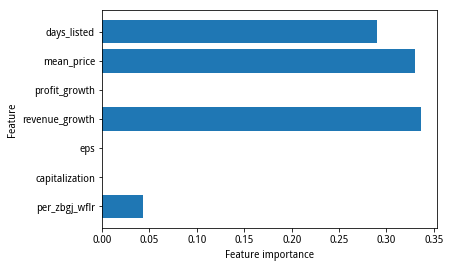从jqdata中获取分红数据,此处定义高送转数据:10送X 10转X大于等于10。
此处要注意from datetime import datetime使用问题。详细的可参考我个人博客:http://blog.sina.com.cn/s/blog_752fbc260102y01g.html
从jqdata中获取A股证券代码,和分红数据进行Join。由于分红数据不止A股,所以Join以后空白的行全部舍弃,剩余的即为A股的分红数据。
小琛先生在2017年预测时用了每股资本公积、每股未分配利润、总股本、净利润同比增长、前20个交易日平均价、上市天数这些因素。JoinQuant和果仁网基本上在此基础上有一些增加。JoinQuant的李伟豪先生额外地进行了有能力因子和有意愿因子的划分,个人觉得特别清晰。基于各位前辈研究的基础,本文初期用以下因子作为特征:1、每股资本公积 2、每股未分配利润 3、每股收益 4、总股本 5、营业收入同比增长 6、净利润同比增长 7、前20个交易日平均价 8、上市天数。样本区间则是选取了2011年-2017年作为训练集及验证集。
特征选取其实是降维的过程。降维的方法其实很多,常见的有PCA,递归,基于树的降维等。本文仍然沿用李伟豪先生的基于ExtraTrees的方法,将1.3所述的8个特征减为7个。
这里分享一篇博观厚积发的文章《机器学习中的特征选择及其Python举例》https://mp.weixin.qq.com/s/wPcMzYFfP3wEuF0nXUYndA,应该说写得非常详细清晰,可以加深对特征选取的理解。
初学的小伙伴可以跳过,只需要明白在做一件减少无关或重复特征的事情即可。
此处还是套用scikit-learn的train_test_split函数。该函数可以随机地将75%的行数据及对应标签作为训练集,剩下的25%的数据作为验证集。一般来说,使用25%的数据作为验证集是经验法则。
基本参考了李伟豪先生的《高送转预测 逻辑回归与支持向量机》思路。
基本参考了李伟豪先生的《高送转预测 逻辑回归与支持向量机》思路。其中涉及数据的缩放,这里要提醒一下对训练集和验证集要应用完全相同的变换。
决策树算法有一个优点,就是将树可视化,便于深入了解预测过程。本文用了export_graphviz函数来实现。另外,查看整个树可能稍微费劲,还可以用一些有用的属性来总结树的工作原理,比如特征重要性(feature importance),它为每个特征对树的决策的重要性进行排序,其值在0-1之间。
基于以上3种算法,可以发现:
逻辑回归的训练集打分为0.63,验证集打分为0.56
SVM的训练集打分为0.51,验证集打分为0.5
决策树的训练集打分为1,验证集打分为0.92
显然,基于决策树算法的score明显高于前2种算法。不过这只是简单的评价。我们接下来要做的才是真正的预测评价。
在引出混淆矩阵、准确率、召回率等概念之前,我们先要了解一下什么是不平衡数据。一个类别比另一个类别多很多的数据集,通常叫做不平衡数据集。在实际中,不平衡数据才是常态。本文要研究的高送转预测也是属于不平衡数据。所以上一节中的score不足以说明问题,评价模型。因为有时不用预测,就可以得到99%的精度。对于不平衡数据,精度并不是最合适的度量方法。
混淆矩阵的输出是一个2*2的数组,其中行对应于真实的类别,列对应于预测的类别。四个象限代表的意义可参考下图:

可能有小伙伴开始晕了,有没有更简单的方法!?有!
就看以下3个指标:
准确率:预测的正类中有多少真实的正类(真累?),即 TP/(TP FP)
召回率:真实的真类中有多少预测的正类,即 TP/(TP FN)
f1-score:准确率和召回率的调和平均。
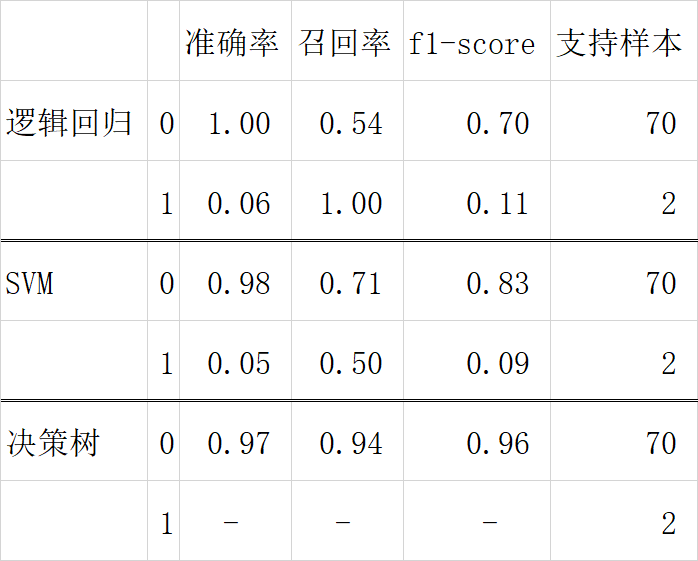
从分析的结果看,决策树算法虽然准确率较低,但召回率较高,也就说基本对反例不误判,但容易错失真正的高送转。
实现的方法也比较方便,调用classification_report函数即可实现。
在特殊的情况下,我们对准确率或召回率有偏好的需求,比如癌症筛查的时候,宁愿多误判,也不希望错过真实病情。
此时可以通过改变阀值来实现。大多数的分类器都提供了decision_function或者predict_proba方法来评估预测的不确定性。
本文中,SVM算法用改变decision_function,决策树算法用改变predict_proba的方法来改变阀值,读者可以参考。
其中decision_function的默认阀值是0,即大于0的被划为正类,如果需要更多的结果被划为1的话(更高的召回率),则需要降低阀值。predict_proba的默认阀值是0.5,即大于0.5的被划为正类,如果需要更少的结果被划为1的话(更高的准确率),则需要提高阀值。
如上所述,改变阀值,可以调节准确率和召回率。而准确率和召回率是由商业目标驱动的。如果有一条曲线可以查看所有准确率和召回率的组合,我们就可以寻找到最理想的折中点。这就是准确率-召回率曲线的由来。实现上调用precision_recall_curve函数可以快速得返回所有阀值对应的准确率和召回率列表,剩下的就是绘制一条曲线。
好吧~我承认这部分你们可以忽略了
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport datetimeimport matplotlib.pyplot as pltfrom sklearn.svm import SVCfrom sklearn.model_selection import StratifiedKFoldfrom sklearn.feature_selection import RFECVfrom sklearn import preprocessing
from jqdata import jyq = query(jy.LC_Dividend).filter()div_data = jy.run_query(q)
/opt/conda/lib/python3.5/site-packages/sqlalchemy/dialects/mysql/base.py:1936: SAWarning: MariaDB (10, 2, 6) before 10.2.9 has known issues regarding CHECK constraints, which impact handling of NULL values with SQLAlchemy's boolean datatype (MDEV-13596). An additional issue prevents proper migrations of columns with CHECK constraints (MDEV-11114). Please upgrade to MariaDB 10.2.9 or greater, or use the MariaDB 10.1 series, to *oid these issues. "series, to *oid these issues." % (mdb_version, ))
from datetime import datetimefrom datetime import timedeltaDATE_Y_FMT = '%Y'DATE_MD_FMT = '%m-%d'### 获取年末分红数据 ####获取年份div_data['year'] = div_data['EndDate'].map(lambda x:datetime.strftime(x, DATE_Y_FMT))#获取月日div_data['type'] = div_data['EndDate'].map(lambda x:datetime.strftime(x, DATE_MD_FMT))#抽取2011年以后(包括2011年)且年末(月日=12-31)的数据div_data = div_data[div_data['year'] >= '2011']div_data = div_data[div_data['type'] == '12-31']### 获取分红列 #####抽取所需列div_data_year = div_data[['InnerCode','year','BonusShareRatio','TranAddShareRaio']]#重新定义列名div_data_year.columns = ['InnerCode','year','sg_ratio','zg_ratio']div_data_year.fillna(0,inplace = True)### 获取高送转数据 ####定义送转列:10送X+10转X合计div_data_year['sz_ratio'] = div_data_year['sg_ratio']+div_data_year['zg_ratio']# 定义是否高送转列(初始值为0)div_data_year['gsz'] = 0#高送转定义:10送X+10转X大于等于10,即定义为高送转div_data_year.loc[div_data_year['sz_ratio'] >=10,'gsz'] = 1#删除不需要列del div_data_year['sz_ratio'] del div_data_year['sg_ratio'] del div_data_year['zg_ratio']
/opt/conda/lib/python3.5/site-packages/pandas/core/frame.py:2754: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the c*eats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy downcast=downcast, **kwargs) /opt/conda/lib/python3.5/site-packages/ipykernel_launcher.py:25: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the c*eats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy /opt/conda/lib/python3.5/site-packages/ipykernel_launcher.py:27: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the c*eats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy /opt/conda/lib/python3.5/site-packages/pandas/core/indexing.py:517: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the c*eats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy self.obj[item] = s
# 获取A股证券基本信息q2 = query(jy.SecuMain.InnerCode,jy.SecuMain.SecuCode,jy.SecuMain.ChiName).filter(jy.SecuMain.SecuCategory == 1 #A股 )df2 = jy.run_query(q2)
# 合并分红PD和证券基本信息PD(主PD为分红PD,采用LEFTJOIN方式,合并标准为InnerCode一致)df3 = div_data_year.merge(df2,how='left',on='InnerCode')
#去掉A股(NaN行)以外数据df3.dropna(inplace=True)
df3['stock'] = df3['SecuCode'].map(lambda x:normalize_code(x))
###将一些指标转变为每股数值def get_perstock_indicator(need_indicator,old_name,new_name,sdate):target = get_fundamentals(query(valuation.code, valuation.capitalization, need_indicator),statDate = sdate)target[new_name] = target[old_name]/target['capitalization']/10000return target[['code',new_name]]
###获取每股收益、股本数量、营业收入同比增长、净利润同比增长def get_other_indicator(sdate):target = get_fundamentals(query(valuation.code, valuation.capitalization, indicator.inc_revenue_year_on_year, indicator.inc_net_profit_year_on_year, indicator.eps),statDate = sdate)# 营业收入同比增长target.rename(columns={'inc_revenue_year_on_year':'revenue_growth'},inplace = True)# 净利润同比增长target.rename(columns={'inc_net_profit_year_on_year':'profit_growth'},inplace = True) # 股本数量target['capitalization'] = target['capitalization']*10000return target[['code','capitalization','eps','revenue_growth','profit_growth']]###获取一个月收盘价平均值def get_bmonth_aprice(code_list,startdate,enddate):mid_data = get_price(code_list, start_date=startdate, end_date=enddate,\ frequency='daily', fields='close', skip_paused=False, fq='pre')mean_price = pd.DataFrame(mid_data['close'].mean(axis = 0),columns=['mean_price'])mean_price['code'] =mean_price.indexmean_price.reset_index(drop = True,inplace =True)return mean_price[['code','mean_price']]
###判断是否为次新股(判断标准为位于上市一年之内) def judge_cxstock(date):mid_data = get_all_securities(types=['stock'])mid_data['start_date'] = mid_data['start_date'].map(lambda x:x.strftime("%Y-%m-%d"))shift_date = str(int(date[0:4])-1)+date[4:]mid_data['1year_shift_date'] = shift_datemid_data['cx_stock'] = 0mid_data.loc[mid_data['1year_shift_date']<=mid_data['start_date'],'cx_stock'] = 1mid_data['code'] = mid_data.indexmid_data.reset_index(drop = True,inplace=True)return mid_data[['code','cx_stock']]###判断上市了多少个自然日from datetime import datedef get_dayslisted(year,month,day):mid_data = get_all_securities(types=['stock'])sdate = date(year,month,day)#date = datetime(year,month,day).date() mid_data['days_listed'] = mid_data['start_date'].map(lambda x:(sdate -x).days)mid_data['code'] = mid_data.indexmid_data.reset_index(drop = True,inplace=True)return mid_data[['code','days_listed']]
"""输入:所需财务报表期、20日平均股价开始日期、20日平均股价结束日期输出:合并好的高送转数据 以及 财务指标数据"""def get_yearly_totaldata(statDate,statDate_before,mp_startdate,mp_enddate,year,month,day):##有能力高送转,基础指标包括:每股资本公积,每股留存收益##每股资本公积per_zbgj = get_perstock_indicator(balance.capital_reserve_fund,'capital_reserve_fund','per_CapitalReserveFund',statDate)#每股留存收益per_wflr = get_perstock_indicator(balance.retained_profit,'retained_profit','per_RetainProfit',statDate)##有能力高送转,其他指标包括:每股净资产、每股收益、营业收入同比增速、净利润同比增速##每股净资产per_jzc = get_perstock_indicator(balance.equities_parent_company_owners,'equities_parent_company_owners','per_TotalOwnerEquity',statDate) #每股收益、股本、营业收入同比增长、净利润同比增速other_indicator = get_other_indicator(statDate)code_list = other_indicator['code'].tolist()##有意愿高送转,指标包括均价、上市时间、股本增加#均价mean_price = get_bmonth_aprice(code_list,mp_startdate,mp_enddate)#是否为次新股cx_signal = judge_cxstock(mp_enddate)#股本增加#dz_signal = judge_dz(statDate,statDate_before)#上市时间days_listed = get_dayslisted(year,month,day)##因子列表:#每股资本公积#每股留存收益#每股净资产#每股收益、股本#均价#是否为次新股#上市时间#chart_list = [per_zbgj,per_wflr,per_jzc,other_indicator,mean_price,cx_signal,dz_signal,days_listed]chart_list = [per_zbgj,per_wflr,per_jzc,other_indicator,mean_price,cx_signal,days_listed]for chart in chart_list:chart.set_index('code',inplace = True)independ_vari = pd.concat([per_zbgj,per_wflr,per_jzc,other_indicator,mean_price,cx_signal,days_listed],axis = 1)independ_vari['year'] = str(int(statDate[0:4]))independ_vari['stock'] = independ_vari.indexindepend_vari.reset_index(drop=True,inplace =True)total_data = pd.merge(df3,independ_vari,on = ['stock','year'],how = 'inner')# 每股资本公积 + 每股留存收益total_data['per_zbgj_wflr'] = total_data['per_CapitalReserveFund']+total_data['per_RetainProfit']return total_data### 获取2011年-2017年的3季报数据gsz_2017 = get_yearly_totaldata('2017q3','2016q3','2017-10-01','2017-11-01',2017,11,1)gsz_2016 = get_yearly_totaldata('2016q3','2015q3','2016-10-01','2016-11-01',2016,11,1)gsz_2015 = get_yearly_totaldata('2015q3','2014q3','2015-10-01','2015-11-01',2015,11,1)gsz_2014 = get_yearly_totaldata('2014q3','2013q3','2014-10-01','2014-11-01',2014,11,1)gsz_2013 = get_yearly_totaldata('2013q3','2012q3','2013-10-01','2013-11-01',2013,11,1)gsz_2012 = get_yearly_totaldata('2012q3','2011q3','2012-10-01','2012-11-01',2012,11,1)gsz_2011 = get_yearly_totaldata('2011q3','2010q3','2011-10-01','2011-11-01',2011,11,1)在每股资本公积+留存收益,每股总资产,总股本,每股盈余,营业利润同比增速,净利润同比增速,前20个交易日平均价,上市天数 这些变量中进行选择
###基于树的判断traindata = pd.concat([gsz_2011,gsz_2012,gsz_2013,gsz_2014,gsz_2015,gsz_2016,gsz_2017],axis = 0)traindata.dropna(inplace = True)x_traindata = traindata[['per_zbgj_wflr',\ 'per_TotalOwnerEquity', 'capitalization', 'eps', 'revenue_growth','profit_growth',\ 'mean_price', 'days_listed']]y_traindata = traindata[['gsz']]X_trainScale = preprocessing.scale(x_traindata)from sklearn.ensemble import ExtraTreesClassifiermodel = ExtraTreesClassifier() model.fit(X_trainScale,y_traindata)print(pd.DataFrame(model.feature_importances_.tolist(),index =['per_zbgj_wflr',\ 'per_TotalOwnerEquity', 'capitalization', 'eps', 'revenue_growth','profit_growth',\ 'mean_price', 'days_listed'],columns = ['importance'] ))
importance per_zbgj_wflr 0.175108 per_TotalOwnerEquity 0.081068 capitalization 0.117600 eps 0.128933 revenue_growth 0.119780 profit_growth 0.132282 mean_price 0.103149 days_listed 0.142079
/opt/conda/lib/python3.5/site-packages/sklearn/preprocessing/data.py:160: UserWarning: Numerical issues were encountered when centering the data and might not be solved. Dataset may contain too large values. You may need to prescale your features.
warnings.warn("Numerical issues were encountered "
/opt/conda/lib/python3.5/site-packages/sklearn/ensemble/weight_boosting.py:29: DeprecationWarning: numpy.core.umath_tests is an internal NumPy module and should not be imported. It will be removed in a future NumPy release.
from numpy.core.umath_tests import inner1d
/opt/conda/lib/python3.5/site-packages/ipykernel_launcher.py:13: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using r*el().
del sys.path[0]各变量相关性
x_traindata.corr()
.dataframe thead tr:only-child th { text-align: right; } .dataframe thead th { text-align: left; } .dataframe tbody tr th { vertical-align: top; }
| per_zbgj_wflr | per_TotalOwnerEquity | capitalization | eps | revenue_growth | profit_growth | mean_price | days_listed | |
|---|---|---|---|---|---|---|---|---|
| per_zbgj_wflr | 1.000000 | 0.990338 | 0.305951 | 0.220499 | -0.029868 | 0.012947 | 0.426836 | 0.115803 |
| per_TotalOwnerEquity | 0.990338 | 1.000000 | 0.390298 | 0.223388 | -0.034992 | 0.006538 | 0.394747 | 0.134275 |
| capitalization | 0.305951 | 0.390298 | 1.000000 | 0.113356 | -0.023559 | -0.043569 | -0.077622 | 0.253917 |
| eps | 0.220499 | 0.223388 | 0.113356 | 1.000000 | -0.003538 | 0.379545 | 0.093393 | -0.009798 |
| revenue_growth | -0.029868 | -0.034992 | -0.023559 | -0.003538 | 1.000000 | 0.117426 | 0.107070 | 0.026184 |
| profit_growth | 0.012947 | 0.006538 | -0.043569 | 0.379545 | 0.117426 | 1.000000 | 0.039201 | 0.036399 |
| mean_price | 0.426836 | 0.394747 | -0.077622 | 0.093393 | 0.107070 | 0.039201 | 1.000000 | 0.329171 |
| days_listed | 0.115803 | 0.134275 | 0.253917 | -0.009798 | 0.026184 | 0.036399 | 0.329171 | 1.000000 |
可以看到每股净资产与每股资本公积+未分配利润 相关度非常高,因此舍去每股净资产
###基于RFE(递归特征消除) 判断traindata = pd.concat([gsz_2011,gsz_2012,gsz_2013,gsz_2014,gsz_2015,gsz_2016,gsz_2017],axis = 0)traindata.dropna(inplace = True)x_traindata = traindata[['per_zbgj_wflr',\'capitalization', 'eps', 'revenue_growth','profit_growth',\ 'mean_price', 'days_listed']]y_traindata = traindata[['gsz']]X_trainScale = preprocessing.scale(x_traindata)svc = SVC(C=1.0,class_weight='balanced',kernel='linear',probability=True)rfecv = RFECV(estimator=svc, step=1, cv=StratifiedKFold(2),scoring='accuracy')X_trainScale = preprocessing.scale(x_traindata)rfecv.fit(X_trainScale,y_traindata)plt.figure()plt.xlabel("Number of features selected")plt.ylabel("Cross validation score (nb of correct classifications)")plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)plt.show()/opt/conda/lib/python3.5/site-packages/sklearn/preprocessing/data.py:160: UserWarning: Numerical issues were encountered when centering the data and might not be solved. Dataset may contain too large values. You may need to prescale your features.
warnings.warn("Numerical issues were encountered "
/opt/conda/lib/python3.5/site-packages/sklearn/utils/validation.py:526: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using r*el().
y = column_or_1d(y, warn=True)
/opt/conda/lib/python3.5/site-packages/sklearn/utils/__init__.py:54: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int64 == np.dtype(int).type`.
if np.issubdtype(mask.dtype, np.int):from sklearn.model_selection import train_test_splitgszData = pd.concat([gsz_2011,gsz_2012,gsz_2013,gsz_2014,gsz_2015,gsz_2016,gsz_2017],axis = 0)gszData.dropna(inplace = True)variable_list = ['per_zbgj_wflr','capitalization', 'eps', 'revenue_growth','profit_growth',\ 'mean_price', 'days_listed']X = gszData.loc[:,variable_list]y = gszData.loc[:,'gsz']X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=19)
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression(class_weight='balanced',C=1e9)model.fit(X_train, y_train)print("Trainning set score:{:.3f}".format(model.score(X_train,y_train)))print(" Test set score:{:.3f}".format(model.score(X_test,y_test)))Trainning set score:0.633 Test set score:0.528
y_pred = model.predict(X_test)
#均值方差标准化standard_scaler = preprocessing.StandardScaler()X_trainScale = standard_scaler.fit_transform(X_train)clf = SVC(C=1.0,class_weight='balanced',gamma='auto',kernel='rbf',probability=True)clf.fit(X_trainScale, y_train) X_testScale = standard_scaler.transform(X_test) y_pred=clf.predict(X_testScale)
y_pred_threshold = clf.decision_function(X_testScale)
y_pred_changed_threshold = (y_pred_threshold > 0.3)
from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier(random_state=0)tree.fit(X_train,y_train)print("Trainning set score:{:.3f}".format(tree.score(X_train,y_train)))print(" Test set score:{:.3f}".format(tree.score(X_test,y_test)))Trainning set score:1.000 Test set score:0.917
y_pred = tree.predict(X_test)
y_pred_threshold = tree.predict_proba(X_test)[:,1]
y_pred_changed_threshold = (y_pred_threshold > 0.9)
from sklearn.tree import export_graphvizimport graphvizdot_data = export_graphviz(tree,out_file=None,class_names=["GSZ ","NOT GSZ"],feature_names=X_train.columns, impurity=False,filled=True)graph = graphviz.Source(dot_data)
graph
n_features = X_train.shape[1]plt.barh(range(n_features),tree.feature_importances_,align='center')plt.yticks(np.arange(n_features),X_train.columns)plt.xlabel("Feature importance")plt.ylabel("Feature")Text(0,0.5,'Feature')
from sklearn.metrics import confusion_matrixconfusion = confusion_matrix(y_test,y_pred)print("Confusion matrix:\n{}".format(confusion))Confusion matrix: [[70 2] [ 0 0]]
from sklearn.metrics import classification_report#print(classification_report(y_test,y_pred))print(classification_report(y_test,y_pred_changed_threshold))
precision recall f1-score support 0 0.97 0.94 0.96 70 1 0.00 0.00 0.00 2 *g / total 0.94 0.92 0.93 72
from sklearn.metrics import precision_recall_curveprecision,recall,thresholds = precision_recall_curve(y_test,y_pred_threshold)close_zero = np.argmin(np.abs(thresholds))plt.plot(precision[close_zero],recall[close_zero],'o',markersize=10,label="threshold zero",\ fillstyle="none",c='k',mew=2)plt.plot(precision,recall,label="precison recall curve")plt.xlabel("Precision")plt.ylabel("Recall")Text(0,0.5,'Recall')
###取出2018年数据statDate = '2018q3'mp_startdate = '2018-10-01' mp_enddate = '2018-11-01'year = 2018 month = 11 day = 1per_zbgj = get_perstock_indicator(balance.capital_reserve_fund,'capital_reserve_fund','per_CapitalReserveFund',statDate)per_wflr = get_perstock_indicator(balance.retained_profit,'retained_profit','per_RetainedProfit',statDate)per_jzc = get_perstock_indicator(balance.total_owner_equities,'total_owner_equities','per_TotalOwnerEquity',statDate)other_indicator = get_other_indicator(statDate)code_list = other_indicator['code'].tolist()mean_price = get_bmonth_aprice(code_list,mp_startdate,mp_enddate)cx_signal = judge_cxstock(mp_enddate)days_listed = get_dayslisted(year,month,day)chart_list = [per_zbgj,per_wflr,per_jzc,other_indicator,mean_price,cx_signal,days_listed]for chart in chart_list:chart.set_index('code',inplace = True)independ_vari = pd.concat([per_zbgj,per_wflr,per_jzc,other_indicator,mean_price,cx_signal,days_listed],axis = 1)independ_vari['year'] = str(int(statDate[0:4]))independ_vari['stock'] = independ_vari.indexindepend_vari.reset_index(drop=True,inplace =True)independ_vari['per_zbgj_wflr'] = independ_vari['per_CapitalReserveFund']+independ_vari['per_RetainedProfit']gsz_2018 = independ_varigsz_2018.loc[gsz_2018['revenue_growth']>300,'revenue_growth'] = 300testdata = gsz_2018testdata.dropna(inplace = True)###利用决策树做预测X_2018 = testdata[variable_list]y_2018 = tree.predict(X_2018)y_2018_proba = tree.predict_proba(X_2018)/opt/conda/lib/python3.5/site-packages/ipykernel_launcher.py:8: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
total_tree = testdata[['stock']].copy()total_tree['predict_prob'] = y_2018_proba[:,1]
#total_tree.sort_values(by=['predict_prob','stock'],inplace = True,ascending = [False,True])total_tree.sort_values(by='predict_prob',inplace = True,ascending = False)total_tree.reset_index(drop=True,inplace = True)total_tree[:50]
.dataframe thead tr:only-child th { text-align: right; } .dataframe thead th { text-align: left; } .dataframe tbody tr th { vertical-align: top; }
| stock | predict_prob | |
|---|---|---|
| 0 | 000011.XSHE | 1.0 |
| 1 | 600793.XSHG | 1.0 |
| 2 | 600658.XSHG | 1.0 |
| 3 | 600682.XSHG | 1.0 |
| 4 | 600697.XSHG | 1.0 |
| 5 | 600701.XSHG | 1.0 |
| 6 | 600706.XSHG | 1.0 |
| 7 | 600791.XSHG | 1.0 |
| 8 | 600847.XSHG | 1.0 |
| 9 | 300623.XSHE | 1.0 |
| 10 | 600889.XSHG | 1.0 |
| 11 | 600891.XSHG | 1.0 |
| 12 | 600976.XSHG | 1.0 |
| 13 | 600980.XSHG | 1.0 |
| 14 | 600990.XSHG | 1.0 |
| 15 | 601872.XSHG | 1.0 |
| 16 | 600636.XSHG | 1.0 |
| 17 | 600605.XSHG | 1.0 |
| 18 | 600599.XSHG | 1.0 |
| 19 | 600593.XSHG | 1.0 |
| 20 | 600543.XSHG | 1.0 |
| 21 | 600485.XSHG | 1.0 |
| 22 | 600444.XSHG | 1.0 |
| 23 | 600429.XSHG | 1.0 |
| 24 | 600381.XSHG | 1.0 |
| 25 | 600345.XSHG | 1.0 |
| 26 | 600262.XSHG | 1.0 |
| 27 | 600259.XSHG | 1.0 |
| 28 | 600241.XSHG | 1.0 |
| 29 | 600211.XSHG | 1.0 |
| 30 | 600208.XSHG | 1.0 |
| 31 | 600155.XSHG | 1.0 |
| 32 | 600152.XSHG | 1.0 |
| 33 | 603006.XSHG | 1.0 |
| 34 | 603016.XSHG | 1.0 |
| 35 | 603026.XSHG | 1.0 |
| 36 | 603083.XSHG | 1.0 |
| 37 | 603161.XSHG | 1.0 |
| 38 | 603159.XSHG | 1.0 |
| 39 | 603139.XSHG | 1.0 |
| 40 | 603136.XSHG | 1.0 |
| 41 | 603131.XSHG | 1.0 |
| 42 | 603129.XSHG | 1.0 |
| 43 | 603127.XSHG | 1.0 |
| 44 | 603110.XSHG | 1.0 |
| 45 | 603106.XSHG | 1.0 |
| 46 | 603096.XSHG | 1.0 |
| 47 | 603090.XSHG | 1.0 |
| 48 | 603089.XSHG | 1.0 |
| 49 | 603088.XSHG | 1.0 |

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...