在优化版的基础上,我花了半天的时间修改了下代码,让RSRS可以对sercuritylist建模,以自己的模型去跑轮动进行分析,而不是像论坛里其他RSRS策略一样,在HS300的建模框架下去跑中小市值的个股,我觉得这是不合理的。
附上其他2篇研究,作为基础:
RSRS模型深入研究1-附上优化版代码:
https://www.joinquant.com/view/community/detail/28a3816a32b326b8f1c8d35a54457a8b?type=1
RSRS模型深入研究2-对右偏态样本处理的质疑与分析 :
https://www.joinquant.com/view/community/detail/dec56fcab7df6a53b47534d7e9445403?type=1
实际sercuritylist我选择了HS300和创业板指这2个模型,选择创业板指主要是其相对于HS300轮动性更强,波动率也更大,样本右偏态分布也比HS300差。
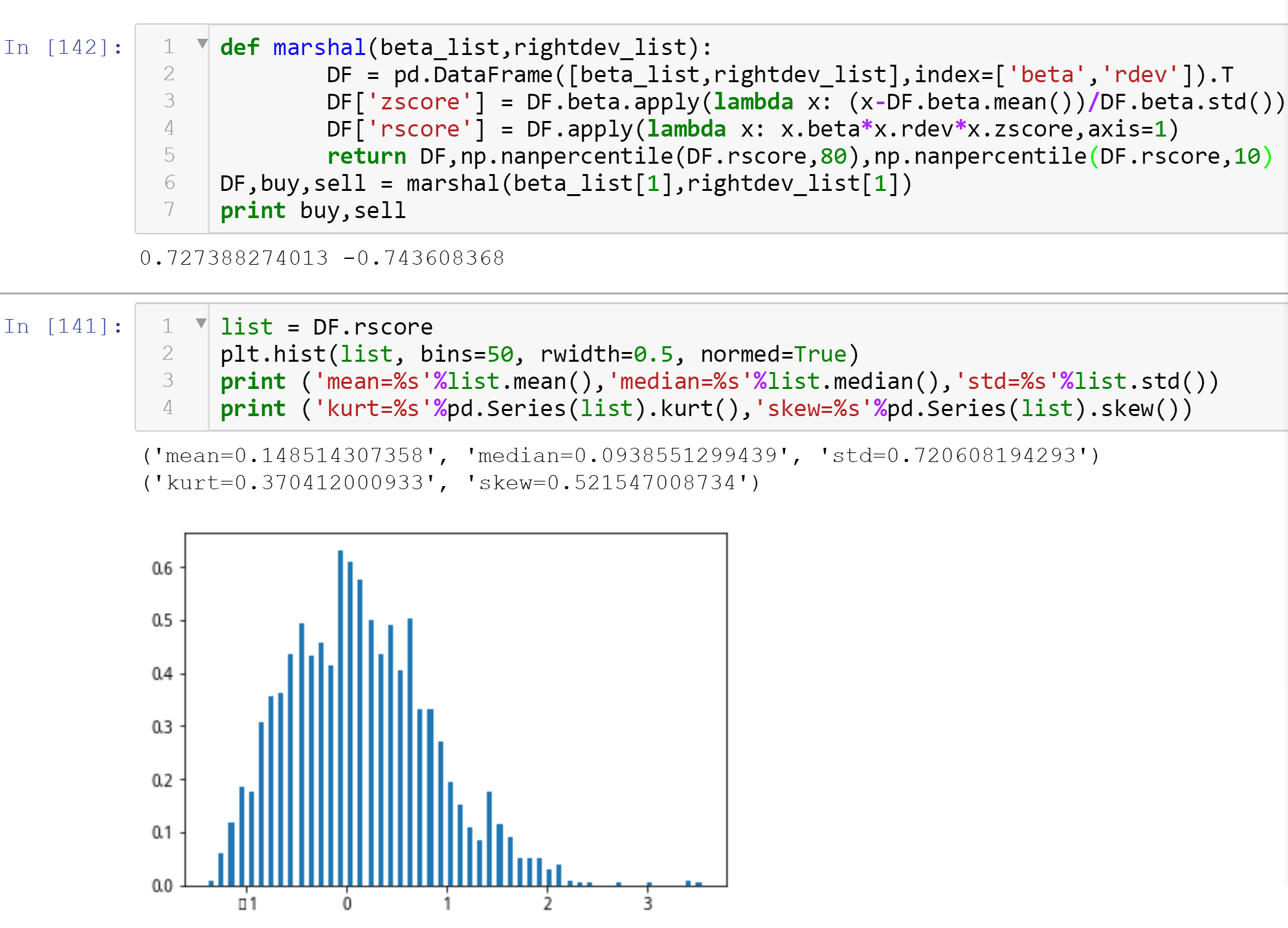
根据上图可以看到,修偏后的创业板指的样本相比HS300的右偏态较差,skew只有0.52左右,在选择同样置信区间的情况下,创业板指的回测也更大,因为更正态的样本,众数离平均数和中位数更接近,统计意义上,更难处理白噪或者说该样本的震荡期。
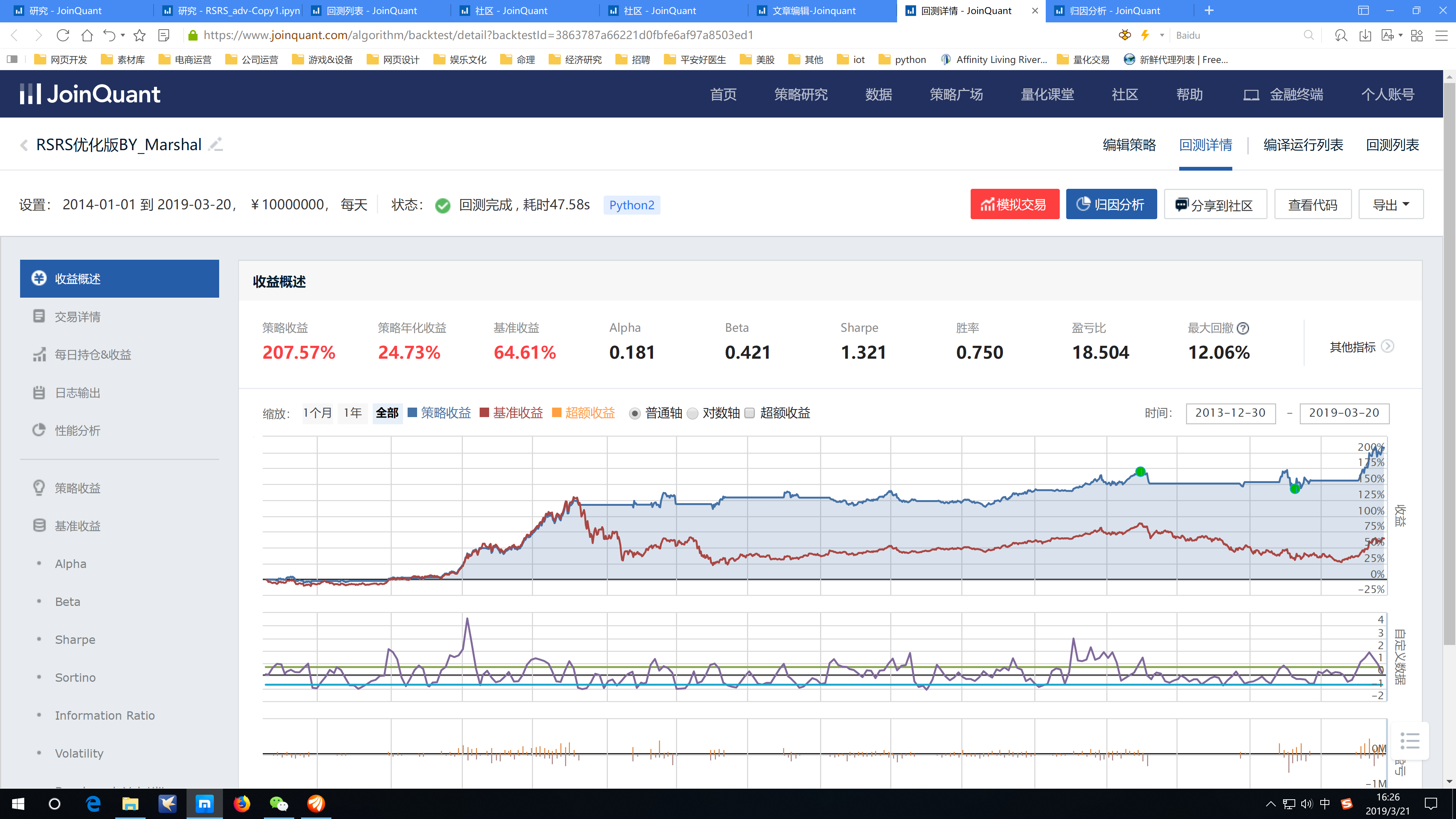
附上同期HS300的RSRS建模后的回测效果。
可以看到,二八轮动中,创业板指在上升过程中虽然某些时刻可以好于HS300,但是由于其样本较HS300的偏态更差,导致很难过滤白噪信号,回撤也更大些,总体反而比HS300单样本建模跑的更差。
综上,经过3期的研究和探索,相信大家对RSRS的择时模型以及数据处理有个更清晰的认识。
在未来的数据样本处理上,我们可以通过纯数学的手段使得样本右偏态化,这样就算是猪,在风口上也能飞起来!








