市场风格变化莫测,交易中总是抓不住市场的节奏,而且我等韭菜也疲于日常工作,迫于资源限制,投资股市时不能做到既关注实时热点,把握大势,又了解行业,深究公司,这样一来,似乎已经落后那些花大力气在做行业研究,公司研究的机构或者大牛们。然而,也不尽然如此,毕竟,对股市所有的看法,最终落地都是参与市场进行交易,总是在市场上留下痕迹。研究量价特征,不失为一种讨巧的办法。
以上就是技术分析爱好者的理论基础了,这对于众多没有便利的渠道掌握一手信息,没有丰富的知识储备分析大势的散户来说,是个好消息,在这个层面来讲,大家几乎掌握着一致的信息,问题就在于谁能挖掘出更多的价值信息。同样,这最轻松的投资方式,也可能是因为这种方式投资成本最低,画几条趋势线,认几个形态,就能做出买卖决定,从市场中赚钱,这可能就是交易吸引人的地方了,也是交易不容易赚钱的原因了,哈哈哈,扯远了都。
下面的内容就是想研究市场的量价方面的特征,因子来源于国泰君安数量化专题,内容参考短周期价量特征的多因子选股体系的内容,在聚宽上尝试建立因子效果检查部分内容,也参考了之前止一之路的帖子。
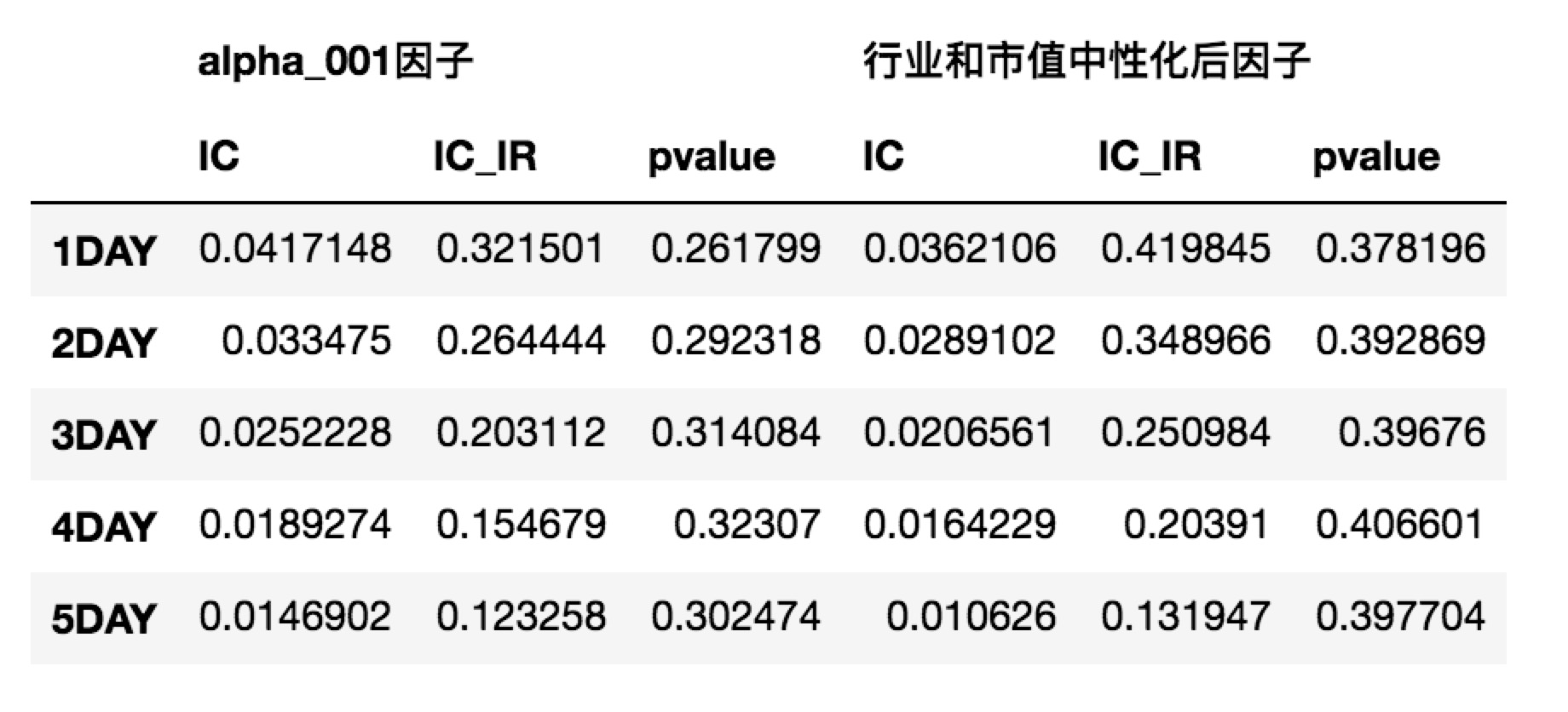
因子数据计算时因为有点耗时,本篇文章中只用到了alpha191因子的第一个因子数据进行了演示说明,将因子值计算出来,行业市值中性,计算不同周期长度的收益,后面若有兴趣可以进行类似的尝试计算更多的结果。
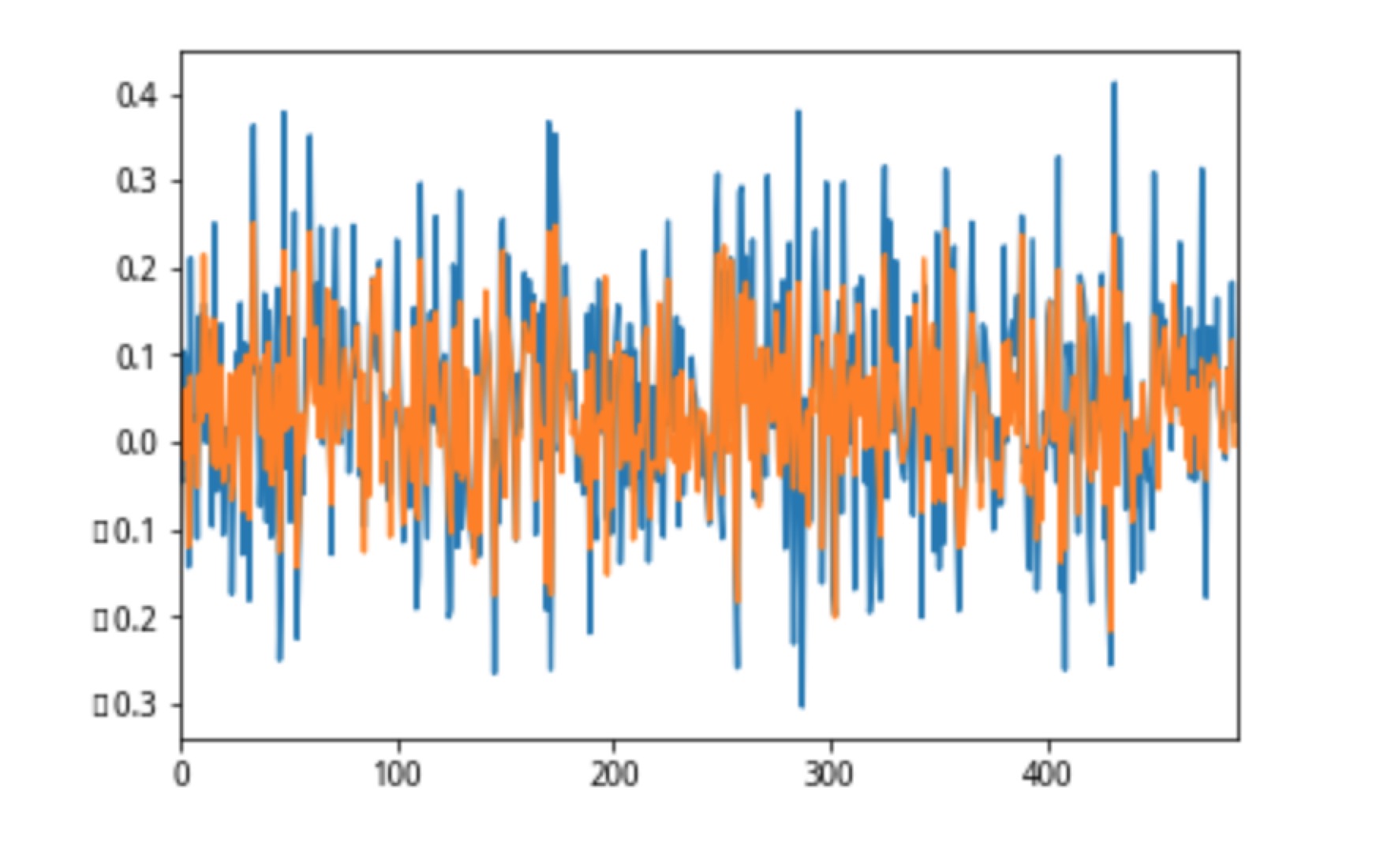
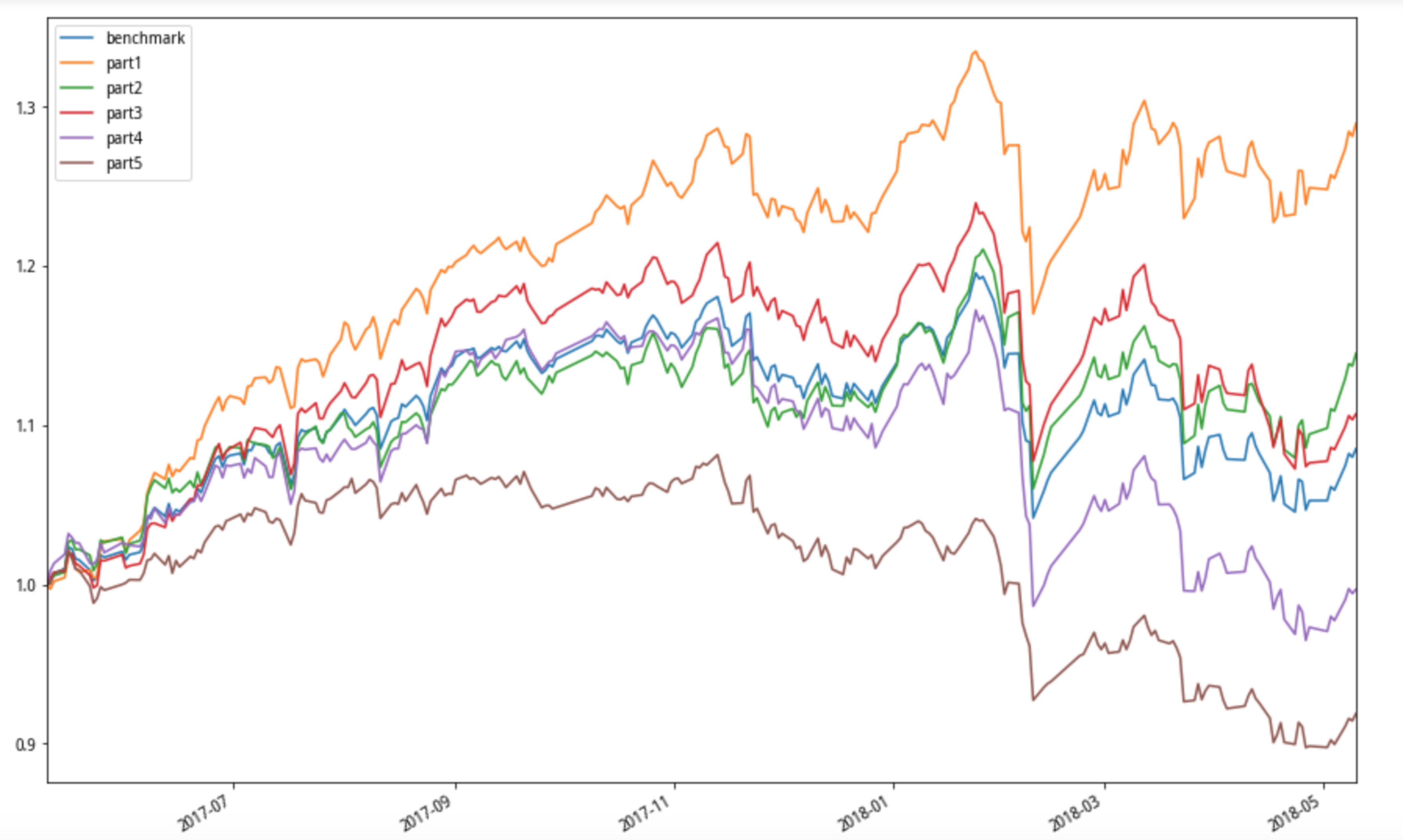
貌似中性化处理后,并没有太过明显的差距,后面可以考虑剔除更多的风格因子,关于代码或者处理方法都可以留言一起探讨
import pandas as pd
import numpy as np
from jqlib.alpha191 import *
import jqdata
import datetime
import time
import statsmodels.api as sm
import scipy.stats as st
import math
from statsmodels import regression
import matplotlib.pyplot as plt
/opt/conda/envs/python2new/lib/python2.7/site-packages/statsmodels/compat/pandas.py:56: FutureWarning: The pandas.core.datetools module is deprecated and will be removed in a future version. Please use the pandas.tseries module instead. from pandas.core import datetools
#计算并保存alpha002因子值
#参数:开始时间,结束时间,股票池,不同alpha因子的API
#输出:index为日期,column是股票名称,values是因子值的dataframe
#将alpha因子值保存为CSV格式文件,使用时直接调用
df_sh50 = get_price('000300.XSHG',start_date='2017-5-10',end_date='2018-5-10')
index_date = df_sh50.index
#对于不同时期的成分股不一致的情况,经过检查,对对columns进行校验
columns_stock = get_index_stocks('000300.XSHG')
alpha_002_factor = pd.DataFrame(index = index_date,columns = columns_stock)
alpha_002_factor_neu = pd.DataFrame(index = index_date,columns = columns_stock)
for i in index_date:
print i
code= list(get_index_stocks('000300.XSHG'))
temp_a = alpha_002(code,i)
#temp_a_neu = get_factor_ne(temp_a,i)['factor_ne']
temp_a = temp_a.dropna()
temp_a_neu = get_factor_neutra(temp_a,i)
#print temp_a_neu
alpha_002_factor.loc[i,:] = temp_a
#中性化后的因子值
alpha_002_factor_neu.loc[i,:] = temp_a_neu
alpha_002_factor.to_csv('alpha_002.csv')
alpha_002_factor_neu.to_csv('alpha_002_neutra.csv')
2017-05-10 00:00:00 2017-05-11 00:00:00 2017-05-12 00:00:00 2017-05-15 00:00:00 2017-05-16 00:00:00 2017-05-17 00:00:00 2017-05-18 00:00:00 2017-05-19 00:00:00 2017-05-22 00:00:00 2017-05-23 00:00:00 2017-05-24 00:00:00 2017-05-25 00:00:00 2017-05-26 00:00:00 2017-05-31 00:00:00 2017-06-01 00:00:00 2017-06-02 00:00:00 2017-06-05 00:00:00 2017-06-06 00:00:00 2017-06-07 00:00:00 2017-06-08 00:00:00 2017-06-09 00:00:00 2017-06-12 00:00:00 2017-06-13 00:00:00 2017-06-14 00:00:00 2017-06-15 00:00:00 2017-06-16 00:00:00 2017-06-19 00:00:00 2017-06-20 00:00:00 2017-06-21 00:00:00 2017-06-22 00:00:00 2017-06-23 00:00:00 2017-06-26 00:00:00 2017-06-27 00:00:00 2017-06-28 00:00:00 2017-06-29 00:00:00 2017-06-30 00:00:00 2017-07-03 00:00:00 2017-07-04 00:00:00 2017-07-05 00:00:00 2017-07-06 00:00:00 2017-07-07 00:00:00 2017-07-10 00:00:00 2017-07-11 00:00:00 2017-07-12 00:00:00 2017-07-13 00:00:00 2017-07-14 00:00:00 2017-07-17 00:00:00 2017-07-18 00:00:00 2017-07-19 00:00:00 2017-07-20 00:00:00 2017-07-21 00:00:00 2017-07-24 00:00:00 2017-07-25 00:00:00 2017-07-26 00:00:00 2017-07-27 00:00:00 2017-07-28 00:00:00 2017-07-31 00:00:00 2017-08-01 00:00:00 2017-08-02 00:00:00 2017-08-03 00:00:00 2017-08-04 00:00:00 2017-08-07 00:00:00 2017-08-08 00:00:00 2017-08-09 00:00:00 2017-08-10 00:00:00 2017-08-11 00:00:00 2017-08-14 00:00:00 2017-08-15 00:00:00 2017-08-16 00:00:00 2017-08-17 00:00:00 2017-08-18 00:00:00 2017-08-21 00:00:00 2017-08-22 00:00:00 2017-08-23 00:00:00 2017-08-24 00:00:00 2017-08-25 00:00:00 2017-08-28 00:00:00 2017-08-29 00:00:00 2017-08-30 00:00:00 2017-08-31 00:00:00 2017-09-01 00:00:00 2017-09-04 00:00:00 2017-09-05 00:00:00 2017-09-06 00:00:00 2017-09-07 00:00:00 2017-09-08 00:00:00 2017-09-11 00:00:00 2017-09-12 00:00:00 2017-09-13 00:00:00 2017-09-14 00:00:00 2017-09-15 00:00:00 2017-09-18 00:00:00 2017-09-19 00:00:00 2017-09-20 00:00:00 2017-09-21 00:00:00 2017-09-22 00:00:00 2017-09-25 00:00:00 2017-09-26 00:00:00 2017-09-27 00:00:00 2017-09-28 00:00:00 2017-09-29 00:00:00 2017-10-09 00:00:00 2017-10-10 00:00:00 2017-10-11 00:00:00 2017-10-12 00:00:00 2017-10-13 00:00:00 2017-10-16 00:00:00 2017-10-17 00:00:00 2017-10-18 00:00:00 2017-10-19 00:00:00 2017-10-20 00:00:00 2017-10-23 00:00:00 2017-10-24 00:00:00 2017-10-25 00:00:00 2017-10-26 00:00:00 2017-10-27 00:00:00 2017-10-30 00:00:00 2017-10-31 00:00:00 2017-11-01 00:00:00 2017-11-02 00:00:00 2017-11-03 00:00:00 2017-11-06 00:00:00 2017-11-07 00:00:00 2017-11-08 00:00:00 2017-11-09 00:00:00 2017-11-10 00:00:00 2017-11-13 00:00:00 2017-11-14 00:00:00 2017-11-15 00:00:00 2017-11-16 00:00:00 2017-11-17 00:00:00 2017-11-20 00:00:00 2017-11-21 00:00:00 2017-11-22 00:00:00 2017-11-23 00:00:00 2017-11-24 00:00:00 2017-11-27 00:00:00 2017-11-28 00:00:00 2017-11-29 00:00:00 2017-11-30 00:00:00 2017-12-01 00:00:00 2017-12-04 00:00:00 2017-12-05 00:00:00 2017-12-06 00:00:00 2017-12-07 00:00:00 2017-12-08 00:00:00 2017-12-11 00:00:00 2017-12-12 00:00:00 2017-12-13 00:00:00 2017-12-14 00:00:00 2017-12-15 00:00:00 2017-12-18 00:00:00 2017-12-19 00:00:00 2017-12-20 00:00:00 2017-12-21 00:00:00 2017-12-22 00:00:00 2017-12-25 00:00:00 2017-12-26 00:00:00 2017-12-27 00:00:00 2017-12-28 00:00:00 2017-12-29 00:00:00 2018-01-02 00:00:00 2018-01-03 00:00:00 2018-01-04 00:00:00 2018-01-05 00:00:00 2018-01-08 00:00:00 2018-01-09 00:00:00 2018-01-10 00:00:00 2018-01-11 00:00:00 2018-01-12 00:00:00 2018-01-15 00:00:00 2018-01-16 00:00:00 2018-01-17 00:00:00 2018-01-18 00:00:00 2018-01-19 00:00:00 2018-01-22 00:00:00 2018-01-23 00:00:00 2018-01-24 00:00:00 2018-01-25 00:00:00 2018-01-26 00:00:00 2018-01-29 00:00:00 2018-01-30 00:00:00 2018-01-31 00:00:00 2018-02-01 00:00:00 2018-02-02 00:00:00 2018-02-05 00:00:00 2018-02-06 00:00:00 2018-02-07 00:00:00 2018-02-08 00:00:00 2018-02-09 00:00:00 2018-02-12 00:00:00 2018-02-13 00:00:00 2018-02-14 00:00:00 2018-02-22 00:00:00 2018-02-23 00:00:00 2018-02-26 00:00:00 2018-02-27 00:00:00 2018-02-28 00:00:00 2018-03-01 00:00:00 2018-03-02 00:00:00 2018-03-05 00:00:00 2018-03-06 00:00:00 2018-03-07 00:00:00 2018-03-08 00:00:00 2018-03-09 00:00:00 2018-03-12 00:00:00 2018-03-13 00:00:00 2018-03-14 00:00:00 2018-03-15 00:00:00 2018-03-16 00:00:00 2018-03-19 00:00:00 2018-03-20 00:00:00 2018-03-21 00:00:00 2018-03-22 00:00:00 2018-03-23 00:00:00 2018-03-26 00:00:00 2018-03-27 00:00:00 2018-03-28 00:00:00 2018-03-29 00:00:00 2018-03-30 00:00:00 2018-04-02 00:00:00 2018-04-03 00:00:00 2018-04-04 00:00:00 2018-04-09 00:00:00 2018-04-10 00:00:00 2018-04-11 00:00:00 2018-04-12 00:00:00 2018-04-13 00:00:00 2018-04-16 00:00:00 2018-04-17 00:00:00 2018-04-18 00:00:00 2018-04-19 00:00:00 2018-04-20 00:00:00 2018-04-23 00:00:00 2018-04-24 00:00:00 2018-04-25 00:00:00 2018-04-26 00:00:00 2018-04-27 00:00:00 2018-05-02 00:00:00 2018-05-03 00:00:00 2018-05-04 00:00:00 2018-05-07 00:00:00 2018-05-08 00:00:00 2018-05-09 00:00:00 2018-05-10 00:00:00
#计算并保存alpha003因子值
#参数:开始时间,结束时间,股票池,不同alpha因子的API
#输出:index为日期,column是股票名称,values是因子值的dataframe
#将alpha因子值保存为CSV格式文件,使用时直接调用
df_sh50 = get_price('000300.XSHG',start_date='2017-5-10',end_date='2018-5-10')
index_date = df_sh50.index
#对于不同时期的成分股不一致的情况,经过检查,对对columns进行校验
columns_stock = get_index_stocks('000300.XSHG')
alpha_003_factor = pd.DataFrame(index = index_date,columns = columns_stock)
alpha_003_factor_neu = pd.DataFrame(index = index_date,columns = columns_stock)
for i in index_date:
print i
code= list(get_index_stocks('000300.XSHG'))
temp_a = alpha_003(code,i)
#temp_a_neu = get_factor_ne(temp_a,i)['factor_ne']
temp_a = temp_a.dropna()
temp_a_neu = get_factor_neutra(temp_a,i)
#print temp_a_neu
alpha_003_factor.loc[i,:] = temp_a
#中性化后的因子值
alpha_003_factor_neu.loc[i,:] = temp_a_neu
alpha_003_factor.to_csv('alpha_003.csv')
alpha_003_factor_neu.to_csv('alpha_003_neutra.csv')
2017-05-10 00:00:00 2017-05-11 00:00:00 2017-05-12 00:00:00 2017-05-15 00:00:00 2017-05-16 00:00:00 2017-05-17 00:00:00 2017-05-18 00:00:00 2017-05-19 00:00:00 2017-05-22 00:00:00 2017-05-23 00:00:00 2017-05-24 00:00:00 2017-05-25 00:00:00 2017-05-26 00:00:00 2017-05-31 00:00:00 2017-06-01 00:00:00 2017-06-02 00:00:00 2017-06-05 00:00:00 2017-06-06 00:00:00 2017-06-07 00:00:00 2017-06-08 00:00:00 2017-06-09 00:00:00 2017-06-12 00:00:00 2017-06-13 00:00:00 2017-06-14 00:00:00 2017-06-15 00:00:00 2017-06-16 00:00:00 2017-06-19 00:00:00 2017-06-20 00:00:00 2017-06-21 00:00:00 2017-06-22 00:00:00 2017-06-23 00:00:00 2017-06-26 00:00:00 2017-06-27 00:00:00 2017-06-28 00:00:00 2017-06-29 00:00:00 2017-06-30 00:00:00 2017-07-03 00:00:00 2017-07-04 00:00:00 2017-07-05 00:00:00 2017-07-06 00:00:00 2017-07-07 00:00:00 2017-07-10 00:00:00 2017-07-11 00:00:00 2017-07-12 00:00:00 2017-07-13 00:00:00 2017-07-14 00:00:00 2017-07-17 00:00:00 2017-07-18 00:00:00 2017-07-19 00:00:00 2017-07-20 00:00:00 2017-07-21 00:00:00 2017-07-24 00:00:00 2017-07-25 00:00:00 2017-07-26 00:00:00 2017-07-27 00:00:00 2017-07-28 00:00:00 2017-07-31 00:00:00 2017-08-01 00:00:00 2017-08-02 00:00:00 2017-08-03 00:00:00 2017-08-04 00:00:00 2017-08-07 00:00:00 2017-08-08 00:00:00 2017-08-09 00:00:00 2017-08-10 00:00:00 2017-08-11 00:00:00 2017-08-14 00:00:00 2017-08-15 00:00:00 2017-08-16 00:00:00 2017-08-17 00:00:00 2017-08-18 00:00:00 2017-08-21 00:00:00 2017-08-22 00:00:00 2017-08-23 00:00:00 2017-08-24 00:00:00 2017-08-25 00:00:00 2017-08-28 00:00:00 2017-08-29 00:00:00 2017-08-30 00:00:00 2017-08-31 00:00:00 2017-09-01 00:00:00 2017-09-04 00:00:00 2017-09-05 00:00:00 2017-09-06 00:00:00 2017-09-07 00:00:00 2017-09-08 00:00:00 2017-09-11 00:00:00 2017-09-12 00:00:00 2017-09-13 00:00:00 2017-09-14 00:00:00 2017-09-15 00:00:00 2017-09-18 00:00:00 2017-09-19 00:00:00 2017-09-20 00:00:00 2017-09-21 00:00:00 2017-09-22 00:00:00 2017-09-25 00:00:00 2017-09-26 00:00:00 2017-09-27 00:00:00 2017-09-28 00:00:00 2017-09-29 00:00:00 2017-10-09 00:00:00 2017-10-10 00:00:00 2017-10-11 00:00:00 2017-10-12 00:00:00 2017-10-13 00:00:00 2017-10-16 00:00:00 2017-10-17 00:00:00 2017-10-18 00:00:00 2017-10-19 00:00:00 2017-10-20 00:00:00 2017-10-23 00:00:00 2017-10-24 00:00:00 2017-10-25 00:00:00 2017-10-26 00:00:00 2017-10-27 00:00:00 2017-10-30 00:00:00 2017-10-31 00:00:00 2017-11-01 00:00:00 2017-11-02 00:00:00 2017-11-03 00:00:00 2017-11-06 00:00:00 2017-11-07 00:00:00 2017-11-08 00:00:00 2017-11-09 00:00:00 2017-11-10 00:00:00 2017-11-13 00:00:00 2017-11-14 00:00:00 2017-11-15 00:00:00 2017-11-16 00:00:00 2017-11-17 00:00:00 2017-11-20 00:00:00 2017-11-21 00:00:00 2017-11-22 00:00:00 2017-11-23 00:00:00 2017-11-24 00:00:00 2017-11-27 00:00:00 2017-11-28 00:00:00 2017-11-29 00:00:00 2017-11-30 00:00:00 2017-12-01 00:00:00 2017-12-04 00:00:00 2017-12-05 00:00:00 2017-12-06 00:00:00 2017-12-07 00:00:00 2017-12-08 00:00:00 2017-12-11 00:00:00 2017-12-12 00:00:00 2017-12-13 00:00:00 2017-12-14 00:00:00 2017-12-15 00:00:00 2017-12-18 00:00:00 2017-12-19 00:00:00 2017-12-20 00:00:00 2017-12-21 00:00:00 2017-12-22 00:00:00 2017-12-25 00:00:00 2017-12-26 00:00:00 2017-12-27 00:00:00 2017-12-28 00:00:00 2017-12-29 00:00:00 2018-01-02 00:00:00 2018-01-03 00:00:00 2018-01-04 00:00:00 2018-01-05 00:00:00 2018-01-08 00:00:00 2018-01-09 00:00:00 2018-01-10 00:00:00 2018-01-11 00:00:00 2018-01-12 00:00:00 2018-01-15 00:00:00 2018-01-16 00:00:00 2018-01-17 00:00:00 2018-01-18 00:00:00 2018-01-19 00:00:00 2018-01-22 00:00:00 2018-01-23 00:00:00 2018-01-24 00:00:00 2018-01-25 00:00:00 2018-01-26 00:00:00 2018-01-29 00:00:00 2018-01-30 00:00:00 2018-01-31 00:00:00 2018-02-01 00:00:00 2018-02-02 00:00:00 2018-02-05 00:00:00 2018-02-06 00:00:00 2018-02-07 00:00:00 2018-02-08 00:00:00 2018-02-09 00:00:00 2018-02-12 00:00:00 2018-02-13 00:00:00 2018-02-14 00:00:00 2018-02-22 00:00:00 2018-02-23 00:00:00 2018-02-26 00:00:00 2018-02-27 00:00:00 2018-02-28 00:00:00 2018-03-01 00:00:00 2018-03-02 00:00:00 2018-03-05 00:00:00 2018-03-06 00:00:00 2018-03-07 00:00:00 2018-03-08 00:00:00 2018-03-09 00:00:00 2018-03-12 00:00:00 2018-03-13 00:00:00 2018-03-14 00:00:00 2018-03-15 00:00:00 2018-03-16 00:00:00 2018-03-19 00:00:00 2018-03-20 00:00:00 2018-03-21 00:00:00 2018-03-22 00:00:00 2018-03-23 00:00:00 2018-03-26 00:00:00 2018-03-27 00:00:00 2018-03-28 00:00:00 2018-03-29 00:00:00 2018-03-30 00:00:00 2018-04-02 00:00:00 2018-04-03 00:00:00 2018-04-04 00:00:00 2018-04-09 00:00:00 2018-04-10 00:00:00 2018-04-11 00:00:00 2018-04-12 00:00:00 2018-04-13 00:00:00 2018-04-16 00:00:00 2018-04-17 00:00:00 2018-04-18 00:00:00 2018-04-19 00:00:00 2018-04-20 00:00:00 2018-04-23 00:00:00 2018-04-24 00:00:00 2018-04-25 00:00:00 2018-04-26 00:00:00 2018-04-27 00:00:00 2018-05-02 00:00:00 2018-05-03 00:00:00 2018-05-04 00:00:00 2018-05-07 00:00:00 2018-05-08 00:00:00 2018-05-09 00:00:00 2018-05-10 00:00:00
#中性化(回归拟合后取残差值为因子的最新值)
#传入:mkt_cap:以股票为index,市值为value的Series,
#factor:以股票code为index,因子值为value的Series,
#输出:中性化后的因子值series
def neutralization(factor,mkt_cap = False, industry = True,date=None):
y = factor
if type(mkt_cap) == pd.Series:
LnMktCap = mkt_cap.apply(lambda x:math.log(x))
if industry: #行业、市值
dummy_industry = get_industry_exposure(factor.index,date)
x = pd.concat([LnMktCap,dummy_industry.T],axis = 1)
else: #仅市值
x = LnMktCap
elif industry: #仅行业
dummy_industry = get_industry_exposure(factor.index)
x = dummy_industry.T
result = sm.OLS(y.astype(float),x.astype(float)).fit()
return result.resid
#为股票池添加行业标记,return df格式 ,为中性化函数的子函数
def get_industry_exposure(stock_list,date):
df = pd.DataFrame(index=jqdata.get_industries(name='sw_l1').index, columns=stock_list)
for stock in stock_list:
try:
df[stock][get_industry_code_from_security(stock,date)] = 1
except:
continue
return df.fillna(0)#将NaN赋为0
#查询个股所在行业函数代码(申万一级) ,为中性化函数的子函数
def get_industry_code_from_security(security,date=None):
industry_index=jqdata.get_industries(name='sw_l1').index
for i in range(0,len(industry_index)):
try:
index = get_industry_stocks(industry_index[i],date=date).index(security)
return industry_index[i]
except:
continue
return u'未找到'
def get_factor_neutra(alpha_factor,date):
h=get_fundamentals(query(valuation.code,valuation.market_cap)\
.filter(valuation.code.in_(alpha_factor.index)),date=date)
stocks_mktcap_se=pd.Series(list(h.market_cap),index=list(h.code))
stocks_neutra_se=neutralization(alpha_factor,stocks_mktcap_se,date)
return stocks_neutra_se
#按行业进行标准化处理的方法
#参数:
#输入:股票名称为index的因子序列,检查日期
#输出: df,包括市值,包括因子值
def get_factor_ne(factor_se,date):
industries = jqdata.get_industries(name='sw_l1').index
df_factor = get_fundamentals(query(valuation.code,valuation.market_cap).filter(valuation.code.in_(factor_se.index)),date)
df_factor.index = df_factor.code
del df_factor['code']
df_factor.columns = ['market_cap']
df_factor['factor'] = factor_se
industries_series = pd.Series()
for aa in industries:
alist = []
stock_list = list(get_industry_stocks(aa, date=date))
for bb in stock_list:
if bb in list(df_factor.index):
alist.append(bb)
aseries = pd.Series(aa, index = alist)
# print aseries
industries_series = pd.concat([industries_series, aseries])
duplicated = industries_series.index.duplicated()
index_list = []
for x in range(len(industries_series.index)):
if duplicated[x] ==True:
index_list.append(list(industries_series.index)[x])
industries_series.drop(index_list, inplace = True)
df_factor['industries_detail'] = industries_series
df_factor.dropna(how = 'any', inplace = True) # 1173/1018 2016/12/31
df_factor['factor_mean'] = NaN
df_factor['factor_std'] = NaN
for x in range(len(industries)):
# 生成均值数据
df_factor['factor_mean'][df_factor['industries_detail'] == industries[x]] \
= df_factor['factor'][df_factor['industries_detail'] == industries[x]].mean()
# 生成方差数据
df_factor['factor_std'][df_factor['industries_detail'] == industries[x]] \
= df_factor['factor'][df_factor['industries_detail'] == industries[x]].std()
# 标准化
df_factor['factor_ne'] = (df_factor['factor'] - df_factor['factor_mean'])/df_factor['factor_std']
#df_factor.dropna(how = 'any', inplace = True)
return df_factor
#进行收益统计构造
#参数:
#输入:开始时间,结束时间,股票池,计算天数
pool = get_index_stocks('000300.XSHG')
start_d='2016-5-9'
end_d='2018-5-10'
days = 1
def get_pool_pct(pool,start_date,end_date,days=1):
df_sh50 = get_price(pool,start_date=start_d,end_date=end_d,fields=['close'])['close']
pct_close = (df_sh50[days:].values-df_sh50[:-days].values)/df_sh50[:-days].values
df_temp = df_sh50#.ix[1:,:]
df_temp.iloc[days:,:]=pct_close
df_temp.iloc[0:days,:] = np.nan
return df_temp
factor_return = get_pool_pct(pool=pool,start_date=start_d,end_date=end_d,days=days)
#计算因子IC值,P值
#输入:因子序列和收益序列
#返回IC和IR
#注意事项:输入的是df格式内容,函数会剔除空值
def get_rank_ic(factor, factor_return,days = 1):
ic_df = pd.DataFrame(index=factor.index, columns=['IC','pValue'])
# 计算相关系数
date_index = factor.index
for i in range(len(date_index)-days):
tmp_factor = factor.ix[date_index[i]]
tmp_ret = factor_return.ix[date_index[i+days]]
cor = pd.DataFrame(tmp_factor)
ret = pd.DataFrame(tmp_ret)
cor.columns = ['corr']
ret.columns = ['ret']
cor['ret'] = ret['ret']
#去除空值
cor = cor[~pd.isnull(cor['corr'])][~pd.isnull(cor['ret'])]
ic, p_value = st.spearmanr(cor['corr'], cor['ret']) # 计算秩相关系数RankIC
ic_df['IC'][i] = ic
ic_df['pValue'][i] = p_value
return ic_df
#因子数据获取比较耗时,这里直接读取的已经存在本地的CSV文件
alpha_001_factor = pd.read_csv('alpha_001.csv')
alpha_001_factor_neu = pd.read_csv('alpha_001_neu.csv')
alpha_001_factor.index = alpha_001_factor.iloc[:,0]
alpha_001_factor_neu.index = alpha_001_factor_neu.iloc[:,0]
#用于计算不同周期的信息系数
factor_ic = {}
factor_neu_ic = {}
for i in range(5):
ic_alpha_day=get_rank_ic(alpha_001_factor,factor_return,days=i+1)
ic_alpha_neu_day=get_rank_ic(alpha_001_factor_neu,factor_return,days=i+1)
factor_ic[str(i+1)+'day']=ic_alpha_day
factor_neu_ic[str(i+1)+'day']=ic_alpha_neu_day
factor_ic
/opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:10: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated # Remove the CWD from sys.path while we load stuff. /opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:11: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated # This is added back by InteractiveShellApp.init_path() /opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:18: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
{'1day': IC pValue
0 -0.0325512 0.599225
1 -0.0462635 0.454143
2 0.103766 0.0930901
3 0.0847722 0.168838
4 -0.143398 0.0197563
5 0.211088 0.000555462
6 0.0305919 0.621398
7 0.0294278 0.633442
8 -0.110679 0.0709847
9 0.144478 0.0181706
10 0.0479846 0.433161
11 0.158497 0.00948303
12 -0.000761458 0.990119
13 0.128105 0.0367893
14 0.0693315 0.258927
15 -0.0968994 0.11283
16 0.250729 3.07897e-05
17 -0.0564929 0.353327
18 -0.0208197 0.733441
19 0.135 0.0262632
20 -0.106695 0.0795483
21 0.0155223 0.799214
22 -0.0427796 0.482298
23 0.0270633 0.656184
24 -0.174528 0.0037552
25 -0.0578074 0.343117
26 0.101989 0.0932154
27 0.0571404 0.346935
28 0.159334 0.00872218
29 -0.129137 0.033591
.. ... ...
458 0.0832798 0.154347
459 0.172722 0.00316892
460 0.0422972 0.472294
461 0.228711 8.48727e-05
462 0.0304881 0.605107
463 0.0965626 0.100769
464 0.0323553 0.583173
465 0.15357 0.0089252
466 -0.0422501 0.473556
467 0.0813818 0.167653
468 -0.044024 0.455169
469 0.128974 0.0280895
470 0.00488431 0.934111
471 0.313418 5.24586e-08
472 -0.0320121 0.587828
473 -0.17822 0.00231676
474 0.131821 0.0247715
475 0.0630512 0.284551
476 0.12994 0.0266594
477 0.0782491 0.183148
478 0.16528 0.00477412
479 0.0440963 0.456791
480 0.0146184 0.804561
481 0.032384 0.583495
482 -0.0199018 0.735751
483 0.0845603 0.15019
484 0.0477487 0.417894
485 0.183121 0.00173919
486 0.0248344 0.673109
487 NaN NaN
[488 rows x 2 columns], '2day': IC pValue
0 -0.0629855 0.308869
1 0.0198755 0.747878
2 0.079178 0.200564
3 -0.141565 0.0211529
4 0.233844 0.000125669
5 0.173071 0.00480188
6 0.0349641 0.572418
7 -0.0021884 0.971716
8 0.152491 0.0126082
9 0.021518 0.72634
10 0.156411 0.0101929
11 -0.0673022 0.273162
12 0.1638 0.00731627
13 0.0759822 0.216763
14 -0.242812 6.09426e-05
15 0.0844765 0.167114
16 -0.0776523 0.203388
17 0.0920267 0.130034
18 0.162318 0.00752811
19 -0.116289 0.0558751
20 0.00970124 0.873694
21 -0.0527188 0.387341
22 0.0515109 0.397447
23 -0.166853 0.00571641
24 -0.0833905 0.168684
25 0.104897 0.084781
26 0.0603345 0.321499
27 0.192409 0.00140106
28 -0.11282 0.0641506
29 0.0990213 0.10383
.. ... ...
458 0.0423907 0.469018
459 0.0692149 0.239992
460 0.267111 3.81523e-06
461 -0.0162369 0.783064
462 0.124293 0.0343708
463 -0.0438933 0.456509
464 0.0782272 0.184031
465 -0.0684607 0.245988
466 0.0939277 0.110455
467 0.00798227 0.892523
468 0.104767 0.0748599
469 0.0106916 0.856139
470 0.293568 3.74613e-07
471 -0.168142 0.00415099
472 -0.150847 0.0102287
473 0.101955 0.0830516
474 0.0101044 0.863962
475 0.125128 0.0331688
476 0.0771821 0.18921
477 0.00400974 0.945701
478 -0.0771689 0.190054
479 0.0642117 0.278282
480 0.066898 0.256959
481 0.103991 0.0775675
482 0.0245137 0.67762
483 -0.00366654 0.950342
484 0.173249 0.00307637
485 0.0147688 0.802254
486 NaN NaN
487 NaN NaN
[488 rows x 2 columns], '3day': IC pValue
0 -0.0243898 0.693794
1 0.0575214 0.35188
2 -0.174327 0.00457712
3 0.226679 0.00019829
4 0.130043 0.0346948
5 -0.117311 0.0569601
6 0.00459606 0.940866
7 0.0695949 0.258925
8 0.0287341 0.640205
9 0.0953753 0.120023
10 -0.0567579 0.353765
11 0.199031 0.00107658
12 -0.0785902 0.2005
13 -0.214921 0.000415413
14 -0.0256282 0.676772
15 -0.109539 0.0728754
16 0.101877 0.0948025
17 0.189131 0.0017292
18 -0.179547 0.0030698
19 0.032276 0.596797
20 -0.085082 0.162508
21 0.00209657 0.972595
22 -0.110198 0.0695866
23 -0.129295 0.0327219
24 0.0636558 0.293746
25 0.012542 0.837165
26 0.21222 0.000424884
27 -0.11632 0.0549055
28 0.152135 0.0123209
29 0.163869 0.00686233
.. ... ...
458 0.0610033 0.297178
459 0.260211 7.1331e-06
460 0.00543286 0.926476
461 0.145794 0.0129423
462 -0.0671292 0.254487
463 -0.0551603 0.349273
464 -0.134219 0.0222455
465 0.115088 0.0506393
466 -0.0259631 0.659719
467 0.0255725 0.665073
468 -0.0396878 0.500817
469 0.176078 0.00262023
470 -0.136145 0.0206003
471 -0.120208 0.0411429
472 0.0996164 0.0909617
473 0.0822764 0.162283
474 0.178643 0.00226087
475 0.0769109 0.191544
476 0.00962391 0.870149
477 0.0148943 0.80027
478 0.0781048 0.184721
479 0.0749081 0.205777
480 0.0856011 0.146619
481 -0.0162343 0.783466
482 -0.0259744 0.659581
483 0.107978 0.0658541
484 0.0377491 0.521981
485 NaN NaN
486 NaN NaN
487 NaN NaN
[488 rows x 2 columns], '4day': IC pValue
0 0.0819587 0.185156
1 -0.233889 0.000125286
2 0.287934 2.0523e-06
3 0.180741 0.00315016
4 -0.116255 0.0592476
5 0.0195204 0.752234
6 0.00260236 0.966497
7 0.0133127 0.829222
8 0.0238694 0.697828
9 -0.0389373 0.52641
10 0.150864 0.0132485
11 -0.0772188 0.208492
12 -0.23246 0.00012646
13 -0.0544847 0.376107
14 -0.199733 0.00103263
15 0.16151 0.00795278
16 0.23563 9.26727e-05
17 -0.172575 0.0043101
18 0.0698632 0.252606
19 -0.106854 0.0790988
20 0.0329688 0.588939
21 0.123957 0.0414467
22 -0.167655 0.00557228
23 0.149146 0.0136323
24 -0.0523312 0.38821
25 0.194876 0.00126324
26 -0.0716961 0.238592
27 0.111941 0.0647636
28 0.149928 0.0136593
29 -0.0749464 0.218772
.. ... ...
458 0.290341 4.04833e-07
459 0.0266132 0.651753
460 0.131094 0.0253306
461 -0.0203115 0.73052
462 -0.0320176 0.587112
463 -0.0653113 0.267607
464 0.0862965 0.142658
465 0.0124458 0.833145
466 0.0736355 0.211208
467 -0.0767864 0.193042
468 0.0641485 0.276237
469 -0.105269 0.0734692
470 -0.0958584 0.103891
471 0.0483174 0.413178
472 0.0425572 0.471117
473 -0.0402118 0.495175
474 0.0279847 0.635074
475 -0.0374525 0.525257
476 -0.0389268 0.508333
477 0.147726 0.0116347
478 0.083015 0.158532
479 0.0645822 0.275512
480 -0.00921437 0.876058
481 -0.0877411 0.136749
482 0.119245 0.0424443
483 0.0142805 0.808337
484 NaN NaN
485 NaN NaN
486 NaN NaN
487 NaN NaN
[488 rows x 2 columns], '5day': IC pValue
0 -0.218641 0.000354007
1 0.163391 0.0078119
2 0.169402 0.00588551
3 -0.121945 0.0473518
4 0.129282 0.0357793
5 -0.155612 0.0113464
6 0.0517323 0.403424
7 0.153341 0.0124473
8 -0.0843436 0.169389
9 0.117874 0.0543864
10 0.00933894 0.878824
11 -0.227008 0.000183363
12 0.0447693 0.466327
13 -0.0897818 0.144194
14 0.214596 0.000413529
15 0.0779474 0.202515
16 -0.229252 0.000144552
17 -0.013081 0.82996
18 -0.0408444 0.503938
19 -0.0392211 0.520273
20 0.158865 0.00879768
21 -0.165627 0.00627862
22 0.143717 0.0177089
23 -0.124786 0.03936
24 0.198115 0.000976773
25 -0.0566564 0.352828
26 0.110207 0.0695624
27 0.155191 0.0102289
28 -0.149911 0.0136705
29 -0.0131562 0.82931
.. ... ...
458 -0.0480161 0.412062
459 0.103316 0.079
460 -0.01675 0.776009
461 -0.0888995 0.130952
462 -0.0843498 0.151922
463 0.0200563 0.733778
464 -0.0713412 0.225821
465 0.0229844 0.697208
466 -0.163141 0.00535486
467 0.0428611 0.467952
468 -0.00172116 0.976718
469 -0.194136 0.000889246
470 0.00796346 0.892775
471 0.080842 0.170499
472 0.0270098 0.647484
473 -0.0215971 0.714186
474 -0.0394058 0.503867
475 -0.0497814 0.398329
476 0.0972651 0.0977208
477 0.148836 0.0110156
478 0.0507965 0.388768
479 0.0247429 0.676382
480 -0.192798 0.000986613
481 0.0492726 0.403993
482 -0.0295379 0.616407
483 NaN NaN
484 NaN NaN
485 NaN NaN
486 NaN NaN
487 NaN NaN
[488 rows x 2 columns]}
alpha_report = pd.DataFrame(index=['1DAY', '2DAY', '3DAY','4DAY','5DAY'],
columns=[['alpha_001因子','alpha_001因子','alpha_001因子', '行业和市值中性化后因子', '行业和市值中性化后因子','行业和市值中性化后因子'],
['IC', 'IC_IR', 'pvalue', 'IC', 'IC_IR', 'pvalue']])
for i in range(1,6):
l = [factor_ic[str(i)+'day']['IC'].mean(),factor_ic[str(i)+'day']['IC'].mean()/factor_ic[str(i)+'day']['IC'].std(),factor_ic[str(i)+'day']['pValue'].mean()]
l_neu = [factor_neu_ic[str(i)+'day']['IC'].mean(),factor_neu_ic[str(i)+'day']['IC'].mean()/factor_neu_ic[str(i)+'day']['IC'].std(),factor_neu_ic[str(i)+'day']['pValue'].mean()]
alpha_report.loc[str(i)+'DAY',:] = l+l_neu
alpha_report
| alpha_001因子 | 行业和市值中性化后因子 | |||||
|---|---|---|---|---|---|---|
| IC | IC_IR | pvalue | IC | IC_IR | pvalue | |
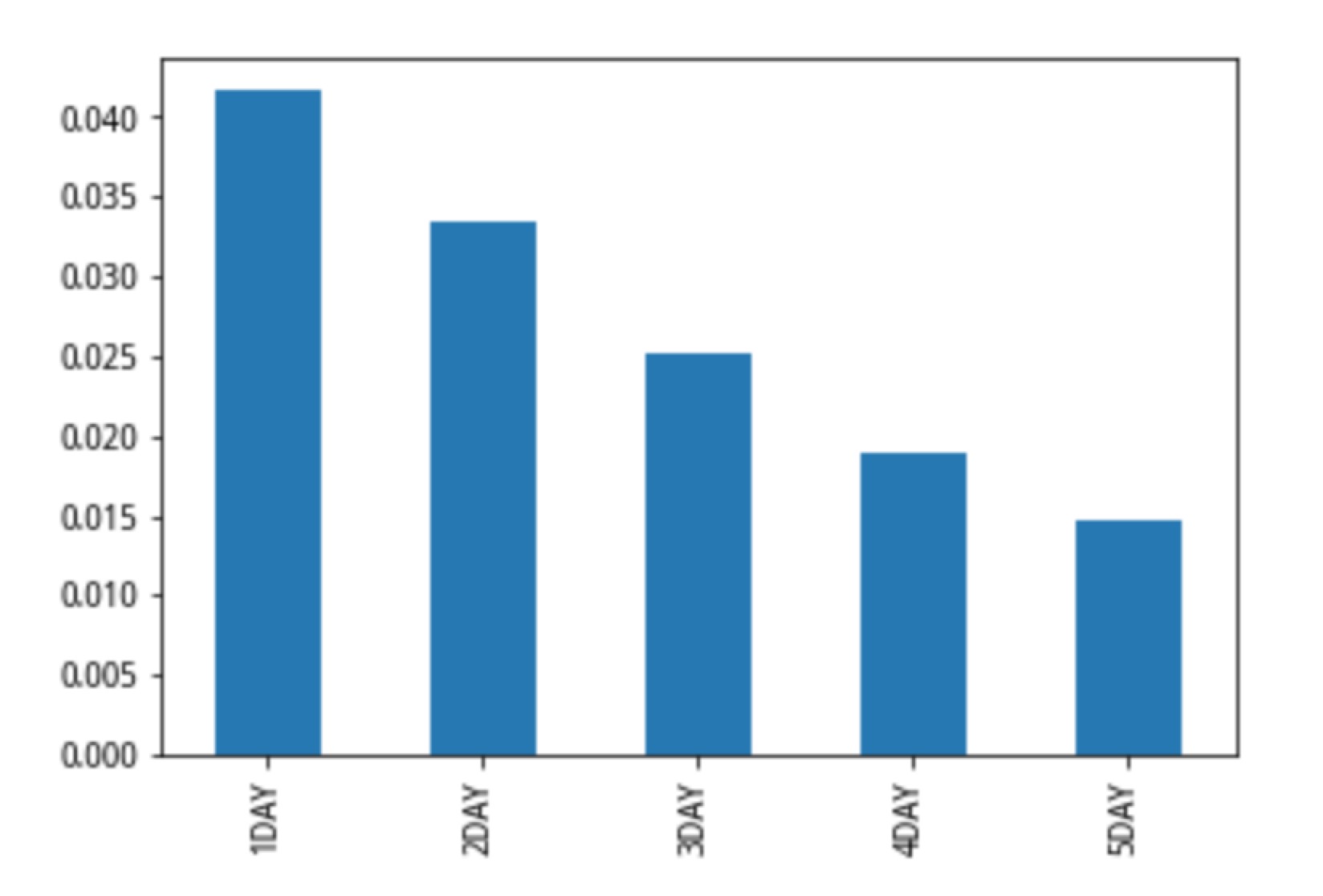
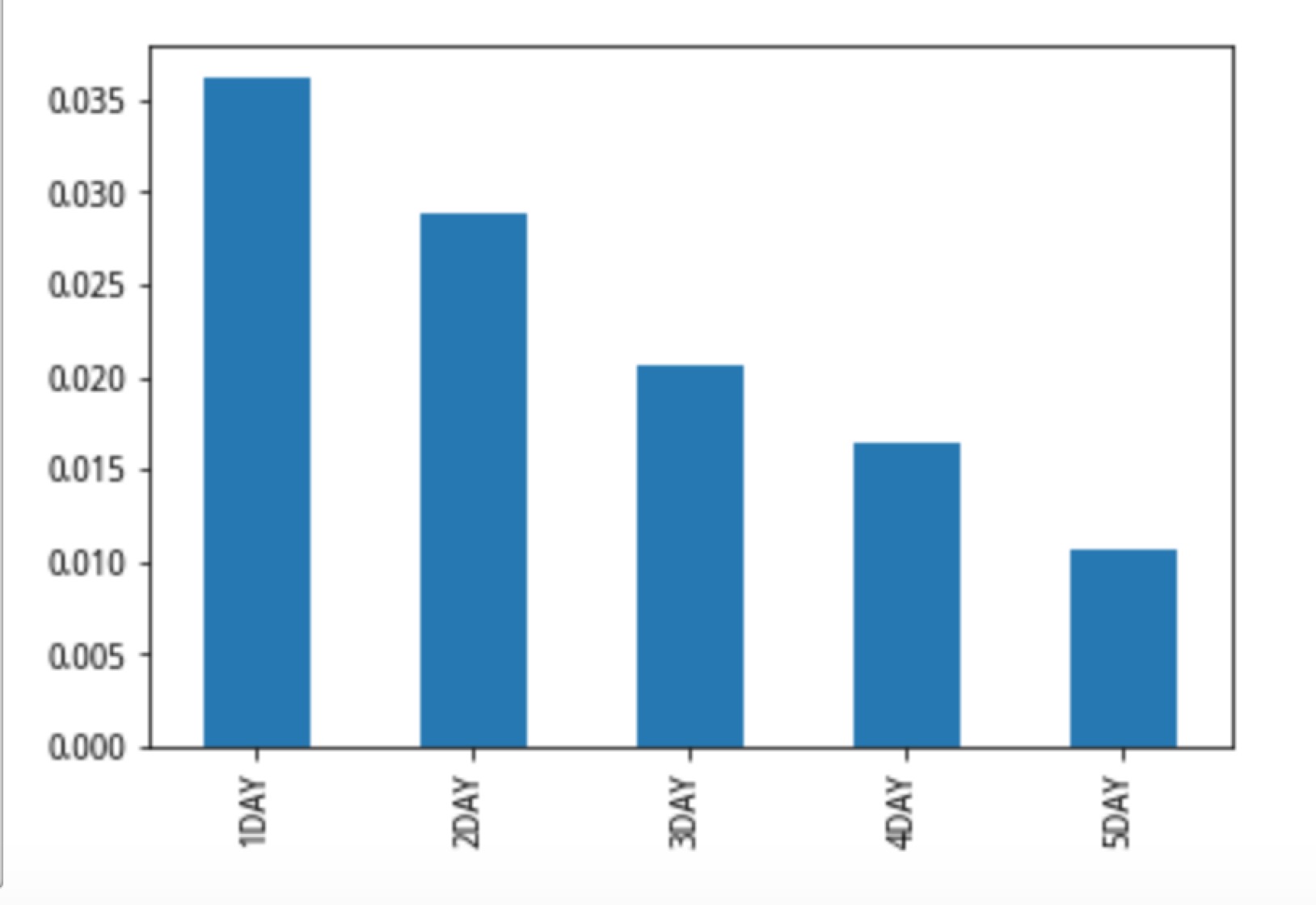
| 1DAY | 0.0417148 | 0.321501 | 0.261799 | 0.0362106 | 0.419845 | 0.378196 |
| 2DAY | 0.033475 | 0.264444 | 0.292318 | 0.0289102 | 0.348966 | 0.392869 |
| 3DAY | 0.0252228 | 0.203112 | 0.314084 | 0.0206561 | 0.250984 | 0.39676 |
| 4DAY | 0.0189274 | 0.154679 | 0.32307 | 0.0164229 | 0.20391 | 0.406601 |
| 5DAY | 0.0146902 | 0.123258 | 0.302474 | 0.010626 | 0.131947 | 0.397704 |
alpha_report['alpha_001因子']['IC'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f8ff699d3d0>

alpha_report['行业和市值中性化后因子']['IC'].plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f8ff69bec50>

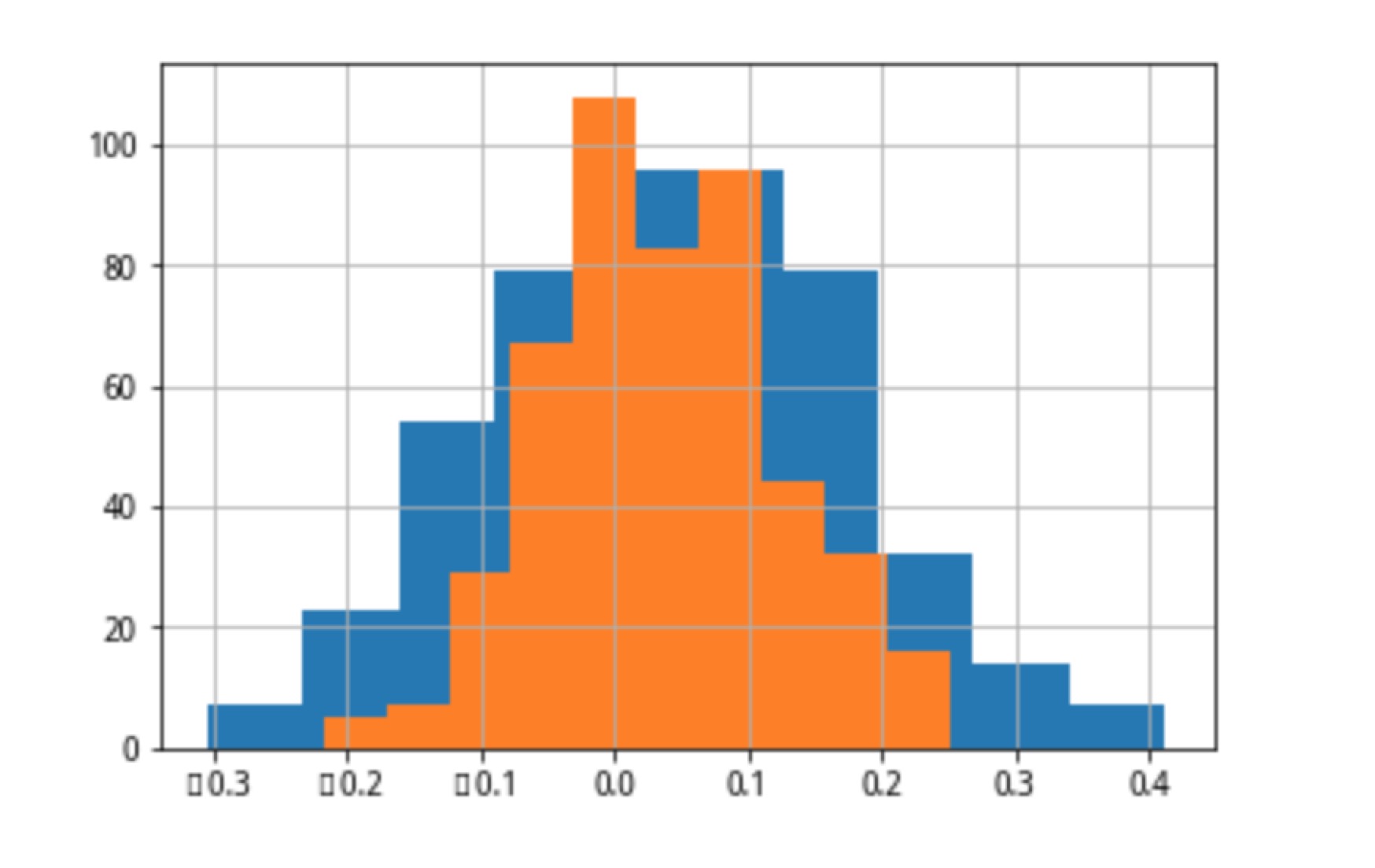
factor_ic['1day']['IC'].hist(),factor_neu_ic['1day']['IC'].hist()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f9005840350>, <matplotlib.axes._subplots.AxesSubplot at 0x7f9005840350>)

factor_ic['1day']['IC'].plot(),factor_neu_ic['1day']['IC'].plot()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f8ff68f4950>, <matplotlib.axes._subplots.AxesSubplot at 0x7f8ff68f4950>)

factor_ic['2day']['IC'].hist(),factor_neu_ic['2day']['IC'].hist()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f9005de3e90>, <matplotlib.axes._subplots.AxesSubplot at 0x7f9005de3e90>)

factor_ic['3day']['IC'].hist(),factor_neu_ic['3day']['IC'].hist()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f9001d5ed10>, <matplotlib.axes._subplots.AxesSubplot at 0x7f9001d5ed10>)

factor_ic['4day']['IC'].hist(),factor_neu_ic['4day']['IC'].hist()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f90015821d0>, <matplotlib.axes._subplots.AxesSubplot at 0x7f90015821d0>)

factor_ic['5day']['IC'].hist(),factor_neu_ic['5day']['IC'].hist()
(<matplotlib.axes._subplots.AxesSubplot at 0x7f8ffc1a2410>, <matplotlib.axes._subplots.AxesSubplot at 0x7f8ffc1a2410>)

#按因子值进行收益分组统计
#定义一个大函数
import pandas as pd
import numpy as np
#import matplotlib.pyplot as plt
#plt.style.use('ggplot')
def get_fact_ret(fact,pool_index='000300.XSHG',fdate='2017-01-01',e_date='2017-02-01'):
def get_df(pool,fdate):
q = query(
valuation.code,
valuation.circulating_market_cap,
valuation.pe_ratio,
valuation.pe_ratio/indicator.inc_net_profit_year_on_year,
valuation.pb_ratio
).filter(
valuation.code.in_(pool))
df = get_fundamentals(q, fdate)
df.columns=['code','circulating_market_cap','pe_ratio','peg','pb_ratio']
#print(df)
return df
def ret_se(sl,start_date=fdate,end_date=e_date):
#得到股票的历史价格数据
df = get_price(sl,start_date=start_date,end_date=end_date,fields=['close']).close
df = df.dropna(axis=1)
#print(df.head(3))
#相当于昨天的百分比变化
pct = df.pct_change()+1
pct.ix[0,:] = 1
#pct = pct.dropna(axis=0)
#累积相乘得到总收益的变化情况
#df1 = pct.cumprod()
#等权重平均收益结果
se1 = pct.cumsum(axis=1).ix[:,-1]/pct.shape[1]
return se1
'''
#获取因子值,进行排序
pool = get_index_stocks(pool_index)
df = get_df(pool,fdate=fdate)
df.index = df.code
'''
df_d1 = fact.loc[fdate:fdate,:].T.sort_values(fdate,ascending=0)[1:]
#print(df_d1.head(3))
#step2 分组
part = list(df_d1.index)
a = len(df_d1)//5
part1 = list(df_d1.index)[:a]
part2 = list(df_d1.index)[a:2*a]
part3 = list(df_d1.index)[2*a:-2*a]
part4 = list(df_d1.index)[-2*a:-a]
part5 = list(df_d1.index)[-a:]
#step3 计算收益
se = ret_se(part)
se1 = ret_se(part1)
se2 = ret_se(part2)
se3 = ret_se(part3)
se4 = ret_se(part4)
se5 = ret_se(part5)
return se,se1,se2,se3,se4,se5
#数据组拼接
def fact_tu(fact,l_all):
l1 = l_all[:-1]
l2 = l_all[1:]
date_list = list(zip(l1,l2))
num = 1
for i,j in date_list:
se,se1,se2,se3,se4,se5 = get_fact_ret(fact,fdate=i,e_date=j)
if num == 1:
#se_list = [ for i in se_list]
df_all_1 = pd.concat([se,se1,se2,se3,se4,se5],axis=1)
df_all_1.columns = ['benchmark','part1','part2','part3','part4','part5']
#df_all_1.ix[0,:] = 1
num = 0
#print(df_all_1)
else:
df_all_2 = pd.concat([se,se1,se2,se3,se4,se5],axis=1)
df_all_2.columns = ['benchmark','part1','part2','part3','part4','part5']
#df_all_2.ix[0,:] = 1
#将各个月份的收益拼接为大表
df_all_1 = pd.concat([df_all_1,df_all_2])
#print(df_all_1)
return df_all_1.cumprod()
#获取时间段内的月初首个交易日日期
#获取每个月的第一个交易日日期
'''
def date_list(start,end):
df_date = pd.read_csv('df_date.csv')
df_1=df_date[(df_date['dt_list']>=start) & (df_date['dt_list']<=end) ]
df_2 = df_1.drop_duplicates(['year','month'])
l_3 = [i for i in df_2.dt_list.values]
return l_3
'''
#每天进行调仓
def date_list(start,end):
l1 = get_price('000001.XSHG',start_date=start,end_date=end)
l2 = [str(i)[:10] for i in l1.index]
return l2
#输入起止日期
l_date=date_list('2017-05-10','2018-05-10')
#输入目标因子进行分组测试
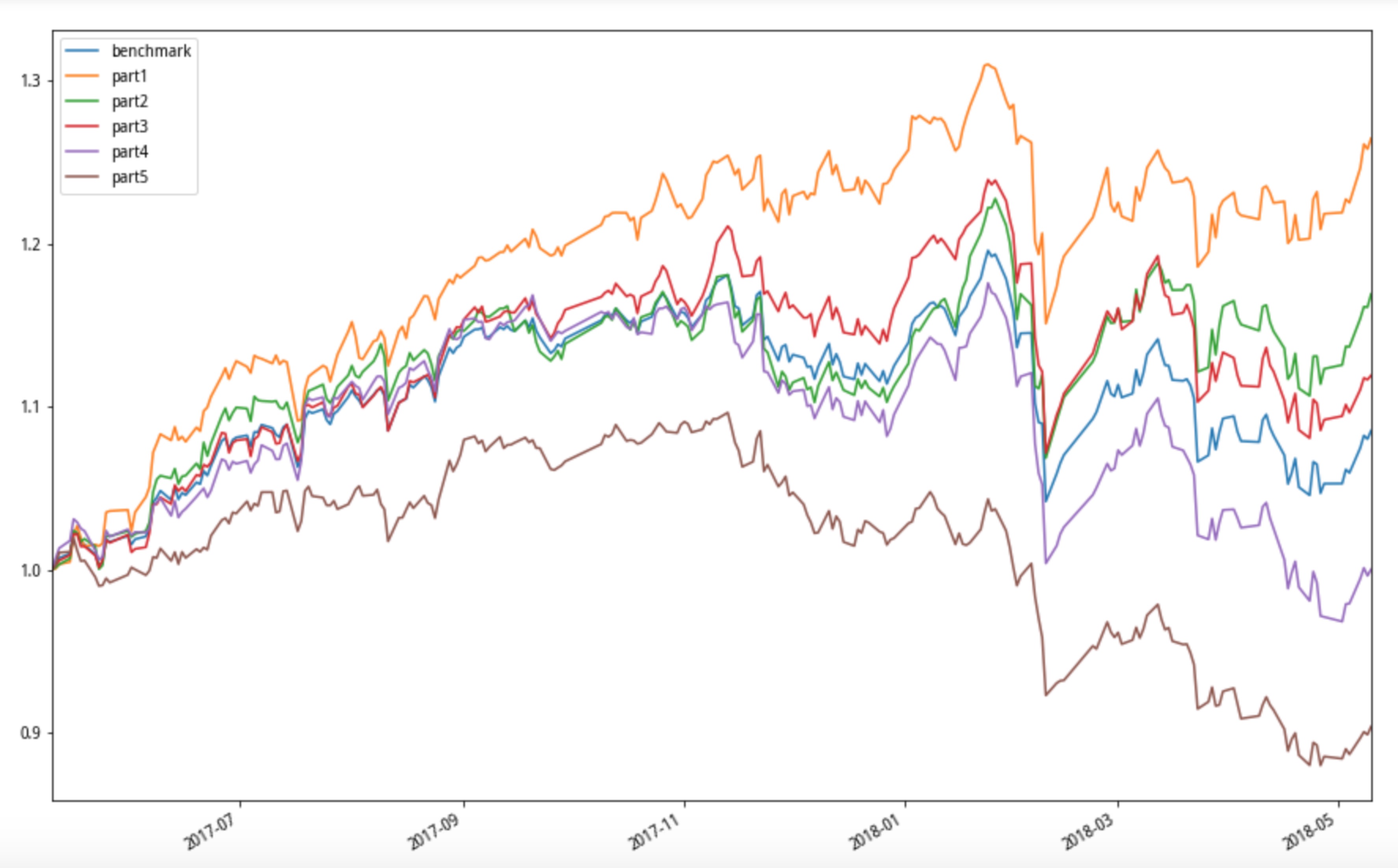
df = fact_tu(alpha_001_factor,l_date)
#对分组收益进行制图
df.plot(figsize=(15,10))
/opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:31: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated /opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:36: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
<matplotlib.axes._subplots.AxesSubplot at 0x7f8ff6517450>

#输入起止日期
l_date=date_list('2017-05-10','2018-05-10')
#输入目标因子进行分组测试
df = fact_tu(alpha_001_factor_neu,l_date)
#对分组收益进行制图
df.plot(figsize=(15,10))
/opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:31: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated /opt/conda/envs/python2new/lib/python2.7/site-packages/ipykernel_launcher.py:36: DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
<matplotlib.axes._subplots.AxesSubplot at 0x7f8ff4bb3f10>


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...