当交易者开始掌握 OpenCL 的时候, 他们会面临在哪里使用它的问题。在指标或自动化交易系统的开发中,没有广泛使用矩阵乘法或大量数据排序等示例。另一种通用应用程序 — 操作神经网络 — 需要该领域的一定知识,学习神经网络对于普通程序人员可能会耗费很多时间,并且不能保证在交易中的结果。这种情况可能会使那些想在解决基本任务时感受到 OpenCL 的全部功能的人失望。
在这篇文章中,我们将会探讨使用 OpenCL 来解决算法交易中的简单任务 — 寻找烛形形态并在历史中测试它们。我们将会开发用于在单次通过测试中的算法,并且在“1分钟OHLC”交易模式下优化两个参数。随后,我们将会比较内建策略测试器和使用OpenCL的效率来发现它们之中哪个更快(以及到何种程度)。
本文假定读者已经对 OpenCL 基础较为熟悉,如果不是,我推荐阅读 "OpenCL: 连接并行世界的桥梁" 和 "OpenCL: 从朴素到更具深度的编程" 这两篇文章。最好手边有 OpenCL 说明书版本 1.2 。这篇文章将致力于构建测试器的算法,而不会专注于 OpenCL 的编程基础。
我们需要依赖一些东西来确保使用OpenCL实现的测试器是正确工作的。首先,我们需要开发一个 MQL5 EA,然后我们将会比较使用常规测试器优化和测试与使用OpenCL的测试器的结果。
策略非常简单:
只在完全关闭的柱上检查是否有形态的出现,换句话说, 我们在新柱出现的时候就检查前面三个柱是否形成形态,
形态的侦测条件如下:

图 1. "看跌针杆" (a) 和 "看涨针杆" (b) 形态
对于看跌针杆 (图 1, a):
对于看涨针杆 (图 1, b):
tail = min(Open[1],Close[1])-Low[1]

图 2. "看跌吞噬" (a) 和 "看涨吞噬" (b)
对于看跌吞噬 (图 2, a):
对于看涨吞噬 (图 2, b):
ENUM_PATTERN Check(MqlRates &r[],uint flags,double ref) { //--- 看跌针杆 if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-MathMax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>MathMax(H(0),H(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- 看涨针杆 if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=MathMin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<MathMin(L(0),L(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- 看跌吞噬 if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- 看涨吞噬 if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- 没有找到 return PAT_NONE; }
这里我们应当注意 ENUM_PATTERN 枚举,它的值是标志,可以组合并使用 bitwise OR(位或) 作为一个参数来传递:
enum ENUM_PATTERN { PAT_NONE=0, PAT_PINBAR_BEARISH = (1<<0), PAT_PINBAR_BULLISH = (1<<1), PAT_ENGULFING_BEARISH = (1<<2), PAT_ENGULFING_BULLISH = (1<<3) };
另外, 引入了下面的宏定义来更方便地记录:
#define O(i) (r[i].open) #define H(i) (r[i].high) #define L(i) (r[i].low) #define C(i) (r[i].close)
Check() 函数是从 IsPattern() 函数中调用的,意义是检查在新柱开启时是否存在指定的形态:
ENUM_PATTERN IsPattern(uint flags,uint ref) { MqlRates r[]; if(CopyRates(_Symbol,_Period,1,PBARS,r)<PBARS) return 0; ArraySetAsSeries(r,false); return Check(r,flags,double(ref)*_Point); }
首先,需要定义输入参数,我们在形态定义条件中有一个参考值,这是针杆的“tail”的最小长度,或者是吞噬中的主体相交区域的最小长度,我们将以点数指定它:
input int inp_ref=50;
另外,我们还有一系列形态的参数,为了更加方便,我们将不会在输入参数中使用标志,而是把它分成了四个 bool 类型的参数:
input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true;
然后再在初始化函数中把它们组合成一个无符号整型变量:
p_flags = 0; if(inp_bullish_pin_bar==true) p_flags|=PAT_PINBAR_BULLISH; if(inp_bearish_pin_bar==true) p_flags|=PAT_PINBAR_BEARISH; if(inp_bullish_engulfing==true) p_flags|=PAT_ENGULFING_BULLISH; if(inp_bearish_engulfing==true) p_flags|=PAT_ENGULFING_BEARISH;
下面, 我们设置可以接收的仓位持有时间, 以小时表示, 获利和止损水平, 以及交易量手数:
input int inp_timeout=5; input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true; input double inp_lot_size=1;对于交易, 我们将使用来自标准库 的 CTrade 类,为了定义测试器的速度, 我们将使用 CDuration 类, 它可以衡量程序中两个控制点的时间间隔的毫秒数, 并且以方便的形式显示它们。在这种情况下,我们将测量在 OnInit() 和 OnDeinit() 函数之间的时间。类的完整代码包含在附加的 Duration.mqh 文件中。
CDuration time; int OnInit() { time.Start(); // ... return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { time.Stop(); Print("测试结束 "+time.ToStr()); }
这个EA的工作非常简单,包含以下内容:
OnTick() 函数的主要任务是处理开启的仓位。如果仓位的持有时间超过了在输入参数中指定的数值,就关闭该仓位。然后,检查是否有新柱开启,如果检查通过,就使用 IsPattern () 函数来检查形态是否存在。当找到形态时,根据策略开启一个买入或者卖出仓位。完整的 OnTick() 函数代码在下面提供:
void OnTick() { //--- 处理开启的仓位 int total= PositionsTotal(); for(int i=0;i<total;i++) { PositionSelect(_Symbol); datetime t0=datetime(PositionGetInteger(POSITION_TIME)); if(TimeCurrent()>=(t0+(inp_timeout*3600))) { trade.PositionClose(PositionGetInteger(POSITION_TICKET)); } else break; } if(IsNewBar()==false) return; //--- 检查形态是否存在 ENUM_PATTERN pat=IsPattern(p_flags,inp_ref); if(pat==PAT_NONE) return; //--- 开启仓位 double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); if((pat&(PAT_ENGULFING_BULLISH|PAT_PINBAR_BULLISH))!=0)//买入 trade.Buy(inp_lot_size,_Symbol,ask,NormalizeDouble(ask-inp_sl*_Point,_Digits),NormalizeDouble(ask+inp_tp*_Point,_Digits),DoubleToString(ask,_Digits)); else//卖出 trade.Sell(inp_lot_size,_Symbol,bid,NormalizeDouble(bid+inp_sl*_Point,_Digits),NormalizeDouble(bid-inp_tp*_Point,_Digits),DoubleToString(bid,_Digits)); }
首先,运行优化以寻找对EA来说交易获利或者至少开启仓位的最佳输入参数值。我们将优化两个参数 — 形态使用的参考值和止损水平点数。把获利水平设为50个点,并在测试中选择所有形态。
优化是在 EURUSD M5 上进行的,时间段为: 01.01.2018 — 01.10.2018. 快速优化 (遗传算法), 交易模式: "1 分钟 OHLC".
优化参数的数值在大范围内和大量的梯度中选择:
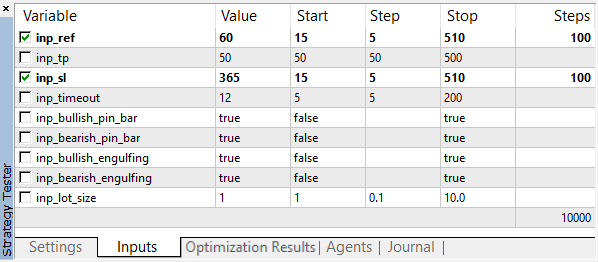
图 3. 优化参数
在优化结束之后,结果根据利润排序:
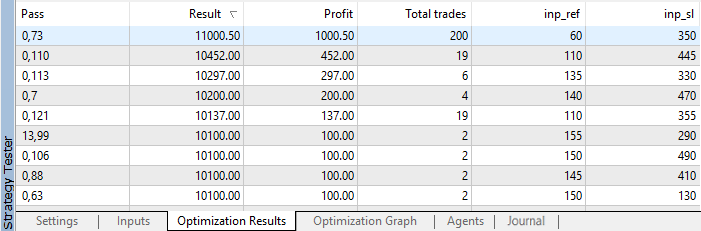
图 4. 优化结果
我们可以看到,获得1000.50 利润的最佳结果是在参考值为60个点而止损水平为350个点的时候取得的。在使用这些参数时运行测试并注意它的执行时间。
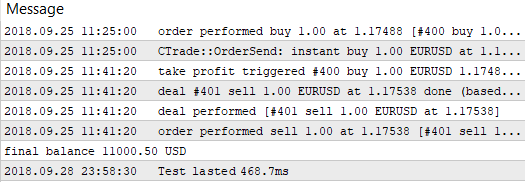
图 5. 使用内建测试器的单次通过测试时间
记住这些数值,在继续不使用常规测试器来测试相同的策略。让我们使用 OpenCL 的特性开发一个自定义的测试器。
为了操作 OpenCL, 我们将使用来自标准库的 COpenCL 类,并作一些小的修改。改进的目标是在错误发生时取得尽可能多的信息。但是,当这样做的时候,我们不能通过条件和向控制台输出数据来重载代码,如需这样做,要创建 COpenCLx 类,它的完整代码可以在下面附加的 OpenCLx.mqh 文件中找到:
class COpenCLx : public COpenCL { private: COpenCL *ocl; public: COpenCLx(); ~COpenCLx(); STR_ERROR m_last_error; // 最近的错误结构 COCLStat m_stat; // OpenCL 统计 //--- 操作缓冲区 bool BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line); template<typename T> bool BufferFromArray(const ENUM_BUFFERS buffer_index,T &data[],const uint data_array_offset,const uint data_array_count,const uint flags,const string function,const int line); template<typename T> bool BufferRead(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); template<typename T> bool BufferWrite(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); //--- 设置参数 template<typename T> bool SetArgument(const ENUM_KERNELS kernel_index,const int arg_index,T value,const string function,const int line); bool SetArgumentBuffer(const ENUM_KERNELS kernel_index,const int arg_index,const ENUM_BUFFERS buffer_index,const string function,const int line); //--- 操作内核 bool KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line); bool Execute(const ENUM_KERNELS kernel_index,const int work_dim,const uint &work_offset[],const uint &work_size[],const string function,const int line); //--- bool Init(ENUM_INIT_MODE mode); void Deinit(void); };
我们可以看到,这个类包含了指向 COpenCL 对象的指针, 以及用于封装的几个与 COpenCL 类方法同名的方法。这些方法中的每一个都有函数名和调用参数的字符串。另外,使用了枚举而不是内核索引和缓冲区,这样做是为了在错误信息中使用 EnumToString(),它比一个索引值能提供更多的信息。
让我们更加详细地讨论其中的一个方法。
bool COpenCLx::KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL 对象不存在",function,line); return false; } //--- 运行内核执行 ::ResetLastError(); if(!ocl.KernelCreate(kernel_index,kernel_name)) { string comment="Failed to create kernel "+EnumToString(kernel_index)+", name \""+kernel_name+"\""; SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_KERNEL_CREATE,comment,function,line); return(false); } //--- return true; }
这里有两项检查: 看 COpenCL 类对象是否存在以及内核创建方法是否成功。但是没有使用 Print() 函数来显示文字,消息是使用宏定义来传递的,包含错误代码、函数名称和调用字符串。这些宏定义会在 m_last_error 类中保存错误信息,它的结构显示如下:
struct STR_ERROR { int code; // 代码 string comment; // 注释 string function; // 出现错误的函数 int line; // 出现错误的字符串信息 };
一共有四个这样的宏定义,让我们挨个讨论它们。
SET_ERR 宏记录最近的执行错误, 函数和调用它的代码行,以及注释作为传入参数。
#define SET_ERR(c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
SET_ERRx 宏和 SET_ERR 类似:
#define SET_ERRx(c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
区别就是函数名和字符串以参数的方式传入,为什么要这样做呢?假定错误发生在 KernelCreate() 方法中,当使用 SET_ERR 宏的时候,我们可以看到 KernelCreate() 方法的名称,但是如果能知道方法是从哪里调用的会更加有用,为了取得这一点,我们把函数和调用的方法代码作为参数传入到宏定义中。
后面是 SET_UERR 宏定义,它对记录自定义错误很有意义:
#define SET_UERR(err,c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
在这个宏中,错误代码是作为参数传入的,而不是调用的 GetLastError(),在其它方面,它与 SET_ERR 宏相同。
SET_UERRx 宏是用于记录自定义错误的,并且把函数名和调用代码作为参数传入:
#define SET_UERRx(err,c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
这样,如果出现错误,我们就有了所有所需的信息,和从 COpenCL 类中把错误发送到控制台不同,这是目标内核的 规格,以及出现的错误是从哪里调用的。从 COpenCL 类 (上面的文字行) 的输出与从 COpenCLx 类扩展输出 (下面的两行) 的简单比较:

图 6. 内核创建错误
让我们探讨另一个封装方法的例子: 创建缓冲区的方法:
bool COpenCLx::BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL 对象不存在",function,line); return false; } //--- 探索和检查空闲内存 if((m_stat.gpu_mem_usage+=size_in_bytes)==false) { CMemsize cmem=m_stat.gpu_mem_usage.Comp(size_in_bytes); SET_UERRx(UERR_NO_ENOUGH_MEM,"没有空闲 GPU 内存,不够 "+cmem.ToStr(),function,line); return false; } //--- 创建缓冲区 ::ResetLastError(); if(ocl.BufferCreate(buffer_index,size_in_bytes,flags)==false) { string comment="创建缓冲区失败 "+EnumToString(buffer_index); SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_BUFFER_CREATE,comment,function,line); return(false); } //--- return(true); }
除了检查 COpenCL 类对象是否存在以及运行结果,它还包含了用于计数的函数和检查空闲内存。因为我们处理相对大量的内存 (几百兆), 我们需要控制它使用的过程,这个任务就指派给 СMemsize 了。完整的代码包含在 Memsize.mqh 文件中,
但是,有一个缺点,尽管调试容易,代码变得臃肿了,例如,创建缓冲区的代码看起来如下:
if(BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE,__FUNCTION__,__LINE__)==false) return false;
有太多没必要的信息,使得难以专注到算法上,这里可以再次使用宏来解决。每个封装方法都使用宏来复制,调用起来更加紧凑了。对于 BufferCreate() 方法, 就是 _BufferCreate 宏:
#define _BufferCreate(buffer_index,size_in_bytes,flags) \ if(BufferCreate(buffer_index,size_in_bytes,flags,__FUNCTION__,__LINE__)==false) return false
感谢宏,调用创建缓冲区方法就可以使用这种形式了:
_BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
创建内核看起来如下:
_KernelCreate(k_FIND_PATTERNS,"find_patterns");
大多数这些宏是以 return false 结束, 而 _KernelCreate 是以 break 来结束的。这在开发代码的时候应当探讨,所有的宏都在 OCLDefines.mqh 文件中定义。
这个类也包含初始化和终止化方法。除了创建 COpenCL 类对象, 前者还检查了对 'double' 的支持, 创建内核以及取得可用的内存大小:
bool COpenCLx::Init(ENUM_INIT_MODE mode) { if(ocl) Deinit(); //--- 创建 COpenCL 类的对象 ocl=new COpenCL; while(!IsStopped()) { //--- 初始化 OpenCL ::ResetLastError(); if(!ocl.Initialize(cl_tester,true)) { SET_ERR("OpenCL 初始化错误"); break; } //--- 检查是否支持操作 'double' 类型 if(!ocl.SupportDouble()) { SET_UERR(UERR_DOUBLE_NOT_SUPP,"这个设备不支持操作 double (cl_khr_fp64) "); break; } //--- 设置内核数量 if(!ocl.SetKernelsCount(OCL_KERNELS_COUNT)) break; //--- 创建内核 if(mode==i_MODE_TESTER) { _KernelCreate(k_FIND_PATTERNS,"find_patterns"); _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_ORDER_TO_M1,"order_to_M1"); _KernelCreate(k_TESTER_STEP,"tester_step"); }else if(mode==i_MODE_OPTIMIZER){ _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_TESTER_OPT_PREPARE,"tester_opt_prepare"); _KernelCreate(k_TESTER_OPT_STEP,"tester_opt_step"); _KernelCreate(k_FIND_PATTERNS_OPT,"find_patterns_opt"); } else break; //--- 创建缓冲区 if(!ocl.SetBuffersCount(OCL_BUFFERS_COUNT)) { SET_UERR(UERR_SET_BUF_COUNT,"创建缓冲区失败"); break; } //--- 取得 RAM 大小 long gpu_mem_size; if(ocl.GetGlobalMemorySize(gpu_mem_size)==false) { SET_UERR(UERR_GET_MEMORY_SIZE,"取得 RAM 值失败"); break; } m_stat.gpu_mem_size.Set(gpu_mem_size); m_stat.gpu_mem_usage.Max(gpu_mem_size); return true; } Deinit(); return false; }
mode 参数设置了初始化的模式,这里可以是优化或者单次测试,可以根据它来创建各种内核,
内核和缓冲区的枚举是在 OCLInc.mqh 文件中定义的,内核的源代码是作为资源附加在那里的,就像 cl_tester 字符串。
Deinit() 方法会删除 OpenCL 程序和对象:
void COpenCLx::Deinit() { if(ocl!=NULL) { //--- 删除 OpenCL 对象 ocl.Shutdown(); delete ocl; ocl=NULL; } }
现在所有辅助的内容都开发好了,是时候开始主体工作了,我们已经有了相对紧凑的代码和有关错误的容易理解的信息,
但是首先我们需要上传所需要处理的数据,这在第一眼看来没有那么简单。
CBuffering 类会上传数据。
class CBuffering { private: string m_symbol; ENUM_TIMEFRAMES m_period; int m_maxbars; uint m_memory_usage; //使用内存的量 bool m_spread_ena; //上传点差缓冲区 datetime m_from; datetime m_to; uint m_timeout; //上传超时的毫秒数 ulong m_ts_abort; //当运行应当被打断的时间毫秒数 //--- 强制上传 bool ForceUploading(datetime from,datetime to); public: CBuffering(); ~CBuffering(); //--- 缓冲区中的数据量 int Depth; //--- 缓冲区 double Open[]; double High[]; double Low[]; double Close[]; double Spread[]; datetime Time[]; //--- 取得上传数据的实时边界 datetime TimeFrom(void){return m_from;} datetime TimeTo(void){return m_to;} //--- int Copy(string symbol,ENUM_TIMEFRAMES period,datetime from,datetime to,double point=0); uint GetMemoryUsage(void){return m_memory_usage;} bool SpreadBufEnable(void){return m_spread_ena;} void SpreadBufEnable(bool ena){m_spread_ena=ena;} void SetTimeout(uint timeout){m_timeout=timeout;} };
我们将不会非常深入地讨论它,因为数据的上传与当前主题没有直接的关系,但是,我们应当简要探讨它的应用。
这个类包含了 Open[], High[], Low[], Close[], Time[] 和 Spread[] 缓冲区,您可以在 Copy() 方法成功结束后操作它们。请注意,Spread[] 缓冲区是 'double' 类型的,不是以点数表示的,而是以价格之差表示的。另外,初始时复制 Spread[] 缓冲区是禁止的,如果需要,应当使用 SpreadBufEnable() 方法来启用。
Copy() 方法是用于上传的,预先设置的 point 参数只是用于把点数的点差重新计算为价格之差,如果点差的复制是关闭的,这个参数也就不会使用。
创建单独的类来上传数据的主要原因是:
CBuffering 类可以复制超过 TERMINAL_MAXBARS 的大量数据, 也可以初始化丢失数据从服务器的上传并等待它结束。因为有这种等待,我们需要注意 SetTimeout() 方法,它是用于设置上传时间 (包括等待) 的毫秒数。默认情况下,类的构造函数中它等于 5000 (5秒),把超时设为0就是禁用它,这不是我们想要的,但是在一些情况下可能会有用。
但还是有一些限制:M1时段的数据上传不能超过一年,这在一定程度上使我们的测试器范围变窄了。
单个测试包含下面的要点:
CBuffering 下载时间序列,然后这些数据应当被复制到 OpenCL 缓冲区中,这样内核就能对它们进行操作。这项任务是由 LoadTimeseriesOCL() 方法来完成的。它的代码在下面提供:
bool CTestPatterns::LoadTimeseriesOCL() { //--- 开盘价缓冲区: _BufferFromArray(buf_OPEN,m_sbuf.Open,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- 最高价缓冲区: _BufferFromArray(buf_HIGH,m_sbuf.High,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- 最低价缓冲区: _BufferFromArray(buf_LOW,m_sbuf.Low,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- 收盘价缓冲区: _BufferFromArray(buf_CLOSE,m_sbuf.Close,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- 时间缓冲区: _BufferFromArray(buf_TIME,m_sbuf.Time,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Open (M1) 缓冲区: _BufferFromArray(buf_OPEN_M1,m_tbuf.Open,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- High (M1) 缓冲区: _BufferFromArray(buf_HIGH_M1,m_tbuf.High,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Low (M1) 缓冲区: _BufferFromArray(buf_LOW_M1,m_tbuf.Low,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Close (M1) 缓冲区: _BufferFromArray(buf_CLOSE_M1,m_tbuf.Close,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Spread (M1) 缓冲区: _BufferFromArray(buf_SPREAD_M1,m_tbuf.Spread,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Time (M1) 缓冲区: _BufferFromArray(buf_TIME_M1,m_tbuf.Time,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- 复制成功 return true; }
这样数据就被下载下来了,现在是时候实现测试算法了。
使用 OpenCL 的形态定义的代码与使用 MQL5 的代码没有很大区别:
//--- 形态 #define PAT_NONE 0 #define PAT_PINBAR_BEARISH (1<<0) #define PAT_PINBAR_BULLISH (1<<1) #define PAT_ENGULFING_BEARISH (1<<2) #define PAT_ENGULFING_BULLISH (1<<3) //--- 价格 #define O(i) Open[i] #define H(i) High[i] #define L(i) Low[i] #define C(i) Close[i] //+------------------------------------------------------------------+ //| 检查形态是否存在 | //+------------------------------------------------------------------+ uint Check(__global double *Open,__global double *High,__global double *Low,__global double *Close,double ref,uint flags) { //--- 看跌针杆 if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-fmax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>fmax(H(0),H(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- 看涨针杆 if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=fmin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<fmin(L(0),L(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- 看跌吞噬 if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- 看涨吞噬 if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- 没有找到 return PAT_NONE; }
有一点小的区别就是缓冲区是通过指针、而不是通过引用来传输的。另外,还有一个 __global 转义符, 它指出时间序列缓冲区是在全局内存中的,所有我们要创建的 OpenCL 缓冲区都是在全局内存中的。
Check() 函数调用 find_patterns() 内核:
__kernel void find_patterns(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global int *Order, // 订单缓冲区 __global int *Count, // 缓冲区中的订单数量 const double ref, // 形态参数 const uint flags) // 寻找哪些形态 { //--- 在一个维度上工作 //--- 柱的索引 size_t x=get_global_id(0); //--- 形态搜索的空间大小 size_t depth=get_global_size(0)-PBARS; if(x>=depth) return; //--- 检查形态是否存在 uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref,flags); if(res==PAT_NONE) return; //--- 设置订单 if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) {//卖出 int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL; } else if(res==PAT_PINBAR_BULLISH || res==PAT_ENGULFING_BULLISH) {//买入 int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_BUY; } }
我们将会使用它来搜索形态,并且在特别设计好的缓冲区中设置订单。
find_patterns() 内核是在一维的任务空间中工作的,在运行时,我们将在维度0上创建在任务空间中指定数量的工作项,在本例中,它就是当前时段的柱数。为了了解哪个柱正在被处理,您需要取得任务的索引:
size_t x=get_global_id(0);
其中0是度量索引。
Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL;
为了取得订单的序列号,使用 atomic_inc() 原子函数。当执行一项任务时,我们不知道哪个任务以及哪些柱已经完成了,这里是并行计算的,并且在任何地方都没有绝对的顺序。任务的索引与已经完成任务的数量没有关系,所以,我们不知道在缓冲区中已经设置了多少订单。如果我们尝试在 Count [] 缓冲区中读取第0单元,另一个任务可能正在同时向那里写入某些内容, 为了避免这一点,我们要使用原子函数。
在我们的例子中,atomic_inc() 函数可以禁止其它任务访问 Count[0] 单元。在那之后,它会把它的数值增加1,而在结果中返回它之前的值。
int i=atomic_inc(&Count[0]);
当然,这会使工作变慢, 因为其它任务必须等待直到 Count[0] 的访问解除锁定,但是在一些情况下(就像我们的),没有其它的方案。
在完成了所有的任务之后,我们可以从 Order[] 缓冲区中取得生成的订单,以及从 Count[0] 单元中取得它们的数量。
这样,我们就在当前时段中找到了形态,而测试应当在 M1 时间框架下进行。这就意味着在当前时段上找到的所有入场点要在M1中找到对应的柱。因为交易形态即使在较小的时间框架中提供的也是相对较少数量的入场点,我们将选择较为粗略但是非常适合的方法 — 枚举。我们将比较每个找到的订单中的时间和M1时间框架下柱的时间,为此,我们创建 order_to_M1() 内核:
__kernel void order_to_M1(__global ulong *Time,__global ulong *TimeM1, __global int *Order,__global int *OrderM1, __global int *Count, const ulong shift) // time shift in seconds { //--- 在二维中工作 size_t x=get_global_id(0); //index of Time index in Order if(OrderM1[x*2]>=0) return; size_t y=get_global_id(1); //index in TimeM1 if((Time[Order[x*2]]+shift)==TimeM1[y]) { atomic_inc(&Count[1]); //--- 设置在 TimeM1 缓冲区中的偶数索引 OrderM1[x*2]=y; //--- 在奇数索引中设置操作 (OP_BUY/OP_SELL) OrderM1[(x*2)+1]=Order[(x*2)+1]; } }
在此我们就有了二维的任务空间,第0维空间大小等于设置订单的数量,而第1维空间的大小等于M1时段的柱的数量。当一个订单的开启时间与 M1 柱的时间重合时,当前订单的操作就复制到 OrderM1[] 缓冲区,并且在M1时段的时间序列中设置侦测到的柱的索引。
有两件东西乍一看来不应该存在,
为此有一些特别的原因。世界不是完美无缺的,在 M5 图表上的柱形,开启时间为 01:00:00 并不意味着在 M1 图表上存在相同开启时间的柱。
在M1图表中对应的柱可能开启时间为 01:01:00, 或者 01:04:00。换句话说,变量等于时间框架时间的比率。所以引入了在 M1 图表中侦测入场点数量的函数:
atomic_inc(&Count[1]);
如果在内核运行完成之后,在M1图表中找到的订单的数量等于在当前时间看框架下侦测到的订单数量,就表示任务已经全部完成,否则,就使用另一个 shift 参数来重新开始。可能会有当前时段所包含的M1时段数量的重新开始次数,
引入了下面的检查来确保侦测到的入场点在重新以非零 shift 参数开始时不会被重写:
if(OrderM1[x*2]>=0) return;
为了使它有效,要在运行内核之前使用 -1 填充 OrderM1[] 缓冲区,为此,创建了 array_fill() 填充缓冲区的内核:
__kernel void array_fill(__global int *Buf,const int value) { //--- 在一个维度上工作 size_t x=get_global_id(0); Buf[x]=value; }
在找到了 M1 上的入场点之后,我们就可以开始取得交易结果了,为此,我们需要一个内核来管理开启的仓位,换句话说,我们应当等到它们因为下面四种原因之一被关闭:
内核的任务是一维的,而它的大小等于订单的数量。内核要在从开启仓位的柱形开始迭代,并检查上面所描述的条件。在柱内,分时是使用 "1 分钟 OHLC" 模式模拟的,在文档的 "测试交易策略" 部分有所介绍。
重要的是一些仓位在开启后很快就关闭,而有些会晚点关闭,而其它一些可能因为超时关闭或者测试结束才关闭。这就表示任务在不同入场点的执行时间会有很大差异。
实际应用中显示,在一次通过中处理一个仓位效率不高,相反,把测试空间 (在根据仓位持有时间超时时的柱数) 分成几个部分而在多个通过中处理,从效率角度会有更好的结果。
在当前通过中没有完成的任务可以推迟到下一个通过,这样, 在每个通过中任务空间的大小就减小了。但是为了实现这一点,您需要使用另一个缓冲区来保存任务索引。每个任务都在订单缓冲区中有入场点索引,在第一次运行的时候,任务缓冲区的内容就完全对应着订单缓冲区,在下一次运行时,它将包含订单的索引,以及还没有关闭的仓位的索引。为了操作任务缓冲区并同时把任务保存到下一次运行,它应当有两个存储体: 一个在当前运行时使用,而另一个用于构建下一次运行的任务。
在实际工作中,看起来是这样的:假定我们有1000个入场点,我们需要从中取得交易结果,仓位的持有时间相当于800个柱,我们决定把测试分成四个通过过程,则在图形上它显示如图7所示。
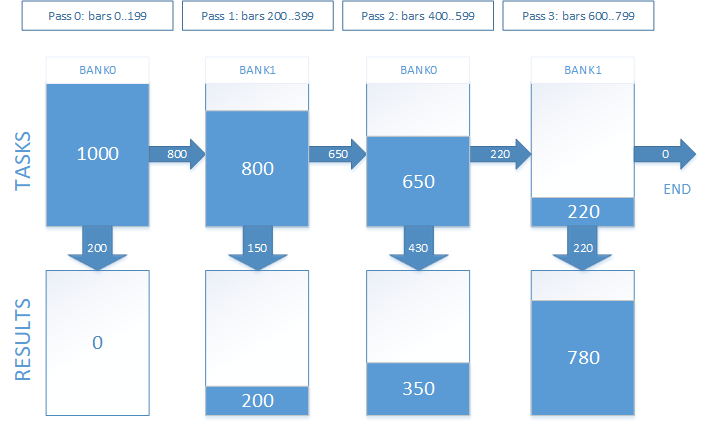
图 7. 在多个通过中跟踪开启的仓位
通过尝试和改错,我们已经确定,对于持仓超时时间为12个小时(或者720个分钟柱)的最佳的通过数等于8,这就是默认值。它根据不同的超时数值和OpenCL设备会有所变化。推荐全部选中以获得最高的效率。
这样,Tasks[] 缓冲区和任务存储体的索引会在时间序列之外加到内核的参数中,另外,我们还加上了 Res[] 缓冲区用于保存结果。
在任务缓冲区中的实际数据量是通过 Left[] 缓冲区返回的,它对于每个存储体有两个元素的大小 — 分别针对每个存储体。
因为测试是分成部分进行的,用于跟踪仓位的开始和结束的柱的值将会在内核的参数中传递,这是一个相对值,可以加上开启仓位柱的索引以取得在时间序列中当前柱的绝对索引。另外,在时间序列中最大允许的柱的索引也应该传给内核,这样就不会超出缓冲区。
这样的结果是,用于跟踪开启仓位的 tester_step() 内核的参数集看起来如下:
__kernel void tester_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1, // 以价格差别表示,而不是点数 __global ulong *TimeM1, __global int *OrderM1, // 订单缓冲区, 其中 [0] 是在 OHLC(M1) 中的索引, [1] - (买入/卖出) 操作 __global int *Tasks, // 任务缓冲区 (已开启仓位) 保存订单在 OrderM1 缓冲区中的索引 __global int *Left, // 剩余任务的数量,两个元素: [0] - 用于存储体0, [1] - 用于存储体1 __global double *Res, // 结果缓冲区 const uint bank, // 当前存储体 const uint orders, // OrderM1 中的订单数量 const uint start_bar, // 已处理的柱形的序列号 (作为 OrderM1 中指定索引的偏移) const uint stop_bar, // 最后要处理的柱 const uint maxbar, // 允许的最大柱索引 (数组中的最后一个柱) const double tp_dP, // 以价格差距表示的 TP const double sl_dP, // 以价格差距表示的 SL const ulong timeout) // 何时强制关闭仓位 (秒数)
tester_step() 内核在一个维度上运行,维度任务的大小在每次调用时随着每个通过中订单数量的减少都会改变,
我们在内核代码的开始取得任务ID:
size_t id=get_global_id(0);
然后,根据当前存储体的索引,它是通过bank参数传递的,按下面的方式计算索引:
uint bank_next=(bank)?0:1;
计算我们将要操作的订单索引,在第一次运行时 (当 start_bar 等于0), 任务缓冲区就对应着订单缓冲区,所以订单索引等于任务索引,在之后的运行中,订单索引是从任务缓冲区中考虑到当前存储体和任务索引来取得的:
if(!start_bar) idx=id; else idx=Tasks[(orders*bank)+id];
知道了订单索引,我们就能取得时间序列中的柱索引,以及操作代码:
//--- 仓位中的柱索引已经在缓冲区 M1 中开启 uint iO=OrderM1[idx*2]; //--- (OP_BUY/OP_SELL) 操作 uint op=OrderM1[(idx*2)+1];
根据 timeout 参数的值,计算强制关闭仓位的时间:
ulong tclose=TimeM1[iO]+timeout;
然后就处理开启的仓位。让我们使用 BUY 操作来作为例子 (SELL 是类似的).
if(op==OP_BUY) { //--- 开启仓位的价格 double open=OpenM1[iO]+SpreadM1[iO]; double tp = open+tp_dP; double sl = open-sl_dP; double p=0; for(uint j=iO+start_bar; j<=(iO+stop_bar); j++) { for(uint k=0;k<4;k++) { if(k==0) { p=OpenM1[j]; if(j>=maxbar || TimeM1[j]>=tclose) { //--- 强制根据时间平仓 Res[idx]=p-open; return; } } else if(k==1) p=HighM1[j]; else if(k==2) p=LowM1[j]; else p=CloseM1[j]; //--- 检查是否触发了获利或者止损 if(p<=sl) { Res[idx]=sl-open; return; } else if(p>=tp) { Res[idx]=tp-open; return; } } } }
如果没有出发到退出内核的条件,任务就推迟到下一个通过:
uint i=atomic_inc(&Left[bank_next]);
Tasks[(orders*bank_next)+i]=idx;
在处理了所有通过后,Res[] 缓冲区就保存了所有交易的结果,为了取得测试结果,应当把它们合计起来。
现在算法已经很清楚了,内核也准备好了,我们应当开始运行它们了。
CTestPatterns 类将帮助我们完成这个任务:
class CTestPatterns : private COpenCLx { private: CBuffering *m_sbuf; // 当前时段的时间序列 CBuffering *m_tbuf; // M1 时段的时间序列 int m_prepare_passes; uint m_tester_passes; bool LoadTimeseries(datetime from,datetime to); bool LoadTimeseriesOCL(void); bool test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); bool optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); void buffers_free(void); public: CTestPatterns(); ~CTestPatterns(); //--- 运行一次测试 bool Test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); //--- 运行优化 bool Optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); //--- 取得程序执行统计的指针 COCLStat *GetStat(void){return &m_stat;} //--- 取得最近错误的代码 int GetLastError(void){return m_last_error.code;} //--- 取得最近错误的结构 STR_ERROR GetLastErrorExt(void){return m_last_error;} //--- 重置最近错误 void ResetLastError(void); //---测试内核运行的通过次数 void SetTesterPasses(uint tp){m_tester_passes=tp;} //---订单准备内核运行的通过次数 void SetPrepPasses(int p){m_prepare_passes=p;} };
让我们详细探讨 Test() 方法:
bool CTestPatterns::Test(STR_TEST_RESULT &result,datetime from,datetime to,STR_TEST_PARS &par) { ResetLastError(); m_stat.Reset(); m_stat.time_total.Start(); //--- 上传时间序列数据 m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- 初始化 OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_TESTER)==false) return false; m_stat.time_ocl_init.Stop(); //--- 运行测试 bool result=test(stat,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return result; }
在入口处,有一个日期范围,它对策略的测试是必须的,以及与参数和测试结果结构的链接。
如果成功,这个方法就返回 "true" 并把结果写到 'result' 参数中。如果在执行中出现错误,方法就返回 'false',如需取得详细的错误信息,调用 GetLastErrorExt().
首先,上传时间序列数据。然后,初始化 OpenCL,这包括创建对象和内核。如果一切正常,调用包含所有测试算法的 test() 方法。实际上,Test() 方法就是 test() 的封装。完成之后要确保在退出’test'方法后要进行终止化并释放时间序列的缓冲区。
在 test() 方法中, 都是从上传时间序列到 OpenCL 缓冲区开始的:if(LoadTimeseriesOCL () ==false)returnfalse;
这是使用之前讨论过的 LoadTimeseriesOCL() 方法来完成的。
首先运行 find_patterns() 内核, 它对应的是 k_FIND_PATTERNS 枚举。在运行之前,我们应当创建订单和结果缓冲区:
_BufferCreate(buf_ORDER,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
订单缓冲区的大小是当前时间框架下柱的数量的两倍。因为我们不知道会找到多少形态,我们假定在每个柱上都会找到形态,这在一开始看来可能很荒谬,但是随后,当增加其它形态的时候,可能会解决很多问题。
设置参数:
_SetArgumentBuffer(k_FIND_PATTERNS,0,buf_OPEN); _SetArgumentBuffer(k_FIND_PATTERNS,1,buf_HIGH); _SetArgumentBuffer(k_FIND_PATTERNS,2,buf_LOW); _SetArgumentBuffer(k_FIND_PATTERNS,3,buf_CLOSE); _SetArgumentBuffer(k_FIND_PATTERNS,4,buf_ORDER); _SetArgumentBuffer(k_FIND_PATTERNS,5,buf_COUNT); _SetArgument(k_FIND_PATTERNS,6,double(par.ref)*_Point); _SetArgument(k_FIND_PATTERNS,7,par.flags);
对于 find_patterns() 内核,设置一个一维任务空间,初始偏移为0:
uint global_size[1]; global_size[0]=m_sbuf.Depth; uint work_offset[1]={0};
运行执行 find_patterns() 内核:
_Execute(k_FIND_PATTERNS,1,work_offset,global_size);
应当注意的是,退出 Execute() 方法不是表示程序已经执行完毕,而是可能还在执行或者排队等待执行中。如需查看当前的状态,要使用 CLExecutionStatus() 方法。如果我们需要等待程序结束,我们可以定时查看它的状态或者读取程序放置结果的缓冲区。在第二种情况下,要在 BufferRead() 缓冲区读取方法中等待程序的结束。
_BufferRead(buf_COUNT,count,0,0,2);
现在在 count[] 缓冲区的索引0处,我们可以找到侦测到的形态的数量或者对应缓冲区中订单的数量。下一步就是在M1时间框架中找到对应的入场点。order_to_M1() 内核会在相同的 count[] 缓冲区索引1处合计侦测到的数量,(count[0]==count[1]) 条件的触发就可以认为是执行成功了。
但是,首先我们要创建M1的订单缓冲区,并使用-1的数值来填充它。因为我们已经知道了订单的数量,就使用不加边缘的准确大小来设置:
int len=count[0]*2; _BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
设置 array_fill() 内核的参数:
_SetArgumentBuffer(k_ARRAY_FILL,0,buf_ORDER_M1); _SetArgument(k_ARRAY_FILL,1,int(-1));
设置一维的任务空间,初始偏移为0,而大小等于缓冲区的大小。开始执行:
uint opt_init_work_size[1]; opt_init_work_size[0]=len; uint opt_init_work_offset[1]={0}; _Execute(k_ARRAY_FILL,1,opt_init_work_offset,opt_init_work_size);
下面,我们应该准备运行 order_to_M1() 内核的执行:
//--- 设置参数 _SetArgumentBuffer(k_ORDER_TO_M1,0,buf_TIME); _SetArgumentBuffer(k_ORDER_TO_M1,1,buf_TIME_M1); _SetArgumentBuffer(k_ORDER_TO_M1,2,buf_ORDER); _SetArgumentBuffer(k_ORDER_TO_M1,3,buf_ORDER_M1); _SetArgumentBuffer(k_ORDER_TO_M1,4,buf_COUNT); //--- k_ORDER_TO_M1 内核的任务空间是二维的 uint global_work_size[2]; //--- 第一个维度包含 k_FIND_PATTERNS 内核产生的订单 global_work_size[0]=count[0]; //--- 第二个维度中包含所有的 M1 图表柱 global_work_size[1]=m_tbuf.Depth; //--- 两个维度中任务空间的初始偏移都是0 uint global_work_offset[2]={0,0};
索引为5的参数没有设置,因为它的值将会有变化,并且将会在内核执行之前立即设置,因为上面所说的原因,order_to_M1() 内核的执行可能会在几秒之内使用不同的偏移执行几次,最大的执行次数是由当前和M1图表时间的比率做限制的:
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1);
整个循环看起来如下:
for(int s=0;s<maxshift;s++) { //--- 设置当前通过的偏移 _SetArgument(k_ORDER_TO_M1,5,ulong(s*60)); //--- 执行内核 _Execute(k_ORDER_TO_M1,2,global_work_offset,global_work_size); //--- 读取结果 _BufferRead(buf_COUNT,count,0,0,2); //--- 在索引0,您可以找到在当前图表上订单的数量 //--- 在索引1,您可以找到在M1图表中侦测到的对应柱数 //--- 如果两个值匹配,就退出循环 if(count[0]==count[1]) break; //--- 否则,就转到下一个迭代并以其它偏移运行内核 } //--- 再次检查订单数量是否有效,以防我们不是通过‘break’退出循环的 if(count[0]!=count[1]) { SET_UERRt(UERR_ORDERS_PREPARE,"M1 orders preparation error"); return false; }
现在是时候运行 tester_step() 内核了,它计算了根据所侦测到的入场点进行交易的结果。首先,让我们创建缓冲区并设置参数:
//--- 创建 Tasks 缓冲区,用于下面的通过而构成 _BufferCreate(buf_TASKS,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); //--- 创建保存交易结果的 Result 缓冲区 _BufferCreate(buf_RESULT,m_sbuf.Depth*sizeof(double),CL_MEM_READ_WRITE); //--- 设置单次测试内核的参数 _SetArgumentBuffer(k_TESTER_STEP,0,buf_OPEN_M1); _SetArgumentBuffer(k_TESTER_STEP,1,buf_HIGH_M1); _SetArgumentBuffer(k_TESTER_STEP,2,buf_LOW_M1); _SetArgumentBuffer(k_TESTER_STEP,3,buf_CLOSE_M1); _SetArgumentBuffer(k_TESTER_STEP,4,buf_SPREAD_M1); _SetArgumentBuffer(k_TESTER_STEP,5,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_STEP,6,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_STEP,7,buf_TASKS); _SetArgumentBuffer(k_TESTER_STEP,8,buf_COUNT); _SetArgumentBuffer(k_TESTER_STEP,9,buf_RESULT); uint orders_count=count[0]; _SetArgument(k_TESTER_STEP,11,uint(orders_count)); _SetArgument(k_TESTER_STEP,14,uint(m_tbuf.Depth-1)); _SetArgument(k_TESTER_STEP,15, double(par.tp)*_Point); _SetArgument(k_TESTER_STEP,16, double(par.sl)*_Point); _SetArgument(k_TESTER_STEP,17,ulong(par.timeout));
下面,把最大仓位持有时间转为在M1图表中的柱数:
uint maxdepth=(par.timeout/PeriodSeconds(PERIOD_M1))+1;
随后,检查指定的内核执行通过数是否有效,它默认等于8,但是为了使不同的 OpenCL 设备有最佳的效率,可以使用 SetTesterPasses() 方法来设置其它值。
if(m_tester_passes<1) m_tester_passes=1; if(m_tester_passes>maxdepth) m_tester_passes=maxdepth; uint step_size=maxdepth/m_tester_passes;
为单个维度设置任务空间的大小并运行计算交易结果的循环:
global_size[0]=orders_count; m_stat.time_ocl_test.Start(); for(uint i=0;i<m_tester_passes;i++) { //--- 设置当前索引 _SetArgument(k_TESTER_STEP,10,uint(i&0x01)); uint start_bar=i*step_size; //--- 设置当前通过开始测试的柱的索引 _SetArgument(k_TESTER_STEP,12,start_bar); //--- 设置当前通过所进行测试的最后柱的索引 uint stop_bar=(i==(m_tester_passes-1))?(m_tbuf.Depth-1):(start_bar+step_size-1); _SetArgument(k_TESTER_STEP,13,stop_bar); //--- 重置下一阶段任务的数量 //--- 它也保存着下一个通过剩余的订单数量 count[(~i)&0x01]=0; _BufferWrite(buf_COUNT,count,0,0,2); //--- 运行测试内核 _Execute(k_TESTER_STEP,1,work_offset,global_size); //--- 读取下一个通过剩余的订单数量 _BufferRead(buf_COUNT,count,0,0,2); //--- 把新任务数量设为等于订单数量 global_size[0]=count[(~i)&0x01]; //--- 如果没有剩余的任务,退出循环 if(!global_size[0]) break; } m_stat.time_ocl_test.Stop();
创建缓冲区用于读取交易结果:
double Result[]; ArrayResize(Result,orders_count); _BufferRead(buf_RESULT,Result,0,0,orders_count);
为了取得结果并与内建测试器比较,读取的数值应当除以 _Point,结果和统计计算的代码提供如下:
m_stat.time_proc.Start(); result.trades_total=0; result.gross_loss=0; result.gross_profit=0; result.net_profit=0; result.loss_trades=0; result.profit_trades=0; for(uint i=0;i<orders_count;i++) { double r=Result[i]/_Point; if(r>=0) { result.gross_profit+=r; result.profit_trades++; }else{ result.gross_loss+=r; result.loss_trades++; } } result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; m_stat.time_proc.Stop();
让我们写一个简短的脚本来运行我们的测试器。
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- 设置测试参数 STR_TEST_PARS pars; pars.ref= 60; pars.sl = 350; pars.tp = 50; pars.flags=15; // 所有形态 pars.timeout=12*3600; //--- 结果结构 STR_TEST_RESULT res; //--- 运行测试 tpat.Test(res,from,to,pars); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- 测试结果 Print("净利润: ", res.net_profit); Print("总获利: ", res.gross_profit); Print("总亏损: ", res.gross_loss); Print("交易总数: ", res.trades_total); Print("获利交易数: ",res.profit_trades); Print("亏损交易数: ", res.loss_trades); //--- 执行的统计 COCLStat ocl_stat=tpat.GetStat(); Print("GPU 内存大小: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU 内存使用: ", ocl_stat.gpu_mem_usage.ToStr()); Print("缓冲: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL 初始化: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL 缓冲: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL 准备订单: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL 测试: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL 中执行: ",ocl_stat.time_ocl_exec.ToStr()); Print("后续处理: ", ocl_stat.time_proc.ToStr()); Print("总计: ", ocl_stat.time_total.ToStr()); }
使用的测试时间范围,交易品种和周期数就是我们在测试使用 MQL5 所实现的EA中使用的,使用的参考和止损水平值也就是在优化中找到的,现在我们所要做的就是运行脚本并把取得的结果与内建测试器的测试结果相比较。
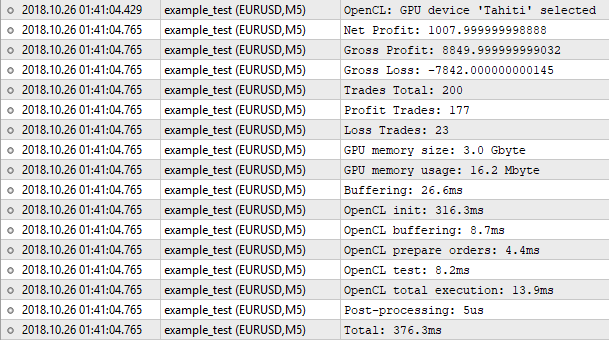
图 8. 使用 OpenCL 所实现的测试器的结果
结果,交易数量是相同的,而净利润的值却不同,内建测试器显示的数字是 1000.50, 而我们的测试器得到的是 1007.99。这里的原因如下:为了取得相同的结果,我们需要考虑到隔夜息和其它一些内容,但是把它们实现在我们的测试器中比较难。为了粗略估计,使用了 "1 分钟 OHLC" 模式,这样的小问题就可以忽略了。重要的是结果非常接近,也就意味着我们的算法工作正常。
现在让我们看看程序执行的统计结果,只使用了16MB的内存,OpenCL 初始化花费了大部分时间,整个处理过程花了 376 毫秒,几乎与内建测试器相同。在此就想取得更高效率没有意义,只有200个交易,我们还要花费时间来做准备工作,例如初始化,复制缓冲区等等。为了感受到区别,我们需要多几百倍的订单来测试,是时候转到优化部分了。
优化的算法和单次测试算法类似,但有一个基本区别。在测试器中我们寻找形态、然后计算交易结果,这里的操作顺序是不同的。首先,我们计算交易结果,然后再搜索形态。这样做的原因是我们有两个优化的参数,第一个是用来寻找形态的参考值,第二个是止损水平,参与了交易结果的计算。所以,它们中的一个影响入场点的数量,而另一个会影响交易结果和建立仓位的时间。如果我们保持与单次测试算法相同的顺序,我们就无法避免重新测试相同的入场点,这会花费大量的时间,因为带有300个点的“tail"的针杆在任何参考值等于或者小于它时都能找到它,
所以,在我们的情况下,更合理的是使用每个柱都作为入场点来计算交易结果(包括买入和卖出)然后再在这些数据中进行形态的搜索。这样,在优化中的操作顺序将是下面这样:
另外,用于搜索形态的任务数量乘以参考值变量的数量,而计算交易结果任务的数量要乘以止损值水平的数量。
我们假定在任何柱上都可以找到想要的形态,这就意味着我们需要在每个柱上都设置买入或者卖出订单。缓冲区的大小可以使用下面的公式来定义:
N = Depth*4*SL_count;
其中 Depth 是时间序列缓冲区的大小,而 SL_count 是止损值的数量。
另外,柱的索引应该是来自M1时间框架的。tester_opt_prepare() 内核搜索时间序列,在M1柱中寻找对应着当前时段柱的开启时间,并把它们以上面指定的格式放到订单缓冲区中。一般来说,它的工作和 order_to_M1() 内核类似:
__kernel void tester_opt_prepare(__global ulong *Time,__global ulong *TimeM1, __global int *OrderM1,// 订单缓冲区 __global int *Count, const int SL_count, // SL 值的数量 const ulong shift) // 时间偏移的秒数 { //--- 在二维中工作 size_t x=get_global_id(0); //index in Time if(OrderM1[x*SL_count*4]>=0) return; size_t y=get_global_id(1); //index in TimeM1 if((Time[x]+shift)==TimeM1[y]) { //--- 按顺序在M1周期中寻找最大的柱索引 atomic_max(&Count[1],y); uint offset=x*SL_count*4; for(int i=0;i<SL_count;i++) { uint idx=offset+i*4; //--- 为每个柱加入两个订单 (买入和卖出l) OrderM1[idx++]=y; OrderM1[idx++]=OP_BUY |(i<<2); OrderM1[idx++]=y; OrderM1[idx] =OP_SELL|(i<<2); } atomic_inc(&Count[0]); } }
但是,有一点重要的区别 — 寻找M1时间框架中的最大索引,让我仔细解释以下为什么要这样做。
当测试单个通过时,我们处理的是相对少量的订单,任务的数量等于订单的数量乘以M1时间序列中缓冲区的大小也是相对较小的,如果我们考虑到我们所进行的测试数据,有200个订单乘以 279 039 М1 个柱,会最终提供 大约5580万 个任务。
在当前的条件下,任务的数量将会大得多。例如,有 279 039 M1 柱乘以当前时段(M5)的 55 843 个柱,大约等于 156 亿 个任务。另外值得考虑的是您必须使用不同的时间偏移值多次运行这个内核,枚举方法在此太耗费资源了。
为了解决这个问题,我们将不使用枚举,尽管我们将会把当前时段的柱数处理范围分成几个部分。另外,我们应当限制相应的分钟柱的范围。然而,因为计算的索引值上限在大多数情况下比实际的多,我们将在返回Count[1]之后的最大分钟柱的索引,并从这个点开始下一次通过。
在准备好订单之后,是时候开始取得交易结果了。
tester_opt_step() 内核与 tester_step() 非常类似。所以,我将不会提供全部代码,而是只着重介绍区别。首先,输入参数有了变化:
__kernel void tester_opt_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1,// 以价格差别表示,而不是点数 __global ulong *TimeM1, __global int *OrderM1, // 订单缓冲区,其中 [0] 是在 OHLC(M1) 中的索引, [1] - (买入/卖出) 操作 __global int *Tasks, // 任务缓冲区 (开启仓位) 保存了订单在 OrderM1 缓冲区中的索引 __global int *Left, // 剩余任务的数量,两个元素: [0] - 用于存储体0, [1] - 用于存储体1 __global double *Res, // 结果缓冲区,取得结果后会立即填充, const uint bank, // 当前的存储体 const uint orders, // OrderM1 中的订单数量 const uint start_bar, // 已经处理的柱的序列号 (作为在 OrderM1 中指定索引的偏移) - 实际上, 就是在运行内核时循环中的 "i" const uint stop_bar, // 将要处理的最后一个柱 - 通常等于 'bar' const uint maxbar, // 可以接收的最大柱索引 (数组中的最后一个柱) const double tp_dP, // 以价格差距表示的 TP const uint sl_start, // SL 点数 - 初始值 const uint sl_step, // SL 点数 - 步长 const ulong timeout, // 交易生命周期 (描述), 超过之后会强制关闭 const double point) // _Point
我们没有使用 sl_dP 参数传入以价格差别 SL 水平值, 现在有了两个参数: sl_start 和 sl_step, 以及 'point' 参数,现在应当使用下面的公式来计算 SL 水平值:
SL = (sl_start+sl_step*sli)*point;
其中 sli 时订单中包含的止损索引值。
第二个区别是从订单缓冲区取得 sli 索引的代码:
//--- 操作 (位 1:0) 以及 SL 索引 (位 9:2) uint opsl=OrderM1[(idx*2)+1]; //--- 取得 SL 索引 uint sli=opsl>>2;
代码的其余部分和 tester_step() 内核是一样的。
在执行之后,我们就在 Res[] 缓冲区中取得每个柱和每个止损值买入和卖出的结果。
与测试不同,这里我们直接在内核中而不是在MQL代码中总计交易结果。但是,还是有个令人不愉快的缺点 — 我们必须把结果转化为整数类型,结果会损失精确度。所以,在 point 参数中,我们应当传入 _Point 值除以100。
强制转换结果到‘int’类型是因为原子函数不能操作'double'类型,atomic_add() 用于总计结果。
find_patterns_opt() 内核工作在三维任务空间中:
在工作过程中,会生成结果的缓冲区,缓冲区包含了每个止损水平和参考值组合的测试统计,测试统计是一个结构,包含下面的数值:
它们都是 'int' 类型的。基于它们,您可以计算净利润和交易总数。内核代码在下面提供:
__kernel void find_patterns_opt(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global double *Test, // 每个柱测试结果的缓冲区, 大小为 2*x*z ([0]-buy, [1]-sell ... ) __global int *Results, // 结果缓冲区, 大小为 4*y*z const double ref_start, // 形态参数 const double ref_step, // const uint flags, // 寻找哪些形态 const double point) // _Point/100 { //--- 在三维工作 //--- 柱的索引 size_t x=get_global_id(0); //--- 参考值索引 size_t y=get_global_id(1); //--- SL 值的索引 size_t z=get_global_id(2); //--- 柱数 size_t x_sz=get_global_size(0); //--- 参考值数量 size_t y_sz=get_global_size(1); //--- 止损值数量 size_t z_sz=get_global_size(2); //--- 形态搜索的空间大小 size_t depth=x_sz-PBARS; if(x>=depth)//不要在接近缓冲区末端开启 return; // uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref_start+ref_step*y,flags); if(res==PAT_NONE) return; //--- 计算在 Test[] 缓冲区中的交易结果索引 int ri; if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) //卖出 ri = (x+PBARS)*z_sz*2+z*2+1; else //买入 ri=(x+PBARS)*z_sz*2+z*2; //--- 根据计算得到的索引取得结果,并转换为分 int r=Test[ri]/point; //--- 计算在 Results[] 缓冲区中的测试结果索引 int idx=z*y_sz*4+y*4; //--- 把交易结果加到当前形态 if(r>=0) {//--- profit //--- 以分为单位合计总利润 atomic_add(&Results[idx],r); //--- 增加获利交易的次数 atomic_inc(&Results[idx+2]); } else {//--- 亏损 //--- 以分为单位统计总的亏损 atomic_add(&Results[idx+1],r); //--- 增加亏损交易次数 atomic_inc(&Results[idx+3]); } }
参数中的 Test[] 缓冲区是在执行了 tester_opt_step() 内核之后取得的结果。
在优化时从MQL5中运行内核的代码与测试过程中所构建的非常类似,Optimize() 公有方法是 optimize() 方法的封装,在其中实现了订单的准备和运行内核。
bool CTestPatterns::Optimize(STR_TEST_RESULT &result,datetime from,datetime to,STR_OPT_PARS &par) { ResetLastError(); if(par.sl.step<=0 || par.sl.stop<par.sl.start || par.ref.step<=0 || par.ref.stop<par.ref.start) { SET_UERR(UERR_OPT_PARS,"优化参数不正确"); return false; } m_stat.Reset(); m_stat.time_total.Start(); //--- 上传时间序列数据 m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- 初始化 OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_OPTIMIZER)==false) return false; m_stat.time_ocl_init.Stop(); //--- 运行优化 bool res=optimize(result,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return res; }
我们将不会详细探讨每一行代码,让我们只专注于其中的变化,特别是运行 tester_opt_prepare() 内核的部分。
首先,创建缓冲区用于管理处理过的柱数并返回在M1柱上的最大索引:
int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
然后,设置任务空间的大小。
_SetArgumentBuffer(k_TESTER_OPT_PREPARE,0,buf_TIME); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,1,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,2,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,3,buf_COUNT); _SetArgument(k_TESTER_OPT_PREPARE,4,int(slc)); // SL 数值的数量 //--- k_TESTER_OPT_PREPARE 内核有二维的任务空间 uint global_work_size[2]; //--- 0 维 - 当前时段的订单 global_work_size[0]=m_sbuf.Depth; //--- 1 维 - 所有的 М1 柱 global_work_size[1]=m_tbuf.Depth; //--- 对于第一次运行,把两个维度上的任务空间偏移都设为0 uint global_work_offset[2]={0,0};
在处理了一部分柱之后,第一个维度上任务空间的偏移会增加,它的值等于M1柱上的最大值,返回内核会再加1.
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1); int prep_step=m_sbuf.Depth/m_prepare_passes; for(int p=0;p<m_prepare_passes;p++) { //当前时段任务空间的偏移 global_work_offset[0]=p*prep_step; // M1 时段任务空间的偏移 global_work_offset[1]=count[1]; //当前时段的任务空间大小 global_work_size[0]=(p<(m_prepare_passes-1))?prep_step:(m_sbuf.Depth-global_work_offset[0]); //M1 时段的任务空间大小 uint sz=maxshift*global_work_size[0]; uint sz_max=m_tbuf.Depth-global_work_offset[1]; global_work_size[1]=(sz>sz_max)?sz_max:sz; // count[0]=0; _BufferWrite(buf_COUNT,count,0,0,2); for(int s=0;s<maxshift;s++) { _SetArgument(k_TESTER_OPT_PREPARE,5,ulong(s*60)); //--- 执行内核 _Execute(k_TESTER_OPT_PREPARE,2,global_work_offset,global_work_size); //--- 读取结果 (数量应该等于 m_sbuf.Depth) _BufferRead(buf_COUNT,count,0,0,2); if(count[0]==global_work_size[0]) break; } count[1]++; } if(count[0]!=global_work_size[0]) { SET_UERRt(UERR_ORDERS_PREPARE,"Failed to prepare M1 orders"); return false; }
m_prepare_passes 参数的意思是订单准备应当除以的通过数量,它的值默认是 64, 尽管它可以使用 SetPrepPasses() 方法来修改。
在从 OptResults[] 缓冲区中读取了测试结果之后, 就搜索取得最大净利润的优化参数组合。
int max_profit=-2147483648; uint idx_ref_best= 0; uint idx_sl_best = 0; for(uint i=0;i<refc;i++) for(uint j=0;j<slc;j++) { uint idx=j*refc*4+i*4; int profit=OptResults[idx]+OptResults[idx+1]; //sum+=profit; if(max_profit<profit) { max_profit=profit; idx_ref_best= i; idx_sl_best = j; } }
之后,重新以‘double’计算结果,并在相应结构中设置优化参数的值。
uint idx=idx_sl_best*refc*4+idx_ref_best*4; result.gross_profit=double(OptResults[idx])/100; result.gross_loss=double(OptResults[idx+1])/100; result.profit_trades=OptResults[idx+2]; result.loss_trades=OptResults[idx+3]; result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; //--- par.ref.value= int(par.ref.start+idx_ref_best*par.ref.step); par.sl.value = int(par.sl.start+idx_sl_best*par.sl.step);
请记住,把 'int' 转换为 'double' 以及反向操作肯定会影响结果,使得它们与单次测试所取得的结果有细微的差别。
写一个小脚本来运行优化:
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| 脚本程序起始函数 | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- 设置优化参数 STR_OPT_PARS optpar; optpar.ref.start = 15; optpar.ref.step = 5; optpar.ref.stop = 510; optpar.sl.start = 15; optpar.sl.step = 5; optpar.sl.stop = 510; optpar.flags=15; optpar.tp=50; optpar.timeout=12*3600; //--- 结果结构 STR_TEST_RESULT res; //--- 运行优化 tpat.Optimize(res,from,to,optpar); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- 优化参数的数值 Print("Ref: ",optpar.ref.value,", SL: ",optpar.sl.value); //--- 测试结果 Print("净利润: ", res.net_profit); Print("总获利: ", res.gross_profit); Print("总亏损: ", res.gross_loss); Print("交易总数: ", res.trades_total); Print("获利交易数: ",res.profit_trades); Print("亏损交易数: ", res.loss_trades); //--- 执行的统计 COCLStat ocl_stat=tpat.GetStat(); Print("GPU 内存大小: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU 内存使用: ", ocl_stat.gpu_mem_usage.ToStr()); Print("缓冲: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL 初始化: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL 缓冲: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL 准备订单: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL 测试: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL 中执行: ",ocl_stat.time_ocl_exec.ToStr()); Print("后续处理: ", ocl_stat.time_proc.ToStr()); Print("总计: ", ocl_stat.time_total.ToStr()); }
输入参数和在内建测试器中优化时相同。开始运行:
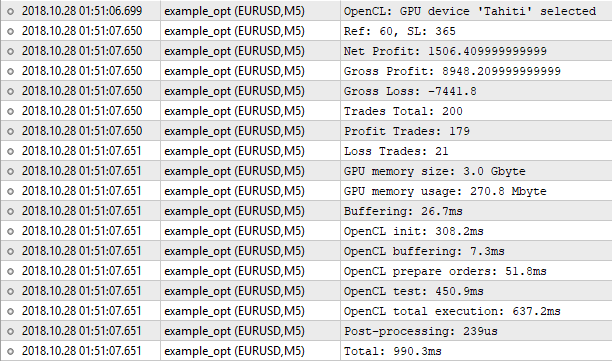
图 9. 在 OpenCL 测试器中的优化
我们可以看到,结果与在内建测试器中的结果不同,为什么呢?是不是因为在把’double‘转换为’int‘时损失了精确度,或者相反的时候造成了这样呢?从理论上说,这可能会造成结果在小数点后的分数位不同,但是这里的差异是很大的。
内建测试器显示 Ref = 60 和 SL = 350 的利润是 1000.50。而 OpenCL 测试器显示 Ref = 60 而 SL = 365 的净利润是 1506.40. 让我们尝试在常规测试器中运行 OpenCL 测试器中找到的数值:

图 10. 检查在 OpenCL 测试器中找到的优化结果
结果与我们的非常接近,所以,这不是因为损失了精确度。而是遗传算法跳过了优化参数的这个组合。让我们在慢速优化模式下运行内建测试器来测试所有枚举出的参数。
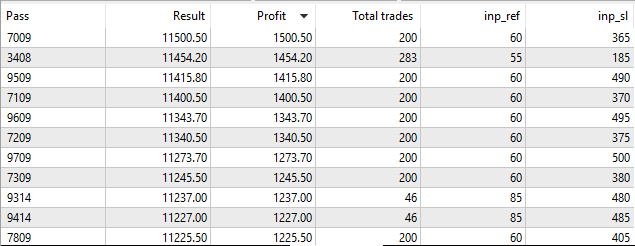
图 11. 在慢速优化模式下运行内建的策略测试器
我们可以看到,如果是完整枚举出的参数,内建测试器找到的数值 Ref = 60 以及 SL = 365, 和 OpenCL 测试器是一样的 。这表示我们实现的优化算法是正确的。
现在是时候比较内建与 OpenCL 测试器的效率了,
我们将比较对上面所描述策略的参数优化上所花费的时间。内建测试器将以两种模式运行: 快速 (遗传算法) 和慢速优化 (参数的完整枚举)。执行运行任务的PC有以下配置:
| 操作系统 |
Windows 10 (build 17134) x64 |
| CPU |
AMD FX-8300 Eight-Core Processor, 3600MHz |
| 内存 |
24 574 Mb |
| MetaTrader 安装所在介质 |
HDD |
为测试代理分配了 8个核中的 6 个。
OpenCL 测试器将在 AMD Radeon HD 7950 video 3Gb RAM and 800Mhz GPU 频率上运行。
将在三个货币对上进行优化: EURUSD, GBPUSD 和 USDJPY。对于每个货币对,每个优化模式将在四个时间范围内进行,我们将使用下面的简写:
| 优化模式 |
描述 |
|---|---|
| 快速测试器 |
内建策略测试器,遗传算法 |
| 慢速测试器 |
内建策略测试器,完整参数枚举 |
| OpenCL 测试器 |
使用OpenCL实现的测试器 |
设计的测试范围:
| 时段 |
时间范围 |
|---|---|
| 1 个月 |
2018.09.01 - 2018.10.01 |
| 3 个月 |
2018.07.01 - 2018.10.01 |
| 6 个月 |
2018.04.01 - 2018.10.01 |
| 9 个月 |
2018.01.01 - 2018.10.01 |
对我们来说,最重要的结果就是所需参数的数值、净利润、交易数量和优化的时间。
H1, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
15 |
15 |
15 |
| 止损 |
330 |
510 |
500 |
| 净利润 |
942.5 |
954.8 |
909.59 |
| 交易数量 |
48 |
48 |
47 |
| 优化持续时间 |
10 秒 |
6 分 2 秒 |
405.8 毫秒 |
H1, 3 个月
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 50 |
65 |
70 |
| 止损 | 250 |
235 |
235 |
| 净利润 | 1233.8 |
1503.8 |
1428.35 |
| 交易数量 | 110 |
89 |
76 |
| 优化持续时间 | 9 秒 |
8 分 8 秒 |
457.9 毫秒 |
H1, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 15 |
20 |
20 |
| 止损 | 455 |
435 |
435 |
| 净利润 | 1641.9 |
1981.9 |
1977.42 |
| 交易数量 | 325 |
318 |
317 |
| 优化持续时间 | 15 秒 |
11 分 13 秒 |
405.5 毫秒 |
H1, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 15 |
15 |
15 |
| 止损 | 440 |
435 |
435 |
| 净利润 | 1162.0 |
1313.7 |
1715.77 |
| 交易数量 | 521 |
521 |
520 |
| 优化持续时间 | 20 秒 |
16 分 44 秒 |
438.4 毫秒 |
M5, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
135 |
45 |
45 |
| 止损 |
270 |
205 |
205 |
| 净利润 |
47 |
417 |
419.67 |
| 交易数量 |
1 |
39 |
39 |
| 优化持续时间 |
7 秒 |
9 分 27 秒 |
418 毫秒 |
M5, 3 个月:
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 120 |
70 |
70 |
| 止损 | 440 |
405 |
405 |
| 净利润 | 147 |
342 |
344.85 |
| 交易数量 | 3 |
16 |
16 |
| 优化持续时间 | 11 秒 |
8 分 25 秒 |
585.9 毫秒 |
M5, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 85 |
70 |
70 |
| 止损 | 440 |
470 |
470 |
| 净利润 | 607 |
787 |
739.6 |
| 交易数量 | 22 |
47 |
46 |
| 优化持续时间 | 21 秒 |
12 分 03 秒 |
796.3 毫秒 |
M5, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 60 |
60 |
60 |
| 止损 | 495 |
365 |
365 |
| 净利润 | 1343.7 |
1500.5 |
1506.4 |
| 交易数量 | 200 |
200 | 200 |
| 优化持续时间 | 20 秒 |
16 分 44 秒 |
438.4 毫秒 |
H1, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
175 |
90 |
90 |
| 止损 |
435 |
185 |
185 |
| 净利润 |
143.40 |
173.4 |
179.91 |
| 交易数量 |
3 |
13 |
13 |
| 优化持续时间 |
10 秒 |
4 分 33 秒 |
385.1 毫秒 |
H1, 3 个月
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 175 |
145 |
145 |
| 止损 | 225 |
335 |
335 |
| 净利润 | 93.40 |
427 |
435.84 |
| 交易数量 | 13 |
19 |
19 |
| 优化持续时间 | 12 秒 |
7 分 37 秒 |
364.5 毫秒 |
H1, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 165 |
170 |
165 |
| 止损 | 230 |
335 | 335 |
| 净利润 | 797.40 |
841.2 |
904.72 |
| 交易数量 | 31 |
31 |
32 |
| 优化持续时间 | 18 秒 |
11 分 3 秒 |
403.6 毫秒 |
H1, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 165 |
165 | 165 |
| 止损 | 380 |
245 |
245 |
| 净利润 | 1303.8 |
1441.6 |
1503.33 |
| 交易数量 | 74 |
74 |
75 |
| 优化持续时间 | 24 秒 |
19 分 23 秒 |
428.5 毫秒 |
M5, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
335 |
45 |
45 |
| 止损 |
450 |
485 |
485 |
| 净利润 |
50 |
484.6 |
538.15 |
| 交易数量 |
1 |
104 |
105 |
| 优化持续时间 |
12 秒 |
9 分 42 秒 |
412.8 毫秒 |
M5, 3 个月:
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 450 | 105 |
105 |
| 止损 | 440 | 240 |
240 |
| 净利润 | 0 |
220 |
219.88 |
| 交易数量 | 0 |
16 |
16 |
| 优化持续时间 | 15 秒 |
8 分 17 秒 |
552.6 毫秒 |
M5, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 510 |
105 |
105 |
| 止损 | 420 |
260 |
260 |
| 净利润 | 0 |
220 |
219.82 |
| 交易数量 | 0 |
23 |
23 |
| 优化持续时间 | 24 秒 |
14 分 58 秒 |
796.5 毫秒 |
M5, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 185 |
195 |
185 |
| 止损 | 205 |
160 |
160 |
| 净利润 | 195 |
240 |
239.92 |
| 交易数量 | 9 |
9 |
9 |
| 优化持续时间 | 25 秒 |
20 分 58 秒 |
4.4 毫秒 |
H1, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
60 |
50 |
50 |
| 止损 |
425 |
510 |
315 |
| 净利润 |
658.19 |
700.14 |
833.81 |
| 交易数量 |
18 |
24 |
24 |
| 优化持续时间 |
6 sec |
4 分 33 秒 |
387.2 毫秒 |
H1, 3 个月
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 75 |
55 |
55 |
| 止损 | 510 |
510 |
460 |
| 净利润 | 970.99 |
1433.95 |
1642.38 |
| 交易数量 | 50 |
82 |
82 |
| 优化持续时间 | 10 秒 |
6 分 32 秒 |
369 毫秒 |
H1, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 150 |
150 |
150 |
| 止损 | 345 |
330 |
330 |
| 净利润 | 273.35 |
287.14 |
319.88 |
| 交易数量 | 14 |
14 |
14 |
| 优化持续时间 | 17 秒 |
11 分 25 秒 |
409.2 毫秒 |
H1, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 190 |
190 |
190 |
| 止损 | 425 |
510 |
485 |
| 净利润 | 244.51 |
693.86 |
755.84 |
| 交易数量 | 16 |
16 |
16 |
| 优化持续时间 | 24 秒 |
17 分 47 秒 |
445.3 毫秒 |
M5, 1 个月:
| 结果 |
快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 |
30 |
35 |
35 |
| 止损 |
225 |
100 |
100 |
| 净利润 |
373.60 |
623.73 |
699.79 |
| 交易数量 |
53 |
35 |
35 |
| 优化持续时间 |
7 秒 |
4 分 34 秒 |
415.4 毫秒 |
M5, 3 个月:
| 结果 | 快速测试器 |
慢速测试器 | OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 45 |
40 |
40 |
| 止损 | 335 |
250 |
250 |
| 净利润 | 1199.34 |
1960.96 |
2181.21 |
| 交易数量 | 71 |
99 |
99 |
| 优化持续时间 | 12 秒 |
8 分 |
607.2 毫秒 |
M5, 6 个月:
| 结果 | 快速测试器 | 慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 130 |
40 |
40 |
| 止损 | 400 |
130 |
130 |
| 净利润 | 181.12 |
1733.9 |
1908.77 |
| 交易数量 | 4 |
229 |
229 |
| 优化持续时间 | 19 秒 |
12 分 31 秒 |
844 毫秒 |
M5, 9 个月:
| 结果 | 快速测试器 |
慢速测试器 |
OpenCL 测试器 |
|---|---|---|---|
| 参考值 | 35 |
30 |
30 |
| 止损 | 460 |
500 |
500 |
| 净利润 | 3701.30 |
5612.16 |
6094.31 |
| 交易数量 | 681 |
1091 |
1091 |
| 优化持续时间 | 34 sec |
18 分 56 秒 |
1 秒 |
取得的结果显示,内建的测试器经常在快速优化模式(遗传算法)中跳过最佳的结果,所以,在完全参数枚举模式下与 OpenCL 做比较会更加公平。为了看得更清除,让我们准备一个在优化中所需时间的综合表格。
| 优化条件 |
慢速测试器 |
OpenCL 测试器 |
比率 |
|---|---|---|---|
| EURUSD, H1, 1 个月 |
6 分 2 秒 |
405.8 毫秒 |
891 |
| EURUSD, H1, 3 个月 |
8 分 8 秒 |
457.9 毫秒 |
1065 |
| EURUSD, H1, 6 个月 |
11 分 13 秒 |
405.5 毫秒 |
1657 |
| EURUSD, H1, 9 个月 |
16 分 44 秒 |
438.4 毫秒 |
2292 |
| EURUSD, M5, 1 个月 |
9 分 27 秒 |
418 毫秒 |
1356 |
| EURUSD, M5, 3 个月 |
8 分 25 秒 |
585.9 毫秒 |
861 |
| EURUSD, M5, 6 个月 |
12 min 3 sec |
796.3 毫秒 |
908 |
| EURUSD, M5, 9 个月 |
17 min 39 sec |
1 秒 |
1059 |
| GBPUSD, H1, 1 个月 | 4 分 33 秒 |
385.1 毫秒 |
708 |
| GBPUSD, H1, 3 个月 | 7 分 37 秒 |
364.5 毫秒 |
1253 |
| GBPUSD, H1, 6 个月 | 11 分 3 秒 |
403.6 毫秒 |
1642 |
| GBPUSD, H1, 9 个月 | 19 分 23 秒 |
428.5 毫秒 |
2714 |
| GBPUSD, M5, 1 个月 | 9 分 42 秒 |
412.8 毫秒 |
1409 |
| GBPUSD, M5, 3 个月 | 8 分 17 秒 |
552.6 毫秒 |
899 |
| GBPUSD, M5, 6 个月 | 14 分 58 秒 |
796.4 ms |
1127 |
| GBPUSD, M5, 9 个月 | 20 分 58 秒 |
970.4 ms |
1296 |
| USDJPY, H1, 1 个月 | 4 分 33 秒 |
387.2 毫秒 |
705 |
| USDJPY, H1, 3 个月 | 6 分 32 秒 |
369 毫秒 |
1062 |
| USDJPY, H1, 6 个月 | 11 分 25 秒 |
409.2 毫秒 |
1673 |
| USDJPY, H1, 9 个月 | 17 分 47 秒 |
455.3 ms |
2396 |
| USDJPY, M5, 1 个月 | 4 分 34 秒 |
415.4 毫秒 |
659 |
| USDJPY, M5, 3 个月 | 8 分 |
607.2 毫秒 |
790 |
| USDJPY, M5, 6 个月 | 12 分 31 秒 |
844 毫秒 |
889 |
| USDJPY, M5, 9 个月 | 18 分 56 秒 |
1 秒 |
1136 |
在这篇文章中,我们已经实现了为使用 OpenCL 的简单交易策略构建测试器的算法。当然,这个实现只是可行方案的一种,它还有很多缺点。其中包括:
尽管有这些问题,这种算法在您需要快速粗略评估简单形态时还是有很大帮助的,因为与内建的测试器运行完全的参数枚举模式相比,它会快几千倍,而与使用遗传算法的测试器相比也会快几十倍。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







