程序框架说明:
与之前发布过的面向对象二八小市值是基本类似的,只是整个框架更加完善更加灵活了。
重点类说明:
1. Rule(object)
所有规则的基类。
该框架以事件触发式设计,包含聚宽策略的事件
Initialize,handle_data,before_trading_start.....等等。即每次聚宽事件都会调用所有规则的相关事件,除了handle_data,会根据策略流程可能中断执行,不会所有都执行。
除此之外,新增自定义的一些事件
on_sell_stock ,on_buy_stock ,before_clear_position ,on_clear_position
为卖股,买股,清仓前,清仓后触发的事件。
假如有其它事件要求,可自行在Rule类添加。2. Group_Rules(Rule)
为包含一系列规则组合的规则,通该类或扩展该类,实现树形策略执行流程。3. Global_variable(object)
自定义所有规则共用的全局变量,用于规则通用数据存储。一个策略对应一个 Global_variable.
包含较为通用的卖股、买股、清仓函数。4. Pick_stocks2(Group_rules) 选股规则组合器。此类通过一系列Filter_query(query选股),Filter_stock_list(list 过滤选股)的子类组合选出股票池5. Pick_financial_data(Filter_query)
根据聚宽财务数据的多因子选股器。6. SortRules(Group_rules,Filter_stock_list)
多因子权重排序规则组合器。多因子权重排序算法实现类。(注,此处看似为多重继承,实际上Filter_stock_list只是定义了一个函数声明,可以理解为继承自 一个类 一个接口,故不必去看多重继承的一些坑)
类继承结构(部分):
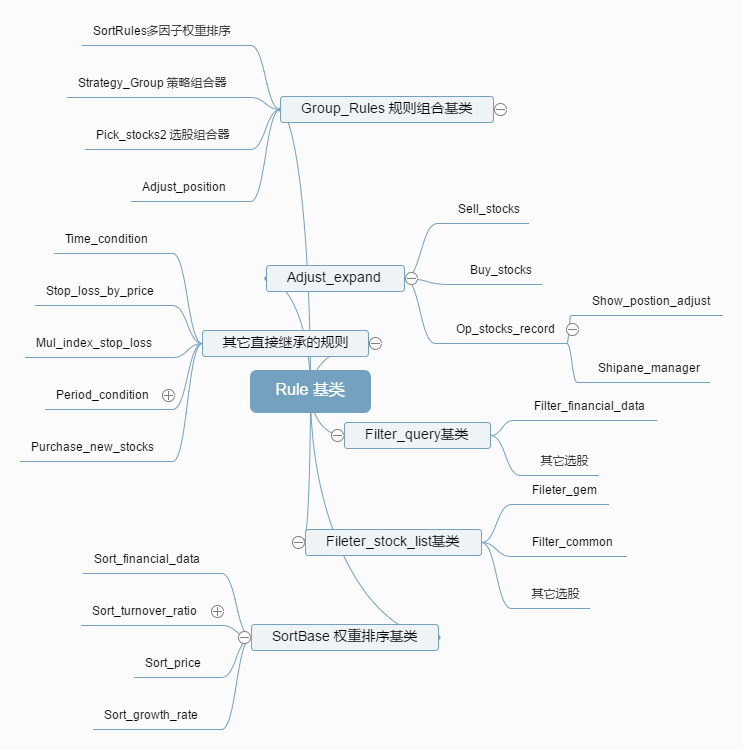
策略流程查看日志生成的策略结构就成行了:
多因子小市值策略
1.预先处理的辅助规则
1.1. 设置系统参数:[使用真实价格交易] [忽略order 的 log] [设置基准]1.2. 根据时间设置不同的交易费率
1.3. 持仓信息打印
1.4. 策略绩效统计
2.调仓执行条件的判断规则组合
2.1. 调仓时间控制器: [调仓时间: ['14:50'] ]
2.2. 大盘高低价比例止损器:[指数: 000001.XSHG] [参数: 160日内最高最低价: 2.2倍] [当前状态: False]2.3. 多指数20日涨幅损器[指数:['000016.XSHG', '399333.XSHE']] [涨幅:0.50%]2.4. 调仓日计数器:[调仓频率: 3日] [调仓日计数 0]3.选股
3.1. 多因子选股:-[ 0 < valuation.circulating_market_cap < 100 ]-[ 0 < valuation.pe_ratio < 200 ]-[ 0 < indicator.eps ]-[排序:valuation.circulating_market_cap 从小到大]-[限制选股数:200]3.2. 过滤创业板股票
3.3. 一般性股票过滤器:['st', 'high_limit', 'low_limit', 'pause']3.4.多因子权重排序器
3.4.1. [权重: 100 ] [排序: 从小到大 ] 流通市值排序
3.4.2. [权重: 20 ] [排序: 从小到大 ] 按当 PriceType.now 价格排序
3.4.3. [权重: 10 ] [排序: 从小到大 ] 按 20 日涨幅排序
3.4.4. [权重: 10 ] [排序: 从小到大 ] 按 60 日涨幅排序
3.4.5. [权重: 10 ] [排序: 从小到大 ] 按换手率排序
3.5. 获取最终待购买股票数:[ 3 ]4.调仓执行规则组合
4.1. 股票调仓卖出规则:卖出不在buy_stocks的股票
4.2. 股票调仓买入规则:现金平分式买入股票达目标股票数
4.3. 显示调仓时买卖的股票
关于多因子选股的说明
其实没啥好说明的,无非是根据各种条件取并集而已。
多因子选股有待扩展的是按市场分布比例取集,比如,取流通市值最小的20%的股票,以后有空再做吧,果仁有这个功能。
关于多因子权重排序说明
对于每个因子,都对股票池进行独立的排序,然后以该因子排名*因子权重加到总权重。最后再对总权重进行排序。
关于策略实盘的说明
Shipane_manager 规则为把聚宽持仓同步到实盘同步的规则
使用该规则需下载 trader_sync.py和shipane_sdk.py到研究里。
下载地址:https://pan.baidu.com/s/1skZHEVV
Purchase_new_stocks为自动打新规则,需要 shipane_sdk.py
关于面向对象策略更新代码失败的各种坑的总结:
大部分都是由序列化和反序列化引起的。
不要把一个对象函数赋与另一个对象变量。如 obj1.func = obj2.func
更新代码前,一些废弃的类、函数请不要删除或改名。要删除或改名请在更新代码成功后。不然会反序列化失败。
新增一个类的成员变量,在使用前需要检测并赋初值,因为原策略里已创建的对象,可能没有被重新创建,然后并不存在这个新增的成员变量,后续再使用时就会报错,尤其是在把各个规则分拆放到研究里时,这个问题相当严重。在本策略中,用以下相互配合达到避免这个错误。
a) 在update_params函数里进行成员变量初始化。
b) Rule自带保存了传入参数的dict self._params,规则使用参数时,请直接用self._params.get(‘参数’,默认值)的方式使用参数,参数不再每个都保存为类成员,自然就不存在因为新增类成员导致策略错误的问题。
c) 假如是在修改研究文件中的类,而该类在策略里有使用,新增成员变量时,在使用前,请Try,异常则初始化。
同一个Group_Rules规则组合下的规则,假如是同一个规则类使用了两次,则一定要设置对象名。即策略配置里的第二个字符串参数。否则会导致策略混乱出现乱七八糟的错误。本策略示例里没有这种情况。
以前我发布的面向对象,代码更新还是经常失败的。现在好多了,掌握了要点,基本没有再出现过更新失败的问题。
最后声明:
该策略只是作为我这个程序框架下的多因子选股票池,多因子权重排序的示例,希望起到抛砖引玉的作用,而对策略结果、收益、风险不负任何责任,也不作任何解释。。。因为我也没研究,随便写的几个因子玩玩的。
该策略框架为较通用的框架,我自己实盘策略也是基于这个写的,只是规则更多,所以有些基类里出现一些没使用过的代码,不要介意,可能我别的地方用了,无视了就好。








