
MQL 语言的新版本向自动交易系统的开发人员提供实施复杂任务的有效工具。不可否认,语言的编程能力已经得到极大的扩展。MQL5 面向对象的编程功能尤其值得一提。此外,也不能忽视标准库。通过错误代码 359 来判断,将很快支持类模板。
在本文中,我将通过描述数据类型和它们的集合来介绍什么在某种形式上可能是本文主题的扩展或延续。在这里,我要引用一篇在 MQL5.community 网站上发布的文章。Dmitry Fedoseev (Integer) 在他的 "MQL5 Programming Basics:Arrays"(MQL5 编程基础:数组)一文中极为详细且全面地描述了使用数组的原则和逻辑。
因此,今天我将转向列表,更加确切地说,转向线性链表。我们将从列表结构、含义及逻辑开始。之后,我们将探讨已经包含在标准库中的相关工具。最后,我将提供一个在使用 MQL5 时如何运用列表的例子。
那么,对于开发者而言,什么是列表?怎么处理列表?我要引用公共信息源维基百科对此术语的一般定义:
在计算机科学中,列表是一种抽象数据类型,实施一种有限而有序的值的集合,其中相同的值可以出现多次。列表的一个实例是有限序列 - 元组这一数学概念的计算机表示。在列表中,一个值的每个实例通常称为列表的一个项目、条目或元素;如果相同的值出现多次,每一次出现都被视为一个分立的项目。
术语“列表”也用于几种有形的数据结构,这些结构可用于实施抽象列表,尤其是链表。
我相信您会同意这一定义在某种程度上太学究气了。
出于本文的目的,我们对此定义的最后一句更有兴趣。因此,让我们在此基础上稍作展开。
在计算机科学中,链表是一个基本的动态数据结构,由若干节点组成,其中每个节点包含数据和一个或两个到链表的下一个和/或上一个节点的引用(“链接)。[1]链表相对于传统数组的主要优势在于结构灵活性:链表中项目的顺序不需要与计算机内存中数据元素的顺序一致,同时始终为列表遍历维持列表项目的内部链接。
让我们尝试一步接一步地深入了解。
在计算机科学中,列表本身是某种数据类型。我们已经确定了这一点。它是一种综合数据类型,因为它包含其它数据类型。列表在一定程度上类似于数组。如果曾经将单一类型的数据组成的数组归类为一个新的数据类型,则该数组应该是列表。但并不是完全如此。
列表的主要优势在于在需要时,它允许在列表的任何位置插入或删除节点。在这里,除了对于列表,您不需要总是要使用 ArrayResize() 函数以外,列表类似于动态数组。
就内存元素的顺序而言,没有保存列表节点,并且不需要按相邻内存区域中数组元素的相同存储方式存储列表节点。
或多或少是这样的。让我们更加深入地探讨列表。
1.1 单向链表中的节点
列表允许您存储节点而不是项目。节点是一种数据类型,由两部分组成。
第一部分是数据字段,第二部分用于其它节点的链接(图 1)。列表中的第一个节点称为“头”,列表中的最后一个节点称为“尾”。尾链接字段包含一个 NULL 引用。基本而言,它用于表示列表没有更多的节点了。其它专业资料将列表中头以下的部分称为“尾”。

图 1 单向链表中的节点
除了单向列表节点以外,还有其它类型的节点。双向链表中的节点或许是更常见的节点。
1.2 双向链表中的节点
我们还需要一种满足双向链表需要的节点。它与前一类型的不同之处在于它包含指向前一节点的另一链接。列表的头节点自然包含一个 NULL 引用。在显示包含此类节点的列表的结构图(图 2)中,指向前一节点的链接显示为红色箭头。

图. 2 双向链表中的节点
因此,双向链表节点的能力将与单向链表节点的类似。您只需要多处理一个到前一节点的链接。
1.3 循环双向链表中的节点
也有可在非线性列表中使用以上节点的情形。尽管本文将主要描述线性列表,我也会提供一个循环列表的例子。

图 3 循环双向链表中的节点
循环双向链表图(图 3)显示具有两个链接字段的节点是简单的循环链接。这通过使用橙色和绿色箭头来表示。因此,头节点将被链接到尾节点(作为上一元素)。尾节点的链接字段不会是空的,因为它将指向头节点。
1.4 主要的列表操作
如专业文献所指出,所有列表操作都可分为 3 个基础组:
添加方法包括:
至于涉及的删除操作,它们几乎是添加组对应操作的镜像:
在这里,我愿意指出,析构函数不仅用于正确完成并终止列表操作,还用于正确地删除其所有元素。
各种检查操作组成的第三组事实上提供了对列表中各个节点或节点值的访问:
除了基础组以外,我还分离出第四组,即服务组。它为前几个组服务:
就是这样。当然,开发者可以依据需要随时扩展列表类的功能。
在这一部分,我建议我们应直接开始对节点和列表进行编程。将在必要时提供代码的说明。
2.1 单向链表中的节点
让我们为满足单向链表需要的节点类打下地基(图 4)。您可以在 "如何使用 UML 工具开发 EA 交易"(如何使用 UML 工具开发 EA 交易)一文中熟悉类图符号(模型)(请参阅图 5. CTradeExpert 类的 UML 模型)。

图 4 CiSingleNode 类模型
现在,让我们尝试处理代码。它以 Art Friedman 和其他作者的"C/C++ Annotated Archives"(C/C++ 注解大全)一书提供的例子为基础。
//+------------------------------------------------------------------+ //| CiSingleNode class | //+------------------------------------------------------------------+ class CiSingleNode { protected: int m_val; // data CiSingleNode *m_next; // pointer to the next node public: void CiSingleNode(void); // default constructor void CiSingleNode(int _node_val); // parameterized constructor void ~CiSingleNode(void); // destructor void SetVal(int _node_val); // set-method for data void SetNextNode(CiSingleNode *_ptr_next); // set-method for the next node virtual void SetPrevNode(CiSingleNode *_ptr_prev){}; // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const {return NULL;}; // get-method for the previous node CiSingleNode *GetNextNode(void) const; // get-method for the next node int GetVal(void){TRACE_CALL(_t_flag) return m_val;} // get-method for data };
我不会解释 CiSingleNode 类的每一种方法。您可以在附带的文件 CiSingleNode.mqh 中更加详细地研究它们。然而,我要提醒您注意一个有趣的细节。类包含处理以前节点的虚拟方法。事实上,它们是虚设的,它们的存在仅仅是为了将来后代的多态现象。
代码使用跟踪使用的每个方法的调用所需的 TRACE_CALL(f) 预处理器指令。
#define TRACE_CALL(f) if(f) Print("Calling: "+__FUNCSIG__);
仅有 CiSingleNode 类可用,您处于创建一个单向链表的情形之中。让我给您一个代码的例子。
//=========== Example 1 (processing the CiSingleNode type ) CiSingleNode *p_sNodes[3]; // #1 p_sNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_sNodes);i++) p_sNodes[i]=new CiSingleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_sNodes)-1);j++) p_sNodes[j].SetNextNode(p_sNodes[j+1]); // #3 //--- check values for(int i=0;i<ArraySize(p_sNodes);i++) { int val=p_sNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_sNodes)-1);j++) { CiSingleNode *p_sNode_next=p_sNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_sNodes);i++) delete p_sNodes[i]; // #12
在字符串 #1 中,我们声明一个指向类型为 CiSingleNode 的对象的指针数组。在字符串 #2 中,该数组被填以创建的指针。对于每个节点的数据,我们使用 rand() 函数,在 0 至 32767 的范围内取用伪随机整数。在字符串 #3 中,节点链接到 到下一指针。在字符串 #4-5 中,我们检查节点的值,在字符串 #9-11 中,我们检查链接的执行。在字符串 #12 中删除指针。
以下是记录到日志的内容。
DH 0 23:23:10 test_nodes (EURUSD,H4) Node #1 value = 3335 KP 0 23:23:10 test_nodes (EURUSD,H4) Node #2 value = 21584 GI 0 23:23:10 test_nodes (EURUSD,H4) Node #3 value = 917 HQ 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #1 value = 21584 HI 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #2 value = 917
可以用下图(图 5)示意性地表示生成的节点结构。
![图 5 CiSingleNode *p_sNodes[3] 数组中节点之间的链接](https://c.mql5.com/2/6/5__1.png "图 5 CiSingleNode *p_sNodes[3] 数组中节点之间的链接")
图 5 CiSingleNode *p_sNodes[3] 数组中节点之间的链接
现在,让我们研究双向链表中的节点。
2.2 双向链表中的节点
首先,我们需要重温一下,双向链表节点的不同之处在于它有两个指针:下一节点指针和前一节点指针,即除了下一节点链接以外,您还需要向单向链表节点添加一个指向前一节点的指针。
为此,我建议使用继承作为类关系。这样,双向链表节点的类模型看起来如下所示(图 6)。

图 6 CDoubleNode 类模型
现在,是时候查看代码了。
//+------------------------------------------------------------------+ //| CDoubleNode class | //+------------------------------------------------------------------+ class CDoubleNode : public CiSingleNode { protected: CiSingleNode *m_prev; // pointer to the previous node public: void CDoubleNode(void); // default constructor void CDoubleNode(int node_val); // parameterized constructor void ~CDoubleNode(void){TRACE_CALL(_t_flag)};// destructor virtual void SetPrevNode(CiSingleNode *_ptr_prev); // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const; // get-method for the previous node CDoubleNode };
只有很少的几个其它方法 - 它们是虚拟的,并且与处理前一节点有关。在 CDoubleNode.mqh 中提供了完整的类描述。
让我们尝试依据 CDoubleNode 类创建一个双向链表。让我给您一个代码的例子。
//=========== Example 2 (processing the CDoubleNode type) CiSingleNode *p_dNodes[3]; // #1 p_dNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_dNodes);i++) p_dNodes[i]=new CDoubleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { p_dNodes[j].SetNextNode(p_dNodes[j+1]); // #3 p_dNodes[j+1].SetPrevNode(p_dNodes[j]); // #4 } //--- check values for(int i=0;i<ArraySize(p_dNodes);i++) { int val=p_dNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_next=p_dNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- check prev-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_prev=p_dNodes[j+1].GetPrevNode(); // #12 int snode_prev_val=p_sNode_prev.GetVal(); // #13 Print("Prev-Node #"+IntegerToString(j+2)+ // #14 " value = "+IntegerToString(snode_prev_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_dNodes);i++) delete p_dNodes[i]; // #15
原则上,这与创建单向链表类似,但仍然有一些特性。注意指针数组 p_dNodes[] 是如何在字符串 #1 中声明的。指针的类型可以设置为与基类相同。字符串 #2 中的多态性原则将帮助我们在以后识别它们。在字符串 #12-14 中检查前一节点。
向日志添加了以下信息。
GJ 0 16:28:12 test_nodes (EURUSD,H4) Node #1 value = 17543 IQ 0 16:28:12 test_nodes (EURUSD,H4) Node #2 value = 1185 KK 0 16:28:12 test_nodes (EURUSD,H4) Node #3 value = 23216 DS 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #1 value = 1185 NH 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #2 value = 23216 FR 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #2 value = 17543 LI 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #3 value = 1185
可以用下图(图 7)示意性地表示生成的节点结构:
![图 7 CDoubleNode *p_sNodes[3] 数组中节点之间的链接](https://c.mql5.com/2/6/7.png "图 7 CDoubleNode *p_sNodes[3] 数组中节点之间的链接")
图 7 CDoubleNode *p_sNodes[3] 数组中节点之间的链接
现在,我建议我们考虑一个在创建松散双向链表时需要的节点。
2.3 松散双向链表中的节点
试想这样一个节点,它包含可归于整个数组的数据成员(而不是单一值),即包含和描述整个数组。然后,可用此类节点来创建一个松散列表。我已经决定在这里不提供任何说明,因为此节点与双向链表中的标准节点完全相同。唯一区别在于“数据”属性封装了整个数组。
我将再次使用继承。CDoubleNode 类将用作松散双向链表节点的基类。松散双向链表节点的类模型将如下所示(图 8)。

图 8 CiUnrollDoubleNode 类模型
可以使用以下代码定义 CiUnrollDoubleNode 类:
//+------------------------------------------------------------------+ //| CiUnrollDoubleNode class | //+------------------------------------------------------------------+ class CiUnrollDoubleNode : public CDoubleNode { private: int m_arr_val[]; // data array public: void CiUnrollDoubleNode(void); // default constructor void CiUnrollDoubleNode(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleNode(void); // destructor bool GetArrVal(int &_dest_arr_val[])const; // get-method for data array bool SetArrVal(const int &_node_arr_val[]); // set-method for data array };
您可以在 CiUnrollDoubleNode.mqh 中更加详细地查看每种方法。
让我们以一个参数化构造函数为例。
//+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CiUnrollDoubleNode::CiUnrollDoubleNode(int &_node_arr[]) : CDoubleNode(ArraySize(_node_arr)) { ArrayCopy(this.m_arr_val,_node_arr); TRACE_CALL(_t_flag) }
在这里,我们使用初始化列表,在数据成员 this.m_val 中输入一个一维数组的大小。
之后,我们“手动”创建一个松散双向链表并检查其中的链接。
//=========== Example 3 (processing the CiUnrollDoubleNode type) //--- data arrays int arr1[],arr2[],arr3[]; // #1 int arr_size=15; ArrayResize(arr1,arr_size); ArrayResize(arr2,arr_size); ArrayResize(arr3,arr_size); srand(GetTickCount()); // initialize a random number generator //--- fill the arrays with pseudorandom integers for(int i=0;i<arr_size;i++) { arr1[i]=rand(); // #2 arr2[i]=rand(); arr3[i]=rand(); } //--- create nodes CiUnrollDoubleNode *p_udNodes[3]; // #3 p_udNodes[0]=new CiUnrollDoubleNode(arr1); p_udNodes[1]=new CiUnrollDoubleNode(arr2); p_udNodes[2]=new CiUnrollDoubleNode(arr3); //--- links for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { p_udNodes[j].SetNextNode(p_udNodes[j+1]); // #4 p_udNodes[j+1].SetPrevNode(p_udNodes[j]); // #5 } //--- check values for(int i=0;i<ArraySize(p_udNodes);i++) { int val=p_udNodes[i].GetVal(); // #6 Print("Node #"+IntegerToString(i+1)+ // #7 " value = "+IntegerToString(val)); } //--- check array values for(int i=0;i<ArraySize(p_udNodes);i++) { int t_arr[]; // destination array bool isCopied=p_udNodes[i].GetArrVal(t_arr); // #8 if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Node #"+IntegerToString(i+1)+ // #9 " array values = "+arr_str); } } //--- check next-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_next=p_udNodes[j].GetNextNode(); // #10 bool isCopied=p_udNode_next.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Next-Node #"+IntegerToString(j+1)+ " array values = "+arr_str); } } //--- check prev-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_prev=p_udNodes[j+1].GetPrevNode(); // #11 bool isCopied=p_udNode_prev.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Prev-Node #"+IntegerToString(j+2)+ " array values = "+arr_str); } } //--- delete nodes for(int i=0;i<ArraySize(p_udNodes);i++) delete p_udNodes[i]; // #12 }
代码的量变得稍微多一些。这是因为我们需要为每个节点创建并填充一个数组。
数据数组的处理在字符串 #1 中开始。它与我们讨论过的前一节点中的处理基本类似。只是我们需要为整个数组打印每个节点的数据值(即字符串 #9)。
结果如下:
IN 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 value = 15 NF 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 value = 15 CI 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 value = 15 FQ 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 EG 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 MK 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 RP 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #1 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 JD 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #2 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 EH 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #2 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 NN 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #3 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756
我建议我们应结束对节点的处理,并直接前往不同列表的类定义。可以在脚本 test_nodes.mq5 中找到例子 1-3。
2.4 单向链表
现在,让我们从主要的列表操作组创建一个单向链表的类模型(图 9)。

图 9 CiSingleList 类模型
很容易看出,CiSingleList 类使用 CiSingleNode 类型的节点。就类之间的关系类型而言,我们可以说:
图 10 说明了以上关系。

图 10 CiSingleList 类和 CiSingleNode 类之间的关系类型
让我们创建一个新类 - CiSingleList。往前看,本文使用的所有其它列表类都以此类为基础。这是它为什么如此“丰满”的原因。
//+------------------------------------------------------------------+ //| CiSingleList class | //+------------------------------------------------------------------+ class CiSingleList { protected: CiSingleNode *m_head; // head CiSingleNode *m_tail; // tail uint m_size; // number of nodes in the list public: //--- constructor and destructor void CiSingleList(); // default constructor void CiSingleList(int _node_val); // parameterized constructor void ~CiSingleList(); // destructor //--- adding nodes void AddFront(int _node_val); // add a new node to the beginning of the list void AddRear(int _node_val); // add a new node to the end of the list virtual void AddFront(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the end of the list //--- deleting nodes int RemoveFront(void); // delete the head node int RemoveRear(void); // delete the node from the end of the list void DeleteNodeByIndex(const uint _idx); // delete the ith node from the list //--- checking virtual bool Find(const int _node_val) const; // find the required value bool IsEmpty(void) const; // check the list for being empty virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list CiSingleNode *GetHeadNode(void) const; // get the head node CiSingleNode *GetTailNode(void) const; // get the tail node virtual uint Size(void) const; // list size //--- service virtual void PrintList(string _caption=NULL); // print the list virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values virtual void BubbleSort(void); // bubble sorting //---templates template<typename dPointer> bool CheckDynamicPointer(dPointer &_p); // template for checking a dynamic pointer template<typename dPointer> bool DeleteDynamicPointer(dPointer &_p); // template for deleting a dynamic pointer protected: void operator=(const CiSingleList &_sList) const; // assignment operator void CiSingleList(const CiSingleList &_sList); // copy constructor virtual bool AddToEmpty(int _node_val); // add a new node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _val); // new "native" node virtual void CalcSize(void) const; // calculate the list size };
在 CiSingleList.mqh 中提供了完整的类方法定义。
当我开始开发这个类时,只有 3 个数据成员和几种方法。但是因为这个类是其它类的基础,我不得不添加几个虚拟成员函数。我不会详细描述这些方法。可以在脚本 test_sList.mq5 中找到使用这个单向链表类的例子。
如果在没有跟踪标记的情况下运行它,则以下条目将出现在日志中:
KG 0 12:58:32 test_sList (EURUSD,H1) =======List #1======= PF 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 RL 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 MD 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 DM 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 QE 0 12:58:32 test_sList (EURUSD,H1) KN 0 12:58:32 test_sList (EURUSD,H1) LR 0 12:58:32 test_sList (EURUSD,H1) =======List #2======= RE 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 DQ 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 GK 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 FP 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 KF 0 12:58:32 test_sList (EURUSD,H1) MK 0 12:58:32 test_sList (EURUSD,H1) PR 0 12:58:32 test_sList (EURUSD,H1) =======renewed List #2======= GK 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=11 JP 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=13 JI 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=14 CF 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=34 QL 0 12:58:32 test_sList (EURUSD,H1) Node #5, val=35 OE 0 12:58:32 test_sList (EURUSD,H1) Node #6, val=36 MR 0 12:58:32 test_sList (EURUSD,H1) Node #7, val=37 KK 0 12:58:32 test_sList (EURUSD,H1) Node #8, val=38 MS 0 12:58:32 test_sList (EURUSD,H1) Node #9, val=666 OF 0 12:58:32 test_sList (EURUSD,H1) QK 0 12:58:32 test_sList (EURUSD,H1)
脚本填写了 2 个单向链表,然后扩展第二个列表并对其排序。
2.5 双向链表
现在,让我们尝试依据前一类型的列表创建一个双向链表。图 11 说明了双向链表的类模型:

图 11 CDoubleList 类模型
派生类包含更少的方法,而数据成员则完全缺失。以下是 CDoubleList 类的定义。
//+------------------------------------------------------------------+ //| CDoubleList class | //+------------------------------------------------------------------+ class CDoubleList : public CiSingleList { public: void CDoubleList(void); // default constructor void CDoubleList(int _node_val); // parameterized constructor void ~CDoubleList(void){}; // destructor virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list protected: virtual bool AddToEmpty(int _node_val); // add a node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _node_val); // new "native" node };
在 CDoubleList.mqh 中对 CDoubleList 类方法提供了完整的描述。
一般而言,在这里使用的虚拟函数仅用于满足指向单向链表中并不存在的前一节点的指针的需要。
可以在脚本 test_dList.mq5 中找到使用 CDoubleList 类型的列表的例子。它说明了与此列表类型有关的所有常见列表操作。脚本代码包含一个 特殊的字符串:
CiSingleNode *_new_node=new CDoubleNode(666); // create a new node of CDoubleNode type
并没有错误,因为此类构造在基类指针描述派生类的对象时是普遍接受的。这是继承的优势之一。
在 MQL5 中,以及在 С++ 中,指向基类的指针可以指向从该基类派生的子类的对象。但反指就是无效的。
如果您编写如下所示的代码字符串:
CDoubleNode*_new_node=new CiSingleNode(666);
编译器将不会报告错误或发出警告,但是程序会运行到此字符串为止。在这个例子中,您将看到一条消息,指出指针引用的对象的类型转换出错。因为最近的绑定机制仅在程序正在运行时才起作用,我们需要仔细考虑类之间的关系层次。
运行脚本之后,日志将包含以下条目:
DN 0 13:10:57 test_dList (EURUSD,H1) =======List #1======= GO 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 IE 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 FM 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 KD 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 JL 0 13:10:57 test_dList (EURUSD,H1) DG 0 13:10:57 test_dList (EURUSD,H1) CK 0 13:10:57 test_dList (EURUSD,H1) =======List #2======= IL 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 KH 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 PR 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 MI 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 DO 0 13:10:57 test_dList (EURUSD,H1) FR 0 13:10:57 test_dList (EURUSD,H1) GK 0 13:10:57 test_dList (EURUSD,H1) =======renewed List #2======= PR 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=11 QI 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=13 QP 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=14 LO 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=34 JE 0 13:10:57 test_dList (EURUSD,H1) Node #5, val=35 HL 0 13:10:57 test_dList (EURUSD,H1) Node #6, val=36 FK 0 13:10:57 test_dList (EURUSD,H1) Node #7, val=37 DR 0 13:10:57 test_dList (EURUSD,H1) Node #8, val=38 FJ 0 13:10:57 test_dList (EURUSD,H1) Node #9, val=666 HO 0 13:10:57 test_dList (EURUSD,H1) JR 0 13:10:57 test_dList (EURUSD,H1)
如单向链表的例子,脚本填充第一个(双向链)表,然后复制并传递到第二个列表。之后,它增加第二个列表中的节点数量,排序并打印列表。
2.6 松散双向链表
此列表类型的方便之处在于它不仅允许您存储值,还允许您存储整个数组。
让我们为 CiUnrollDoubleList 类型的列表打下地基(图 12)。

图 12 CiUnrollDoubleList 类模型
因为在这里我们将处理一个数据数组,我们必须重新定义在间接基类 CiSingleList 中定义的方法。
以下是 CiUnrollDoubleList 类的定义。
//+------------------------------------------------------------------+ //| CiUnrollDoubleList class | //+------------------------------------------------------------------+ class CiUnrollDoubleList : public CDoubleList { public: void CiUnrollDoubleList(void); // default constructor void CiUnrollDoubleList(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual void AddFront(int &_node_arr[]); // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]); // add a new node to the end of the list virtual bool CopyByValue(const CiSingleList &_udList); // copy by values virtual void PrintList(string _caption=NULL); // print the list virtual void BubbleSort(void); // bubble sorting protected: virtual bool AddToEmpty(int &_node_arr[]); // add a node to an empty list virtual void addFront(int &_node_arr[]); // add a new "native" node to the beginning of the list virtual void addRear(int &_node_arr[]); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" node from the beginning of the list virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int &_node_arr[]); // new "native" node };
在 CiUnrollDoubleList.mqh 中提供了完整的类方法定义。
让我们运行脚本 test_UdList.mq5 以检查类方法的操作。在这里,节点操作与在前面的脚本中使用的操作类似。或许我们应该对排序和打印方法多说几句。排序方法按元素的数量排列节点,将含有最小值数组的节点置于列表的最前面。
打印方法打印某个节点包含的数组值的字符串。
运行脚本之后,日志将包含以下条目:
II 0 13:22:23 test_UdList (EURUSD,H1) =======List #1======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 OO 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 GG 0 13:22:23 test_UdList (EURUSD,H1) GP 0 13:22:23 test_UdList (EURUSD,H1) GR 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 before sorting======= JO 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 CH 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CF 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 GD 0 13:22:23 test_UdList (EURUSD,H1) GQ 0 13:22:23 test_UdList (EURUSD,H1) LJ 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 after sorting======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CJ 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 II 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 MD 0 13:22:23 test_UdList (EURUSD,H1) MQ 0 13:22:23 test_UdList (EURUSD,H1)
如您所见,在排序之后,udList2 列表的打印顺序是从含有最小数组的节点开始,直到含有最大数组的节点。
2.7 循环双向链表
尽管非线性列表不在本文的讨论范围之内,我建议我们也处理此类列表。前文已经显示了如何以循环方式链接节点(图 3)。
让我们创建 CiCircleDoubleList 类的一个模型(图 13)。这个类是 CDoubleList 类的派生类。

图 13 CiCircleDoubleList 类模型
由于这个列表中的节点是特殊字符(头尾相链),来源基类 CiSingleList 的几乎全部方法都必须是虚拟的。
//+------------------------------------------------------------------+ //| CiCircleDoubleList class | //+------------------------------------------------------------------+ class CiCircleDoubleList : public CDoubleList { public: void CiCircleDoubleList(void); // default constructor void CiCircleDoubleList(int _node_val); // parameterized constructor void ~CiCircleDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual uint Size(void) const; // list size virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool Find(const int _node_val) const; // find the required value virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values protected: virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list protected: void CalcSize(void) const; // calculate the list size void LinkHeadTail(void); // link head to tail };
在 CiCircleDoubleList.mqh 中提供了完整的类描述。
让我们研究一下 CSnakeGame 类的某些方法。CiCircleDoubleList::LinkHeadTail() 方法将尾节点链接到头节点。当出现新的尾节点或头节点,并且前一链接丢失时,应调用该方法。
//+------------------------------------------------------------------+ //| Linking head to tail | //+------------------------------------------------------------------+ void CiCircleDoubleList::LinkHeadTail(void) { TRACE_CALL(_t_flag) this.m_head.SetPrevNode(this.m_tail); // link head to tail this.m_tail.SetNextNode(this.m_head); // link tail to head }
请想一想如果我们正在处理循环单向链表,这个方法会是什么样子。
例如,思考一下 CiCircleDoubleList::addFront() 方法。
//+------------------------------------------------------------------+ //| New "native" node to the beginning of the list | //+------------------------------------------------------------------+ void CiCircleDoubleList::addFront(int _node_val) { TRACE_CALL(_t_flag) CDoubleList::addFront(_node_val); // call a similar method of the base class this.LinkHeadTail(); // link head and tail }
您可以看到,在方法的主体中调用了基类 CDoubleList 的类似方法。此时,如果它并不是针对一件事情的,则我们会完成方法操作(在这里,基本上不需要此类方法)。头节点和尾节点之间的链接丢失,并且在没有该链接的情况下,列表不能循环链接。这是我们必须调用链接头节点和尾节点的方法的原因之所在。
在脚本 test_UdList.mq5 检查了对循环双向链表的处理。
就任务和目标而言,使用的其他方法与前面的例子是相同的。
因此,日志包含以下条目:
PR 0 13:34:29 test_CdList (EURUSD,H1) =======List #1======= QS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=14 QI 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=666 LQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=13 OH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=11 DP 0 13:34:29 test_CdList (EURUSD,H1) DK 0 13:34:29 test_CdList (EURUSD,H1) DI 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 before sorting======= MS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=38 IJ 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=37 IQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=36 EH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=35 EO 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=34 FF 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=14 DN 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=666 GD 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=13 JK 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=11 JM 0 13:34:29 test_CdList (EURUSD,H1) JH 0 13:34:29 test_CdList (EURUSD,H1) MS 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 after sorting======= LE 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=11 KL 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=13 QS 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=14 NJ 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=34 NQ 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=35 NH 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=36 NO 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=37 NF 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=38 JN 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=666 RJ 0 13:34:29 test_CdList (EURUSD,H1) RE 0 13:34:29 test_CdList (EURUSD,H1)
这样,所介绍的列表类之间的最终继承关系图如下所示(图 14)。
我不确定是否所有的类都需要通过继承关联在一起,但是我决定让所有的类都如此。

图 14 列表类之间的继承
本文的这一节说明了自定义列表,我要指出,我们几乎未曾谈到非线性列表组、多链接链表 (multiply linked list) 等。当我收集到相关信息并获得处理此类动态数据结构的更多经验时,我将尝试撰写另一篇文章。
让我们看一看可在标准库中找到的列表类(图 15)。
它属于数据类。

图 15 CList 类模型
说也奇怪,CList 是 CObject 类的派生类,即列表继承该节点类的数据和方法。
列表类包含一组令人印象深刻的方法。老实说,我并不期待在标准库中找到如此之大的类。
CList 类有 8 个数据成员。我要指出某些事项。类属性包含当前节点的索引 (int m_curr_idx) 和指向当前节点的指针 (CObject* m_curr_node)。可以说列表很“聪明” - 它能够指出在哪里对控制进行本地化。此外,它具有内存管理机制(我们可以实际删除节点,或仅仅是从列表排除该节点)、排序列表标记和排序模式。
至于方法,CList 类的所有方法都可以分为以下的组别:
如通常一样,有一个标准构造函数和一个析构函数。
第一个函数清空 (NULL) 所有指针。内存管理标记状态设置为删除。新列表是不排序的。
在其主体中,析构函数仅调用 Clear() 方法来清空节点的列表。列表末尾的存在并不是一定伴随着其元素(节点)的“死亡”。因此,在删除列表元素时设置的内存管理标记将类关系从组合转为聚合。
我们可以使用 set- 和 get- 方法 FreeMode() 处理此标记。
类有两种能够用于扩展列表的方法:Add() 和 Insert()。第一种方法与本文第一节中使用的 AddRear() 方法类似。第二种方法与 SetNodeByIndex() 方法类似。
让我们以一个小例子开始。首先,我们需要创建一个 CNodeInt 节点类,该类是接口类 CObject 的派生类。它存储整数类型的值。
//+------------------------------------------------------------------+ //| CNodeInt class | //+------------------------------------------------------------------+ class CNodeInt : public CObject { private: int m_val; // node data public: void CNodeInt(void){this.m_val=WRONG_VALUE;}; // default constructor void CNodeInt(int _val); // parameterized constructor void ~CNodeInt(void){}; // destructor int GetVal(void){return this.m_val;}; // get-method for node data void SetVal(int _val){this.m_val=_val;}; // set-method for node data }; //+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CNodeInt::CNodeInt(int _val):m_val(_val) { };
我们将在脚本 test_MQL5_List.mq5 中处理 CList 列表。
示例 1 说明了列表和节点的动态创建。然后,用节点填充列表,并在删除列表之前和之后检查第一个节点的值。
//--- Example 1 (testing memory management) CList *myList=new CList; // myList.FreeMode(false); // reset flag bool _free_mode=myList.FreeMode(); PrintFormat("\nList \"myList\" - memory management flag: %d",_free_mode); CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("List \"myList\" has as many nodes as: %d",myList.Total()); Print("=======Before deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",p_new_nodes_int[0].GetVal()); delete myList; int val_to_check=WRONG_VALUE; if(CheckPointer(p_new_nodes_int[0])) val_to_check=p_new_nodes_int[0].GetVal(); Print("=======After deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",val_to_check);
如果重设标记的字符串保持为在前面加有注释符号(不活动),则我们将在日志中得到以下条目:
GS 0 14:00:16 test_MQL5_List (EURUSD,H1) EO 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 1 FR 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 JH 0 14:00:16 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= DO 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: 7189 KJ 0 14:00:16 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= QK 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: -1
请注意,在动态删除 myList 列表之后,也会从内存删除其中的所有节点。
然而,如果我们取消重置标记字符串的注释:
// myList.FreeMode(false); // reset flag则输出到日志的条目将显示如下:
NS 0 14:02:11 test_MQL5_List (EURUSD,H1) CN 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 0 CS 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 KH 0 14:02:11 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= NL 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 HJ 0 14:02:11 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= LI 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 QQ 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 undeleted objects left DD 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 objects of type CNodeInt left DL 1 14:02:11 test_MQL5_List (EURUSD,H1) 400 bytes of leaked memory
很容易注意到,在删除列表之前和之后,头节点的值保持不变。在这种情形下,如果脚本不包含正确删除它们的代码,则仍然会有未被删除的对象留下来。
现在,让我们尝试处理排序方法。
//--- Example 2 (sorting) CList *myList=new CList; CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("\nList \"myList\" has as many nodes as: %d",myList.Total()); Print("=======List \"myList\" before sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } myList.Sort(0); Print("\n=======List \"myList\" after sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } delete myList;
因此,日志包含以下条目:
OR 0 22:47:01 test_MQL5_List (EURUSD,H1) FN 0 22:47:01 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 FH 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" before sorting======= LG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 30511 CO 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 17404 GF 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 12215 KQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 31574 NJ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 7285 HP 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 23509 IH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 26991 NS 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 414 MK 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 18824 DR 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 1560 OR 0 22:47:01 test_MQL5_List (EURUSD,H1) OM 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" after sorting======= QM 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 26991 RE 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 23509 ML 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 18824 DD 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 414 LL 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 1560 IG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 17404 PN 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 30511 II 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 31574 OQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 12215 JH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 7285
即使任何排序都已完成,排序技术对我而言仍然是神秘的。我将解释这是为什么。在没有详细探讨调用顺序的情况下,CList::Sort() 方法调用虚拟方法 CObject::Compare(),该方法没有在基类中以任何方式实施。因此,编程者必须自己处理排序方法的实施。
现在,让我就 Total() 方法说几句。它返回数据成员 m_data_total 负责的元素(节点)的数量。这是一种非常简明的方法。这种实施中的元素计数将比我以前提出的方法快很多。事实上,为什么每次遍历列表和计数节点,尽管添加或删除节点时可以设置列表中节点的精确数量?
示例 3 比较了 CList 和 CiSingleList 类型的列表填充速度并计算了获得每个列表的大小所用的时间。
//--- Example 3 (nodes number) int iterations=1e7; // 10 million iterations //--- the new CList CList *p_mql_List=new CList; uint start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) { CNodeInt *p_node_int=new CNodeInt(rand()); p_mql_List.Add(p_node_int); } uint time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); int list_size=p_mql_List.Total(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_mql_List; //--- the new CiSingleList CiSingleList *p_sList=new CiSingleList; start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) p_sList.AddRear(rand()); time=GetTickCount()-start; // time spent, msec Print("\n=======the CiSingleList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); list_size=(int)p_sList.Size(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_sList;
日志中的结果如下所示:
KO 0 22:48:24 test_MQL5_List (EURUSD,H1) CK 0 22:48:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= JL 0 22:48:24 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2606 msec RO 0 22:48:24 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 0 msec LF 0 22:48:29 test_MQL5_List (EURUSD,H1) EL 0 22:48:29 test_MQL5_List (EURUSD,H1) =======the CiSingleList type list======= KK 0 22:48:29 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2356 msec NF 0 22:48:29 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 359 msec
获取大小的方法在 CList 列表中即时有效。通过这种方式,向列表添加节点也很快速。
在下一代码块(示例 4)中,我建议注意列表作为数据容器的一个主要不利方面 - 访问元素的速度。问题在于列表元素是线性访问的。在 CList 类中,以二元方式访问元素,这稍微降低了算法的劳动强度。
进行线性搜索时,劳动强度为 O(N)。以二元方式实施的搜索让劳动强度变为 log2(N)。
以下是访问数据集元素的代码的一个例子:
//--- Example 4 (speed of accessing the node) const uint Iter_arr[]={1e3,3e3,6e3,9e3,1e4,3e4,6e4,9e4,1e5,3e5,6e5}; for(uint i=0;i<ArraySize(Iter_arr);i++) { const uint cur_iterations=Iter_arr[i]; // iterations number uint randArr[]; // array of random numbers uint idxArr[]; // array of indexes //--- set the arrays size ArrayResize(randArr,cur_iterations); ArrayResize(idxArr,cur_iterations); CRandom myRand; // random number generator //--- fill the array of random numbers for(uint t=0;t<cur_iterations;t++) randArr[t]=myRand.int32(); //--- fill the array of indexes with random numbers (from 0 to 10 million) int iter_log10=(int)log10(cur_iterations); for(uint r=0;r<cur_iterations;r++) { uint rand_val=myRand.int32(); // random value (from 0 to 4 294 967 295) if(rand_val>=cur_iterations) { int val_log10=(int)log10(rand_val); double log10_remainder=val_log10-iter_log10; rand_val/=(uint)pow(10,log10_remainder+1); } //--- check the limit if(rand_val>=cur_iterations) { Alert("Random value error!"); return; } idxArr[r]=rand_val; } //--- time spent for the array uint start=GetTickCount(); //--- accessing the array elements for(uint p=0;p<cur_iterations;p++) uint random_val=randArr[idxArr[p]]; uint time=GetTickCount()-start; // time spent, msec Print("\n=======the uint type array======="); PrintFormat("Random accessing the array of elements %.1e has taken %d msec",cur_iterations,time); //--- the CList type list CList *p_mql_List=new CList; //--- fill the list for(uint q=0;q<cur_iterations;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_mql_List.Add(p_node_int); } start=GetTickCount(); //--- accessing the list nodes for(uint w=0;w<cur_iterations;w++) CNodeInt *p_node_int=p_mql_List.GetNodeAtIndex(idxArr[w]); time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Random accessing the list of nodes %.1e has taken %d msec",cur_iterations,time); //--- free the memory ArrayFree(randArr); ArrayFree(idxArr); delete p_mql_List; }
基于块操作结果,以下条目被打印到日志:
MR 0 22:51:22 test_MQL5_List (EURUSD,H1) QL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= IG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+003 has taken 0 msec QF 0 22:51:22 test_MQL5_List (EURUSD,H1) IQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= JK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+003 has taken 0 msec MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) QD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= GO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+003 has taken 0 msec QN 0 22:51:22 test_MQL5_List (EURUSD,H1) II 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= EP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+003 has taken 16 msec OR 0 22:51:22 test_MQL5_List (EURUSD,H1) OL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= FG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+003 has taken 0 msec CF 0 22:51:22 test_MQL5_List (EURUSD,H1) GQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CH 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+003 has taken 31 msec QJ 0 22:51:22 test_MQL5_List (EURUSD,H1) MD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= MO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+003 has taken 0 msec EN 0 22:51:22 test_MQL5_List (EURUSD,H1) MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+003 has taken 47 msec CR 0 22:51:22 test_MQL5_List (EURUSD,H1) KL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= JG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+004 has taken 0 msec GF 0 22:51:22 test_MQL5_List (EURUSD,H1) KR 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= MK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+004 has taken 343 msec GJ 0 22:51:22 test_MQL5_List (EURUSD,H1) GG 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= LO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+004 has taken 0 msec QO 0 22:51:24 test_MQL5_List (EURUSD,H1) MJ 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= NP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+004 has taken 1217 msec OS 0 22:51:24 test_MQL5_List (EURUSD,H1) KO 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the uint type array======= CP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+004 has taken 0 msec MG 0 22:51:26 test_MQL5_List (EURUSD,H1) ER 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the CList type list======= PG 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+004 has taken 2387 msec GK 0 22:51:26 test_MQL5_List (EURUSD,H1) OG 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the uint type array======= NH 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+004 has taken 0 msec JO 0 22:51:30 test_MQL5_List (EURUSD,H1) NK 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the CList type list======= KO 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+004 has taken 3619 msec HS 0 22:51:30 test_MQL5_List (EURUSD,H1) DN 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the uint type array======= RP 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+005 has taken 0 msec OD 0 22:52:05 test_MQL5_List (EURUSD,H1) GS 0 22:52:05 test_MQL5_List (EURUSD,H1) =======the CList type list======= DE 0 22:52:05 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+005 has taken 35631 msec NH 0 22:52:06 test_MQL5_List (EURUSD,H1) RF 0 22:52:06 test_MQL5_List (EURUSD,H1) =======the uint type array======= FI 0 22:52:06 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+005 has taken 0 msec HL 0 22:54:20 test_MQL5_List (EURUSD,H1) PD 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the CList type list======= FN 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+005 has taken 134379 msec RQ 0 22:54:20 test_MQL5_List (EURUSD,H1) JI 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the uint type array======= MR 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+005 has taken 15 msec NE 0 22:58:48 test_MQL5_List (EURUSD,H1) FL 0 22:58:48 test_MQL5_List (EURUSD,H1) =======the CList type list======= GE 0 22:58:48 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+005 has taken 267589 msec
您可以看到,随着列表大小的增加,随机访问列表元素用的时间也增加(图 16)。

图 16 随机访问数组和列表元素所用的时间
现在,让我们讨论用于存储和加载数据的方法。
基础列表类 CList 包含此类方法,但它们是虚拟的。因此,为了使用一个例子测试它们的运行,我们需要做一些准备。
我们应使用派生类 CIntList 继承 CList 类的能力。后者只有 1 个方法用于创建新的元素 CIntList::CreateElement()。
//+------------------------------------------------------------------+ //| CIntList class | //+------------------------------------------------------------------+ class CIntList : public CList { public: virtual CObject *CreateElement(void); }; //+------------------------------------------------------------------+ //| New element of the list | //+------------------------------------------------------------------+ CObject *CIntList::CreateElement(void) { CObject *new_node=new CNodeInt(); return new_node; }
我们还需要向派生节点类型 CNodeInt 添加虚拟方法 CNodeInt::Save() 和 CNodeInt::Load()。将从成员函数 CList::Save() 和 CList::Load() 分别调用它们。
结果,示例如下所示(图 5):
//--- Example 5 (saving list data) //--- the CIntList type list CList *p_int_List=new CIntList; int randArr[1000]; // array of random numbers ArrayInitialize(randArr,0); //--- fill the array of random numbers for(int t=0;t<1000;t++) randArr[t]=(int)myRand.int32(); //--- fill the list for(uint q=0;q<1000;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_int_List.Add(p_node_int); } //--- save the list to the file int file_ha=FileOpen("List_data.bin",FILE_WRITE|FILE_BIN); p_int_List.Save(file_ha); FileClose(file_ha); p_int_List.FreeMode(true); p_int_List.Clear(); //--- load the list from the file file_ha=FileOpen("List_data.bin",FILE_READ|FILE_BIN); p_int_List.Load(file_ha); int Loaded_List_size=p_int_List.Total(); PrintFormat("Nodes loaded from the file: %d",Loaded_List_size); //--- free the memory delete p_int_List;
在图表上运行脚本之后,以下条目将被添加到日志:
ND 0 11:59:35 test_MQL5_List (EURUSD,H1) As many as 1000 nodes loaded from the file.
这样,我们已经探讨了 CNodeInt 节点类型的数据成员的输入/输出方法的实施。
在下一节中,我们将探讨在使用 MQL5 时如何使用列表解决问题的例子。
在前一节中,我在讨论标准库类 CList 的方法时举出了几个例子。
现在,我将讨论使用列表来解决具体问题的例子。在这里,我必须再一次指出列表作为容器数据类型的优点。我们可以通过充分利用列表的灵活性这一优势来更加高效地处理代码。
4.1 处理图形对象
想象一下我们需要在图表中以程序方式创建图像对象。由于各种原因,可能有不同的对象出现在图表中。
我记得列表曾经如何帮助我用图形对象解决问题。我愿意与您分享这个经历。
我有一项按指定条件创建垂直线条的任务。按照条件,垂直线作为给定时间区间的界限,而时间区间的长度在每个案例中各有不同。据说,区间从来没有完整的形成过。
我研究了 EMA21 的行为,并且为该目的而收集了统计数据。
我对移动平均线的坡长特别感兴趣。例如,在向下运动中,通过记录移动平均线的负运动(即值减小)来确定起点,并在该点画一条垂直线。图 17 显示了为 EURUSD,H1 在 2013 年 9 月 5 日 16:00,在烛形建立时确定的这样一个点。

图 17 向下区间的第一个点
依据相反原则确定向下运动结束的第二个点 - 通过记录移动平均线的正运动,即值增大(图 18)。

图 18 向下区间的第二个点
因此,目标区间是从 2013 年 9 月 5 日 16:00 至 2013 年 9 月 6 日 17:00。
确定不同区间的系统可能更复杂,也可能更简单。这不是关键所在。重要的是这种处理图形对象同时收集统计数据的技术涉及列表的一个主要优势 - 组合的灵活性。
对于当前例子,我首先创建了一个 CVertLineNode 类型的节点,负责 2 个“垂直线”图形对象。
类定义如下:
//+------------------------------------------------------------------+ //| CVertLineNode class | //+------------------------------------------------------------------+ class CVertLineNode : public CObject { private: SVertLineProperties m_vert_lines[2]; // array of structures of vertical line properties uint m_duration; // frame duration bool m_IsFrameFormed; // flag of frame formation public: void CVertLineNode(void); void ~CVertLineNode(void){}; //--- set-methods void SetLine(const SVertLineProperties &_vert_line,bool IsFirst=true); void SetDuration(const uint _duration){this.m_duration=_duration;}; void SetFrameFlag(const bool _frame_flag){this.m_IsFrameFormed=_frame_flag;}; //--- get-methods void GetLine(SVertLineProperties &_vert_line_out,bool IsFirst=true) const; uint GetDuration(void) const; bool GetFrameFlag(void) const; //--- draw the line bool DrawLine(bool IsFirst=true) const; };
基本而言,此节点类型描述了一个框架(在这里解释为两条垂直线包含的若干烛形)。用若干垂直线属性、持续时间和格式标记组成的结构表示框架界限。
除了标准构造函数和析构函数以外,类还有几个 set- 和 get- 方法,以及用于在图表上绘制线条的方法。
让我提醒您,在我的例子中,垂直线条(框架)节点在出现表示向下运动开始的第一条垂直线以及表示向上运动开始的第二条垂直线时即可被视为已经形成。
使用脚本 Stat_collector.mq5,我在图表中显示了所有框架,并且统计了在过去的 2000 条柱中有多少个节点(框架)对应于某个持续时间。
为了说明,我创建了包含任意框架的 4 个列表。第一个列表包含最多 5 根烛形的框架,第二个列表包含最多 10 根烛形的框架,第三个列表包含最多 15 根烛形的框架,第四个列表包含烛形数量不限的框架。
NS 0 15:27:32 Stat_collector (EURUSD,H1) =======List #1======= RF 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 5 ML 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 65 HK 0 15:27:32 Stat_collector (EURUSD,H1) OO 0 15:27:32 Stat_collector (EURUSD,H1) =======List #2======= RI 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 10 NP 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 15 RG 0 15:27:32 Stat_collector (EURUSD,H1) FH 0 15:27:32 Stat_collector (EURUSD,H1) =======List #3======= GN 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 15 FG 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 6 FR 0 15:27:32 Stat_collector (EURUSD,H1) CD 0 15:27:32 Stat_collector (EURUSD,H1) =======List #4======= PS 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 20
如此一来,我得到下图(图 19)。为方便起见,第二条垂直框架线以蓝色显示。
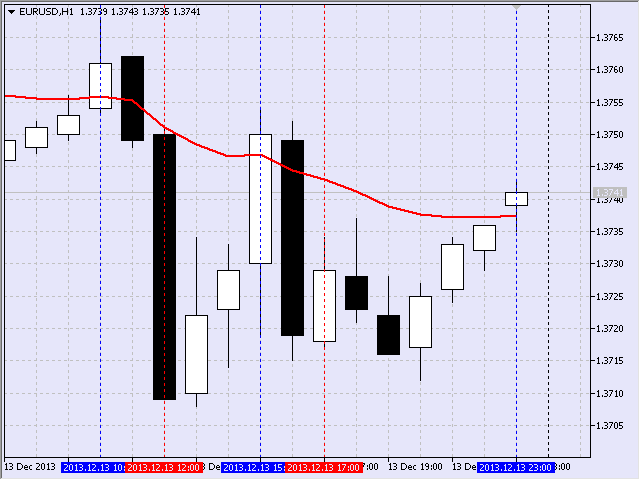
图 19 显示框架
说也奇怪,最后一个框架在 2013 年 12 月 13 日星期五的最后一小时形成。它属于第二个列表,因为它的持续时间为 6 小时。
4.2 处理虚拟交易
想象一下,您需要创建一个 EA 交易程序,在一个价格变动中对一种金融工具实施几种独立的策略。显然,在现实中,对于一种金融工具,一次只能实施一个策略。所有其他策略都将是虚拟的。那么,只能出于测试和优化交易理念的目的来实施它。
在这里,我必须引用一篇基础文章,该文一般性地详细描述了与交易有关的基本概念,并且尤其与 MetaTrader 5 客户端相关:"Orders, Positions and Deals in MetaTrader 5"(MetaTrader 5 中的订单、仓位和成交)。
因此,如果在解决这个问题的过程中,我们使用 MetaTrader 5 环境中常用的交易概念、交易对象管理系统和交易对象信息存储方法,则我们可能会想到创建一个虚拟数据库。
让我提醒您,开发人员将所有交易对象归类为订单、仓位、成交和历史订单。挑剔者可能注意到作者自己在这里使用了“交易对象”这一术语。这是千真万确的......
我建议在虚拟交易中使用类似的方法并得到以下虚拟交易对象:虚拟订单、虚拟仓位、虚拟成交和虚拟历史订单。
我认为这个主题值得深入且更加详细的讨论。同时,回到本文的主题,我要说容器数据类型,包括列表,在实施虚拟策略时会给编程者带来便利。
考虑新的虚拟仓位,很自然,它不能在交易服务器端。这意味着其相关信息应保存在客户端。在这里,可以用一个列表表示一个数据库,该列表又包含几个列表,其中一个列表将包含虚拟仓位节点。
使用开发人员的方法,将有以下用于虚拟交易的类:
类/组 |
说明 |
CVirtualOrder |
处理虚拟挂单的类 |
CVirtualHistoryOrder |
处理虚拟“历史”订单的类 |
CVirtualPosition |
处理虚拟未平仓位的类 |
CVirtualDeal |
处理虚拟“历史”成交的类 |
CVirtualTrade |
执行虚拟交易操作的类 |
表 1. 用于虚拟交易的类
我不会讨论任何虚拟交易类的组合。但是它很可能包含标准交易类的全部或几乎全部方法。我只是想指出开发人员使用的不是指定交易对象本身的一个类,而是其属性的一个类。
为了在您的算法中使用列表,您也需要节点。因此,我们需要在一个节点中打包虚拟交易对象的类。
假定虚拟未平仓位节点是 CVirtualPositionNode 类型。此类型的定义最初如下所示:
//+------------------------------------------------------------------+ //| Class CVirtualPositionNode | //+------------------------------------------------------------------+ class CVirtualPositionNode : public CObject { protected: CVirtualPositionNode *m_virt_position; // pointer to the virtual function public: void CVirtualPositionNode(void); // default constructor void ~CVirtualPositionNode(void); // destructor };
现在,当建立了虚拟仓位时,它可以被添加到虚拟仓位列表中。
我也要指出,处理虚拟交易对象的这种方法不需要使用缓存,因为数据库存储在随机存取存储器中。当然,您也可以安排将其存储在其他存储介质中。
在本文中,我力图说明容器数据类型,例如列表的优点。但是我也必须指出其缺点。无论如何,我希望这些信息能够帮助那些对面向对象编程进行一般性研究的人,尤其是那些具体研究其多态性(基础原理之一)的人。
文件位置:
以我的观点,最好在项目文件夹中创建和存储文件。例如,如下所示:%MQL5\Projects\UserLists。这是我保存所有源代码文件的地方。如果您使用默认目录,则您需要在某些文件的代码中更改包含文件指定方法(用尖括号代替引号)。
| # | 文件 | 位置 | 说明 |
|---|---|---|---|
| 1 | CiSingleNode.mqh | %MQL5\Projects\UserLists | 单向链表节点类 |
| 2 | CDoubleNode.mqh | %MQL5\Projects\UserLists | 双向链表节点类 |
| 3 | CiUnrollDoubleNode.mqh | %MQL5\Projects\UserLists | 松散双向链表节点类 |
| 4 | test_nodes.mq5 | %MQL5\Projects\UserLists | 含有节点处理例子的脚本 |
| 5 | CiSingleList.mqh | %MQL5\Projects\UserLists | 单向链表类 |
| 6 | CDoubleList.mqh | %MQL5\Projects\UserLists | 双向链表类 |
| 7 | CiUnrollDoubleList.mqh | %MQL5\Projects\UserLists | 松散双向链表类 |
| 8 | CiCircleDoublList.mqh | %MQL5\Projects\UserLists | 循环双向链表类 |
| 9 | test_sList.mq5 | %MQL5\Projects\UserLists | 含有单向链表处理例子的脚本 |
| 10 | test_dList.mq5 | %MQL5\Projects\UserLists | 含有双向链表处理例子的脚本 |
| 11 | test_UdList.mq5 | %MQL5\Projects\UserLists | 含有松散双向链表处理例子的脚本 |
| 12 | test_CdList.mq5 | %MQL5\Projects\UserLists | 含有循环双向链表处理例子的脚本 |
| 13 | test_MQL5_List.mq5 | %MQL5\Projects\UserLists | 含有 CList 类处理例子的脚本 |
| 14 | CNodeInt.mqh | %MQL5\Projects\UserLists | 整数类型节点的类 |
| 15 | CIntList.mqh | %MQL5\Projects\UserLists | CNodeInt 节点的列表类 |
| 16 | CRandom.mqh | %MQL5\Projects\UserLists | 随机数生成器的类 |
| 17 | CVertLineNode.mqh | %MQL5\Projects\UserLists | 处理垂直线条框架的节点类 |
| 18 | Stat_collector.mq5 | %MQL5\Projects\UserLists | 含有统计数据收集例子的脚本 |
参考文献:

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程





