
在前面的文章中, 我们探讨了随机决策森林算法,提出了一种基于强化学习的简单自学习算法。
概述了这种方法的以下主要优点:
同时,这种方法有一个主要缺点:
有两种主要方法可以克服过度拟合:
上述技术以原始方式包含在算法中。一方面,通过枚举价格增量和选择几个最佳值来构造属性,另一方面,通过调整r参数来选择新数据上分类错误最小的模型。
此外,还有一个同时创建多个RL代理的新机会,您可以将不同的设置设置设置为,从理论上讲,这将提高模型对新数据的稳定性。模型枚举是使用蒙特卡罗方法(随机抽取标签)在优化器中执行的,而最佳模型则写入文件以供进一步使用。
为了方便起见,库是基于OOP的,这使得它很容易连接到EA并声明所需数量的RL代理。
在这里,我将描述一些类字段,以便更深入地理解程序中的交互结构。
//+------------------------------------------------------------------+ //|RL 代理的基类 | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //在每次交易后更新学习者原则 void updateReward(); //在关闭一个交易后更新收益 double getTradeSignal(double&[]); //从训练好的代理或者随机接收交易信号 int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
前三种方法用于形成学习者(代理)的政策(策略),更新奖励并接收来自训练有素代理的交易信号。在第一篇文章中对它们进行了详细描述。
定义随机森林设置的辅助字段、属性数(输入)、存储模型错误的数组和代理(代理组)名称将在上进一步声明。
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
进一步阐述了参数化学习策略、随机森林对象和存储错误的辅助对象的保存矩阵。
提供以下静态变量用于存储代理的唯一ID:
static int CRLAgent::agentIDs=0;
构造函数在开始工作之前初始化所有变量:
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
在最后,控制权委托给getRDFstructure()方法,执行以下操作:
//+------------------------------------------------------------------+ //|载入学习过的代理 | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
如果启动了EA优化,将检查文件中是否存在在上一个优化程序迭代期间记录的错误。在每次新的迭代中比较模型误差,以便随后选择最小的迭代。
如果在测试模式下启动EA,则从文件中下载经过培训的模型以供进一步使用。此外,模型的最新错误将被清除,并设置等于1的默认值,以便新的优化从零开始。
在优化器中进行下一次运行后,对学习者进行如下培训:
//+------------------------------------------------------------------+ //|一个代理的学习 | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
控制权委托给指定的方法,用于连续选择属性,即价格增量。让我们看它是如何工作的:
//+------------------------------------------------------------------+ //|矩阵输入的递归特征消除 | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //特征转换,使每两个特征以不同的滞后返回 ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //用增量填充矩阵(数组零索引价格除以BF移位的价格) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //训练一个随机森林,其中只使用选定的增量作为预测器 ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //保存 oob 集合上的错误 bestFeatures[modelCounterInitial][1] = bf; //保存增量'延迟' modelCounterInitial++; } ArraySort(bestFeatures); //数组排序 (根据第0维), 这里也就是根据错误 oob ArrayResize(bestFeatures,bestfeatures_num); // 只保留最佳的 bestfeatures_num 属性 m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { // 再次填充矩阵,但是这一次使用最佳属性 for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); // 根据选定的最佳属性训练随机森林 }
让我们全面了解一下代理培训方法:
//+------------------------------------------------------------------+ //|一个代理的学习 | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
在选择属性并对代理进行训练后,将当前优化过程中的代理分类错误与整个优化过程中保存的最小错误进行比较。如果当前代理的错误较小,则当前模型将保存为最佳模型,随后的比较将使用此模型的错误。
蒙特卡罗方法(价格变量随机抽样)应单独考虑:
//+------------------------------------------------------------------+ //| 取得交易信号 | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
如果 EA 不在优化模式下, 初始化EA时下载的已经训练过的模型用于接收交易信号。否则,如果优化过程正在进行中或没有模型文件,则信号会在没有打开位置(50/50)的情况下随机出现,并且在存在打开订单的情况下,通过prob_shift变量设置偏移概率。因此,例如,如果已经存在一个公开买入交易,您可以将卖出信号的概率转换为0.1(而不是0.5)。结果,训练集中的样本总数减少,仓位持有时间延长。同时,当设置prob_shift>=0.5时,交易数量增加。
现在,我们可以让多个代理(学习者)在交易系统中执行各种任务。本课程的目的是为了更方便地管理同质学习者群体。
//+------------------------------------------------------------------+ //|多 RL 代理类 | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
Agents结构接受每个学习者的参数,结构数组包含它们的总数。对于单个代理,使用这个特定类也是有意义的。
构造函数获取学习所需的所有参数:
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
它们包括:代理组名称、工人数量、每个工人的属性数量、最佳选择的属性数量、森林中树的数量、规范化参数(分离为培训和测试集)和管理交易数量的概率偏移。
如我们所见,具有相同输入以及训练和测试错误的学习者对象被放置到结构数组中。
代理学习方法为每个CRLAgent基类调用学习方法,并返回所有代理的测试集的平均错误:
//+------------------------------------------------------------------+ //|所有代理的学习 | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
当使用蒙特卡罗方法迭代模型时,此错误被用作自定义优化标准来可视化错误扩散。
在一个子组中创建一定数量的学习者时,其设置保持不变。因此,有一种方法可以调整每个学习者的参数:
//+------------------------------------------------------------------+ //|调整代理的设置 | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
与 CRLAgent 基类不通, 在 CRLAgents 中, 交易信号显示维学习者所属子组的平均信号:
//+------------------------------------------------------------------+ //|取得通用交易信号 | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
最后,获取统计数据的方法在测试仪中显示关于测试和培训所有代理的错误的数据:
//+------------------------------------------------------------------+ //|取得代理的统计数据 | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
现在我们只需要编写一个简单的EA来演示库功能。让我们从第一个案例开始,在这个案例中,只有一个代理被创建来接受有关交易工具收盘价的培训。
#include <RL Monte Carlo.mqh>
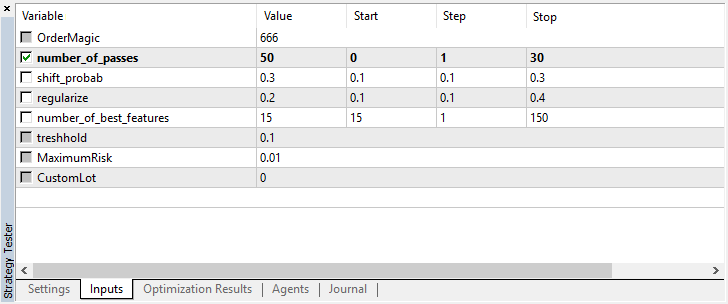
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
包含开发库并定义需要优化的 inputs(输入参数),number_of_passes 用于确定终端优化器中的传递次数,而不在任何位置传递。由于入场和出场是由工人随机选择的,因此可以在多次通过并定义最小错误后实现最佳策略。设置的通过数越多,获得最优策略的概率就越高。
其余设置在上面概述,并直接传递到创建的模型。在这里,我们创建了一个属于RLMonteCarlo 组的单一代理。将500个属性传递给输入,并在其中选择5个最佳属性。该模型将有50个决策树,其中训练集和测试集的间隔为0.6(r参数),没有概率偏移。
在 OnTester 函数中, 自定义优化标准(作为所有学习者的测试样本的平均误差)在初步培训后返回:
//+------------------------------------------------------------------+ //| EA 交易 OnTester 函数 | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
在去初始化过程中,将删除学习者并释放记忆:
//+------------------------------------------------------------------+ //| EA 交易去初始化函数 | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
预测器的矢量填充如下:
//+------------------------------------------------------------------+ //| 计算 Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
在这种情况下,最后500个收盘价是简单取得的。您可能还记得,在模型中,数组零元素与其他元素的比率(具有一定的滞后)被视为一个预测因子,因此,将数组设置为接收收盘价格,以序列的方式。之后调用交易信号获取方法。
最后一个函数是交易函数:
//+------------------------------------------------------------------+ //| 设置订单 | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
'threshold' 参数已经另外介绍了,它允许设置信号激活阈值。例如,如果购买信号概率小于0.6,则订单不会打开。
让我们看看可以优化的设置:
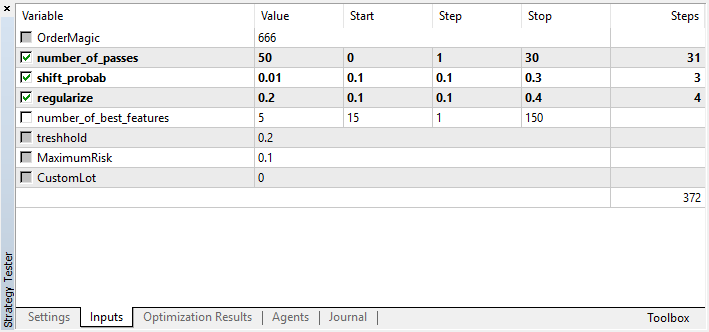
请记住,number of_passes不会将任何值传递给学习者,相反,它只是设置优化器通过的次数。假设您已经决定了其他设置,现在您只想使用基于蒙特卡洛的枚举。在这种情况下,您应该只根据这个标准进行优化。如果需要,您仍然可以优化其余四个设置。
当前版本的另一个特点是,不需要禁用测试代理,因为优化器中的过程彼此独立,保存模型的顺序也不重要。
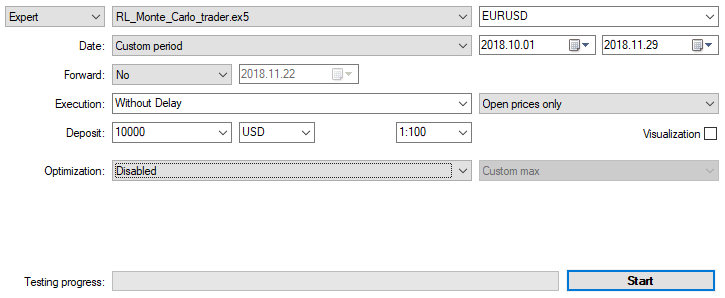
让我们在两个月内通过公开价格,使用上面在M15中指定的设置来优化EA。"Custom max" 应选择作为优化标准。当达到优化准则的可接受值时,可随时停止优化过程:
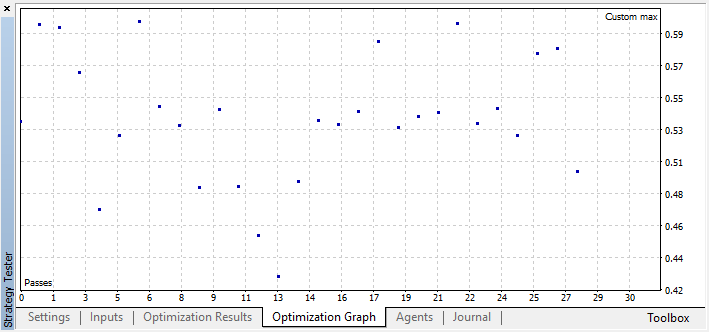
例如,我在第44步停止了优化,因为其中一个最佳模型超过了精度阈值0.6。这意味着测试样本的分类误差低于0.4。记住,模型越好,误差越小,但是为了遗传算法的正确操作(如果你想使用它),误差值是颠倒的。
您可以在“优化”选项卡中检查最佳模型设置,按自定义条件最大值对值排序:
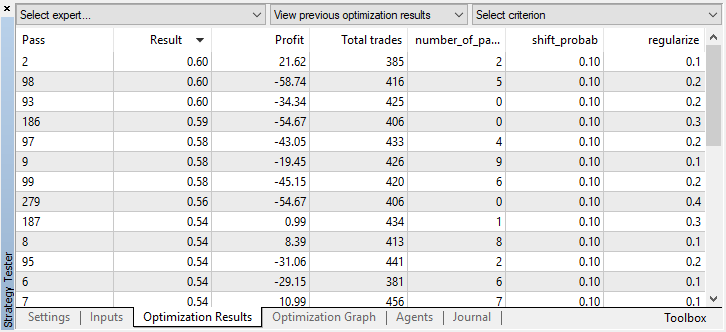
在这种情况下,最佳模型的概率偏移量为0.1,并且r参数为0.2(培训集仅为整个交易矩阵的20%,而80%为测试子集)。
停止优化后,只需启用单一测试模式(因为最佳模型已写入文件,并且只上载该模型):
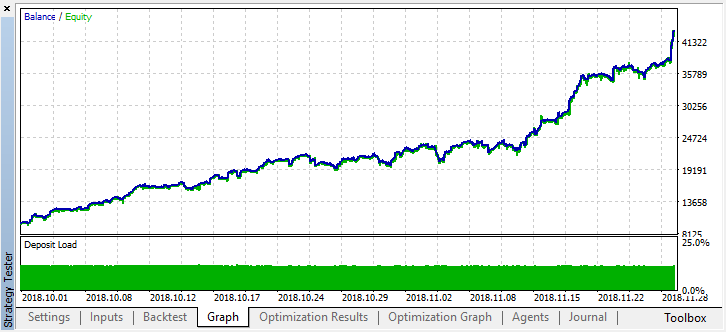
让我们滚动两个月前的历史记录,看看该模型在整个四个月内是如何工作的:
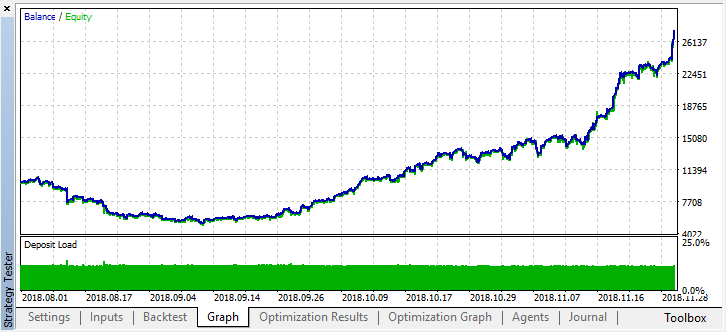
我们可以看到结果模型持续了另一个月(几乎整个9月),而在8月崩溃。让我们尝试通过将“treshhold”设置为0.2来微调模型:
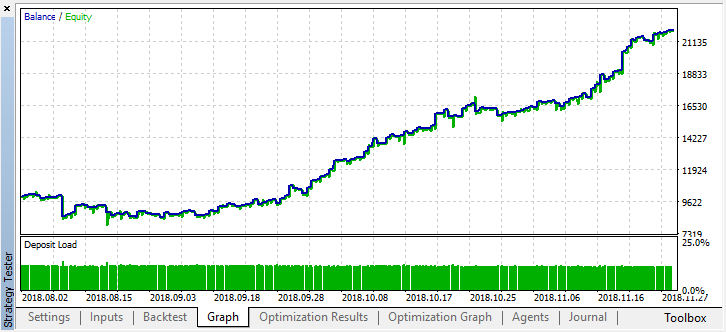
情况明显好转。该模型的准确性提高了,同时交易数量也减少了。如果培训期具有适当的长度,则可以进行更深入的测试。
现在,让我们考虑具有多个学习者的EA变体,以便比较多代理方法与单代理方法的效率。
为此,在创建一组代理时添加“Multi”结尾,这样不同系统的文件就不会混合在一起。另外,设置工作单元数量,例如,五个:
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
所有的代理都是相同的(它们有相同的设置),您可以在EA初始化函数中分别配置每个工作单元:
//+------------------------------------------------------------------+ //| EA 交易初始化函数 | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
在这里,我决定不再使事情复杂化,并按500到25的降序排列代理的属性数量。此外,最佳选择属性的数量也从20个减少到了2个。其他设置保持不变。您可以更改它们并添加新的优化参数。我鼓励您尝试这些设置,并在下面的评论中分享您的结果。.
您可能还记得,数组在函数中填充了预测值:
//+------------------------------------------------------------------+ //| 计算 Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
这里,我们只需根据每个学习者的大小为inpVector数组填充接近的价格,因此对于这种情况,函数是通用的,不需要更改。
使用与单个代理相同的设置启动优化:
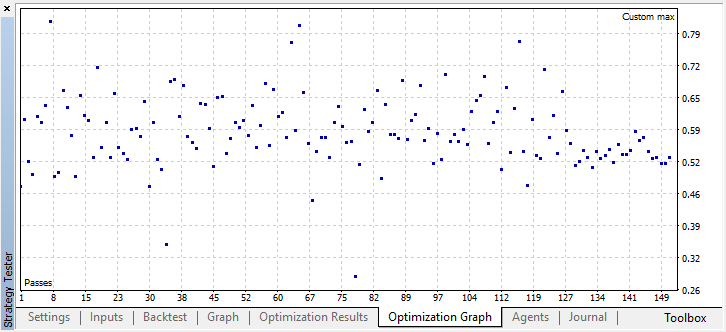
最佳结果超过0.7,比第一种情况好得多。在测试器中启动一次运行:
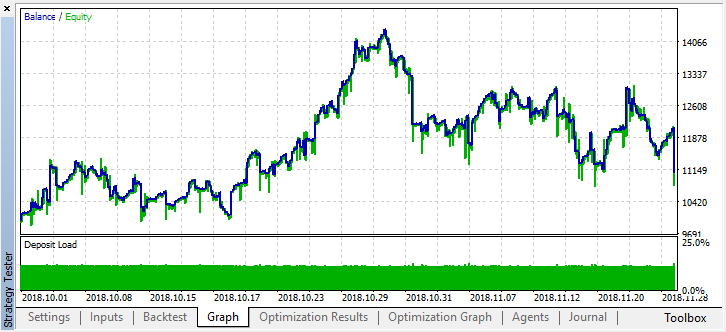
余额图反映的真实结果变得更糟。为什么呢?让我们看看最佳运行的随机交易数量,它们只有21个!
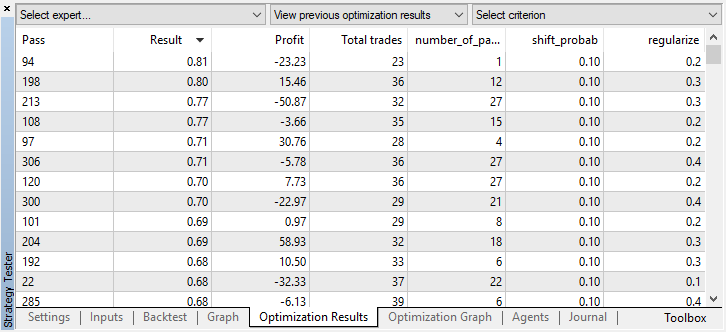
结果是这样的,因为随机抽样导致多个代理的信号重叠,交易总数减少。要解决此问题,请将shift_probab参数设置为接近0.5。在这种情况下,每个代理的交易数量将更大,从而也会增加总交易数量,另一方面,您可以简单地增加学习周期,但首先我们应该看看是否有可能进一步使用这种模型。将“threshold”设置为0.2,然后查看会发生什么:
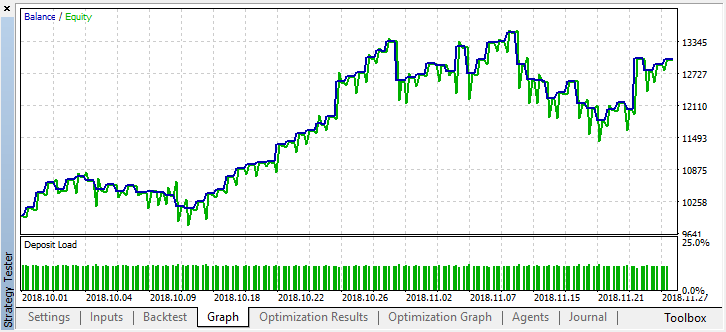
至少,尽管交易数量进一步减少,但该模型不会亏损。在一次测试运行后,测试器日志中会显示以下错误:
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
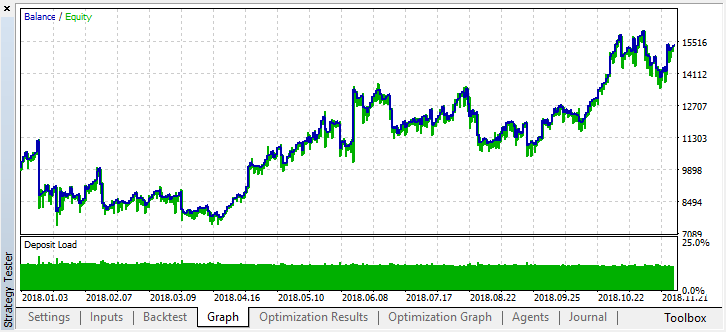
现在让我们从年初开始测试这个模型。结果相当稳定:
将shift-probab设置为0.3,然后在M15上启动优化器,使其在两个月内不带此参数(以查找交易数量平衡):
由于计算的复杂性有所增加,我决定在优化器中进行几次迭代后继续使用以下结果:
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
测试集上的误差仍然相当大,但是,在0.2的阈值下,该模型在4个月内显示出盈利,尽管它在测试数据上表现出相当不稳定。
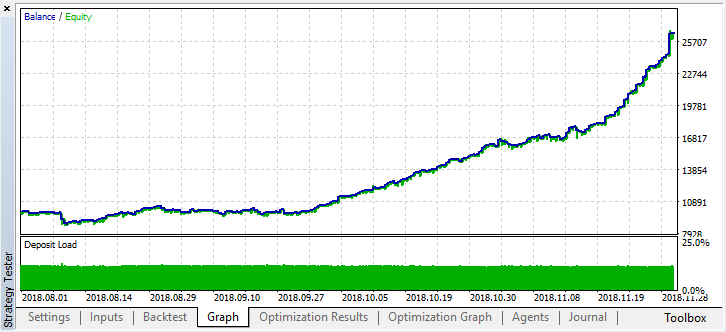
请记住,所有学习者都接受过相同数据(接近价格)的培训,因此没有理由添加新数据。总之,这是添加新代理的简单示例。
强化学习可能是机器学习中最有趣的方法之一。人们总是倾向于认为人工智能能够在独立学习的同时解决金融市场的交易问题。同时,为了创造这样一个“奇迹”,人们应该对机器学习、统计学和概率论有广泛的了解。蒙特卡罗方法和用最小误差选择模型的试验数据,大大改善了本文第一篇提供的模型。这个模型已经不再过度拟合了。
最好的模型应该根据交易的数量和最小的分类误差来选择。理想情况下,训练和测试集的误差应大致相等,且不应达到0.5(一半的例子预测错误)。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







