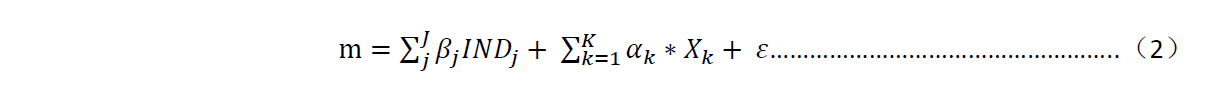传统的多因子策略的研究更多的是用上涨或下跌的分类预测来实现。xfy先生写了一篇用市值回归思路的多因子策略,对我启发颇大,本文在xfy先生的基础上做进一步的研究。先在此表示感谢!
本文试图采用统一的视角解释和测试各种不同的基于机器学习选股的量化投资策略,并分析它们应用于多因子模型的异同。具体而言,本文主要关注并讨论如下几个问题:
1.基于机器学习选股的量化投资策略的有效性的验证。本文所采用的策略是否能够有效地获得更高的收益率和更低的风险?
2.基于机器学习选股算法的选择问题。相比传统的线性回归,在其他条件不变的情况下,机器学习的算法能否对量化投资策略有进一步的提升?
3.因子组合和算法,持仓数和算法,市场风格和算法的匹配的问题。机器学习的算法在不同的因子组合下,或者是不同持仓数下,或者是不同的市场环境下的表现有什么差异?
4.算法调优问题。改变机器学习的算法的参数或者训练集的长度是否可以改善模型,提升投资的表现?
本文基于机器学习的算法,对中证全指成分股进行选股及量化投资。样本的回测区间选取的是2014年1月1日到2018年7月31日。
首先对于基于机器学习选股的量化策略进行了有效性的验证和比较;
其次,对于不同因子组合的表现进行了比较;
然后,对于不同持仓数的表现进行了比较,得出不同策略下的最佳持仓数;
然后,根据不同市场切换风格,对策略进行比较,得出不同市场风格时的最佳策略;
最后,对策略进行参数调优和训练集长度的调节比较,对不同策略下的最佳参数和最佳训练集长度进行实证分析。
本文通过JoinQuant平台 获取中证全指及沪深300、中证500指数样本股在2014年1月1日至2018年7月31日期间每个交易日的截面数据作为测试集样本。另外,当天停牌或者开盘涨跌停的样本股作为对象外。
本文经过对因子的相关性等方面的测试和综合考虑,分别从估值,资本结构,盈利,成长四个方面进行考虑,选取如表1所示的因子作为候选因子。
从xfy先生的研究中,我们能够看出,某个时间点上,股票的市值可以被多个因素解释。根据多因子模型的基本思路,我们在截面上将市值作为样本标签,按照上述表1所示因子,计算其因子暴露度,作为样本的原始特征。对表1的多个因子进行回归,得到的残差值越小,说明股票市值向下偏离其理论值越严重,也就意味着该股票未来上涨的可能性越大,即收益率越高。构建模型如下所示:
本文通过JoinQuant平台获取所需的市值及因子数据。在进行模型构建与分析之前,为了提高数据的质量,需要对数据进行预处理。数据预处理有多种方法,包括数据清理,数据集成,数据变换,数据归约等。本文对数据主要进行以下预处理。
对于初始数据存在缺失的情况,本文统一用0来填充。
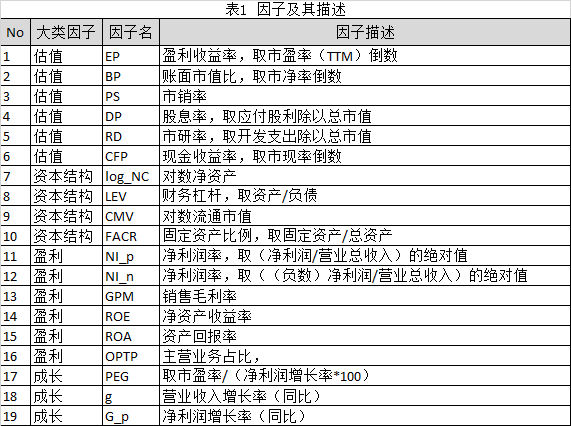
因为过大或过小的因子数据可能会影响到分析结果,尤其是在做回归的时候,我们需要对因子的离群值进行处理。处理方法是调整因子值中的离群值至上下限(Winsorzation处理),其中上下限由离群值判断的标准给出,从而减小离群值的影响力。离群值的判断标准有三种,分别为MAD、3σ、百分位法。本文统一采用MAD(n=5)标准对因子进行离群值处理。离群值处理前后的比较,以因子g在2018年7月11日截面数据为例,参考图1所示。
由于不同因子所描述的对象单位不一样,那么可能导致不同因子数值差异很大,举个例子,如果我们用不经过标准化的市值作为因子暴露,如果公司A的市值是B的市值的100倍,那是否代表我们能说市值因子的收益率对A的收益率的影响是对B的收益率的影响的100倍呢?显然是不能的。所以,在利用因子进行策略建立之前,需要先对因子进行标准化处理。标准化的方法有很多,本文采用z-score的方法,参考图2所示,将因子值的均值调整为0,标准差调整为1。处理后的数据从有量纲转化为无量纲,从而使得数据更加集中,或者使得不同的指标能够进行比较和回归。
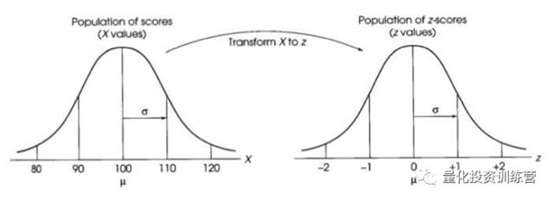
以因子log_NC在2018年7月11日截面数据为例,标准化处理的前后比较参考图3所示。
在使用因子进行选股时,有时会因为其它因子的影响,而导致选出来的股票具有一些我们不希望看到的偏向。另一方面,朝阳行业和夕阳行业的市盈率在大致上也有一定的特点,也就是说行业对估值因子也有影响,那么我们得到的结果是具有一些多余偏好的。为了解决这一由于不同行业和市值大小导致的误差问题,让我们在用某一因子时能剔除其他因素的影响,使得选出的股票更加分散,我们需要对其进行中性化处理。
对于因子来说,市场风险(例如牛市和熊市)和行业风险(同一行业的公司受的影响类似)是中性化主要考虑的因素,对这两者的处理方式有两种:
1,将市场因子和行业因子同时纳入模型。
2,仅纳入行业因子,而将市场因子包含在行业因子中。
第一种方式和第二种方式的区别在于,第一种方式行业因子收益率计算出来的是行业相对于市场的超额收益率,而第二种方式计算出来的收益率是行业绝对收益率。对于验证风格因子有效性而言,这两种方式是没有区别的;对于回归而言,只是前者是带截距项的回归,而后者是穿越原点的回归。本文采取第二种方式,模型调整如下所示:
式中:
IND——行业虚拟变量矩阵。若该公司属于该行业,则将该行业的虚拟变量的值设为1,否则设为0。本文不对公司所属行业进行比例拆分,即公司只能属于一个特定的行业。本文的行业划分采用JoinQuant行业1级分类。https://www.joinquant.com/help/api/help?name=plateData#聚宽行业
本文采用历史回测的方式进行实证分析。回测参数设置的不同所得到的测试结果差异很大,客观设置回测参数关系到策略交易效果的真伪和对策略的最终取舍。本文的回测参数设置及全局设定参考如下。
(一)投资金额
假定投资金额为:100万。
(二)回测区间
未指定的情况下,默认回测区间为:2014年1月1日—2018年7月31日
(三)佣金及印花税
为了使回测结果更加接近真实的交易成本,在实证分析中,设置佣金及印花税的比例。
近十年印花税的主要两次变化包括:
1)2008年4月24号起,由3‰调整为1‰。
2)2008年9月19日起,由双边征收改为单边征收,税率保持1‰。由出让方按1‰的税率缴纳股票交易印花税,受让方不再征收。
佣金方面,由于券商及客户本身的不同,佣金比率各自不同。佣金及印花税的设定参考表2设置。
(四)滑点
所谓滑点,是指下单价与实际成交价之间的差价。由于滑点对最终结果的影响较小,本文滑点设定为0。
(五)仓位
根据每次买入时所剩资金,按照买入股票数平均资金,全仓买入。
(六)可行股票池
如无特别指定的情况,本文的可行股票池默认为中证全指。实际情况中,当天停牌的股票是无法进行买卖操作的,所以在整体回测前,将当日停牌的股票剔除。另外,本文在跌停状态下策略不进行买入,涨停状态下策略不进行卖出。
(七)比较基准
对应可行股票池,选取中证全指的每日价格作为判断策略好坏和一系列风险值计算的基准。
(八)测试集提取
交易日当天的因子特征值为样本的原始特征,当天的市值对数为样本的标签。
(九)训练集(包括验证集)*
以T日为例,每21个交易日为间隔,在没有特别指定的情况下,默认使用T-21至T-63的特征和标签作为训练集(包含验证集),且使用3折交叉验证的方法。
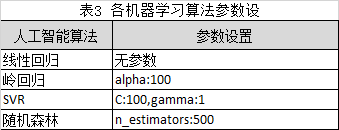
(十)机器学习算法参数设置
在没有特定指定的情况下,各机器学习算法的参数设置参考表3所示,使用固定参数的方式。
(十一)其他
1)回测使用市价单下单,并假设不存在买不到或卖不出的现象。
2)财报和市值数据使用的回测日的前一天数据,从而避免未来函数。
在对策略进行深入的研究之前,首先对策略进行有效性的研究及实证,以保证之后的研究在正确的前提下进行。对策略的有效性实证方法如下:
1.根据线性回归算法,对模型中的因子特征值对市值(取对数)标签做线性回归,取实际值与预测值之差作为新的因子特征值。
2.按照差值从小到大的顺序对股票进行排序。
3.将股票等分为10组,分别按照每10天和每30天进行一次调仓。
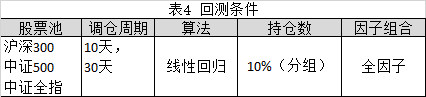
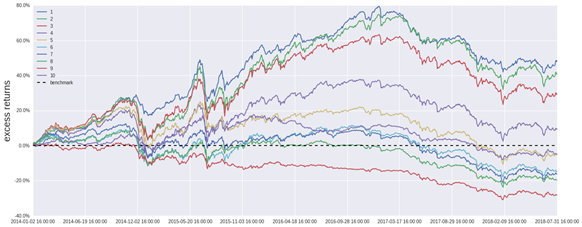
根据上述方法,回测条件参考表4所示,进行分组回测。分组回测的结果分别参考表5、图4(中证全指,调仓周期:10天)、图5(中证全指,调仓周期:10天)所示。
由表5、图4、图5可知:
1.根据假定的模型,沪深300不能得到明显的单调的策略收益率,而中证全指能得到相对明显的单调的策略收益率。中证500则居于沪深300和中证全指中间。说明该策略不适合用于投资沪深300,但可以用于投资中证全指或者中证500。
2.中证全指不仅能得到相对明显的单调的策略收益率,还可以获得相对单调的夏普比率和信息比率。
3.中证全指不能获得单调的最大回测,说明该模型在风险控制上并没有有效的机制。
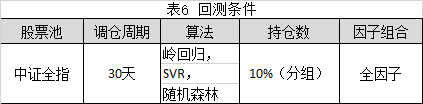
以中证全指为股票池,按照每30日进行一次调仓,分别采用岭回归,SVR和随机森林算法进行分组回测。回测条件参考表6所示,回测结果参考表7所示。
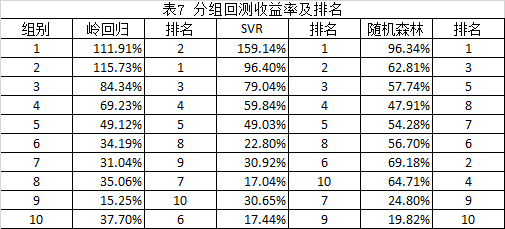
从表7可知,仅从收益角度看,岭回归,SVR和随机森林三种算法,和线性回归类似,也能够得到相对明显的单调的策略收益率。其中,SVR的趋势最为明显。随机森林的趋势不够显著,在头尾的收益率分水岭比较清晰,在中间分组的分水岭比较模糊。
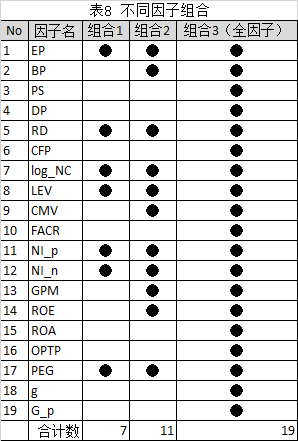
将全部因子分成三种不同的因子组合,参考表8所示。
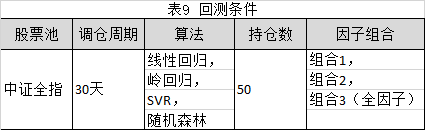
利用不同算法下,买入排序后前50名股票。每30日进行一次调仓。回测条件参考表9所示。
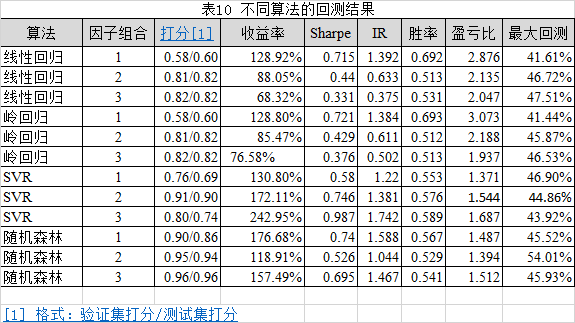
根据上述方法,利用不同的算法进行回测,回测结果参考表10所示:
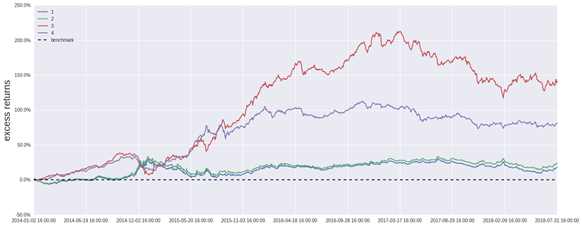
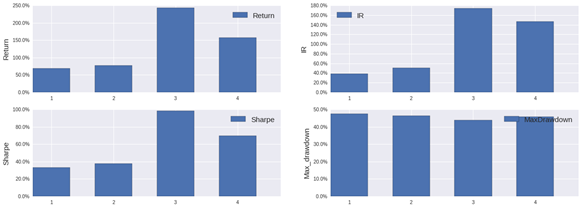
由表10、图6、图7(因子组合3)可知:
1.收益和风险的平衡最理想的策略是采用全因子组合的SVR算法策略,该策略的收益率为243%,夏普比率为0.987,IR为1.742。该三项指标在所有投资组合中表现最好,而其最大回测与其他投资组合持平,甚至更低。
2.长期来看,该投资策略在不同的算法皆能跑赢基准。在该投资策略下,总体上看,收益率表现最好的是SVR。SVR最低的收益率也比岭回归及线性回归最高的收益率要略高。其次是随机森林,而岭回归和线性回归不相伯仲。
3.随着因子数的增多,线性回归,岭回归的收益率反而下降,而SVR随着因子数的增多,收益率上升。随机森林的收益率表现不稳定。夏普比率和IR的表现和收益率相似。
4.不同的因子组合在不同的算法下,最大回测相差不大,没有一种算法也没有一种因子组合有特别的优势。这说明该投资策略本身在风险控制上存在着不足。
5.从测试集及验证集的打分来看,随机森林的模型拟合程度最高,预测准确度最高。SVR的拟合程度表现不稳定。线性回归和岭回归的拟合程度基本一致。
6.随着因子数的增多,线性回归,岭回归,随机森林的打分越来越高,说明随着因子数的增加,其拟合程度越来越高。SVR打分和因子数没有明显的关系。SVR也是验证集打分与测试集打分的差别最大。
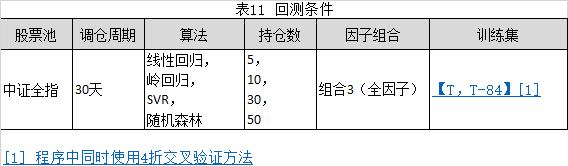
本文为了分析并实证不同持仓数下的收益和风险的不同表现,按照表8所示的因子组合3(全因子组合),将持仓数分别设置为5、10、30、50,进行回测,详细的回测条件参考表11所示,
回测结果参考表12所示,
从表12可知,
1.收益表现最好的是SVR算法(持仓数为5)的情况,该算法实现了698%的最高收益率,夏普比率和IR也达到最高,分别为1.61和2.03。但是该算法的最大回测也非常高,超过了50%,策略波动率远高于基准波动率。如果考虑最大回测不要超过50%的话,SVR算法(持仓数为30)的情况最为理想,该算法实现了263%的收益率,普遍高于其他情况,夏普比率为1.07,也普遍高于其他情况。而该持仓数下,最大回测下降到44%,接近于平均值。
2.在相同持仓数下,收益率及夏普比率排名大致保持SVR>随机森林>岭回归>线性回归的顺序。
3.随着持仓数减少,各个算法的收益率都有上升,SVR上升最为明显。由此可见,持仓越分散,收益越容易被平摊。而策略波动率则刚刚相反。持仓越集中,波动越大。
4.线性回归和岭回归随着持仓数减少,最大回测出现了逐渐缩小迹象。其中岭回归在持仓数为5的时候最大回测达到最小,盈亏比达到最大;与之相反,SVR和随机森林随着持仓数减少,最大回测出现明显扩大。
5.结合收益和风险的指标,利用线性回归和岭回归算法时,最佳持仓数为5,利用SVR和随机森林算法时,最佳持仓数为30。
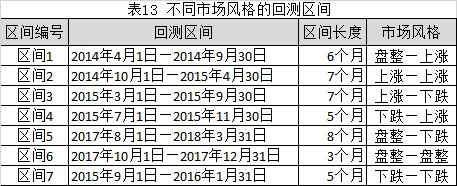
根据不同的市场的风格之间的切换,设置不同的回测区间,参考表13所示。
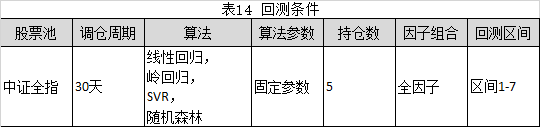
回测条件参考表14所示,
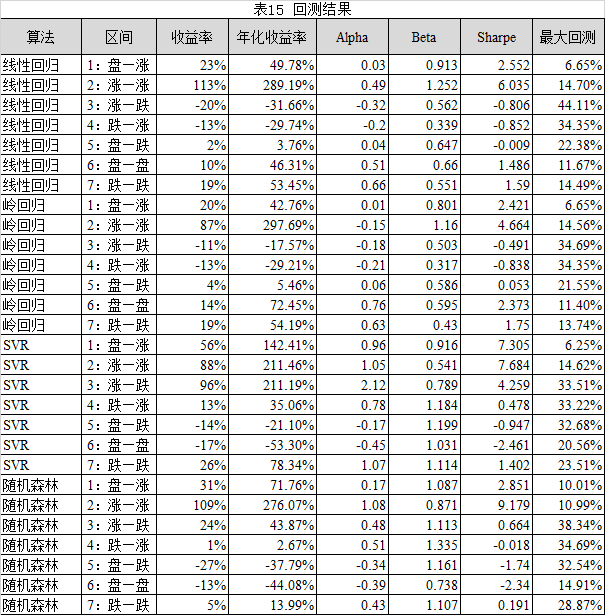
回测结果参考表15所示,
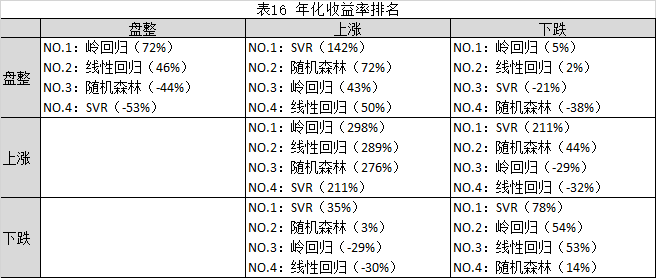
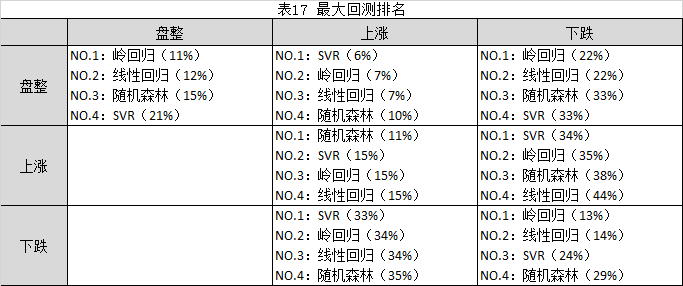
为了更加清晰地比较不同算法的收益和风险,对表15进行简化,参考表16(年化收益排名)、表17(最大回测排名)所示。
从表16、表17可知,
1.从收益来看,在市场风格没有大的切换的期间,整体而言,线性模型要优于SVR和随机森林算法。在市场长期盘整阶段,SVR和随机森林算法基本失效。在长期盘整走势当中应该谨慎用机器学习算法进行量化投资的指导,此时更应该结合其他技术分析理论进行投资决策辅助。在持续下跌的市场环境中,SVR算法也能获得超额收益。
2.从收益来看,在市场风格出现明显切换的期间,SVR和随机森林算法整体而言要优于线性模型,SVR算法尤其突出。但是在市场风格由盘整切换到下跌期间,SVR和随机森林算法基本失效。
3.从风险来看,在市场风格没有大的切换的期间,线性模型整体而言要优于SVR和随机森林算法。在持续上涨阶段,SVR和随机森林算法基本能赶上线性模型,其他情况下,其风险远高于线性模型。
3.从风险来看,在市场风格出现明显切换的期间,并没有什么算法表现出特别高的风险预测能力。
4.总体而言,市场风格没有大的切换的期间,线性模型优于SVR和随机森林算法,反之,SVR算法更优(市场风格由盘整切换到下跌期间除外)。
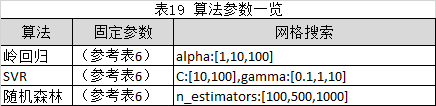
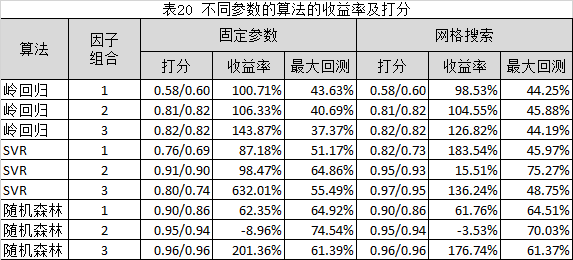
以中证全指为可行股票池,持仓数为5,分别使用固定参数和网格搜索(带标准3折交叉验证)的方法来验证不同参数的模型泛化程度并调节监督模型参数以获得最佳泛化性能。回测条件参考表18所示,算法参数参考表19所示,
回测结果参考表20所示,
由表20可知:
1.岭回归采用不同的参数设置方式下,固定参数的收益率高于网格搜索的收益率。而SVR和随机森林表现不稳定。
2.岭回归和随机森林的模型拟合程度(测试集打分)在不同参数的设置方式下,网格搜索相对于固定参数而言,没有明显的提升。而SVR的网格搜索的测试集打分则显著优于固定参数的打分。
3.总体而言,使用网格搜索可以使SVR的模型拟合度更高。但是,使用网格搜索并不能带来收益率的显著上升,甚至导致收益率的下降。
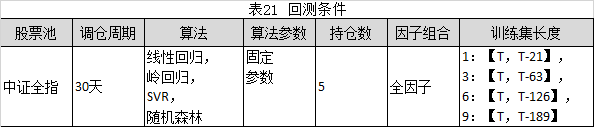
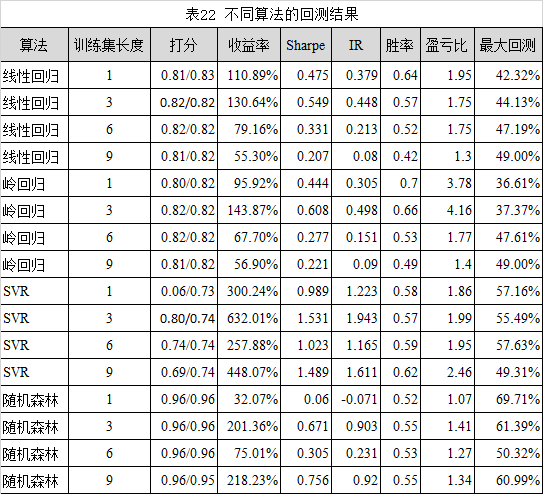
调节滚动训练集的长度,回测条件参考表21所示,进行回测。回测结果参考表22所示:
由表22可知,
1.收益表现最好的是SVR算法(训练集长度:3)。该策略的夏普比率和信息比率也是最优的。
2.从收益来看,增加训练集长度,并不一定能带来收益率的增加。线性回归,岭回归,SVR表现最佳的训练集长度是3,随机森林表现最佳的训练集长度为9。
3.从风险来看,增加训练集长度,并不一定能降低风险。线性回归,岭回归算法随着训练集长度的增加,最大回测有下降趋势。SVR,随机森林表现不稳定。
1.本文构建的量化选股模型在2014年1月-2018年7月间累计收益率最高可达到698%(SVR算法,持仓数为5的情况),年化收益率达到59%,远远超出同期比较基准(中证全指)的业绩表现(收益率:42%),可见本文的策略具有较好的选股效果。
2.通过分组回测比较分析可以发现,在中证全指的情况下,策略业绩随着分位组变化具有显著的递减趋势,说明该模型在投资中证全指成分股时能够有效区分强势股和弱势股。
3.与线性模型(线性回归和岭回归)对比分析可以发现,本文的投资策略通过非线性模型(SVR和随机森林)可以不断适应市场环境的变化,可以更好地挖掘具有超额收益的股票。非线性模型在收益率、夏普比率和信息比率方面表现不错,基于非线性模型选股的投资策略能稳定地优于线性模型;从回撤的角度看,非线性模型相比于线性模型不具备明显优势,有些时候回撤与线性模型持平甚至大于线性模型。
4.随机森林和SVR相比,虽然在个别的情况下,随机森林比SVR能获取更高的超额收益,但是从整体来看,随机森林的收益率要低于SVR。但是,在本文因子条件下,随机森林的预测能力毋庸置疑远胜于SVR。
5.具有正则化优势的岭回归相比线性回归对策略没有明显的提升作用。我们分析有两个可能的原因。首先,随着模型的可用数据越来越多,两个模型的性能都在提升,最终线性回归的性能追上了岭回归。反过来同时验证了如果有足够多的训练数据,正则化变得不那么重要,并且岭回归和线性回归将具有相同的性能。其次,由于预处理过程中做了去极值和标准化,在降低因子多重共线性的同时减少了极端样本的出现概率,因而进一步削弱了正则化的价值。所以,在本文的策略中,正则化并没有对收益率等指标产生明显的帮助。
随着因子数的增多,不管是哪种算法,整体上,拟合度和收益率出现了反向关系。两者刚好相反的原因可以解释如下:由于本文的量化投资策略是以购买偏离预测值下方最多的股票为投资标的,所以拟合度不高的算法反而更容易发现那些实际值与预测值偏差过大的股票,从而更能精准地买入。
6.不同的因子组合,不同的持仓数对策略表现具有一定的影响。线性模型在因子增多时收益率下降。非线性模型在因子增多时更具有收益能力。持仓数越少收益率越高,风险也随之增大。
7.在本文,我们将市场风格划分为9种,并实证了其中7种不同市场风格,分别是持续盘整,持续上涨,持续下跌,盘整—上涨切换,盘整—下跌切换,上涨—下跌切换,下跌—上涨切换。每种市场风格都测试了用机器学习算法对于收益率和最大回测的情况。根据测试结果显示:在市场风格没有大的切换时候,线性模型的算法要优于SVR和随机森林的算法,反之,SVR表现最佳,且该算法的收益远胜于其他算法。
8.关于在算法优化方面,不管是采用网格搜索的方法来优化算法的参数,还是采用增加滚动训练集长度的方法来优化模型泛化程度,都不能带来收益率的明显上升,甚至下降。SVR算法的收益率对是否使用网格搜索或者说参数值的敏感度很高,在使用SVR算法时要充分讨论其参数的合理性。从收益率和夏普比率的角度来看,线性模型,SVR算法的回测效果最佳的滚动训练集长度是3个交易月,随机森林算法的回测效果最佳的滚动训练集长度是9个交易月。
本文在传统的多因子模型的基础上,引入机器学习选股,试图建立更加有效的量化选股策略,但仍然存在以下的几点不足:
1.本文的策略在风险控制上显得不足,尤其是2015年牛熊市的市场风格切换异常迅速,本文的量化投资策略在市场高风险时没能考虑止损等风险控制,导致最大回撤较大。如能加入止盈止损条件或引入择时模型对股票的买卖时机以及仓位进行判断,或利用对冲机制对风险进行对冲,有望能控制风险。由于时间的关系,本文在这方面没有做深度研究。
2.本文在使用多因子模型时,使用的因子的范围比较窄,主要基于基本面。基本面以外,比如技术面的因子并没有考虑进来。
3.由于实际条件的限制,本文的量化投资策略的评价主要基于历史数据的回测结果进行比较和评估,没有后续的实盘模拟及实时交易跟踪。本文的策略还有待于在实盘交易中进行进一步的验证。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程