | 0.0 |
| 150 | 1.0 |
| 151 | 1.0 |
| 152 | 1.0 |
参考:一键即得标准化、规范化、二值化等多种机器学习数据预处理方式 https://www.joinquant.com/post/1fdd694e5faa64bf0dfc20d6241b41b1?f=stydy&m=python
from sklearn import preprocessing
factor_nor = preprocessing.normalize(factor, norm='l1')
features = factor_nor
target = hs
def roc(test,predictions):
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
fpr, tpr, th = metrics.roc_curve(test, predictions)
print('-'*50)
print('FPR = ',fpr)
print('-'*50)
print('TPR = ',tpr)
print('-'*50)
print('AUC = %.4f' %metrics.auc(fpr, tpr))
print('-'*50)
plt.figure(figsize=[6, 6])
plt.plot(fpr, tpr, 'b--')
plt.title('ROC curve')
plt.show()
def accuracy(pred1,stest):
from sklearn.metrics import accuracy_score
print(accuracy_score(stest, pred1))
def train_pred(factor,hs,period,alg):
pred = []
ytest = []
alg=alg
for i in np.arange(len(factor)-period):
x_train, y_train = factor[i:i+period], hs[i:i+period]
x_test, y_test = np.array(factor[i+period]), hs.close.iloc[i+period]
alg.fit(x_train,y_train)
temp = alg.predict(x_test.reshape(1,16))
pred.append(temp[0])
ytest.append(y_test)
return(pred,ytest)
from sklearn.linear_model import LogisticRegression
alg = LogisticRegression()
lr_pred, ytest = train_pred(features,target,18,alg)
accuracy(ytest,lr_pred)
0.55223880597
roc(ytest, lr_pred)
-------------------------------------------------- FPR = [ 0. 0.48387097 1. ] -------------------------------------------------- TPR = [ 0. 0.58333333 1. ] -------------------------------------------------- AUC = 0.5497 --------------------------------------------------

from sklearn import tree
alg = tree.DecisionTreeClassifier(criterion='gini')
dt_pred, ytest = train_pred(features,target,18,alg)
accuracy(ytest,dt_pred)
0.574626865672
roc(ytest, dt_pred)
-------------------------------------------------- FPR = [ 0. 0.48387097 1. ] -------------------------------------------------- TPR = [ 0. 0.625 1. ] -------------------------------------------------- AUC = 0.5706 --------------------------------------------------

from sklearn import svm
alg = svm.SVC()
svm_pred, ytest = train_pred(features,target,18,alg)
accuracy(ytest,svm_pred)
0.544776119403
roc(ytest, svm_pred)
-------------------------------------------------- FPR = [ 0. 0.48387097 1. ] -------------------------------------------------- TPR = [ 0. 0.56944444 1. ] -------------------------------------------------- AUC = 0.5428 --------------------------------------------------


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程