本周聚宽更新了几项功能。1.新增聚宽的多因子库。2.新增数据处理函数。给多因子模型的研究带来了许多方便之处。
之前发布了两篇:多因子回测框架(上)--生成因子 多因子回测框架(下)--检验因子
针对聚宽的更新,打算更新重写之前发的主题。新增的功能主要便捷生成因子这个模块。本主题将生成因子进行了重写。后续,将会对聚宽的发布的156个因子一一进行检验,找出有效因子,最后在回测模块形成策略。欢迎各位朋友交流指正,共同进步。
目前聚宽因子库有156个因子,手工输入因子麻烦,我在EXCEL中导入,所以第一个模块就是导入因子名而已。
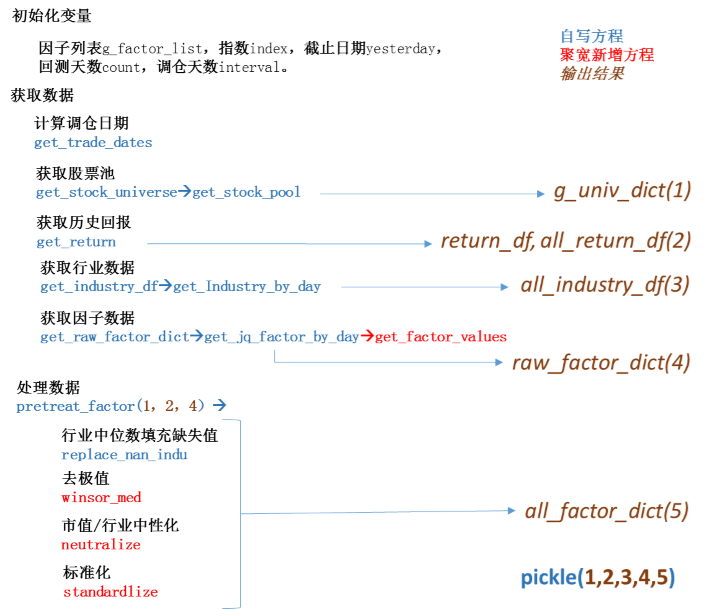
多因子流程附图一张,希望这样比文字讲解更清晰:
import xlrd # 手工输入156个因子太麻烦,所以我就在EXCEL里上传了,也可手工输入。
ExcelFile=xlrd.open_workbook('FactorTable.xlsx')
name=ExcelFile.sheet_names()
sheet=ExcelFile.sheet_by_name(name[0])
factor_quality=list(sheet.col_values(1))
factor_fundamental=list(sheet.col_values(2))[:28]
factor_mood=list(sheet.col_values(3))[:35]
factor_growth=list(sheet.col_values(4))[:8]
factor_risk=list(sheet.col_values(5))[:12]
factor_stock=list(sheet.col_values(6))[:15]
import time
import jqdata
import datetime
from multiprocessing.dummy import Pool as ThreadPool
from jqfactor import Factor,calc_factors
import pandas as pd
import statsmodels.api as sm
import scipy.stats as st
from jqfactor import get_factor_values
from jqfactor import winsorize,winsorize_med,neutralize,standardlize
import pickle
starttime=time.clock()
global g_index
global g_count
global g_factor_list
global g_univ_dict
global g_neu_factor
g_index='000300.XSHG'
g_count=500
g_factor_list=factor_quality+factor_fundamental+factor_mood+factor_growth+factor_risk+factor_stock
g_neu_factor=factor_quality+factor_fundamental+factor_growth+factor_stock
def get_trade_dates(end,count=250,interval=20):
date_list=list(jqdata.get_trade_days(end_date=end,count=count))
date_list=date_list[::-1]
date_list=list(filter(lambda x:date_list.index(x)%interval==0,date_list))
date_list=date_list[::-1]
return date_list
def get_stock_pool(date,index='all'):
df=get_all_securities(types=['stock'],date=date)
dayBefore=jqdata.get_trade_days(end_date=date,count=60)[0] #上市不足60天
df=df[df['start_date']<dayBefore] #上市不足count天的去掉
universe_pool=list(df.index)
if index=='all':
stock_pool=universe_pool
else:
index_pool=get_index_stocks(index,date=date)
stock_pool=list(set(index_pool)&set(universe_pool))
return stock_pool
def get_stock_universe(trade_date_list,index='all'):
univ_list=[]
univ_dict={}
for date in trade_date_list:
stock_pool=get_stock_pool(date,index)
univ_list.append(stock_pool)
univ_dict[date]=stock_pool
return univ_list,univ_dict
def get_return(trade_date_list,count=250): #小概率风险:一个股票曾经是指数成分股而如今已经退市
date=max(trade_date_list)
universe=get_stock_pool(date,index='all')
price=get_price(universe,end_date=date,count=count,fields=['close'])['close']
return_df=price.loc[trade_date_list].pct_change().shift(-1)
#return_df.index=dateTransform(return_df.index)
all_return_df=price.pct_change().shift(-1)
return return_df,all_return_df
def get_jq_factor_by_day(date):
factor_dict=get_factor_values(securities=g_univ_dict[date], factors=g_factor_list, start_date=date, end_date=date)
return factor_dict
def get_raw_factor_dict(trade_date_list):
pool=ThreadPool(processes=len(trade_date_list))
frame_list=pool.map(get_jq_factor_by_day,trade_date_list)
pool.close()
pool.join()
raw_factor_dict={}
count=0
for factor in g_factor_list:
y=[x[factor] for x in frame_list]
y=pd.concat(y,axis=0)
#y.index=dateTransform(y.index) ************************
raw_factor_dict[factor]=y
count=count+1
print(count,end=',')
return raw_factor_dict
def get_Industry_by_day(date):
industry_set = ['801010', '801020', '801030', '801040', '801050', '801080', '801110', '801120', '801130',
'801140', '801150', '801160', '801170', '801180', '801200', '801210', '801230', '801710',
'801720', '801730', '801740', '801750', '801760', '801770', '801780', '801790', '801880','801890']
industry_df = pd.DataFrame(index=[date],columns=g_univ_dict[date])
for industry in industry_set:
industry_stocks = get_industry_stocks(industry,date = date)
industry_stocks = list(set(industry_stocks)&set(g_univ_dict[date]))
industry_df.loc[date,industry_stocks] = industry
return industry_df
def get_industry_df(trade_date_list):
pool=ThreadPool(processes=len(trade_date_list))
frame_list=pool.map(get_Industry_by_day,trade_date_list)
pool.close()
pool.join()
all_industry_df=pd.concat(frame_list)
return all_industry_df
def replace_nan_indu(all_industry_df,factor_df,univ_dict):
fill_factor=pd.DataFrame()
for date in list(univ_dict.keys()):
univ=univ_dict[date]
factor_by_day=factor_df.loc[date,univ].to_frame('values')
industry_by_day=all_industry_df.loc[date,univ].dropna().to_frame('industry') #和后面的inner去除掉了没有行业的股票
factor_by_day=factor_by_day.merge(industry_by_day,left_index=True,right_index=True,how='inner')
mid=factor_by_day.groupby('industry').median()
factor_by_day=factor_by_day.merge(mid,left_on='industry',right_index=True,how='left')
factor_by_day.loc[pd.isnull(factor_by_day['values_x']),'values_x']=factor_by_day.loc[pd.isnull(factor_by_day['values_x']),'values_y']
fill_factor=fill_factor.append(factor_by_day['values_x'].to_frame(date).T)
return fill_factor
def pretreat_factor(factor_df,g_univ_dict,neu):
pretreat_factor_df=pd.DataFrame(index=list(factor_df.index),columns=list(factor_df.columns))
for date in list(g_univ_dict.keys()):
factor_se=factor_df.loc[date,g_univ_dict[date]].dropna()
factor_se=winsorize_med(factor_se, scale=3, inclusive=True, inf2nan=True, axis=1) # winsorize
if neu:
factor_se=neutralize(factor_se, how=['jq_l1', 'market_cap'], date=date, axis=1) # neutralize
factor_se=standardlize(factor_se, inf2nan=True, axis=0) # standardize
pretreat_factor_df.loc[date,list(factor_se.index)]=factor_se
return pretreat_factor_df
def get_all_factor_dict(raw_factor_dict,g_univ_dict,all_industry_df):
all_factor_dict={}
count=0
for key,raw_factor_df in raw_factor_dict.items():
#把nan用行业中位数代替,依然会有nan,比如说整个行业没有该项数据,或者该行业仅有此一只股票,且为nan。
factor_df=replace_nan_indu(all_industry_df,raw_factor_df,g_univ_dict)
neu=True if key in g_neu_factor else False
factor_df=pretreat_factor(factor_df,g_univ_dict,neu)
all_factor_dict[key]=factor_df
count=count+1
print(count,end=',')
return all_factor_dict
print('开始运行...')
today=datetime.date.today()
yesterday=jqdata.get_trade_days(end_date=today,count=2)[0] # 获取回测最后一天日期
print('获取时间序列')
trade_date_list=get_trade_dates(yesterday,g_count,20) # 将用于计算的时间序列
print('获取股票池')
univ_list,g_univ_dict=get_stock_universe(trade_date_list,index=g_index) # 获取股票池
print('获取历史回报')
return_df,all_return_df=get_return(trade_date_list,count=g_count) # 获得所有股票的历史回报 (all stocks)
print('获取因子,共计%d个,进度:' % len(g_factor_list))
raw_factor_dict=get_raw_factor_dict(trade_date_list)
print('\n获取行业数据')
all_industry_df=get_industry_df(trade_date_list)
print('处理数据---去极值化/中性化/标准化,共计%d个,进度:'% len(g_factor_list))
all_factor_dict=get_all_factor_dict(raw_factor_dict,g_univ_dict,all_industry_df)
print('\npickle序列化')
Package=[g_univ_dict,return_df,all_return_df,raw_factor_dict,all_factor_dict,all_industry_df]
pkl_file = open('MyPackage.pkl', 'wb')
pickle.dump(Package,pkl_file,0)
pkl_file.close()
endtime=time.clock()
runtime=endtime-starttime
print('运行完成,用时 %.2f 秒' % runtime)
/opt/conda/envs/python3new/lib/python3.6/site-packages/statsmodels/compat/pandas.py:56: FutureWarning: The pandas.core.datetools module is deprecated and will be removed in a future version. Please use the pandas.tseries module instead. from pandas.core import datetools
开始运行... 获取时间序列 获取股票池 获取历史回报 获取因子,共计156个,进度: 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156, 获取行业数据 处理数据---去极值化/中性化/标准化,共计156个,进度: 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156, pickle序列化 运行完成,用时 1633.12 秒
import pickle
pkl_file = open('MyPackage.pkl', 'rb')
load_Package = pickle.load(pkl_file)
g_univ_dict,return_df,all_return_df,raw_factor_dict,all_factor_dict,all_industry_df=load_Package

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程