所有交易者都愿意通过建立自己的交易系统,尽快或不久就能成长为分析师。他们长年累月地试图寻找市场的发展趋势并测试交易思路。可以根据不同的方法测试每一个思路, - 从策略测试员优化模式的最佳参数值搜索,转化为科学地 (有时是伪科学) 的市场研究。
在本文中,我建议研究统计假设- 一种用于研究和推理验证的统计分析工具。让我们来利用 Statistica 开发包测试不同的假设,以及使用移植的数值分析库 ALGLIB MQL5 的例子。
"统计假设" 的概念有若干定义。它们当中的一些涉及到有关正在研讨的对象或现象的统计特性的假设。
统计假设是有关概率规律,就一个问题的现象提出的假设。
其它定义点明了统计特性必须与一些随机变量的分布或这些分布的参数有关。
统计假设是关于统计分布参数或者随机变量分布原理的假设。
在数理统计的文献中,"假设" 的概念被解释为第二种方式。那么我们就可以区分:
在接下来的章节中,我们将讨论一种检验假设的方法。
被测试的假设称为零假设 (Н0)。一个竞争假设 (Н1) 是它的备选。它在 Н0 硬币的翻面, 即逻辑上它拒绝零假设。
试想一下,有一些交易系统的一组止损数据群落。我们将说明两个假设进行测试的基础。
Н0 – 平均止损值等于 30 点;
Н1 – 平均止损值不等于 30 点。
接受和拒绝假设的变种:
最后两个变种都与错误有关。
现在,显著级别值已经被指定。它是备选假设将被接受,而真正的假设是零假设 (第三变种) 的概率。此概率是首选最小化。
在我们的情况里,如果我们假定止损在平均不等于 30 点,即使它实际上是的时候,会发生这样的错误。
通常显著级别值 (α) 等于 0.05。这意味着,不超过百分之五的零假设测试统计值可以进入临界区。
在我们的情况里,测试统计值将在一个经典图表 (图例.1) 上进行评估。

图例.1. 按正常概率规律分布的测试统计值
若零假设被接受,测试统计值不应该到达红色区域。出于示例目的,让我们假设该测试统计值是正态分布。
每次测试都有自己的公式来计算测试统计值。
变种 4 意味着第二个类型 (β) 有个错误。在我们的情况里,如果我们假定止损在平均等于 30 点,不过实际不等于该点数时,会发生这样的错误。
用于示例的源数据保存在 Data.xls 文件里。
3.1. 依赖的样本测试
想象一下以下的情形。假设有一个交易系统生成交易群落。让我们从盈利交易中以 100 单位的交易量进行取样。源数据在 "Profits" 表单里。
除去异常数值之后,利润 样本的描述性统计列于表1:

表.1。盈利样本统计
样本直方图如下所示 (图例.2)。

图例.2. 盈利样本直方图
平均值是 83.4 点,中位数为 83 点。
如果入场点变化了几个点,会发生什么?例如,提高入场价格的挂单可以在出现交易信号后放置。
它将如何影响结果?这个问题可以用统计假设回答。
在 Statistica 开发包里我们正式地检查,是否样本并非取自一般群落:
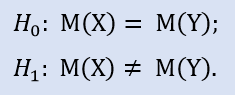
如果我们将入场点改变 15 点, 我们将接收到 NewProfits 样本。理想的结果图片应如下 (图例.3)。

图例.3. 盈利图表和 NewProfits 样本
由于样本中位数的不同,备选假设被接受的概率很高。
此图片, 无论如何, 很难获得,因为市场上没有更好的价格。在我的情况里,第二样本包括入场价格更改后的 84 笔交易。其它 15 笔交易根本没有执行。此修正样本将被命名为 NewProfitsReal。
在 "带胡须的箱子" 类型的图形里,两个样本之间没有很大不同。

图例.4. 盈利和 NewProfitsReal 样本图形
让我们用有关的样本进行一次非参数 Wilcoxon 标记等级测试。
结果在表 2:

表格 2. 盈利和 NewProfitsReal 样本的 Wilcoxon 测试结果
显著级别值非常高,这有利于零假设。
这样我们就可以说,改变入场点不影响系统的产率。它是相对而言。从绝对数字来看,系统因为错过了入场点,从而利润减少。
Wilcoxon 测试 可以用 MQL5 程序进行。虽然它与指定 m 值的分布中值相比,这种差异并不显著。
我们继续检查:
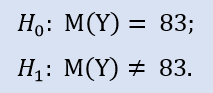
ALGLIB 库包括以下过程: CAlglib::WilcoxonSignedRankTest()。它给出了一个三种测试类型的结果: 双侧, 左侧和右侧。
脚本 test_profits.mq5 提供了一个计算例程。日志 "专家" 对于 NewProfitsReal 样本有如下结果:
OO 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the two-sided test: 0.7472 HD 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the left-sided test: 0.6285 CM 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the right-sided test: 0.3736
左侧测试的形式:
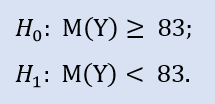
此处我们检查备选,因为 NewProfitsReal 样本的中值可以大于或等于 83。错误拒绝 H0 的概率是 0.63。所以 H0 被接受。
右侧测试如下所示:
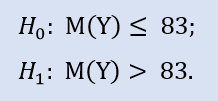
在测试中我们检查备选,即 NewProfitsReal 样本的中值可以小于或等于 83。错误拒绝 H0 的概率是 0.37。所以 H0 被接受。
3.2. 测试独立样本
假设我们要检查不同经纪公司处理交易订单的速度有多迅速,以及经纪公司之间有关的交易指令执行时间是否有差异。
这样,有两个源数据的样品用于分析。每个样品最初包含 50 个观测点。在删除异常情况之后, 48 观测点保留在第一个样本里 (经纪公司 А), 以及在第二个 (经纪公司 B) 里有 49 个观测点。数据可在 "ExecutionTime" 表单里找到。
我们继续检查:
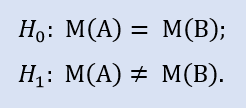
让我们图片上表示一个样本指数 (图例.5)。根据图形,中位数的值不同,虽然并不显著。

图例.5. 经纪公司 A 和 B 的数据样本图形
因为我们不知道每个样本所属的分布,我们将参照非参数测试进行比较。
例如,让我们实施 Mann — Whitney U-测试 (表 3)。它被认为最翔实。

表 3. Mann — Whitney U-经纪公司 A 和 B 的数据样本测试结果
结论: 检测结果不同,因此有关样本平等的零假设拒绝赞成 Н1。
Mann — Whitney U-测试 可以用 MQL5 程序进行。在 ALGLIB 库里有 CAlglib:: MannWhitneyUTest() 过程。它给出了一个三种测试类型的结果: 双侧, 左侧和右侧。
脚本 test_time_execution.mq5 提供了一个计算例程。日志 "专家" 里有以下结果可以用于样本比较:
MR 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the two sided test: 0.0001 QF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the left-sided test: 1.0000 PF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the right-sided test: 0.0001
左侧测试的形式:
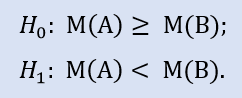
零假设是经纪公司 A 的数据样本可以大于或等于经纪公司 B 的数据样本。备选是其被拒。错误拒绝 H0 的概率是 1.0。所以 H0 被接受。
右侧测试如下所示:
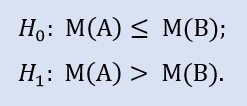
零假设是经纪公司 A 的数据样本可以小于或等于经纪公司 B 的数据样本。备选是其被拒。
错误拒绝 H0 的概率是 0.0。所以 H0 拒绝赞成 Н1。
3.3. 关联测试
想象一个策略组合。目标是降低组合里的策略数量。
选择标准如下: 如果两个策略同样比较止损, 则策略之一将被从组合里删除。让我们取两个带止损的不同系统作为两个样本。假设: 系统入场反应方式相同,但离场反应不同。
我们将使用 Spearman 的等级-顺序关联测试。此处有三个样本在数据文件 "Correlation" 表单里。
检查是否关联系数等于零:
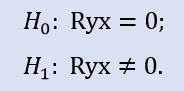
比较 Stops1-Stops2 样本对将给出以下结果 (表 4)。

表 4. 对于 Stops1 和 Stops2 样本的 Spearman 等级-顺序关联测试
在此情况下,关于样本元素之间缺乏关联的零假设不能拒绝赞成备选。所以它被接受。
图例.6 中的图形显示出数据不能形成任何明显配置。相反,数据分散在整个平面图。

图例.6. Stops1 和 Stops2 样本的散布图
Stops1-Stops3 样本之间的关系检查结果显示在表 5:

表 5. 对于 Stops1 和 Stops3 样本的 Spearman 等级-顺序关联测试结果
在此情况下, 零假设被拒因为错误概率太低。
因此,有关存在关系的备选被接受。关系如下所示 (图例.7)。

图例.7. Stops1 和 Stops3 样本的散布图
确认结果的 MQL5 代码。test_correlation.mq5 包含一个计算例程。
ALGLIB 库包括过程 CAlglib::SpearmanRankCorrelationSignificance(), 它实现了 Spearman 等级-顺序关联性系数 显著性测试。
日志包括以下记录:
OO 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops2===--- GO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.9840 KK 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.4920 JJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.5080 DM 0 12:57:43.545 test_correlation (EURUSD.e,H1) HJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops3===--- NS 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.0002 RO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.9999 FG 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.0001
左侧测试的形式:
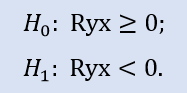
在此测试中,变量之间存在非负关联 (即, 关联系数为零或负) 的零假设被验证。
左侧测试表明 Stops1-Stops2 样本对的零假设被接受。左侧测试表明 Stops1-Stops3 样本对的零假设也被接受。一个逻辑问题会问 "为什么 Stops1-Stops2 样本之间没连接, 而 Stops1-Stops3 之间则有?" 其原因是检查结果 "大于或等于零"。在第一种情况下, "等于零" 对于 H0 很重要, 且在第二情况下, 则是 "大于零"。
右侧测试如下所示:
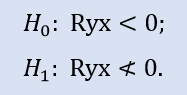
此处,是不是负关联的零假设被测试。
对于样本对 Stops1-Stops2, 右侧测试显示零假设被接受。对于样本对 Stops1-Stops3 右侧测试显示零假设被拒。
最后一个注释。测试显示,样本 Stops1-Stops3 之间有正相关概率。这种关联的强度是平均水平。因此它将由交易者决定是否拒绝策略 1 或 3。
在本文中,我尝试用实例表明,量化变量可以用数理统计进行评估。我希望新晋开发员能发现这篇文章对他们未来的交易系统非常有用。我也希望有关使用数理统计方法的文章系列能够继续。
库文件 ALGLIB 需要单独下载。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







