摩根士丹利对今年参加量化会议的与会者做了一项问卷调查。聚宽量化实验室最近发现这篇文章并翻译过来,虽然调查结果是美国市场的情况,但是非常值得我们在中国市场进行预先布局和思考。
统计结果显示,与2017年相比,运用机器学习进行量化研究的人数有所上升,同时越来越多的人更看好被动投资,但总体上讲,参与量化研究的人数增长率有所放缓。
我们对参加我们第六届摩根士丹利量化研究和投资大会的与会者做了一项问卷调查。其中一些问题在去年和前年也曾出现在问卷中,这让我们能看到近些年的一些变化。
一、重要结论:
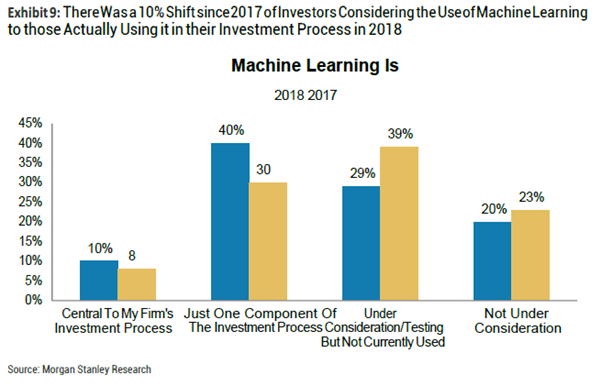
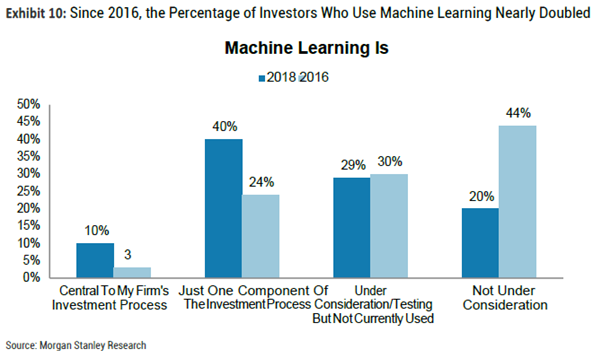
? 过去一年内采用机器学习方法做量化投资的人有显著增长。大约10%的被调查者从仅仅将机器学习用在回测和调试阶段,转为将机器学习实际应用在他们的交易策略中,这顺应了2016年以来的趋势。
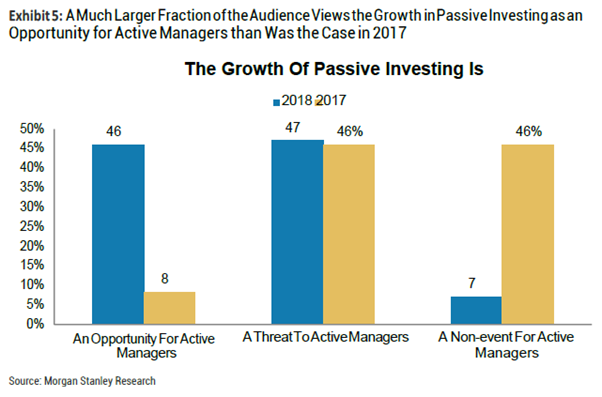
? 与去年相比,认为被动投资的方法使主动投资者有获利空间的人数大幅上升,从8%上升到了46%。但同时,接近半数的被调查者仍然认为被动投资对主动投资者有不利影响。今年几乎没有人认为被动投资对主动投资没有任何影响。
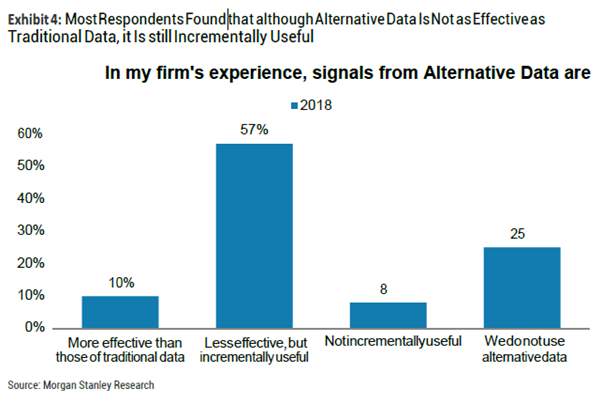
? 57%的被调查者表示,尽管另类数据作为辅助因素越来越有用,但是它们依然不如传统数据(即财务和价格数据)有效。利用另类数据依然是一个机会,但是也有25%的人表示他们并不使用另类数据。
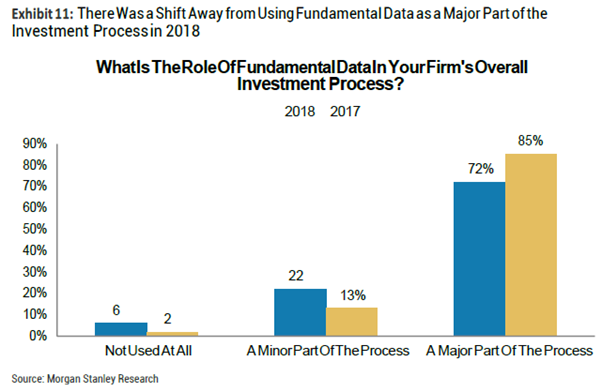
? 财务数据不再是投资策略的核心,很多公司开始淡化其在策略中的占比,甚至不再在策略中包含财务数据因子。
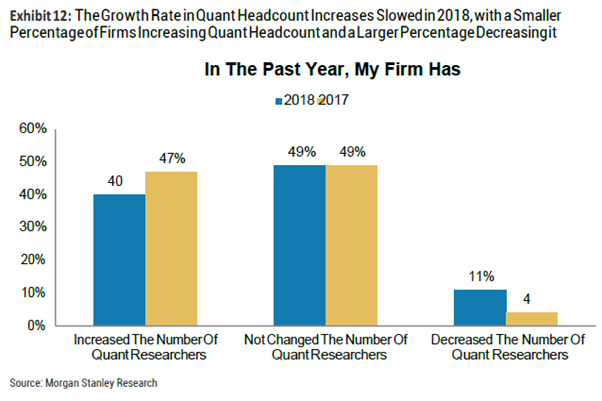
? 量化公司员工人数增速放缓,与去年47%的公司选择增员相比,今年只有40%的公司增加量化研究员人数。同时与去年4%的公司选择裁员相比,今年有11%的公司选择裁员。
二、问卷调查结果详述:
1.另类数据:57%的被调查者表示,尽管另类数据作为辅助因素越来越有用,但是它们依然不如传统数据(财务和价格数据)有效。利用另类数据依然是一个机会,但是也有25%的人表示他们并不使用另类数据。
2.机器学习:过去一年内采用机器学习方法做量化投资的人有显著增长。大约10%的被调查者从仅仅将机器学习用在回测和调试阶段,转为实际应用在他们的交易策略中,这顺应了2016年以来的趋势。
3.被动投资:与去年相比,认为被动投资有利于主动投资者的人数大幅上升,从8%上升到了46%。接近一半的人仍然认为被动投资对主动投资者不利。但是现在几乎没有人认为被动投资对主动投资没有影响。
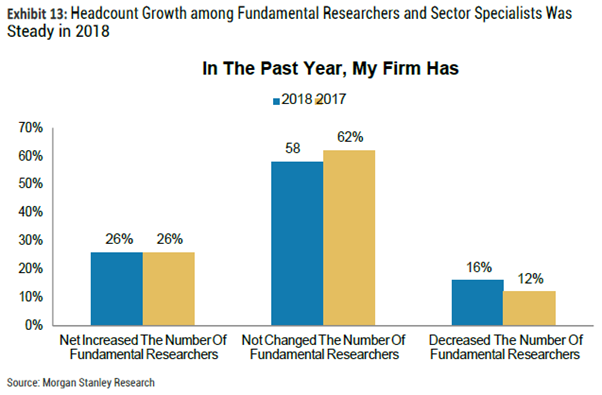
4.基本面量化投资方法的趋势:增加量化研究员的公司占比从47%下降到了40%,同时进行裁员的公司占比从4%上升到了11%。利用财务数据作为他们投资策略的核心的公司占比也有所下降,但财务数据研究员的数量几乎不变。
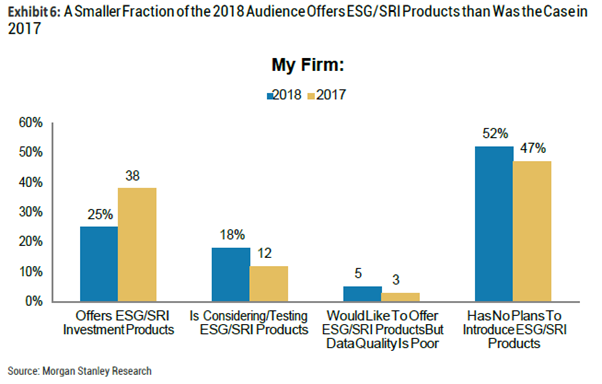
5.ESG/SRI:与去年相比,越来越少的公司提供ESG/SRI产品,但是越来越多的公司在考虑推出这类产品。被调查者对市场营销和ESG/SRI产品的表现,能给产品带来的相对效益大小的观点与去年保持一致。
注:ESG(Environmental, Social and Governance)通常代表环境、社会和公司治理三大因素,是社会责任投资SRI(Socially Responsible Investment)中投资决策的重要考量因子。
我们查阅资料显示:社会责任感薄弱,ESG表现并不好的企业,不管盈利能力和发展前景再怎么优秀,都会面临一些监管和指数收录问题。各大金融机构均在其投资决策和工作中纳入ESG因子和责任投资相关内容。
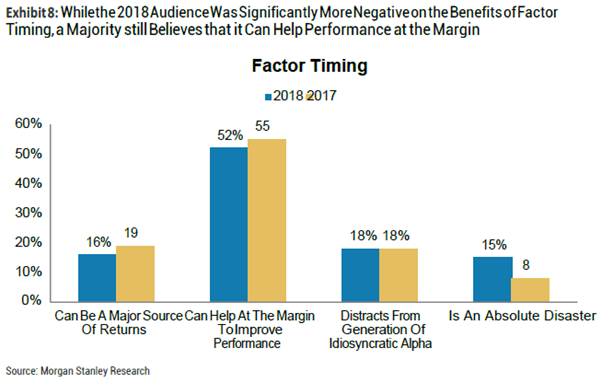
6.因子择时:更多的被调查者表示他们会酌情使用因子择时(动态调整因子权重),但是与2017年相比,对因子择时能带来效益的观点持否定态度的人有所增加,甚至有15%的人认为因子择时根本就是一个灾难。
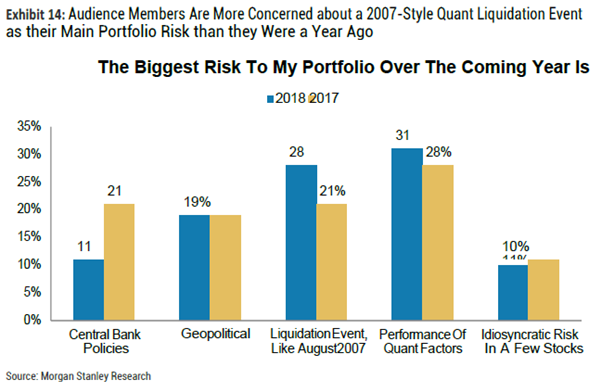
7.风险:量化因子的表现被视为影响策略表现的最大风险因素,但28%的被调查者认为像2017年8月的次贷危机事件才是最大的风险。相关反馈与去年相比并无显著变化。
三、与会发言人演讲重点:
? 来自加州大学伯克利分校的Martin Lettau教授展示了利用主成分分析(PCA)做扩展应用得到的结果。这种新方法不仅能解释何为风险,还能解释为何不同资产有不同的预期回报率。这个方法应用起来非常直接,并且与纯主成分分析(PCA)和标准因子模型相比,能从样本中找出具有更高夏普比率的因子。有趣的是,Lettau教授指出有五个因子能解释几乎所有风险和回报,而这正与摩根士丹利机器学习小组的发现不谋而合。
? 由来自摩根士丹利的Michael Kearns主导的机器学习小组澄清了关于机器学习的几个误解:
加大机器学习的研究会使得人力成本增加,而不是减少,因为必须有人去分析和解释数据。
另类数据并不一定需要机器学习。事实上,具有更多特征的更长历史的传统数据更适合使用机器学习作分析。小组成员认为,对于十分详细的数据,如何保护隐私和缓和可能的偏差是非常重要的考量,这点可以通过使用机器学习中的目标函数里的限制条件来达到。
? 来自摩根士丹利的Chiente Hsu指出另类数据尽管有一定潜力,但是搜集这类数据所花费的成本和如何存储并分析这些数据是更大的挑战。另一位同样来自摩根士丹利的Boris Lerner发现量化因子在不同地区效用不同,例如在日本,动量因子的效用就非常糟糕。






