前段时间偶然在微博上得到这张图片,这是一种通过百分比堆积的形式,获得不同分析目标占比形式的可视化效果,图片来自 Visual Capitalist 制图,华尔街见闻汉化。
根据华尔街见闻分析,图片描述了美国股市从 19 世纪初到现在的行业分布情况。
最早金融股占据较大份额,因为其他行业上市公司还非常稀少,之后以铁路为代表的交通股最初表现最为抢眼,在 1868-1873 年美国内战期间,美国铁路总长度增加了 3.3 万英里。随着运输业的蓬勃发展,铁路相关股票吸引了大量资金流入,该板块市值一度达到美国股市总市值的 60%。
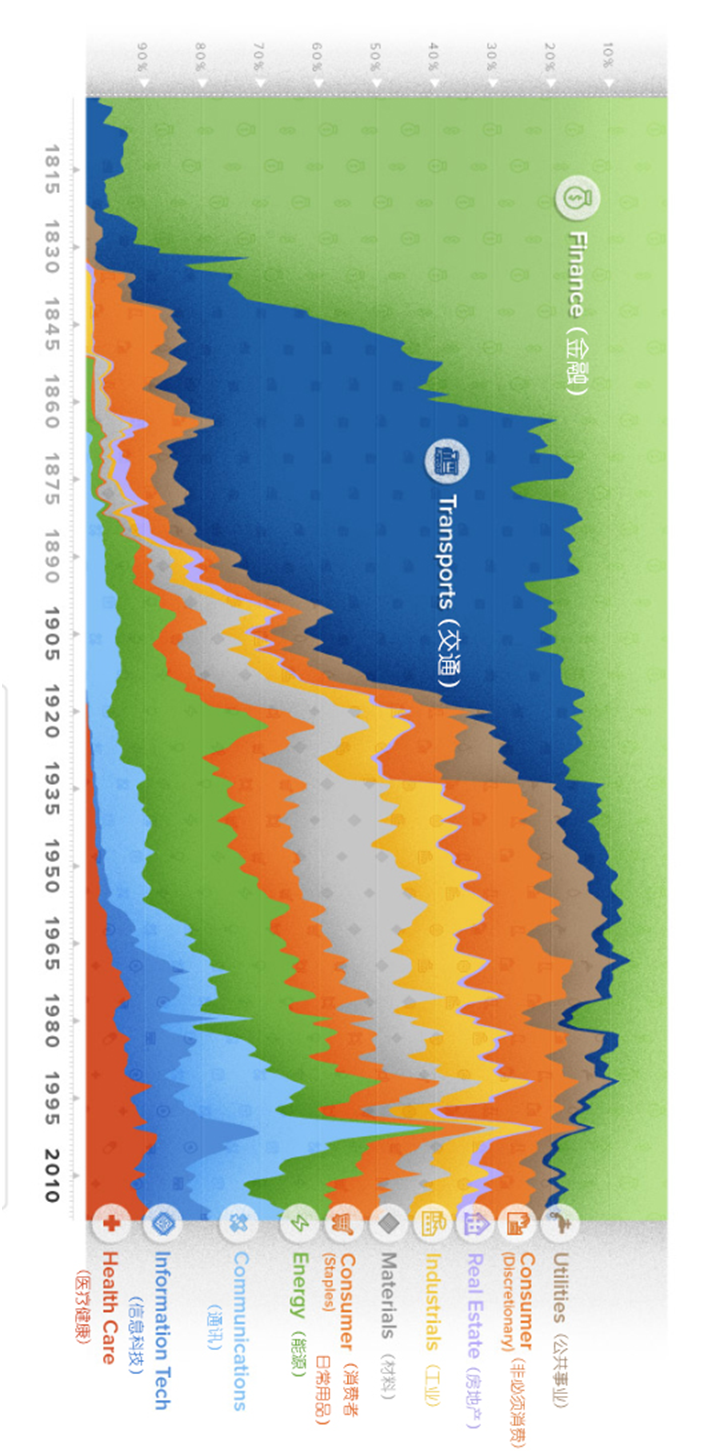
20世纪,股指成分变得更加丰富,包括公用事业、钢铁和能源等板块也加入队列。但是在1930年的大萧条时代,政府大手笔投资了公共事业,在拉动经济的同时,增加了该版块的市值,其他版块也应声回落。
到了2018年,市场权重也发生了重要的变化:铁路业未能经得起时间的检验,份额已大幅萎缩至2%;信息技术和医疗保健类股异军突起,成为新加入的新兴板块,且在美股市场中占据相对较高的市场份额。
可惜A股远没有这么长时间的可用数据,但是考虑到国内经济结构变化迅猛,通过聚宽平台我们依然可以拿到2005年以来的数据,一定程度上获得和Visual Capitalist图片类似的效果。
A股市场格局同样有重大变化
考虑到申万28个一级行业数量较大,并且历史上发生过变更,我们选择聚宽行业分类,首先分析了各行业市值market_cap情况,发现金融行业占据全市场市值一度达到2017年大牛市的40%,随后始终处于下降通道。信息技术、可选消费,是这几年得到市值增长的板块。
然后我们分别分析了total_operating_revenue(总营业收入)total_liability(总负债)。发现工业企业、可选消费,的营业收入增长较为稳健,金融行业、能源行业有一定衰弱。这或许和国家工业布局的完整性,工业成为世界工厂的行业地位,和消费升级有一定关系。
信息技术板块虽然在第一张图片中有较大的市值占比提升,但是到了营业收入图可以看出,它的营业收入虽然增长,但不及市值增长,说明该板块整体估值较高。房地产板块的销售数据也有些出乎我们意料,虽然我们知道大部分家庭的消费都用于购房,但是它的营业收入并没有占据很大比率。
总负债情况是非常极端的,这是由于金融行业的计算方法略有不同,且金融行业是依靠高杠杆来负债放贷,支持实体经济。根本原因还是该行业的业务性质决定的。金融企业的负债率较高,一般在90%左右。金融企业的自有资金要求不得低于一定比例,通常为8%。其中2016年,我国GDP为74.4万亿,这意味着我国的总负债率为342.7%,除去金融的实体总负债率刚刚超过250%。
除了财务性质的分析,我们还挖掘了各行业的上市公司数量,获得如下发现:
工业领域上市公司家数最多,其次是信息技术(注意图例是反的),且在近几年可选消费、工业、医疗保健板块的上市公司数量大幅度增加,压制了金融领域的上市公司数量比率,虽然2018年我们看到几个城商行相继上市,但是依然无法和每周众多中小企业上市的速度相提并论。所以总体上看,我们的股票市场的确是在服务实体经济。信息技术行业虽有持续增长,但是没有出现上市公司家数短期大幅度提升。房地产行业也出现了显著比例压缩,值得关注。
最终一个分析维度是上图的市场关注热度,我们直接使用了成交量来作为表达变量。此时和第一张图市值占比对比分析可以看出,金融行业没有因为坐拥较大的市值而拥有同样的成交量,反而它的成交量比重较小,工业和材料领域因为上市公司数量众多,自然分走了较大的成交量。这一情况和我们熟知的A股市场特征“小市值股票活跃,大市值股票波动率低”是吻合地,这是阶段性的市场特征。
本次分析暂时告一段落,受限数据长度不足和行业分类的科学性有待提升,我们得到了一些模糊的结论,但是要做出更加严谨的分析结论,并指导实战,还有差距。
所有代码,均在研究平台可以复现。
from jqdata import *
import datetime
import numpy as np
import pandas as pd
from jqdata import finance
import talib
#备注:成交量使用get_price,而财务数据获取使用的get_fundamentals函数,写成两段了
#1、取到需要取数据的具体日期
date_list = [datetime.datetime.strptime(str(i) + '-' + str(j) + '-01','%Y-%m-%d').date() for i in range(2005,2019) for j in range(1,13)]
#2、使用的财务数据种类:市值,营业额,负债,净利润,以及对应数据所属数据库中表名
factor_list = [('valuation','market_cap'),('income','total_operating_revenue'),('balance','total_liability')]
#3、取到行业成分股
def get_index_stock(industry_level,current_date,wanted):
all_industry_code = get_industries(industry_level)
ind_name = list(all_industry_code['name'])
ind_codes = list(all_industry_code.index)
ind_stock_dict = {}
for ind_code in ind_codes:
ind_sample = ind_name[ind_codes.index(ind_code)]
ind_stock_dict[ind_sample] = get_industry_stocks(ind_code, date=current_date)
if wanted == 'Name':
return ind_name
else:
return ind_stock_dict
#取到想要的数据
def get_data(factor_tuple,stock_list,date):
encoding_str = str(factor_tuple[0]) + '.' + str(factor_tuple[1])
q = query(
eval(encoding_str)
).filter(
eval(factor_tuple[0]).code.in_(stock_list))
factor_data = get_fundamentals(q,date)
return factor_data.fillna(0).sum()
#4、检查2005年到现在行业分类标准是否有品类上的变更
def repeat_check(industry_level):
ind_name = get_index_stock(industry_level,date_list[0],'Name')
for date in date_list:
new = get_index_stock(industry_level,date,'Name')
if list(ind_name) != list(new):
print(industry_level + '有变更' + str(date) )
break
else:
pass
if industry_level == 'jq_l1':
print('聚宽1级分类无变更')
repeat_check('jq_l1')
聚宽1级分类无变更
#5、最终的画图函数
def plot_figure(industry_level):
for factor in factor_list:
data_dict = {}
for date in date_list:
current_stock_dict = get_index_stock(industry_level,date,'list')
data_list = {}
cal_percent_list = []
for ind_key in current_stock_dict.keys():
current_data = get_data(factor,current_stock_dict[ind_key],date)
data_list[ind_key] = float(current_data)
cal_percent_list.append(float(current_data))
sum_factor = sum(cal_percent_list)
for key in data_list.keys():
data_list[key] = data_list[key] / sum_factor
data_dict[date] = data_list
data_df = pd.DataFrame(data_dict).T
data_df.plot(kind = 'area',title = factor[1],figsize = (12,6))
# 6、成交量画图
vol_df = pd.DataFrame()
current_stock_dict = get_index_stock('jq_l1',date_list[-1],'list')
for ind_key in current_stock_dict.keys():
current_data = get_price(current_stock_dict[ind_key], start_date=date_list[0], end_date=date_list[-1], frequency='daily', fields=['volume'])['volume'].fillna(0).sum(axis = 1)
vol_df[ind_key] = current_data
vol_sum = vol_df.sum(axis = 1)
vol_sum
col_list = vol_df.columns
for item in col_list:
vol_df[item] = vol_df[item] / vol_sum
vol_df.plot(kind = 'area',figsize = (12,6),title = '成交量百分比堆积图')
/opt/conda/lib/python3.6/site-packages/jqresearch/api.py:87: FutureWarning: Panel is deprecated and will be removed in a future version. The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/. Pandas provides a `.to_xarray()` method to help automate this conversion. pre_factor_ref_date=_get_today())
<matplotlib.axes._subplots.AxesSubplot at 0x7f161040ffd0>

# 7、绘制财务数据图
plot_figure('jq_l1')
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:15: RuntimeWarning: invalid value encountered in double_scalars from ipykernel import kernelapp as app



# 8、上市公司数量数据图
stock_num_dict = {}
for date in date_list:
stock_num_dict[date] = {}
stock_list = get_index_stock('jq_l1',date,'list')
for idne_name in list(stock_list.keys()):
stock_num_dict[date][idne_name] = len(stock_list[idne_name])
stock_num_df = pd.DataFrame(stock_num_dict)
stock_num_df = stock_num_df.T
col_sum = stock_num_df.sum(axis = 1)
for col in stock_num_df.columns:
stock_num_df[col] = stock_num_df[col] / col_sum
stock_num_df.plot(kind = 'area',figsize = (12,6),title = '上市公司数量堆积')
<matplotlib.axes._subplots.AxesSubplot at 0x7f1620979278>


本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







